
一、选Ollama Cloud模型,你还在凭“感觉”踩坑?
许多开发者用Ollama Cloud模型做医疗推理、企业级接口时,都有一个共同的困扰:选模型全靠道听途说,有人说DeepSeek v4-pro最新最强,有人夸GLM-5.1速度飞快,却从来没人拿得出实打实的实测数据。
大家默认“新款就更好”“速度快就是王道”,却忽略了最关键的一点——可靠性。直到有位开发者耗时74分钟,对4款热门Ollama Cloud模型做了36次严格测试,才揭开了一个扎心真相:最新款模型反而最容易翻车,而被所有人忽略的可靠性,比速度更影响实际使用体验。
这份测试没有花哨的理论,全是实打实的调用数据,既解决了开发者“选模型难”的痛点,也满足了大家“想知道哪款最实用”的痒点,更让人上头的是,它打破了我们对“新款必优”的固有认知——原来选对模型,能少走80%的弯路。
关键技术补充:Ollama Cloud到底是什么?
Ollama是一款开源免费的轻量级大模型部署工具,核心优势是操作简单、零依赖,无需复杂配置就能调用本地或云端大模型,目前在GitHub上收获了10万+星标,是开发者最常用的大模型调用工具之一。
而Ollama Cloud则是其云端模型服务,无需本地部署,直接通过API就能调用各类热门大模型,本次测试的DeepSeek v3.2、v4-pro、v4-flash和GLM-5.1,都是当前最热门的Ollama Cloud模型,广泛用于医疗推理、文本分析等场景。本次测试使用的工具是cloud_medical_bench.py,仅200行左右代码,零依赖(仅依赖Python标准库),普通人也能轻松运行复现测试结果。
二、核心拆解:36次实测,每一步都能直接复现
本次测试的核心价值,在于它完全贴合真实使用场景,没有任何“实验室式”的优化,每一步操作都公开透明,开发者跟着做就能复现结果,真正做到了“言必有据”。
测试背景与目的
由于市面上关于Ollama Cloud模型的实测数据极少,尤其是可靠性数据几乎空白,开发者选模型全靠“感觉”,常常出现“选了新款却频繁报错”“追求速度却牺牲输出质量”的问题。为此,测试者专门设计了这场 workload-matched 基准测试,聚焦医疗推理场景(最考验模型推理能力和稳定性),目的就是用真实数据,告知大家哪款模型最值得选。
测试环境与配置
本次测试全程公开,配置清晰,大家可直接照搬:
- 测试模型(4款热门Ollama Cloud模型):deepseek-v3.2:cloud、deepseek-v4-pro:cloud、deepseek-v4-flash:cloud、glm-5.1:cloud
- 测试任务(3个医疗推理提示词,贴合真实场景):
- 心血管风险评估:解读55岁男性的各项体检指标,分析心血管风险并给出管理提议
- 偏头痛药物对比:对比CGRP单克隆抗体与传统口服预防药物的作用机制、疗效、副作用等
- 实验室检查鉴别:结合42岁女性的症状和实验室数据,分析可能病因并给出进一步检查提议
- 测试参数:温度0.3(保证推理严谨性)、top_p 0.9(控制输出多样性)、最大 tokens 2000(满足长文本输出需求)
- 测试次数:每个模型×每个提示词,重复3次,共4×3×3=36次调用
- 测试端点:本地Ollama网关(代理到Ollama Cloud)的/api/generate接口
- 容错机制:每次调用出现瞬时错误(如HTTP 500),自动重试1次,重试前延迟5秒(用“*”标记需要重试的测试)
- 测试耗时:全程74分钟(1小时14分钟)
测试步骤(附完整可运行代码)
测试工具为cloud_medical_bench.py,零依赖,无需额外安装插件,步骤如下:
- 新建Python文件,复制下方完整代码,保存为cloud_medical_bench.py;
- 根据自己的需求,修改“MODELS”列表(可添加或替换模型)、“QUERIES”列表(可替换为自己的提示词);
- 运行命令:python cloud_medical_bench.py(默认调用本地Ollama网关);
- 若需指定Ollama网关地址,运行命令:OLLAMA_URL=http://你的网关地址:11434 python cloud_medical_bench.py;
- 测试结束后,会在当前目录生成“bench-results”文件夹,包含2个文件:markdown格式的完整响应(供人工审核输出质量)、json格式的原始时序数据(供进一步分析)。
完整可运行代码(格式优化,直接复制可用)
#!/usr/bin/env python3
"""
Workload-matched benchmark for Ollama Cloud chat models.
