
4 月 2 日凌晨,谷歌放了一个大招。
他们发布了新一代开源模型 Gemma 4,直接把许可证从之前的自定义协议换成了 Apache 2.0——这意味着企业可以拿去商用,不用再担心谷歌哪天改条款。推特上的反应很说明问题:一条中文推文拿到了 1700+ 点赞和 300+ 转发,核心观点只有一个——推理成本被压到接近于零,API 收费模式要被颠覆了。
但情绪之外,Gemma 4 到底带来了什么?我花了两天时间把官方文档和社区反馈都过了一遍,下面是干货。
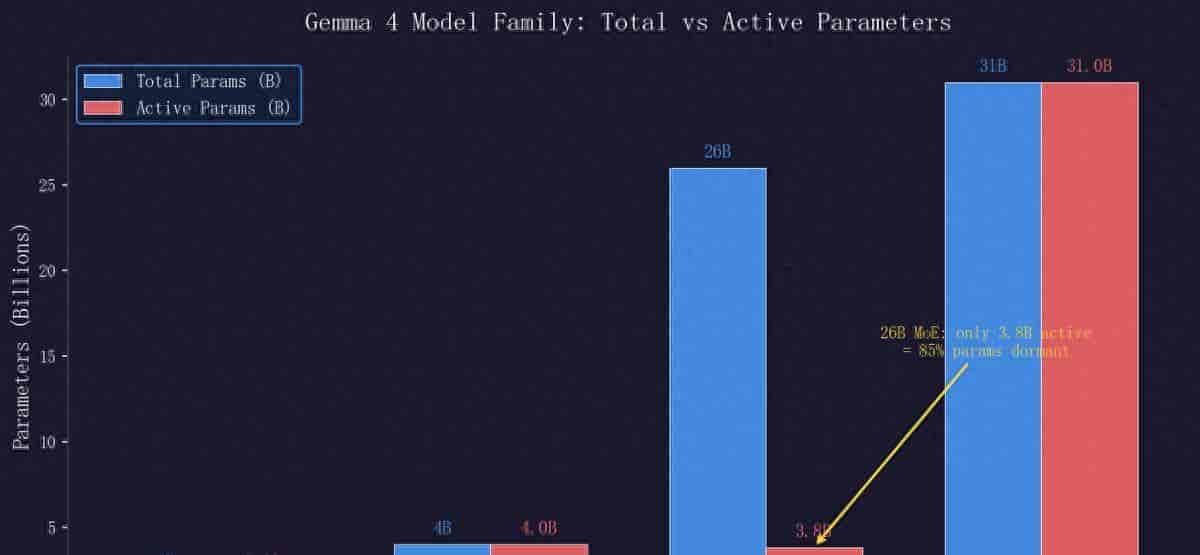
四个尺寸,覆盖从手机到工作站
Gemma 4 这次一口气发了四个版本,策略超级清晰:不同硬件用不同模型,不搞一个巨无霸打天下。
|
模型 |
参数规模 |
推理时激活参数 |
适用硬件 |
Arena AI 排名 |
|
31B Dense |
310 亿 |
310 亿 |
80GB GPU / 量化后消费级显卡 |
全球 #3 (1452 Elo) |
|
26B MoE |
260 亿 |
38 亿 |
消费级 GPU |
全球 #6 (1441 Elo) |
|
E4B |
– |
40 亿 |
手机 / 树莓派 |
– |
|
E2B |
– |
20 亿 |
手机 / IoT 设备 |
– |
几个关键数字值得细看。
31B Dense 在 Arena AI 文本排行榜上排第三,Elo 评分 1452。排在它前面的模型参数量动辄是它的 10 到 20 倍。换句话说,谷歌用 310 亿参数做到了别人用几千亿参数才能做到的事情。这个”智能密度”的突破不是渐进式的,而是跨越式的。
26B MoE 更有意思。总参数量 260 亿,但推理时只激活其中 128 个专家里的一部分,实际运算量只相当于 38 亿参数。这意味着响应速度极快,tokens/s 明显优于同级别的 Dense 模型,适合需要低延迟的 Agent 场景。
Benchmark 暴涨:不是小幅提升,是质变
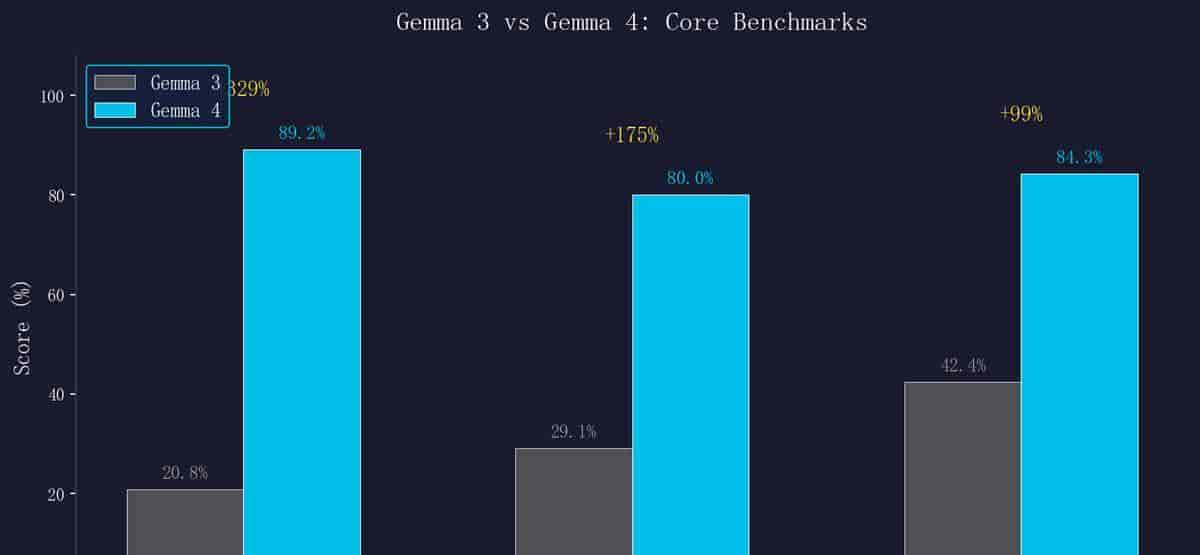
