
日期:2026-05-11 时长:约 40-45 分钟
目录
- 引言 — 为什么 Agentic AI 需要工程化思考
- 沙盒环境 — 让 Agent 安全地”动手”
- Agent 记忆设计 — 从”金鱼记忆”到持久智能
- MCP 服务云端部署 — 工具连接的标准化之路
- 身份认证与授权 — Agent 的”身份证”问题
- Agent 质量评估 — 如何衡量一个 Agent 好不好用
- 可观测性设计 — 让黑盒变成白盒
- 隐私与安全 — Agent 的”红线”在哪里
- 总结与讨论
1. 引言
为什么要关注这个话题?
Gartner 将 Agentic AI 列为 2025 年第一大战略技术趋势。但把 Agent 从 Demo 搬到生产环境,面临的不再是”模型能力够不够”的问题,而是一系列工程化难题:
- Agent 生成的代码在哪里执行?怎么隔离?
- 跨多轮、跨会话的上下文怎么保持?
- 工具调用怎么标准化?怎么部署和管理?
- Agent 代表用户操作时,权限边界在哪?
- 怎么评估 Agent 的输出质量?
- 出了问题怎么排查?
- 用户数据怎么保护?
一句话概括: Agentic AI 的工程化落地,本质上是在”自主性”和”可控性”之间找到平衡点。
Agent 系统的分层架构
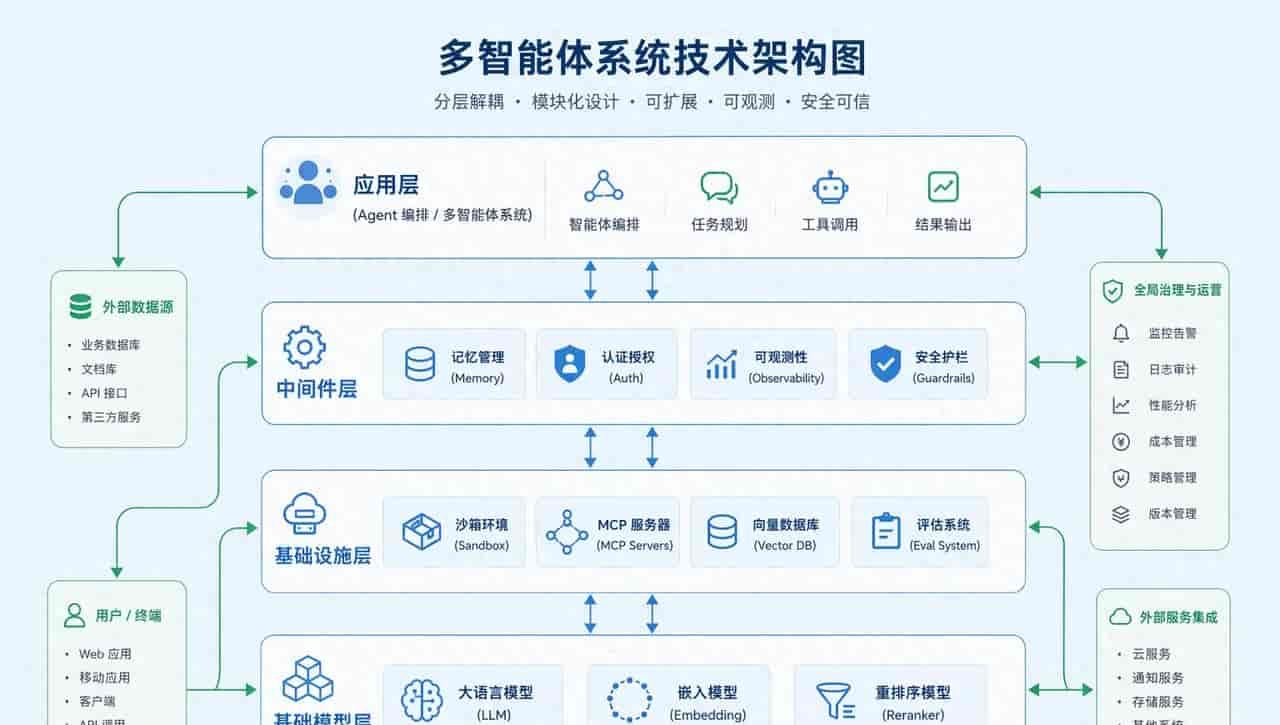
今天的分享聚焦 Middleware Layer 和 Infrastructure Layer,这是把 Agent 从 Demo 推向生产的核心战场。
2. 沙盒环境
问题本质
Agent 能写代码、能调命令,但直接在宿主机执行 = 给了 Agent “root 权限”。一个恶意 Prompt Injection 就可能:
- 读取环境变量中的 API Key
- 发起网络请求外泄数据
- 无限循环耗尽资源
沙盒的三重价值
|
维度 |
作用 |
|
安全隔离 |
限制 blast radius,即使 Agent 生成恶意代码也不影响宿主 |
|
弹性伸缩 |
数千个 Agent 会话可并行启停,无需预留 VM |
|
可观测 |
细粒度的进程日志、资源指标、网络出入口控制 |
隔离技术栈对比
隔离强度 ─────────────────────────────────────────────────▶
进程级 容器级 MicroVM 全虚拟化
(chroot) (Docker+gVisor) (Firecracker) (KVM/QEMU)
启动: <10ms 启动: <100ms 启动: ~125ms 启动: 数秒
隔离: 弱 隔离: 中 隔离: 强 隔离: 最强
开销: 极低 开销: 低 开销: 中 开销: 高主流沙盒方案对比
|
方案 |
隔离技术 |
冷启动 |
自动伸缩 |
网络策略 |
适用场景 |
|