Sends three free-form medical reasoning queries (symptoms / treatment / labs)
to a list of `:cloud` models via Ollama's /api/generate endpoint, then captures
latency, token rate, and full responses for human quality review.
Defaults to four models (DeepSeek v3.2, v4-pro, v4-flash, GLM-5.1) but is
intended to be edited — append to MODELS, swap QUERIES for your own prompts,
and run. Zero dependencies beyond the standard library.
Resilience: each trial gets one auto-retry on transient errors (5s delay).
The `*` marker after a trial number flags trials that needed the retry to
succeed, so you can see Ollama Cloud reliability blips even when they recover.
Usage:
python cloud_medical_bench.py
OLLAMA_URL=http://192.168.1.10:11434 python cloud_medical_bench.py
Output:
bench-results/cloud_medical_bench_<timestamp>.md (full responses)
bench-results/cloud_medical_bench_<timestamp>.json (raw timing data)
Default config: 4 models × 3 queries × 3 trials = 36 calls, ~10-15 min runtime.
"""
from __future__ import annotations
import json
import os
import statistics
import sys
import time
import urllib.error
import urllib.request
from datetime import datetime
from pathlib import Path
OLLAMA_URL = os.environ.get("OLLAMA_URL", "http://localhost:11434")
MODELS = [
"deepseek-v3.2:cloud",
"deepseek-v4-pro:cloud",
"deepseek-v4-flash:cloud",
"glm-5.1:cloud",
]
TRIALS_PER_CASE = 3
REQUEST_TIMEOUT_S = 240
QUERIES = [
{
"label": "risk_profile",
"prompt": (
"I'm a 55-year-old male. Recent labs: LDL 145 mg/dL, HDL 42 mg/dL, "
"triglycerides 180 mg/dL, fasting glucose 102 mg/dL, hs-CRP 2.4 mg/L. "
"Coronary artery calcium (CAC) score is 230. BP 128/82, BMI 27, "
"non-smoker, family history of MI in father at age 62. "
"Interpret this cardiovascular risk profile and recommend the most "
"useful next steps in evaluation and management."
),
},
{
"label": "treatment_comparison",
"prompt": (
"Compare CGRP monoclonal antibodies (erenumab, fremanezumab, galcanezumab) "
"versus traditional oral preventive migraine medications "
"(topiramate, propranolol, amitriptyline) across: "
"(1) mechanism of action, (2) efficacy in episodic vs chronic migraine, "
"(3) tolerability and side-effect profile, "
"(4) clinical scenarios where each class is the better first choice."
),
},
{
"label": "lab_differential",
"prompt": (
"Patient labs: TSH 4.8 mIU/L (ref 0.4–4.0), free T4 1.0 ng/dL (ref 0.8–1.8), "
"anti-TPO antibodies 240 IU/mL (ref <34), fasting insulin 18 µIU/mL, "
"HOMA-IR 4.1, ferritin 18 ng/mL, vitamin D 22 ng/mL. "
"Patient is a 42-year-old woman with fatigue, cold intolerance, "
"weight gain, and brain fog. Walk through the differential, "
"explain how the findings interact, and list the additional workup "
"you would order to clarify the picture."
