
目前AI Agent越来越像能落地干活的数字员工,从调API到写报表都能完成,但没人敢拍胸脯说:它真的按要求做成了这件事吗?我们目前用来测能力的题库,还能代表今天企业最痛的需求吗?
以往只看结果的评测,正在系统性高估AI Agent的实际能力;而固定不变的题库,早已经跟不上真实工作流的迭代速度。当评测的底层逻辑都已经改变,AI Agent的落地进程会被怎样改写?
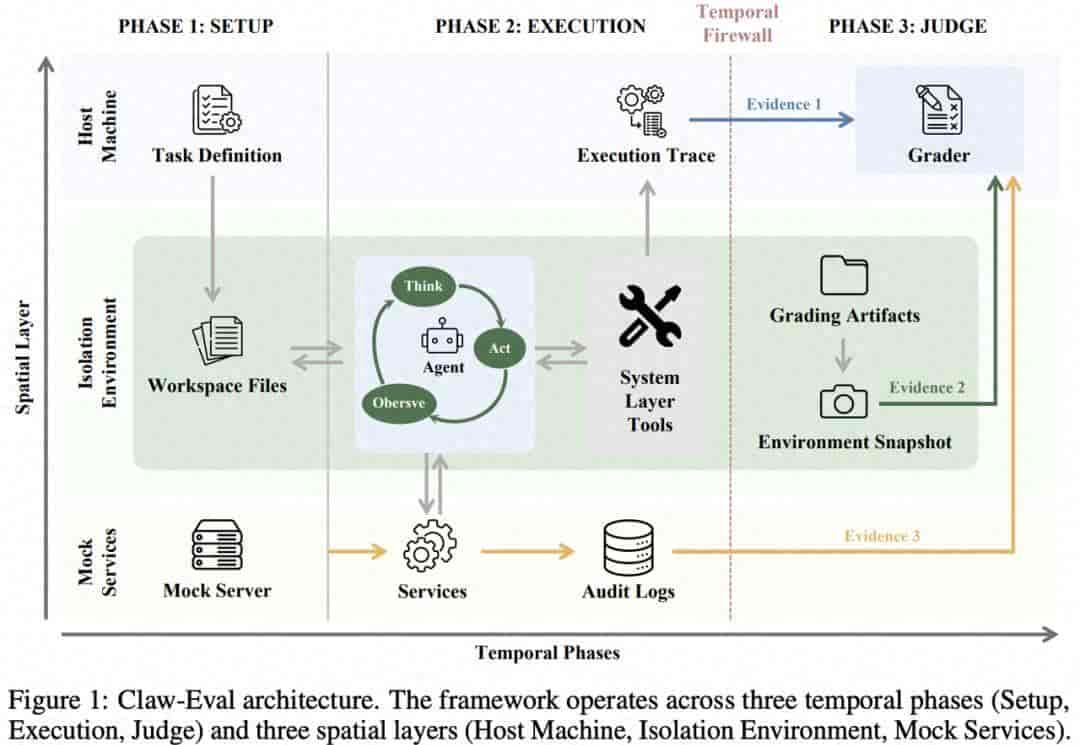
Claw-Eval架构图 / 展示Claw-Eval的三阶段三层架构及证据链
只看结果的评测,为什么必定会「放水」?