Modal |
gVisor 容器 |
<1s |
20k+ 并发 |
内置隧道+出口策略 |
大规模 Agent SaaS |
|
E2B |
Firecracker MicroVM |
<1s |
需自建集群 |
无内置策略 |
开源自建、灵活定制 |
|
Daytona |
容器 |
~90ms |
Warm pool |
基础控制 |
低延迟 eval pipeline |
|
DIY K8s |
gVisor/Kata |
看配置 |
取决于集群 |
NetworkPolicy |
完全自主可控 |
生产落地关键设计
# E2B 沙盒使用示例 - 每个 Agent 任务一个隔离环境
from e2b_code_interpreter import Sandbox
def execute_agent_code(code: str, timeout: int = 30):
"""在隔离沙盒中执行 Agent 生成的代码"""
sandbox = Sandbox(
template="python-3.11", # 预构建镜像
timeout=timeout,
metadata={"agent_id": "xxx"}
)
try:
result = sandbox.run_code(code)
return {
"stdout": result.logs.stdout,
"stderr": result.logs.stderr,
"artifacts": result.results
}
finally:
sandbox.kill() # 用完即销毁最佳实践
- 最小权限原则:沙盒默认无网络出口,按需开白名单
- 资源 Quota:CPU/内存/磁盘/执行时长都要设上限
- 文件系统只读挂载:Agent 需要的工具预装在镜像里,运行时只给 /tmp 可写
- 审计日志:所有沙盒内的系统调用和网络请求全量记录
思考题:在我们团队的场景中,Agent 需要访问内部 Git 仓库和数据库,沙盒的网络策略该怎么设计?
3. Agent 记忆设计
为什么 Agent 需要记忆?
没有记忆的 Agent ≈ 每次对话都是”失忆的天才”。Context Window 有限,而用户期望 Agent 能:
- 记住上下文偏好(”我喜爱 Go 而不是 Python”)
- 跨会话积累知识(”上次我们讨论的架构方案…“)
- 从历史行为中学习(”这个用户总是需要详细的代码注释”)
记忆层次模型
借鉴认知科学,Agent 记忆可分为多层:
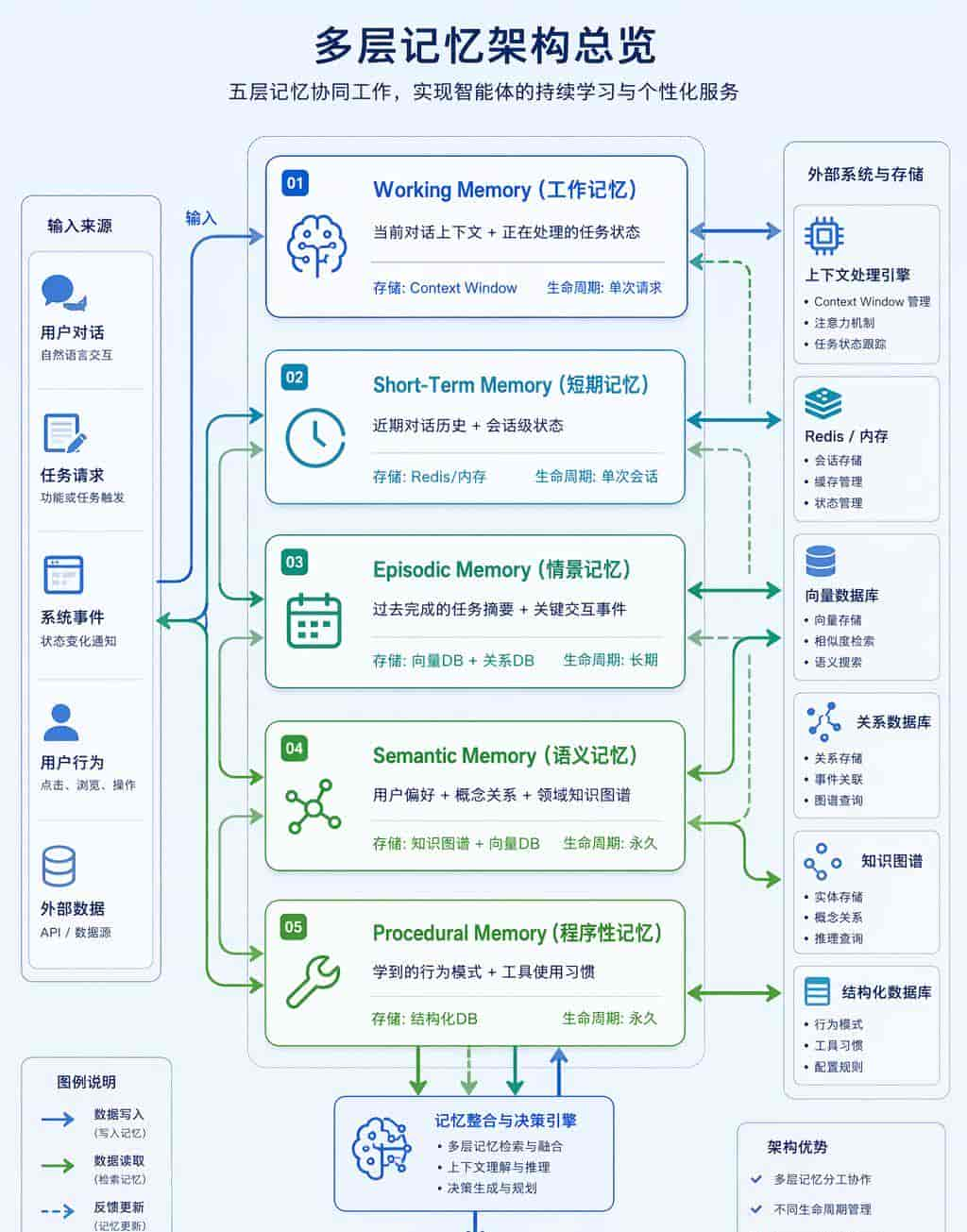
Mem0 架构剖析
Mem0 是当前最成熟的 Agent 记忆框架,被 AutoGen、LangChain 等集成:
用户输入 ──▶ Memory Extraction ──▶ Memory Consolidation ──▶ Storage