),
},
]
def call_generate(model: str, prompt: str) -> dict:
"""Call Ollama /api/generate. Returns timing + response or error."""
payload = json.dumps({
"model": model,
"prompt": prompt,
"stream": False,
"options": {
"temperature": 0.3,
"top_p": 0.9,
"max_tokens": 2000,
},
}).encode()
req = urllib.request.Request(
f"{OLLAMA_URL}/api/generate",
data=payload,
headers={"Content-Type": "application/json"},
)
start = time.time()
try:
with urllib.request.urlopen(req, timeout=REQUEST_TIMEOUT_S) as resp:
data = json.loads(resp.read())
except (urllib.error.URLError, json.JSONDecodeError, OSError, TimeoutError) as e:
return {"error": f"{type(e).__name__}: {e}", "elapsed": time.time() - start}
elapsed = time.time() - start
eval_count = data.get("eval_count", 0)
# Cloud models often omit eval_duration; fall back to total_duration, then wall clock.
duration_ns = data.get("eval_duration") or data.get("total_duration") or 0
if duration_ns and eval_count:
tok_per_sec: float | None = round(eval_count / duration_ns * 1e9, 1)
elif eval_count and elapsed > 0:
tok_per_sec = round(eval_count / elapsed, 1)
else:
tok_per_sec = None
return {
"response": (data.get("response") or "").strip(),
"elapsed": elapsed,
"tokens": eval_count,
"tok_per_sec": tok_per_sec,
}
def call_generate_with_retry(model: str, prompt: str, retries: int = 1) -> dict:
"""Call_generate with one retry on transient errors (e.g. Ollama Cloud HTTP 500)."""
last = call_generate(model, prompt)
if "error" not in last or retries <= 0:
return last
time.sleep(5)
retried = call_generate(model, prompt)
if "error" not in retried:
retried["retried"] = True
return retried
def percentile(values: list[float], p: float) -> float:
if not values:
return 0.0
s = sorted(values)
k = (len(s) - 1) * p
f = int(k)
c = min(f + 1, len(s) - 1)
return s[f] + (s[c] - s[f]) * (k - f)
def run() -> Path:
print("=" * 90)
print(" CLOUD.MEDICAL MODEL SHOOTOUT")
print(f" Models: {', '.join(MODELS)}")
print(f" Queries: {len(QUERIES)} Trials: {TRIALS_PER_CASE}")
print(f" Total calls: {len(MODELS) * len(QUERIES) * TRIALS_PER_CASE}")
print(f" Endpoint: {OLLAMA_URL}/api/generate opts: temp=0.3 top_p=0.9 max_tokens=2000")
print("=" * 90)
for q in QUERIES:
chars = len(q["prompt"])