跟上一代 Gemma 3 相比,Gemma 4 在核心 benchmark 上的提升幅度接近疯狂:
|
评测项 |
Gemma 3 |
Gemma 4 |
提升幅度 |
|
AIME 2026 (数学) |
20.8% |
89.2% |
+329% |
|
LiveCodeBench (编程) |
29.1% |
80.0% |
+175% |
|
GPQA (科学推理) |
42.4% |
84.3% |
+99% |
数学能力从 20.8% 跳到 89.2%,这不是调参调出来的微调改善,而是底层能力的根本性提升。LiveCodeBench 编程能力从 29.1% 到 80.0%,意味着 Gemma 4 已经具备了实用级别的代码生成能力,能真正充当本地代码助手。
这些提升来自 Gemma 4 与 Gemini 3 共享的研究基础。谷歌 DeepMind 团队在架构上做了几个关键创新:
**交替注意力机制**——模型层级交替使用局部滑动窗口注意力(512-1024 tokens)和全局全上下文注意力,兼顾效率和长距离理解能力。
**双重 RoPE 位置编码**——滑动窗口层用标准 RoPE,全局层用比例 RoPE,这个设计让大模型支持 256K 上下文窗口,小模型也能做到 128K。
256K 上下文什么概念?大约相当于一本 300 页的技术书,或者一个中等规模的代码仓库。一次性扔进去让模型理解全部内容,不用再切分上下文窗口。
iPhone 上 3 分钟跑起来:AI Edge Gallery 实测
推特上最火的讨论不是 benchmark 数字,而是一件更接地气的事——Gemma 4 能在 iPhone 上直接跑。
一条获得 2000 点赞的推文是这么说的:
“iPhone 上使用 Gemma-4 大模型,很简单。App Store 上下载 Google AI Edge Gallery,打开软件点击 Agent Skills,下载相应模型,大致 3G 左右,下载完就可以使用了,支持中文。”
我按这个步骤试了一下,的确 如此。整个过程:
App Store 搜索 “Google AI Edge Gallery” 下载安装
