
两条路径,两种逻辑,正在2026年4月这个时间节点上发生剧烈碰撞。
从技术路线的角度来看,OpenAI的GPT-6与DeepSeek的V4,选择了完全不同的登顶方式。
GPT-6走的是“性能极致化”的闭源路线。其核心是5-6万亿密集参数的“暴力美学”,以及200万Token的行业顶尖上下文窗口。它通过原生多模态架构“Symphony”,将文本、图像、音频、视频进行底层统一处理,目标是追求AGI(通用人工智能)的绝对技术壁垒。
代价是天文数字般的成本:训练动用约10万张H100 GPU,成本超20亿美元。
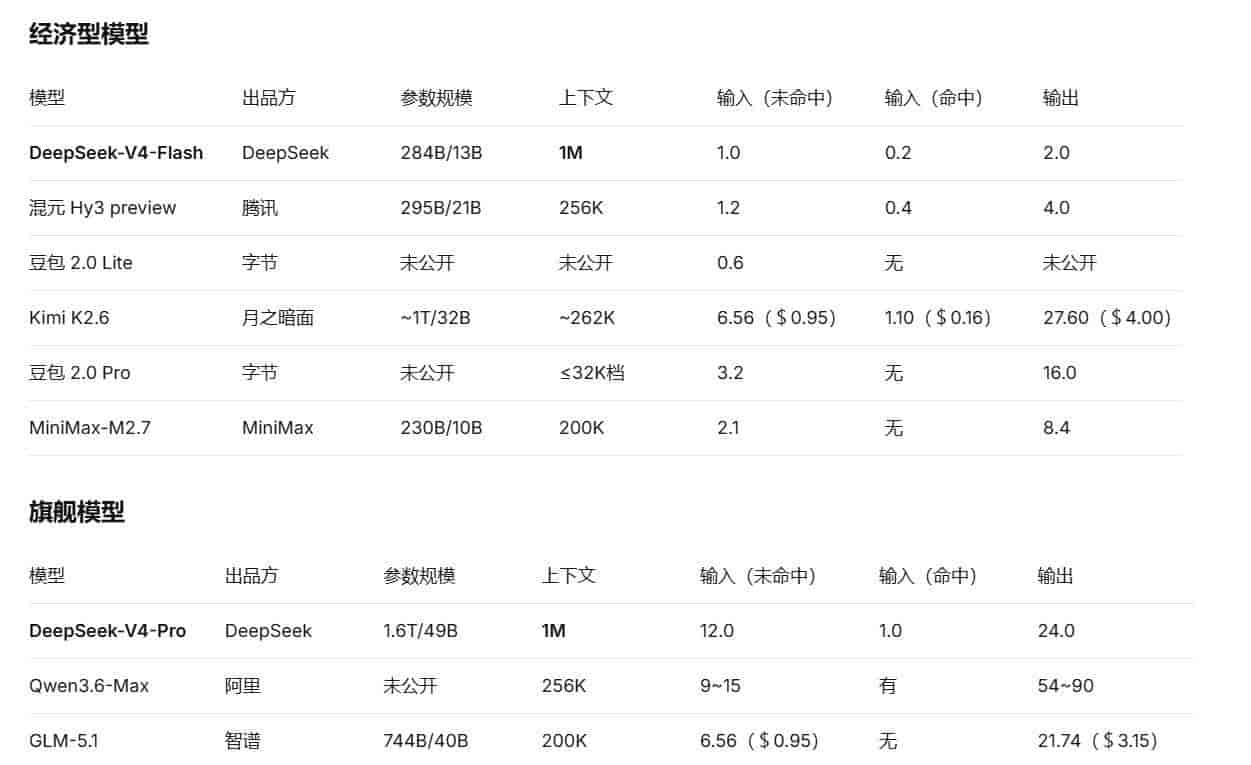
而DeepSeek V4走的是“普惠规模化”的开源路线。其核心是1.6万亿MoE(混合专家)参数的架构优化。它通过稀疏激活技术,每次推理仅激活约490亿参数,在保证知识储备的同时,将单Token推理算力消耗降至上一代的27%。

更重大的是,它首次将100万Token上下文窗口设为全系标配,把长文本处理从高端功能降维为基础设施级服务。
站在商业策略的角度,两者的分野更是泾渭分明,直接决定了谁能赢得开发者和市场。
GPT-6延续了OpenAI的高端定价策略,API定价为2.5美元/百万Token输入,旨在通过技术壁垒服务高付费能力的大型企业和科研机构。
DeepSeek V4则扮演了“价格屠夫”的角色。其V4-Flash版本,在输入缓存命中的场景下,价格低至0.02元/百万Token。这是什么概念?