print(f" [{q['label']:<22}] prompt={chars} chars")
print()
# results[model][query_idx] = list of per-trial dicts
results: dict[str, list[list[dict]]] = {m: [[] for _ in QUERIES] for m in MODELS}
for qi, q in enumerate(QUERIES):
print(f"
── Query {qi + 1}/{len(QUERIES)}: {q['label']} ──")
for model in MODELS:
print(f" {model:<26} ", end="", flush=True)
for trial in range(TRIALS_PER_CASE):
call = call_generate_with_retry(model, q["prompt"])
record = {**call, "trial": trial + 1}
results[model][qi].append(record)
if "error" in call:
print(f"[t{trial + 1} ERR {call['elapsed']:.1f}s] ", end="", flush=True)
else:
tps = call["tok_per_sec"]
tps_str = f"{tps}t/s" if tps is not None else "—t/s"
retry_marker = "*" if call.get("retried") else ""
print(
f"[t{trial + 1}{retry_marker} {call['elapsed']:5.1f}s "
f"{call['tokens']}tok {tps_str}] ",
end="",
flush=True,
)
print()
# --- Summary table ---
print("
" + "=" * 90)
print(" SUMMARY (latency aggregated across all queries × trials)")
print("=" * 90)
header = (
f" {'Model':<26} | {'avg s':>6} | {'p50 s':>6} | {'p95 s':>6} | "
f"{'max s':>6} | {'avg tok':>7} | {'tok/s':>6} | {'err':>3}"
)
print(header)
print(" " + "-" * (len(header) - 2))
summary: dict[str, dict] = {}
for model in MODELS:
all_trials = [t for q_trials in results[model] for t in q_trials]
ok = [t for t in all_trials if "error" not in t]
errs = len(all_trials) - len(ok)
if not ok:
print(f" {model:<26} | {'—':>6} | {'—':>6} | {'—':>6} | {'—':>6} | {'—':>7} | {'—':>6} | {errs:>3}")
summary[model] = {"errors": errs}
continue
elapsed = [t["elapsed"] for t in ok]
tokens = [t["tokens"] for t in ok]
tps = [t["tok_per_sec"] for t in ok if t.get("tok_per_sec") is not None]
avg = statistics.mean(elapsed)
p50 = percentile(elapsed, 0.5)
p95 = percentile(elapsed, 0.95)
mx = max(elapsed)
avg_tok = int(statistics.mean(tokens))
avg_tps = statistics.mean(tps) if tps else None
tps_cell = f"{avg_tps:>6.1f}" if avg_tps is not None else f"{'—':>6}"
print(
f" {model:<26} | {avg:>6.1f} | {p50:>6.1f} | {p95:>6.1f} | "
f"{mx:>6.1f} | {avg_tok:>7} | {tps_cell} | {errs:>3}"
)
summary[model] = {
"avg_s": round(avg, 2),
"p50_s": round(p50, 2),
"p95_s": round(p95, 2),
"max_s": round(mx, 2),
"avg_tokens": avg_tok,