(LLM 提取关键信息) (去重、冲突解决、合并) (多后端)
查询时: Query ──▶ Hybrid Search ──▶ Relevance Ranking ──▶ Context Injection
(向量类似度 + 关键词) (时间衰减 + 重大度) (注入到 Prompt)核心设计要点:
- 动态提取:不是存原始对话,而是 LLM 提取结构化信息(实际、偏好、关系)
- 冲突解决:新旧记忆矛盾时的更新策略(最新优先 / 置信度加权)
- 时间衰减:老旧记忆权重递减,避免过时信息污染决策
生产级记忆系统设计
# 记忆系统核心接口设计
class MemoryManager:
def add(self, content: str, metadata: dict) -> str:
"""提取并存储记忆"""
# 1. LLM 提取关键信息
facts = self.extract_facts(content)
# 2. 去重检查(语义类似度 > 0.9 视为重复)
facts = self.deduplicate(facts)
# 3. 冲突解决(同一实体的新旧信息)
facts = self.resolve_conflicts(facts)
# 4. 持久化(向量 + 结构化双写)
return self.store(facts, metadata)
def search(self, query: str, user_id: str, top_k: int = 5) -> list:
"""检索相关记忆"""
# 混合检索:向量类似度 + BM25 关键词
candidates = self.hybrid_search(query, user_id)
# 应用时间衰减和重大度加权
scored = self.rank_with_decay(candidates)
return scored[:top_k]
def forget(self, memory_id: str):
"""GDPR 合规:支持用户要求删除记忆"""
self.soft_delete(memory_id)记忆存储选型
|
记忆类型 |
推荐存储 |
缘由 |
|
Working |
LLM Context |
无需外部存储 |
|
Short-Term |
Redis + TTL |
高速读写,自动过期 |
|
Episodic |
PostgreSQL + pgvector |
结构化+向量混合查询 |
|
Semantic |
Neo4j / 知识图谱 |
关系推理能力强 |
|
Procedural |
JSON/YAML 配置 |
规则明确、易审计 |
思考题:我们的 Agent 需要记住用户的代码风格偏好,这属于哪层记忆?用什么存储方案最合适?
4. MCP 服务云端部署
MCP 是什么?