打开 App,点击 Agent Skills
选择 Gemma 4 模型(E2B 或 E4B),下载大约 3GB
下载完成直接开聊,完全离线,不需要网络
这里有几个重大细节。模型跑在手机芯片上,推理全程离线,你的对话数据不会经过任何服务器。对于在意隐私的用户来说,这是一个质的改变——以前用 ChatGPT、Claude 或者 Gemini,所有对话都要上传到云端处理。目前有了一个真正的本地替代方案。
谷歌跟 Pixel 团队、高通和联发科深度合作,对 E2B 和 E4B 模型做了专门的硬件级优化。这两个模型不仅能在 iPhone 和 Android 手机上跑,还支持树莓派和 NVIDIA Jetson Orin Nano 这类边缘设备。
而且这两个小模型不只是能聊天——它们支持原生视觉和音频输入。你可以拍张照片让模型分析,或者直接语音对话。这在以前是只有云端大模型才有的能力。
Apache 2.0:开源界等了很久的一步
前几代 Gemma 虽然号称”开源”,但用的是谷歌自定义许可证,里面有不少限制条款。企业法务团队看完一般的反应是”再等等”。
Gemma 4 切换到 Apache 2.0,这是开源界最主流的商业友善许可证之一。它意味着:
可以免费商用,不需要向谷歌付费或报备
可以修改模型并分发修改后的版本
可以用来构建闭源商业产品
不会有哪天醒来发现许可条款变了的风险
Hugging Face CEO Clement Delangue 在官方博客中评价:”Gemma 4 在 Apache 2.0 下发布是一个巨大的里程碑。”
这句话的含义很直白——之前 Gemma 系列虽然性能不错,但许可证问题让许多企业止步。目前这个障碍彻底消除了。
对 API 收费模式的冲击有多大?
推特上讨论最热烈的话题是 Gemma 4 对 OpenAI、Anthropic 等 API 按量计费模式的冲击。
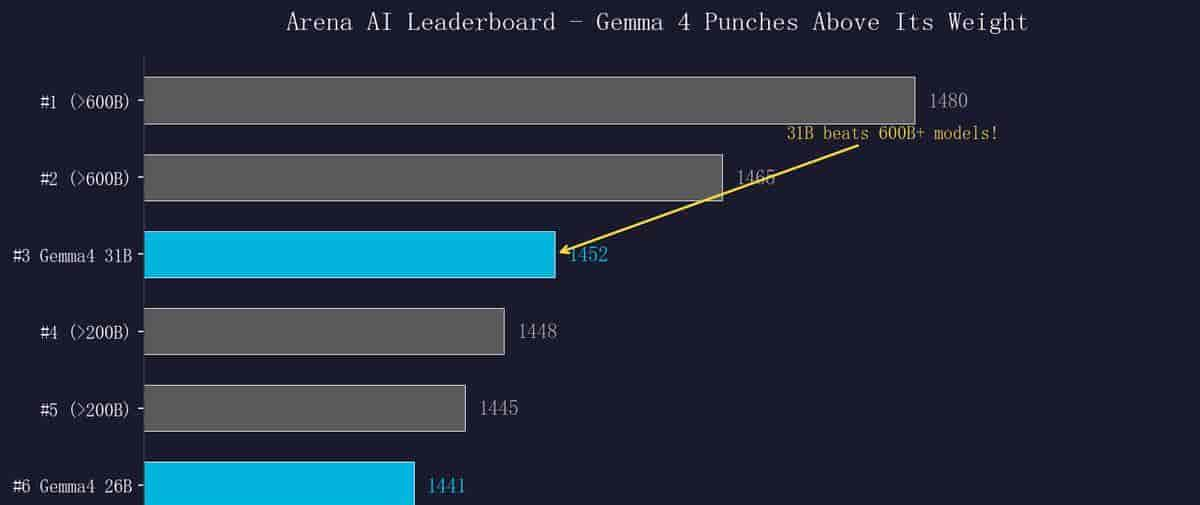
逻辑很简单:当一个性能足够强的模型可以在本地免费运行时,为什么还要为每次 API 调用付费?