绝大多数现有的AI Agent评测,遵循的都是超级传统的逻辑:给一个任务,看最终输出,匹配参考答案判断对错。输出符合预期就算任务完成,反之就是失败。
可对需要真实执行操作的AI Agent来说,这套逻辑藏着两个致命的漏洞,之前没人真正系统性解决。
第一个漏洞,就是只看结果不看过程,给了模型「走捷径」的空间。模型可以编出一个看起来完全正确的答案,但它根本没有调用要求的API,也没有去对应数据库拉取真实数据,本质上就是「瞎猫碰上死耗子」。
第二个漏洞,是完全不反映真实部署的要求。一个能落地的Agent不仅要把活干完,还要能在API超时、服务报错的异常环境里稳定运行,还要避免做出越权操作这类危险行为。这些要求,只看结果根本测不出来。
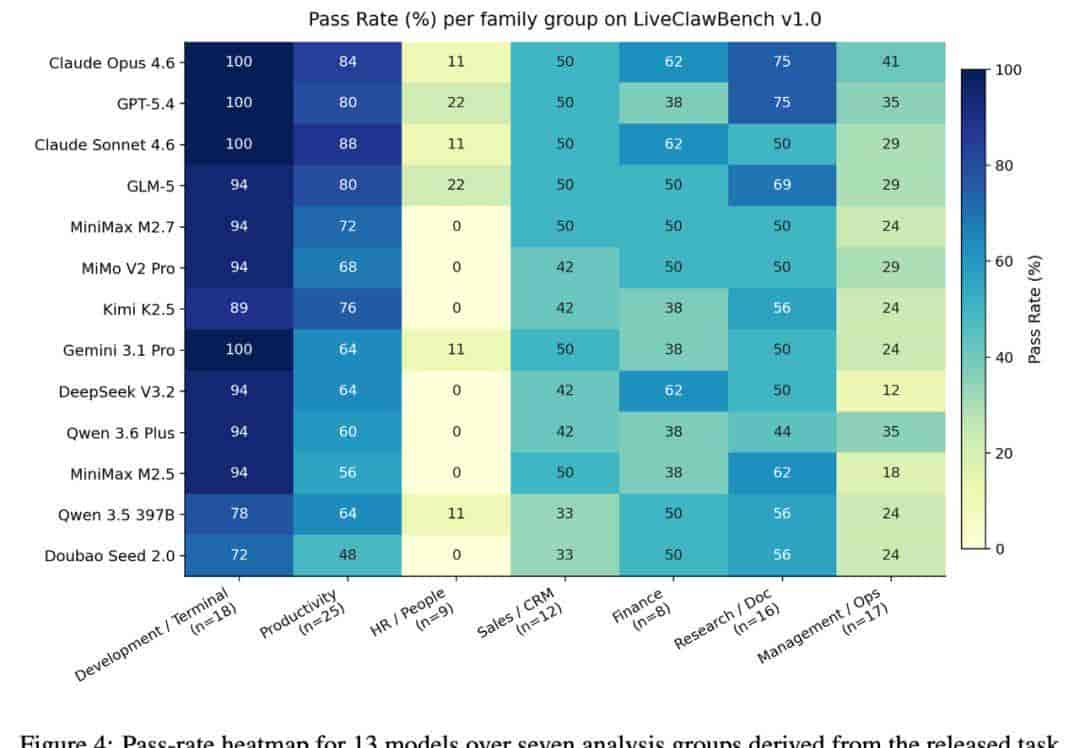
模型任务家族通过率热力图 / 13个模型在7类任务家族的通过率热力分布
Claw-Eval做的第一件事,就是把评测从「只看答案」推进到了「看完整执行过程」。它的核心思路超级直接:让Agent的每一步执行都变成可审计的证据。
整套评测在隔离环境里运行,分为环境搭建、执行、打分三个阶段,Agent运行时拿不到任何评分脚本和参考答案。最终打分不仅看输出,还要结合三条独立证据链:执行轨迹、服务端审计日志、执行后的环境快照。
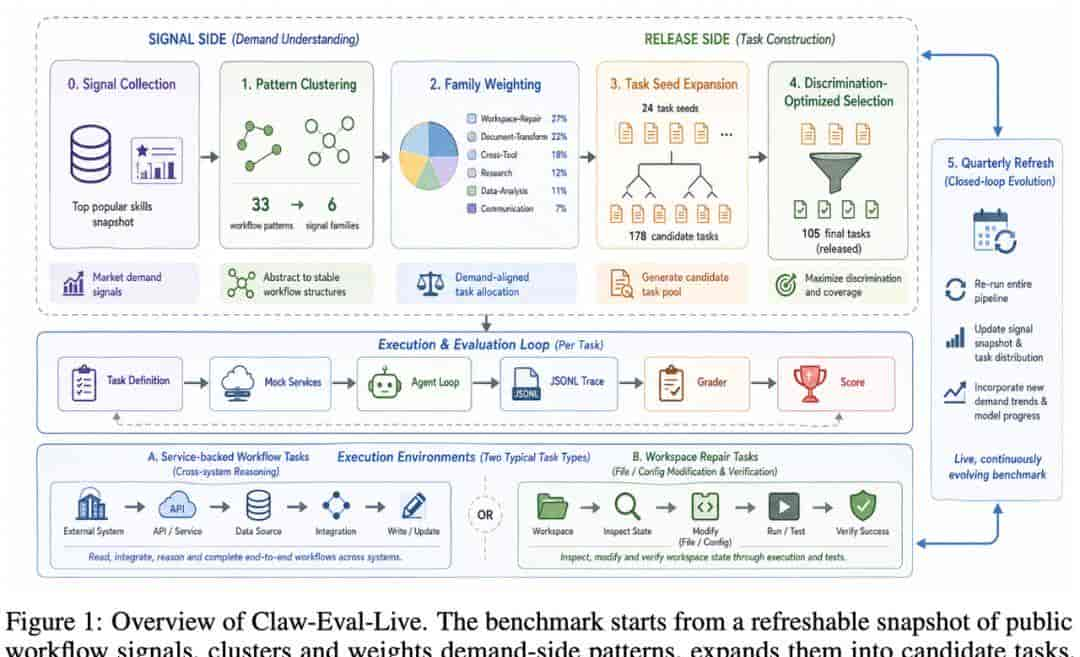
Claw-Eval-Live整体流程图 / 呈现Claw-Eval-Live的任务构建与执行流程
Claw-Eval的对照实验结果超级扎心:只拿对话记录和评分脚本,缺了服务端日志和环境快照的话,会漏掉44%的安全违规和13%的鲁棒性问题。也就是说,只看结果的评测,必定会系统性高估AI Agent的真实能力。
只要评测不看过程,你就永远没法确定,Agent是真的做成了事,还是只是编了个对的答案。
固定的benchmark,为什么必定会过时?