Model Context Protocol (MCP) 是 Anthropic 于 2024 年发布的开放协议,定义了 LLM 应用与外部工具/数据源的标准接口。可以类比为 “AI 时代的 USB 协议”。
┌──────────┐ MCP Protocol ┌──────────────┐
│ LLM App │◀────────────────────▶│ MCP Server │
│ (Client) │ JSON-RPC / SSE │ (Tool/Data) │
└──────────┘ └──────────────┘为什么需要云端部署?
本地 MCP (stdio) 的局限:
- ❌ 每个客户端需要单独安装、配置
- ❌ 无法共享状态(如数据库连接池)
- ❌ 无法水平扩展
- ❌ 升级需要逐个客户端更新
云端 MCP (HTTP/SSE) 的优势:
- ✅ 聚焦管理、统一升级
- ✅ 多租户、多客户端共享
- ✅ 弹性伸缩、高可用
- ✅ 统一的监控、鉴权、限流
MCP 2025-11-25 规范要点
MCP 在一年的演进中,规范已趋于成熟:
|
版本 |
关键变化 |
|
2024-11 (初版) |
基础 JSON-RPC + stdio 传输 |
|
2025-03 |
新增 Streamable HTTP 传输 |
|
2025-06 |
新增 OAuth 2.1 授权框架、elicitation |
|
2025-11 |
完善安全规范、标准化错误码 |
云端部署架构
┌───────────────────────┐
│ Load Balancer │
│ (Nginx / Envoy) │
└──────────┬────────────┘
│
┌────────────────┼────────────────┐
│ │ │
┌────────▼──────┐ ┌──────▼────────┐ ┌────▼──────────┐
│ MCP Server 1 │ │ MCP Server 2 │ │ MCP Server 3 │
│ (Instance) │ │ (Instance) │ │ (Instance) │
└───────┬───────┘ └──────┬────────┘ └───────┬───────┘
│ │ │
┌───────▼────────────────▼───────────────────▼───────┐
│ Shared Infrastructure │
│ Redis (Session) │ DB │ Message Queue │ Secrets │
└────────────────────────────────────────────────────┘部署关键考量
1. 传输协议选择
stdio (本地) ──▶ 适合开发调试、单用户场景
HTTP + SSE ──▶ 生产推荐,支持无状态扩展
WebSocket ──▶ 需要双向实时通信的场景(未来可能标准化)2. 会话管理
MCP 是有状态的协议(Resources 订阅、Sampling 等),云端部署需要:
- Session affinity(粘性会话)或者
- 聚焦式 Session Store(Redis)
3. 容器化部署模板(Kubernetes)
apiVersion: apps/v1
kind: Deployment
metadata:
name: mcp-server-github
spec:
replicas: 3
template:
spec:
containers:
- name: mcp-server
image: your-registry/mcp-github:v1.2.0
ports:
- containerPort: 8080
env:
- name: MCP_TRANSPORT
value: "streamable-http"
- name: GITHUB_TOKEN
valueFrom:
secretKeyRef:
name: mcp-secrets
key: github-token
resources:
limits:
memory: "256Mi"
cpu: "500m"
livenessProbe:
httpGet:
path: /health
port: 8080最佳实践
- 版本化 API:MCP Server URL 带版本号 /v1/mcp,方便灰度
- 健康检查:实现 /health 和 /ready 端点
- 优雅关闭:处理完在途请求再退出
- Rate Limiting:按用户/per-tool 限流,防止 Agent 循环调用耗尽资源
- Tool 注册中心:维护一个 Tool Registry,Agent 按需发现可用工具
思考题:如果一个 MCP Server 需要访问用户的私有数据(如 Git 仓库),token 该怎么安全传递?
5. 身份认证与授权
核心挑战
传统认证是”人 → 系统”,目前变成了”人 → Agent → 工具/数据”的三方关系:
┌──────┐ 委托 ┌──────┐ 代理访问 ┌──────────┐
│ 用户 │──────────▶│ Agent │──────────────▶│ MCP Server│
└──────┘ (授权) └──────┘ (Token) └──────────┘
│
问题:Agent 应该拥有多大权限?
