RAG,全称 Retrieval-Augmented Generation,中文叫检索增强生成。简单说,就是给大模型配个“随身图书馆”,回答前先查资料、再组织语言,从根源解决AI“瞎编”(幻觉)、知识过时、不懂企业内部信息的痛点。
一、为什么需要RAG?
传统大模型像“死记硬背的学生”,训练完知识就固定了,问新问题容易编实际、说旧数据;企业内部文档、产品手册、合同这些私有数据,模型根本没见过。RAG就是开卷考试:不让模型硬记,而是允许它查指定资料再回答,既准又新。
二、RAG核心原理
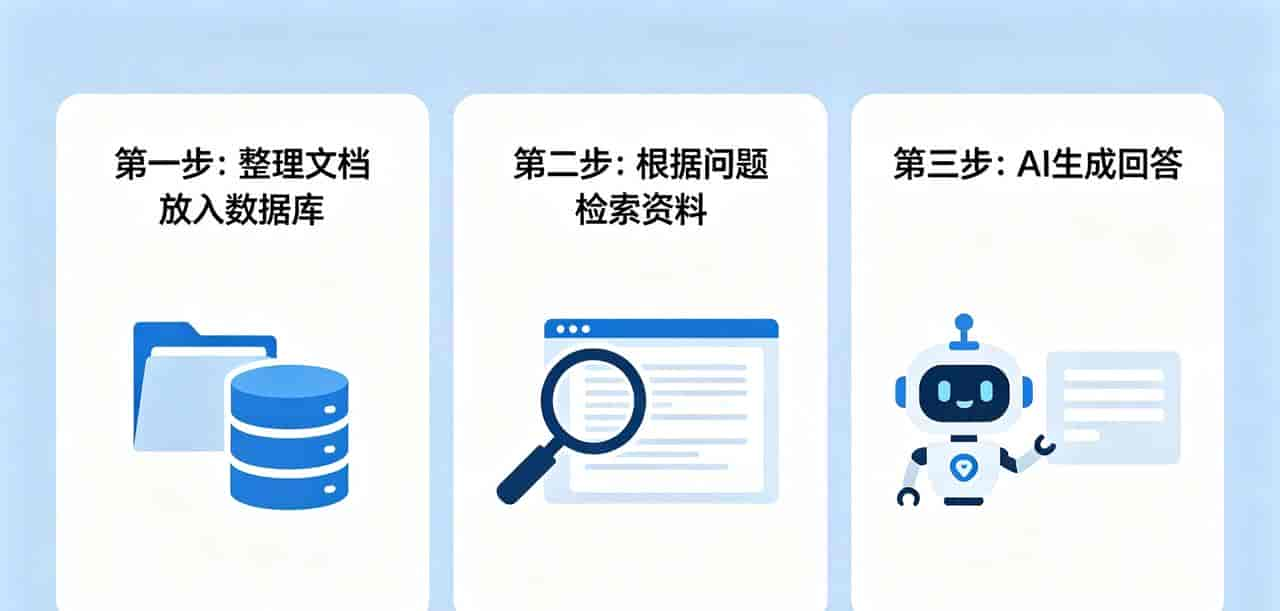
1. 第一步:建库——把资料变成“数字索引”
先把PDF、Word、网页等文档,清洗成纯文本。
再把长文切成小文本块(每块几百字),保证语义完整。
然后用嵌入模型,把每个文本块转成高维向量(一串数字),语义相近的文本,向量距离更近。
最后把向量和原文存进向量数据库,建好“快速检索索引”。这步离线做,一次建好长期用。
2. 第二步:检索——精准找到相关资料
用户提问后,系统先把问题也转成同维度向量。
向量数据库快速计算“问题向量”和“所有文本块向量”的类似度,找出最相关的Top-K片段。
再用重排序模型二次筛选,把最关键的内容排在前面。
3. 第三步:生成——基于资料写答案
把检索到的资料、用户问题,按模板拼成提示词。
交给大模型:只许用给的资料回答,不许编内容。
模型整理语言,给出准确、带来源的答案。
三、RAG好在哪?
– 更准确:杜绝幻觉,答案全有依据。
– 更实时:更新知识库就行,不用重训模型。
– 更安全:数据本地存储,保护隐私合规。
– 低成本:接入快、维护简单。
四、实际用在哪?
– 企业客服:基于产品手册回答咨询,不出错。
– 内部问答:员工查制度、技术文档,秒级响应。
– 法律医疗:检索法条、文献,辅助专业决策。
– 金融投研:查财报、政策,生成分析报告 。
五、总结
RAG不是替代大模型,而是给AI装了“知识外挂”。它把“检索”和“生成”结合,让AI从“泛泛而谈”变成“精准靠谱”。如今企业级AI应用,几乎都离不开RAG,它是大模型落地的“标配能力”,也是AI从“能用”到“好用”的关键一步。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