Claw-Eval解决了「怎么评得准」的问题,但它和所有传统benchmark一样,逃不开另一个更本质的问题:任务从发布那天起就固定了,不管外面的世界怎么变,题库都不会跟着变。
在NLP的传统任务里,列如翻译、问答,这个问题并不突出,任务形态本身变化很慢。可到了AI Agent这里,问题被急剧放大了——Agent面对的是具体的企业工作流,而工作流一直在变。
工具栈半年就迭代一次,企业的痛点从日报自动化变成了跨系统对账,新的自动化场景从无到有,旧的核心场景慢慢变成边缘。一套固定的题库,发布半年之后,测的就已经不是今天企业最关心的问题了。
这种过时不是某一道题不能用了,而是任务的分布比例已经偏离了当下真实的需求结构。Claw-Eval-Live要解决的,就是这个没人碰过的新问题:怎么让benchmark一直跟着真实需求走,同时还能保持评测的可复现性。

Claw-Eval-Live论文标题页 / 显示Claw-Eval-Live论文标题、作者及相关信息
Claw-Eval-Live给出的答案,是做「活的benchmark」,核心是两层分离的创新设计:信号层负责捕捉真实需求,发布层输出固定可复现的快照。
信号层不会靠团队拍脑袋决定要测什么,而是从ClawHub的Top500热门技能这类公开的需求信号出发,分析当下哪些工作流是用户最关心的。发布层则把每次分析的结果做成带时间戳的固定任务包,所有定义、环境、脚本全部锁定,模型之间依然可以稳定比较,完全满足学术可复现的要求。
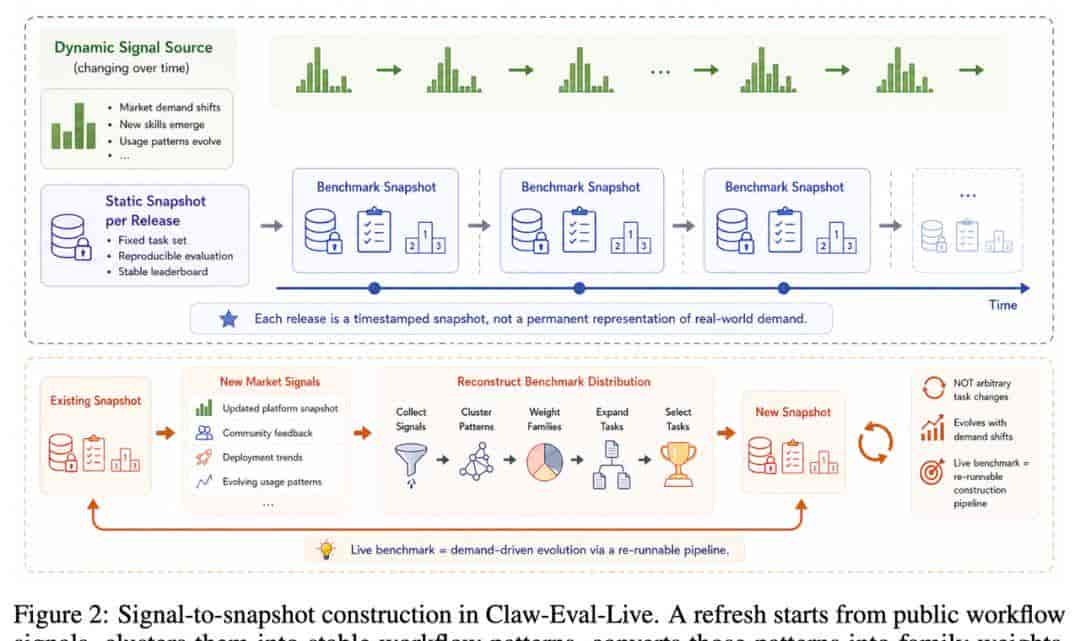
信号到快照构建流程图 / 展示Claw-Eval-Live从信号到快照的迭代过程
从信号采集到最终发布,整个流程分成五步:先抓取热门技能的时间戳快照,再把碎片化技能聚合成稳定的工作流模式,根据需求热度给不同任务家族分配权重,然后生成可执行候选并筛选出能拉开差距的题目,最后用混合整数线性规划选出最优的任务组合。
它不是让benchmark天天变,而是让每一次发布都成为当下真实需求的一张切片。既解决了题库过时的问题,又保住了评测可复现的核心要求。
贴近真实需求后,我们看到了什么反常识结论?