答案:最小权限 + 用户显式授权MCP 的 OAuth 2.1 授权框架
MCP 规范(2025-11-25)明确要求使用 OAuth 2.1 + PKCE:
┌─────────┐ ┌─────────────────┐
│MCP Client│ │ MCP Server │
│ (Agent) │ │ (Resource Server)│
└────┬─────┘ └────────┬────────┘
│ │
│ 1. 发起连接 │
│──────────────────────────────────────────────▶│
│ │
│ 2. 401 Unauthorized + Authorization Server URL │
│◀──────────────────────────────────────────────│
│ │
│ 3. OAuth Authorization Code Flow (with PKCE) │
│ ┌──────────────────────────────────────────┐ │
│ │ a. 重定向用户到授权页面 │ │
│ │ b. 用户登录并授权 │ │
│ │ c. 获取 Authorization Code │ │
│ │ d. 用 Code 换取 Access Token │ │
│ └──────────────────────────────────────────┘ │
│ │
│ 4. 携带 Bearer Token 调用 MCP │
│──────────────────────────────────────────────▶│
│ │
│ 5. 验证 Token + 返回结果 │
│◀──────────────────────────────────────────────│关键安全要求
|
要求 |
说明 |
|
PKCE 必须 |
防止授权码拦截攻击,Public Client 必须使用 |
|
Token 范围最小化 |
Scope 准确到具体 Tool(如 read:repo 而非 admin) |
|
短期 Token |
Access Token 有效期 ≤ 1h,配合 Refresh Token 轮换 |
|
动态客户端注册 |
支持 RFC 7591,Agent 可自动注册获取 client_id |
|
Token 不进 Context |
Token 绝不能出目前 LLM 的 Prompt 中! |
三种授权模式对比
|
模式 |
描述 |
适用场景 |
|
用户委托 |
用户通过 OAuth 授权 Agent 代其操作 |
Agent 代用户读写数据 |
|
服务身份 |
Agent 本身有独立的 service account |
Agent 访问公共 API/数据 |
|
即时审批 |
每次敏感操作弹窗让用户确认 |
高风险操作(删除、转账) |
生产落地提议
# Agent 工具调用的权限检查中间件
class PermissionMiddleware:
def __call__(self, tool_call: ToolCall, context: AgentContext):
# 1. 检查 Agent 是否有调用此 Tool 的基础权限
if not self.has_tool_permission(context.agent_id, tool_call.name):
raise PermissionDenied(f"Agent not authorized for {tool_call.name}")
# 2. 检查 Token Scope 是否覆盖此操作
required_scope = self.get_required_scope(tool_call)
if not context.token.has_scope(required_scope):
raise InsufficientScope(required_scope)
# 3. 高风险操作需要用户实时确认
if self.is_high_risk(tool_call):
approval = self.request_user_approval(tool_call)
if not approval:
raise UserDenied("User rejected the operation")
return self.execute(tool_call, context)思考题:Agent 的 Token 存在哪里最安全?如果 Agent 是 Multi-Tenant 的,不同用户的 Token 如何隔离?
6. Agent 质量评估
评估的难点
Agent 不是简单的 Q&A 系统,它的输出具有:
- 非确定性:同样输入可能不同输出
- 多步骤:中间步骤的质量也很重大
- 工具使用:不只看最终答案,还要看调用路径是否合理
- 长尾问题:Edge case 无穷无尽
评估维度框架
Agent 质量评估金字塔
╱╲
╱ ╲
╱ E2E╲ 端到端任务完成率
╱ Task ╲ (用户视角)
╱ Success╲
╱──────────╲
╱ Tool Use ╲ 工具选择正确率
╱ Accuracy ╲ 参数填充准确率
╱────────────────╲
╱ Reasoning Path ╲ 推理路径合理性
╱ Efficiency ╲ 步骤数是否最优
╱──────────────────────╲
╱ Safety & Guardrails ╲ 拒绝率、越权检测
╱ Latency & Cost ╲ 响应时间、Token 消耗
╱────────────────────────────╲评估方法论
|
方法 |
描述 |
优缺点 |
|
确定性 Eval |
正则匹配、准确值比对 |
快速、客观,但覆盖面窄 |
|
LLM-as-Judge |
GPT-4 等模型打分 |
灵活、覆盖广,但成本高且有偏差 |
|
Human Eval |
人工标注 + 盲评 |
金标准,但无法大规模执行 |
|
对比 Eval (A/B) |
同一 Case 对比新旧版本 |
检测回归,但需要 baseline |
|
Simulation Eval |
模拟用户交互的自动化测试 |
可大规模运行,但与真实场景有 Gap |
主流评估工具
|
工具 |
特点 |
适用场景 |
|
Maxim AI |
组件级 Eval、运行时保护 |
生产环境持续评估 |
|
Braintrust |
Prompt 版本管理 + Eval |
开发迭代期快速验证 |
|
Galileo |
自动失败检测 + 合规 |
企业级合规要求高 |
|
OpenAI Evals |
开源框架 + 社区 Benchmark |
标准化基线测试 |
|
LangSmith |
全链路追踪 + 回放 Eval |
LangChain 生态内最方便 |
构建 Eval Pipeline
# 评估 Pipeline 示例
class AgentEvalPipeline:
def __init__(self):
self.evaluators = [
TaskCompletionEvaluator(), # 任务是否完成
ToolUseEvaluator(), # 工具调用是否正确
EfficiencyEvaluator(), # 步骤数是否合理
SafetyEvaluator(), # 是否触发安全边界
CostEvaluator(), # Token 消耗是否合理
]
def evaluate(self, test_case: TestCase) -> EvalResult:
# 运行 Agent
trace = self.run_agent(test_case.input)
# 多维度评估
scores = {}
for evaluator in self.evaluators:
scores[evaluator.name] = evaluator.score(
input=test_case.input,
expected=test_case.expected,
actual=trace
)
return EvalResult(