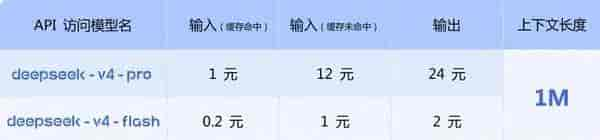
根据开发者实测数据,处理一样任务,其成本仅为海外同级别闭源模型的1/5甚至更低,与GPT-5.5相比,输入成本更是达到了惊人的1/890。这种极致的性价比,不是简单的补贴,而是基于自研稀疏注意力架构等技术突破带来的真实成本下降。
聚焦到下游产业应用,两条路径正在推动不同场景的AI革命。
GPT-6的智能体化架构,深度集成了工具调用与任务规划能力,其200万Token的上下文窗口为处理复杂、长程任务提供了基础。这使其在高端研发、复杂系统构建等前沿领域具有天然优势。
DeepSeek V4则凭借开源和低成本,正在快速渗透并重塑实体经济。一个标志性案例是深圳市南山区人民医院。从DeepSeek V4发布到完成全链路调试上线,该院仅用了9小时。
模型能够瞬间处理患者数年积累的病历与海量医学文献,覆盖30余项核心医疗应用,从被动问答工具升级为主动服务智能体。这证明了在医疗、客服、代码开发等需要规模化、低成本落地的场景,开源普惠模型拥有巨大的爆发力。
从全球AI竞赛的格局来看,这次“撞车”发布,标志着一个新时代的开启。
最核心的变化是中美技术差距的实质性弥合。斯坦福2026 AI指数报告指出,中美顶级AI模型的性能差距已不足3%。在Codeforces编程天梯榜上,DeepSeek V4-Pro排名第23位,与GPT-5.4实战性能相当。
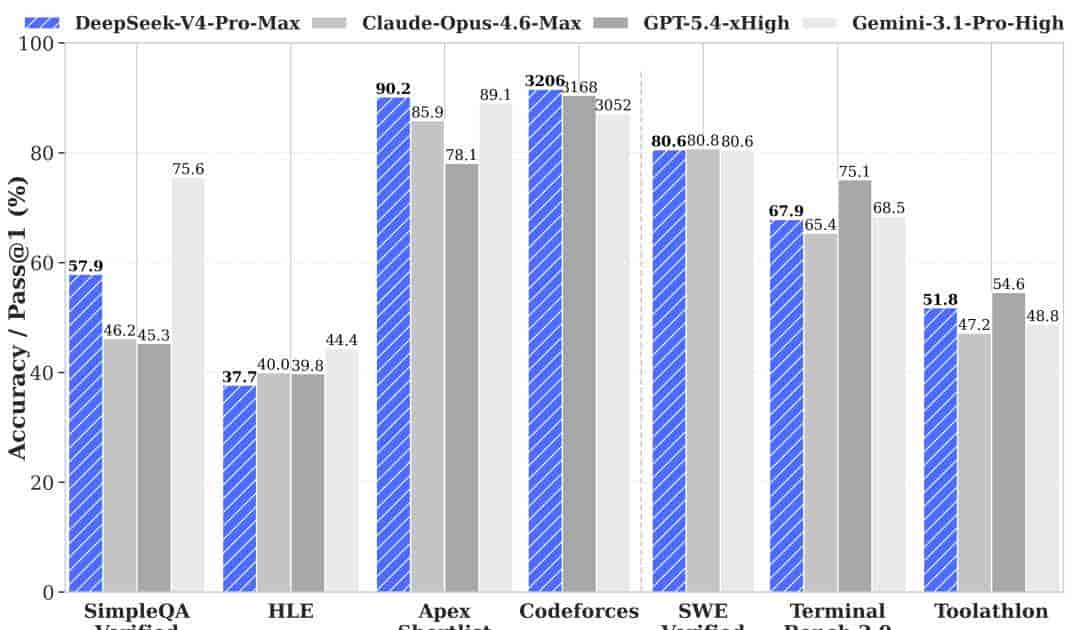
这意味着,在核心能力上,中国顶级模型已与全球闭源旗舰站在了同一梯队。
其次,市场结构正从“一家独大”走向“二元共生”。OpenRouter平台数据显示,2026年4月,中国AI大模型调用量已连续多周超越美国。同时,行业预测到2028年,开源模型在全球AI调用量中的占比将超过60%。
全球AI市场正在形成“高端闭源+普惠开源”的二元结构:闭源模型凭借技术领先性锁定高利润市场,开源模型则通过生态扩张成为普惠基础设施的主流选择。
综合来看,GPT-6与DeepSeek V4的同期发布,并非偶然的“撞车”,而是AI发展内在逻辑分化的必然结果。
它们共同终结了“参数规模至上”的单一竞赛,将竞争引入了更深层次:是继续不计成本地探索智力上限,还是在现实约束下追求极致的应用效率?这场对决没有单一的赢家,但它清晰地划出了两条路径,并共同加速了全球AI产业的双极格局与生态重构。
未来,我们很可能看到的是一个长期共存的局面:在探索AGI未知边界的实验室和顶级企业里,GPT-6及其后继者将继续引领方向;而在千行百业的数字化转型现场,DeepSeek V4这样的开源普惠模型,将成为驱动规模化智能升级的“水电煤”。这场“撞车”,撞出的是一个更多元、也更富生机的AI新时代。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