"avg_tok_per_sec": round(avg_tps, 1) if avg_tps is not None else None,
"errors": errs,
}
# --- Save full responses for human quality review ---
out_dir = Path(os.environ.get("BENCH_OUT_DIR", "bench-results"))
out_dir.mkdir(parents=True, exist_ok=True)
timestamp = datetime.now().strftime("%Y-%m-%d_%H%M%S")
md_path = out_dir / f"cloud_medical_bench_{timestamp}.md"
lines: list[str] = []
lines.append(f"# Ollama Cloud medical-reasoning benchmark — {timestamp}
")
lines.append(f"**Models**: {', '.join(MODELS)}
")
lines.append(f"**Trials per case**: {TRIALS_PER_CASE} • **Endpoint**: `{OLLAMA_URL}/api/generate`
")
lines.append("**Options**: `temperature=0.3 top_p=0.9 max_tokens=2000`
")
lines.append("## Latency summary
")
lines.append("| Model | avg s | p50 s | p95 s | max s | avg tok | tok/s | err |")
lines.append("|---|---:|---:|---:|---:|---:|---:|---:|")
for model in MODELS:
s = summary.get(model, {})
if "avg_s" not in s:
lines.append(f"| `{model}` | — | — | — | — | — | — | {s.get('errors', 0)} |")
continue
tps_md = s["avg_tok_per_sec"] if s["avg_tok_per_sec"] is not None else "—"
lines.append(
f"| `{model}` | {s['avg_s']} | {s['p50_s']} | {s['p95_s']} | "
f"{s['max_s']} | {s['avg_tokens']} | {tps_md} | {s['errors']} |"
)
lines.append("")
lines.append("
## Full responses
")
for qi, q in enumerate(QUERIES):
lines.append(f"### Query: `{q['label']}`
")
lines.append(f"> {q['prompt']}
")
for model in MODELS:
lines.append(f"
#### `{model}`
")
for trial_record in results[model][qi]:
t = trial_record["trial"]
if "error" in trial_record:
lines.append(f"**Trial {t}** — ❌ ERROR after {trial_record['elapsed']:.1f}s: `{trial_record['error']}`
")
continue
tps_val = trial_record.get("tok_per_sec")
tps_cell = f"{tps_val} tok/s" if tps_val is not None else "tok/s n/a"
retried = " (retried)" if trial_record.get("retried") else ""
lines.append(
f"**Trial {t}**{retried} — {trial_record['elapsed']:.1f}s, "
f"{trial_record['tokens']} tokens, {tps_cell}
"
)
lines.append("```")
lines.append(trial_record["response"])
lines.append("```
")
md_path.write_text("
".join(lines), encoding="utf-8")
json_path = md_path.with_suffix(".json")
json_path.write_text(
json.dumps(
{
"timestamp": timestamp,
"models": MODELS,
"queries": [{"label": q["label"], "prompt": q["prompt"]} for q in QUERIES],