test_case_id=test_case.id,
scores=scores,
passed=all(s >= threshold for s, threshold in scores.items()),
trace=trace # 保留执行轨迹用于调试
)
# 回归测试:每次 Prompt/模型变更自动触发
def regression_test(new_version, baseline_version, test_suite):
"""对比新旧版本的 Eval 分数,检测回归"""
new_results = [pipeline.evaluate(tc) for tc in test_suite]
old_results = load_baseline(baseline_version, test_suite)
regressions = find_regressions(new_results, old_results, threshold=0.05)
if regressions:
alert(f"检测到 {len(regressions)} 个回归 Case")
return regressions关键指标 (KPI)
|
指标 |
计算方式 |
参考基线 |
|
Task Success Rate |
完成的任务 / 总任务 |
> 85% |
|
Tool Accuracy |
正确工具调用 / 总调用 |
> 95% |
|
Avg Steps |
平均步骤数 |
越少越好 |
|
Avg Latency (E2E) |
从输入到最终输出 |
< 30s |
|
Cost per Task |
Token 消耗 × 单价 |
持续下降 |
|
Safety Violation Rate |
安全违规 / 总请求 |
< 0.1% |
思考题:LLM-as-Judge 评估时,Judge 本身可能有 bias(偏好长回答、偏好特定格式),怎么缓解?
7. 可观测性设计
为什么 Agent 的可观测性特别重大?
传统应用:确定性,给定输入 → 固定输出,报错有 stack trace。 Agent 应用:非确定性,同样输入可能不同路径,”失败”往往无报错只是”结果不好”。
Agent 的可观测性不只是监控,更是改善的反馈循环:
Telemetry ──▶ Monitoring ──▶ Alerting ──▶ Debugging
│ │
└──────▶ Evaluation ──▶ Improvement ◀────┘
(反馈循环)OpenTelemetry GenAI 语义规范
OpenTelemetry 社区在 2025 年建立了 AI Agent 的标准语义规范:
三大支柱映射到 Agent:
|
Pillar |
Agent 场景下的含义 |
|
Traces |
Agent 的完整推理链:用户输入 → 推理 → 工具调用 → 子 Agent → 最终输出 |
|
Metrics |
Token 使用量、延迟分布、工具调用成功率、缓存命中率 |
|
Logs |
LLM 的 Prompt/Completion、中间推理过程、错误详情 |
Agent Trace 的 Span 层级
[Agent Span] user_query="帮我分析这个 PR" total_duration=12.3s
│
├── [LLM Span] model=gpt-4o tokens_in=1200 tokens_out=350 duration=2.1s
│ └── (Planning: 决定需要获取 PR 信息)
│
├── [Tool Span] tool=github.get_pr status=success duration=0.8s
│
├── [LLM Span] model=gpt-4o tokens_in=3500 tokens_out=800 duration=4.2s
│ └── (Reasoning: 分析代码变更)
│
├── [Tool Span] tool=github.get_diff status=success duration=1.1s
│
└── [LLM Span] model=gpt-4o tokens_in=5000 tokens_out=1200 duration=4.1s
└── (Generation: 生成分析报告)可观测性工具链对比
|
工具 |
定位 |
开源 |
OTel 兼容 |
特色 |
|
Langfuse |
LLM 可观测 |
✅ |
✅ |
开源自建、评估集成 |
|
LangSmith |
LangChain 生态 |
❌ |
部分 |
与 LangChain 深度集成 |
|
Arize Phoenix |
ML 可观测 |
✅ |
✅ |
从传统 ML 演进,数据分析强 |
|
Braintrust |
Eval + 可观测 |
❌ |
✅ |
Prompt 版本管理优秀 |
|
Helicone |
代理层监控 |
✅ |
❌ |
零代码、网关模式 |
落地实践:关键 Metrics 看板
# 基于 OpenTelemetry 的 Agent 埋点
from opentelemetry import trace, metrics
tracer = trace.get_tracer("agent-service")
meter = metrics.get_meter("agent-service")
# 核心指标
token_counter = meter.create_counter("agent.tokens.total")
latency_histogram = meter.create_histogram("agent.latency")
tool_call_counter = meter.create_counter("agent.tool_calls")
error_counter = meter.create_counter("agent.errors")
async def handle_agent_request(request):
with tracer.start_as_current_span("agent.run") as span:
span.set_attribute("agent.user_id", request.user_id)
span.set_attribute("agent.input_length", len(request.input))
start = time.time()
try:
result = await agent.run(request.input)
# 记录指标
token_counter.add(result.total_tokens, {"model": result.model})
latency_histogram.record(time.time() - start)
tool_call_counter.add(len(result.tool_calls))
span.set_attribute("agent.output_length", len(result.output))
span.set_attribute("agent.steps", result.step_count)
return result
except Exception as e:
error_counter.add(1, {"error_type": type(e).__name__})
span.record_exception(e)
raise生产告警规则
|
告警条件 |
级别 |
动作 |
|
P95 延迟 > 30s |
Warning |
检查模型响应/工具超时 |
|
工具调用错误率 > 5% |
Critical |
检查工具服务健康 |
|
Token 用量突增 50% |
Warning |
检查是否有循环调用 |
|
安全违规 > 0 |
Critical |
立即人工介入 |
|
任务完成率 < 80% |
Warning |
触发 Eval 回归测试 |
思考题:Agent 的”失败”往往不是异常而是”回答质量差”,怎么设计告警来捕获这类软失败?