当评测终于对准真实工作流,13个前沿模型跑出来的结果,颠覆了许多人对AI Agent的固有认知。
第一个结论,就是整体天花板依然很低,没有任何模型能突破70%的通过率,榜首到末尾的差距超过22个百分点。真实工作流自动化,还远没到可以大规模可靠部署的阶段。
有意思的是,通过率接近的模型,完成度差距可以很大。三个通过率都是53.3%的模型,整体完成度从76.9降到了74.0——许多模型不是完全不会做,而是常常差一步闭环,问题出在执行环节,不是语言能力。
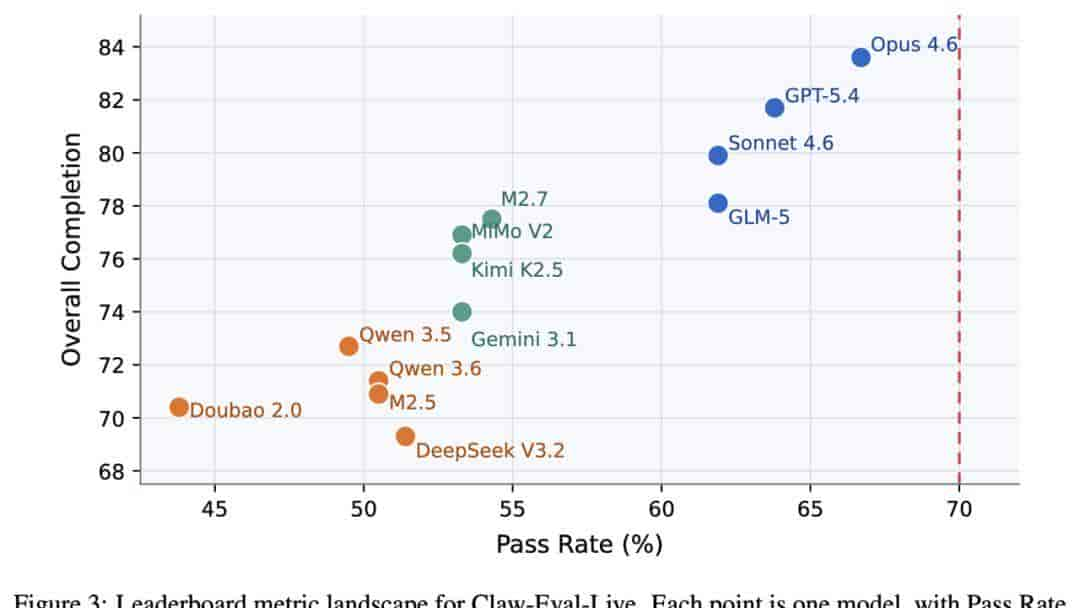
模型通过率与完成度散点图 / 13个模型的通过率与整体完成度分布
最有冲击力的,是第二个反常识结论:最难的任务,不是你以为的那些技术类任务。
所有人都觉得,终端操作、环境修复这类需要硬核操作的任务肯定最难,但评测结果恰恰相反。对头部模型来说,终端操作类任务的通过率已经达到了100%,最弱的模型也能超过72%。
真正卡脖子的,是HR、运营管理以及跨系统编排这类业务任务。HR类任务的平均通过率只有6.8%,管理类任务在公开规则下全失败,跨系统工作流平均通过率也只有12.8%。

Claw-Eval论文标题页 / 显示Claw-Eval论文标题、作者及相关信息
这意味着,当前AI Agent的核心瓶颈,已经不是会不会用终端,而是能不能在多个系统之间持续收集证据、正确关联记录,并完成必须的写操作。许多模型能写出超级通顺的入职文档,但根本没把员工信息、工具调用和证据闭环补全——它只是在「说」这件事,不是真的「做完」这件事。
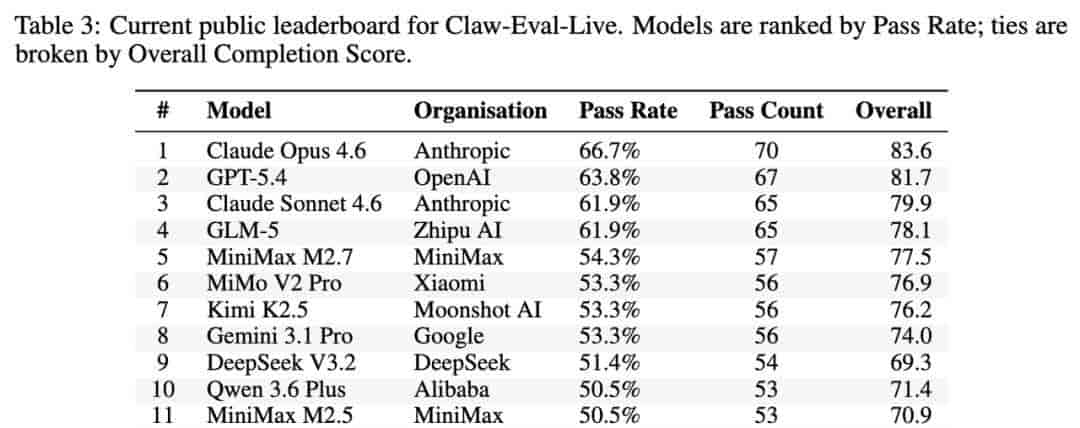
Claw-Eval-Live模型排行榜 / 13个模型的通过率、完成度等排名数据
第三个结论,成本的差异比你想象的大得多。头部的Claude Opus 4.6准确率最高,但跑完105道题估算API成本就要31.6美元;GPT-5.4只花6.3美元,拿到了第二名,通过率只低了2.9个百分点;GLM-5花了大致2.5美元,达到了和Claude Sonnet 4.6一样的通过率,成本只有Opus的不到8%。