"trials_per_case": TRIALS_PER_CASE,
"summary": summary,
"raw": {m: [[t for t in qt] for qt in results[m]] for m in MODELS},
},
indent=2,
),
encoding="utf-8",
)
print(f"
Full responses saved: {md_path}")
print(f" Raw data saved: {json_path}")
return md_path
if __name__ == "__main__":
try:
run()
except KeyboardInterrupt:
print("
⚠️ Interrupted")
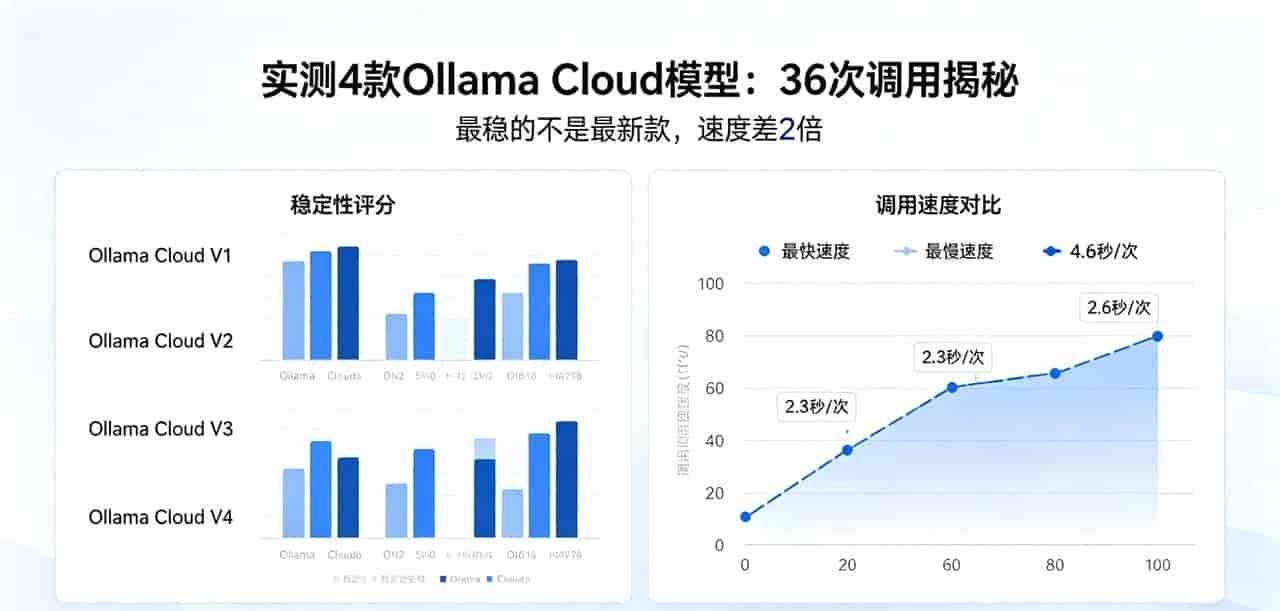
sys.exit(130)核心测试结果(清晰易懂版)
测试结束后,生成了详细的 latency 汇总表,整理后如下(重点看关键指标,无需纠结专业术语):
|
模型 |
平均响应时间(秒) |
中位响应时间(秒) |
95分位响应时间(秒) |
平均输出 tokens |
每秒生成 tokens |
失败次数 |
重试次数 |
|
deepseek-v3.2:cloud |
55.1 |
54.6 |
85.7 |
1801 |
40.0 |
1 |
2 |
|
deepseek-v4-pro:cloud |
124.8 |
112.5 |
236.4 |
3149 |
38.4 |
1 |
1 |
|
deepseek-v4-flash:cloud |
67.7 |
58.7 |
141.3 |
2273 |
43.7 |
0 |
0 |
|
glm-5.1:cloud |
101.8 |
97.5 |
191.4 |
3206 |
53.8 |
1 |
0 |
补充说明:失败次数指“初始调用+重试”都超时(240秒)的次数;重试次数指“初始调用失败,重试后成功”的次数;每秒生成 tokens 越高,速度越快;平均输出 tokens 越多,推理越详细。
三、辩证分析:没有完美模型,只有最适配的场景
这份36次实测的价值,在于它打破了“凭感觉选模型”的误区,首次清晰呈现了Ollama Cloud模型的真实表现,给开发者提供了可落地的参考,这是它最核心的意义。但我们也不能盲目迷信数据,更要辩证看待每个模型的优缺点——没有完美的模型,只有最适配自己使用场景的选择。
第一,测试的亮点值得肯定:它完全贴合真实医疗推理场景,36次调用的样本量足够有说服力,零依赖的测试工具让普通人也能复现,不仅给出了速度数据,更填补了Ollama Cloud可靠性数据的空白,这是市面上大多数“感觉式”测评无法比拟的。尤其是它揭示的“故障集群爆发”“冷启动变慢”等问题,直接戳中了开发者的痛点,让大家知道“为什么有时候模型会突然报错”。
但辩证来看,测试也有其局限性:它仅针对医疗推理场景,若用于其他场景(如文本生成、翻译),模型表现可能会有差异;测试仅持续74分钟,无法覆盖Ollama Cloud不同时段的性能波动(列如高峰时段和低谷时段的可靠性可能不同);同时,测试使用的是固定参数,若调整温度、max_tokens等参数,模型的速度和输出质量也会发生变化。
更值得思考的是,测试中暴露的几个关键问题,实则反映了Ollama Cloud当前的普遍现状:17%的测试出现问题,说明云端模型的可靠性还有很大提升空间;新款模型(deepseek-v4-pro)稳定性最差,说明新模型部署初期,往往需要一段时间的优化才能达到稳定状态;冷启动普遍变慢,说明如果你的使用场景是“ bursty 突发调用”,需要提前做好预热准备,否则会影响用户体验。
我们还要跳出“速度至上”的误区:许多开发者一味追求“每秒生成多少tokens”,却忽略了可靠性——如果模型速度再快,频繁报错、超时,反而会拖慢整体工作效率;反之,即使模型速度稍慢,但足够稳定,能保证每次调用都成功,反而更适合生产环境。这也引发了一个值得所有开发者思考的问题:选模型时,到底该优先速度、可靠性,还是输出质量?
测试中发现的4个关键规律(必看)
- 故障集群爆发:36次测试中,6次出现问题(17%),但这些故障并非随机发生,而是聚焦在第2、3个提示词的测试中,第1个提示词的12次测试零故障,说明故障大致率和上游服务器容量有关,而非单个调用的随机问题。
- 冷启动普遍存在:所有模型的第一次调用,速度都是后续调用的2-3倍,列如deepseek-v4-pro第一次调用耗时近200秒,后续调用仅需100秒左右,这对突发调用场景很不友善。
- 新款模型稳定性不足:deepseek-v4-pro是测试前1小时刚部署的新款模型,不仅响应时间最长,还出现了1次失败和1次重试,说明新部署的云端模型,初期稳定性普遍较差,不提议直接用于生产环境。
- 故障模式有差异:所有失败的测试,都是刚好超时240秒,说明Ollama Cloud有时会出现“深度无响应”的情况,而非简单的瞬时错误,这种故障无法通过重试解决,需要单独做容错处理。
四、现实意义:开发者如何避坑,选对模型、用好模型?