8. 隐私与安全
Agent 系统的威胁模型
攻击面
┌──────────────────────────┐
│ │
┌────▼────┐ ┌────────┐ ┌─────▼─────┐
│ Prompt │ │ 数据 │ │ 工具调用 │
│ Injection│ │ 泄露 │ │ 滥用 │
└────┬────┘ └────┬───┘ └─────┬─────┘
│ │ │
▼ ▼ ▼
·Jailbreak ·PII暴露 ·未授权操作
·间接注入 ·训练数据 ·资源耗尽
·角色劫持 ·记忆泄露 ·供应链攻击OWASP Top 10 for LLM Applications (2025)
|
# |
风险 |
Agent 场景下的表现 |
|
1 |
Prompt Injection |
间接注入:恶意网页/文档中嵌入指令劫持 Agent |
|
2 |
Sensitive Information Disclosure |
Agent 将 Token、PII 回显给用户或写入日志 |
|
3 |
Supply Chain |
恶意 MCP Server / 被投毒的 Tool |
|
4 |
Data and Model Poisoning |
Agent 记忆被注入虚假信息 |
|
5 |
Improper Output Handling |
Agent 输出未经过滤直接执行(如 SQL) |
|
6 |
Excessive Agency |
Agent 被赋予过高权限,做了不该做的事 |
|
7 |
System Prompt Leakage |
攻击者套出 System Prompt |
|
8 |
Vector and Embedding Weaknesses |
RAG 检索被操控返回恶意内容 |
|
9 |
Misinformation |
Agent 自信地编造错误信息 |
|
10 |
Unbounded Consumption |
无限循环消耗 Token/API |
纵深防御架构
┌─────────────────────────────────────────────────────────────┐
│ Layer 1: Input Guardrails │
│ • Prompt Injection 检测 (分类器/规则) │
│ • PII 自动脱敏 (姓名、身份证、手机号) │
│ • 输入长度/格式校验 │
├─────────────────────────────────────────────────────────────┤
│ Layer 2: Execution Guardrails │
│ • Tool 调用白名单 + 权限校验 │
│ • 循环调用检测 + 最大步骤数限制 │
│ • 沙盒隔离执行 │
├─────────────────────────────────────────────────────────────┤
│ Layer 3: Output Guardrails │
│ • 输出内容审核 (毒性/偏见/合规) │
│ • PII/Secret 扫描 (防止 Agent 回显敏感信息) │
│ • 结构化输出校验 (Schema Validation) │
├─────────────────────────────────────────────────────────────┤
│ Layer 4: Audit & Compliance │
│ • 全链路审计日志 (谁、什么时间、做了什么) │
│ • 数据留存策略 (GDPR Right to Erasure) │
│ • 定期安全评估 (Red Team Testing) │
└─────────────────────────────────────────────────────────────┘核心安全措施代码示例
# Prompt Injection 检测
class PromptInjectionDetector:
def __init__(self):
self.classifier = load_model("prompt-injection-detector-v2")
self.rules = [
r"ignore (previous|all|above) instructions",
r"you are now",
r"system prompt",
r"<|im_start|>", # 特殊标记注入
]
def detect(self, user_input: str) -> tuple[bool, float]:
# 规则匹配(快速)
for pattern in self.rules:
if re.search(pattern, user_input, re.IGNORECASE):
return True, 1.0
# 模型分类(准确)
score = self.classifier.predict(user_input)
return score > 0.85, score
# PII 过滤器
class PIIFilter:
"""输入输出双向过滤"""
PATTERNS = {
"phone": r"1[3-9]d{9}",
"id_card": r"d{17}[dX]",
"email": r"[w.-]+@[w.-]+.w+",
"credit_card": r"d{4}[s-]?d{4}[s-]?d{4}[s-]?d{4}",
}
def mask(self, text: str) -> str:
for pii_type, pattern in self.PATTERNS.items():