对真正要落地Agent的企业来说,比榜单更重大的,是「特定工作流的准确率乘以单位成本」——适合自己需求的,才是最好的。
Agent评测的下半场,比的到底是什么?
从Claw-Eval到Claw-Eval-Live,这两次迭代实则把AI Agent评测的底层逻辑彻底重写了。在那之前,所有评测拼的都是「谁更会答题」,拼模型在固定题库上的分数。
目前规则变了:第一步要先能证明Agent真的做成了任务,第二步要保证评测的任务就是当下真实的需求。缺少任何一步,评测结果都可能偏离真相。
开源社区给Claw生态积累的5700多个预构建技能,实则恰恰给Claw-Eval-Live的需求信号采集提供了天然的土壤——全球数十万开发者的使用偏好,本身就是最真实的需求温度计。
过去我们聊AI Agent的进化,总说模型能力要升级、工具调用要更准,但很少有人讨论:我们到底该怎么证明Agent真的变好了?如果评测本身就不准或者过时,再好的模型也没法证明自己的价值。
Claw-Eval和Claw-Eval-Live做的这件事,本质上是给AI Agent的落地扎下了评测的根——先把评测做准,再让评测跟上真实世界,我们才能真正看清Agent的能力到底走到了哪一步。
当大模型竞争从「拼说话能力」进入「拼干活能力」的下半场,评测体系的进化,才是真正推动行业往前走的隐形动力。
今天最好的Agent也只能完成不到七成的真实业务任务,这个数字看起来让人沮丧,但实则是件好事。我们终于不用再靠案例宣传判断能力,而是能拿着真实可信的评测结果,一步步往落地推进。
毕竟对所有要用上Agent的企业来说,它们要的从来不是一个「说得好」的模型,而是一个「做得成」的帮手。这件事,从一开始就需要一把准的尺子。那目前尺子终于做对了形状,接下来的进化只会比以往更快。
#人工智能##Agent##AI妙生图##benchmark##大型语言模型LLM#
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