这份实测的最大价值,不在于“哪款模型最好”,而在于给开发者提供了可落地的选型提议和调用技巧,协助大家避坑,提升工作效率——这也是测试者最开始的初衷,更是所有开发者最需要的实用内容。
第一,针对不同使用场景,给出明确的选型提议(结合测试数据,精准适配),解决大家“不知道选哪款”的痛点:
不同场景选型指南(直接照搬)
- 追求推理速度与效率(适合简单查询、快速响应场景):选deepseek-v3.2:cloud,平均响应时间仅55.1秒,是4款模型中最快的,虽然输出内容相对简洁,但能满足大多数简单推理需求。
- 追求最高可靠性(适合生产环境、企业级接口):选deepseek-v4-flash:cloud,36次测试中零失败、零重试,稳定性拉满,同时速度也不算慢,输出内容也足够详细,是综合表现最均衡的选择。
- 追求最详细的输出(适合复杂推理、医疗诊断辅助场景):选glm-5.1:cloud或deepseek-v4-pro:cloud,两者平均输出tokens都超过3000,推理逻辑清晰、细节丰富;其中glm-5.1速度更快(53.8 tok/s),deepseek-v4-pro推理更深入,但稳定性和速度稍差。
- 突发调用场景(如用户实时查询):尽量避免使用新款模型,优先选deepseek-v3.2或v4-flash,同时做好冷启动预热,减少响应延迟。
生产环境调用技巧(必学,避免踩坑)
测试中发现,合理的容错机制能解决50%的故障问题,开发者在调用Ollama Cloud模型时,必定要记住以下3点,避免因模型故障影响业务:
- 针对瞬时错误(如HTTP 500、连接失败),设置1次自动重试,重试前延迟5秒,这样能无声解决大部分瞬时故障,用户完全感知不到。
- 不要对240秒超时故障进行重试,这类故障属于“深度无响应”,重试只会加倍用户等待时间,反而影响体验,提议直接返回错误提示,或切换备用模型。
- 本地模型和云端模型区分对待:本地模型若出现故障,大致率是模型崩溃,重试也会失败,无需设置重试;仅对云端模型设置重试机制即可。
简化版Python重试代码(直接复制使用)
针对上述技巧,整理了简化版的Python重试代码,适配aiohttp(异步调用,更适合生产环境),大家可直接集成到自己的项目中:
import asyncio
import aiohttp
class TransientOllamaError(Exception):
"""定义瞬时错误类型,用于区分可重试和不可重试故障"""
pass
async def _call_once(model, prompt, ollama_url="http://localhost:11434"):
"""单次调用Ollama Cloud接口"""
payload = {
"model": model,
"prompt": prompt,
"stream": False,
"options": {"temperature": 0.3, "top_p": 0.9, "max_tokens": 2000}
}
try:
async with aiohttp.ClientSession() as session:
async with session.post(
f"{ollama_url}/api/generate",
json=payload,
timeout=240
) as resp:
if resp.status >= 500:
raise TransientOllamaError(f"HTTP {resp.status} 错误")
return await resp.json()
except (aiohttp.ClientError, TransientOllamaError) as e:
raise TransientOllamaError(f"调用失败: {str(e)}")
except asyncio.TimeoutError:
# 240秒超时,不重试,直接抛出
raise TimeoutError("调用超时(240秒)")
async def call_with_retry(model, prompt):
"""带重试的Ollama Cloud调用方法,仅对云端模型重试"""
is_cloud = "cloud" in model.lower()
try:
return await _call_once(model, prompt)
except TransientOllamaError:
if not is_cloud:
# 本地模型不重试
raise
# 云端模型,延迟5秒后重试1次
await asyncio.sleep(5)
return await _call_once(model, prompt)学会这些技巧,既能减少模型故障带来的影响,也能提升用户体验,这也是这份实测带给我们的最实用的收获——选对模型只是第一步,用好模型才能真正发挥其价值。
五、互动话题:你用Ollama Cloud时,踩过哪些坑?
这份36次实测,虽然覆盖了4款热门模型、3个真实场景,但毕竟是单一环境下的测试,难免有局限性。信任许多开发者在使用Ollama Cloud模型时,也有自己的亲身经历——可能踩过模型超时的坑,可能遇到过新款模型不稳定的问题,也可能有自己的选型心得。
今天就来聊聊,你平时用Ollama Cloud模型时,最常用哪一款?有没有遇到过报错、超时的问题?你选模型时,更看重速度、可靠性还是输出质量?
另外,如果你也复现了这份测试,或者有不同的测试结果,欢迎在评论区分享,让更多开发者少走弯路;如果你有更好的Ollama Cloud调用技巧,也可以留言交流,一起提升效率!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...