text = re.sub(pattern, f"[{pii_type.upper()}_MASKED]", text)
return text
# 工具调用安全检查
class ToolCallGuard:
def check(self, tool_call, context):
# 1. 白名单检查
if tool_call.name not in context.allowed_tools:
raise SecurityViolation("Tool not in allowlist")
# 2. 循环检测
if self.detect_loop(tool_call, context.history):
raise SecurityViolation("Potential infinite loop detected")
# 3. 参数中的敏感数据检查
if self.contains_secrets(tool_call.arguments):
raise SecurityViolation("Secrets detected in tool arguments")隐私设计原则 (Privacy by Design)
- 数据最小化:Agent 只获取完成任务必需的数据
- 目的限制:记忆中的信息不得用于训练或共享
- 存储时限:设置记忆的 TTL,过期自动清除
- 用户控制:提供”查看我的记忆”和”删除我的数据”入口
- 审计透明:用户可查看 Agent 访问了哪些数据
思考题:如果 Agent 的记忆中存了用户 A 的偏好,Agent 为用户 B 服务时不小心引用了用户 A 的数据,这算不算数据泄露?怎么防止?
9. 总结与讨论
核心 Takeaway
- 沙盒是生产 Agent 的底线 — 不隔离 = 裸奔,推荐 Firecracker MicroVM 级别隔离
- 记忆让 Agent 从”工具”变成”伙伴” — 分层设计(短期/情景/语义/程序性),Mem0 是当前最佳实践
- MCP 是工具连接的标准答案 — 云端部署解决共享、扩展、管理问题,2025-11 规范已生产就绪
- OAuth 2.1 + PKCE 是 Agent 认证的正解 — Token 永远不进 LLM Context,最小权限 + 即时审批
- 评估是持续工程 — 不是上线前做一次,而是持续回归,LLM-as-Judge + 确定性检查互补
- 可观测性 = 改善的基础设施 — OpenTelemetry GenAI SIG 标准化中,Trace 是核心
- 安全要纵深防御 — 输入/执行/输出/审计四层 Guardrails,没有银弹
技术选型决策树
你的 Agent 需要执行代码?
├── 是 ──▶ 需要沙盒(E2B/Modal/K8s+gVisor)
└── 否 ──▶ 仅需工具调用权限控制
你的 Agent 需要跨会话记忆?
├── 是 ──▶ Mem0 / 自建分层记忆(推荐 pgvector + Redis)
└── 否 ──▶ Context Window 管理即可
你的 Agent 需要对接多种外部工具?
├── 是 ──▶ MCP 协议 + Tool Registry
└── 否 ──▶ 简单 Function Calling
你是多租户 SaaS?
├── 是 ──▶ 完整 OAuth 2.1 + 租户隔离 + 审计
└── 否 ──▶ API Key + 基础鉴权开放讨论
- 成本控制:Agent 动辄消耗数万 Token,如何在质量和成本之间找到平衡?
- 可靠性:Agent 偶尔”犯傻”是可接受的吗?不同场景的容错阈值是多少?
- 合规:如果 Agent 做出了错误决策导致损失,责任归属是谁?
- 团队落地:我们最适合先从哪个子系统开始建设?
参考资料
官方文档与规范
- Model Context Protocol Specification (2025-11-25)
- MCP Authorization Spec
- OpenTelemetry GenAI Semantic Conventions
- OpenAI Practices for Governing Agentic AI Systems
论文与白皮书
- Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory (2025)
- Memory Architectures in Long-Term AI Agents (2025)
- Agentic AI: Architectures, Taxonomies, and Design Patterns (2026)
- Evaluation and Benchmarking of LLM Agents: A Survey (2025)
工具与框架
- E2B – Open-source AI Sandbox
- Modal Sandboxes
- Mem0 – Memory Layer for AI
- Langfuse – Open-source LLM Observability
- Maxim AI – Agent Evaluation Platform
社区与最佳实践
- OpenTelemetry AI Agent Observability Blog (2025)
- Anthropic: Building Effective Agents
- OWASP Top 10 for LLM Applications
Awesome Sandbox – Code Sandboxing for AI
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...