但实际情况比这复杂。Gemma 4 31B 的确 强,但它毕竟只是 310 亿参数的模型。在复杂的长链推理、多轮对话一致性、以及处理高度模糊指令等场景下,跟 GPT-4o、Claude Opus 这类旗舰模型还是有差距的。
更现实的影响可能是:
**高频、低复杂度的 AI 调用会大量转移到本地。** 代码补全、文档摘要、格式转换、简单问答——这类任务占了 AI API 调用量的大头,但对模型能力的要求并不高。Gemma 4 的 26B MoE 模型只激活 38 亿参数就能处理这些场景,而且完全免费。
**Agent 工作流的成本结构会改变。** 一个 AI Agent 在执行复杂任务时,可能需要做几十上百次的工具调用和中间推理。如果每次都走云端 API,费用会迅速累积。本地部署 Gemma 4 作为 Agent 的执行引擎,只在需要顶级推理能力时才调用云端大模型,这种混合架构会成为主流。
**开发者的实验成本降到零。** 以前想测试一个 AI 功能的原型,哪怕只是验证可行性,也要先充值 API 余额。目前用 Gemma 4 本地跑就行,想怎么折腾怎么折腾。
生态系统:开箱即用不是空话
Gemma 4 在发布第一天就支持了超过十几个主流推理框架:
**本地推理**:Ollama、llama.cpp、MLX、LM Studio
**服务器部署**:vLLM、SGLang、NVIDIA NIM
**训练微调**:Hugging Face Transformers/TRL、Keras、Unsloth
**模型下载**:Hugging Face、Kaggle、Ollama
如果你用 Mac,直接 `ollama run gemma4` 就能开始;Windows 上也差不多。这种即开即用的体验,跟两年前跑开源模型要折腾半天 CUDA 环境的状况完全不同。
谷歌还在 Google AI Studio 上提供了 31B 和 26B MoE 的在线试用,想先体验效果再决定是否本地部署也完全可以。
Gemmaverse 的规模效应
谷歌在博客中提到了一个数据:自第一代 Gemma 发布以来,开发者累计下载超过 4 亿次,社区创建了超过 10 万个变体模型。
10 万个变体意味着什么?意味着针对各种垂直场景——医疗、法律、金融、教育、多语言——都已经有人基于 Gemma 做了专门的微调版本。Gemma 4 的 Apache 2.0 许可证会进一步加速这个飞轮。
对于普通开发者来说,你不需要从头训练。找一个社区里针对你场景微调过的 Gemma 4 变体,下载下来本地跑就行。
谁应该关注 Gemma 4?
**独立开发者和小团队**——API 费用一直是约束。Gemma 4 让你在零边际成本下构建 AI 功能,不需要担心用量爆炸带来的账单。
**注重隐私的企业**——医疗、金融、法律等行业对数据出境超级敏感。本地部署意味着数据永远不离开你的服务器。
**边缘设备开发者**——IoT、嵌入式、移动端。E2B 和 E4B 模型专门为低功耗场景优化,这是之前开源模型很少覆盖的领域。
**AI Agent 构建者**——Gemma 4 原生支持函数调用和结构化 JSON 输出,可以直接作为 Agent 的推理引擎,不用再套一层 LangChain 之类的中间件做格式适配。
—
谷歌这次的策略很清晰:不再追求用一个最大的模型碾压一切,而是用一个完整的模型家族覆盖所有部署场景,再用 Apache 2.0 许可证消除一切商用顾虑。
从手机到工作站,从边缘设备到云端集群,4 个模型、一套许可证、全场景覆盖。
这可能是开源 AI 领域 2026 年最重大的一次发布。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











