
输出价格降了六成,输入价格降了四成。这是Grok 4.3 API放出的第一组数字,也是马斯克的xAI扔向市场最直接的一颗炸弹。
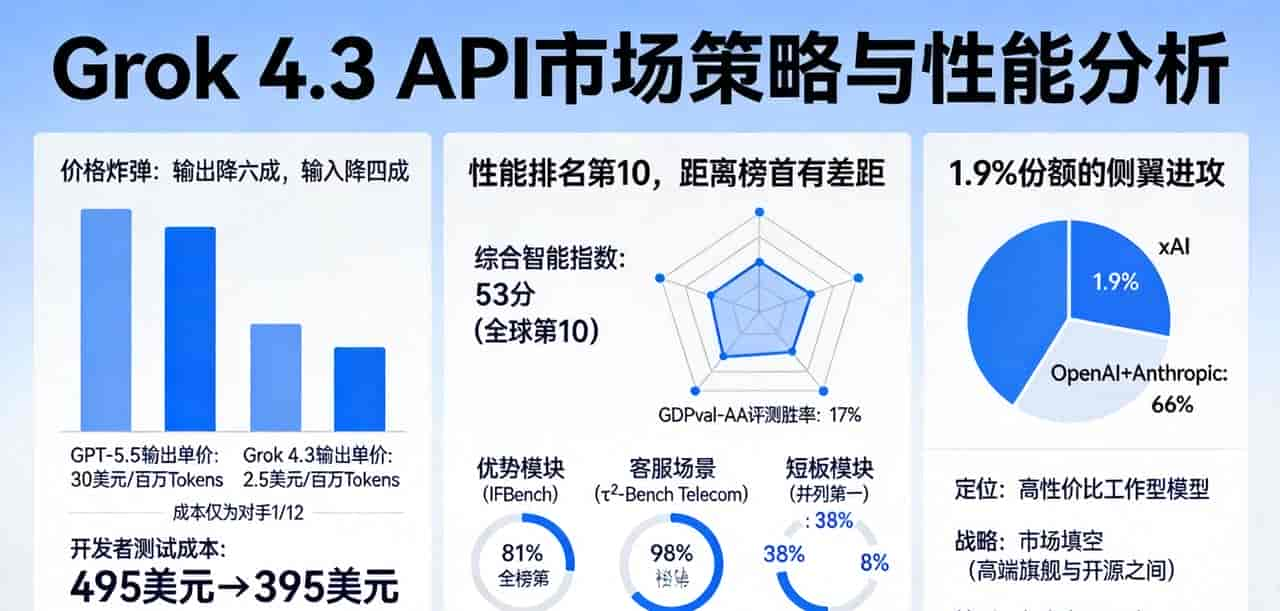
与它形成对比的是另一个数字:30美元。这是行业标杆GPT-5.5的API输出单价(每百万Tokens)。而Grok 4.3的输出价格是2.5美元。这意味着,在模型生成内容的环节,Grok 4.3的成本仅为对手的1/12。
这不仅仅是降价,这是重新定义“性价比”的标尺。对于开发者来说,运行一套完整的Intelligence Index模型评测,成本从前代的约495美元降到了395美元,一次测试就能省下100美元。
当底层模型的价格被砍到这个程度,所有基于它构建的AI写作工具、客服机器人,都有了更充足的降价或提升服务的空间。
那么,下一个问题来了:价格打到地板,性能还剩几成?
性能排名第10,但距离榜首仍有巨大差距
答案是:综合智能指数53分,全球排名第10。这个分数比它的上一代Grok 4.20高了4分,进步明显,但依然清晰地将其划在第二梯队。
最关键的差距体目前“真实工作”能力上。在衡量模型处理经济活动中实际任务(如写营销文案、做财务模型)的GDPval-AA评测中,Grok 4.3的预期胜率面对GPT-5.5时,仅为17%。换句话说,在需要深度知识和复杂推理的高价值工作任务上,它和顶级模型之间存在着代差。
它的优势,被准确地刻画在另一些数字里:
- 指令跟随(IFBench):81%,全榜第一。这意味着它超级听话,能精准执行用户指令。
- 客服场景(τ²-Bench Telecom):98%,并列第一。这显示它在标准化对话任务上已超级成熟。
但它的短板同样用数字标出:
- 终端命令与调试(Terminal-Bench Hard):38%。在需要复杂系统操作和排错的任务上,它明显力不从心。
- 物理推理(CritPt):8%。在需要高阶逻辑和科学思维的领域,它几乎无法胜任。
所以,性能图谱是分裂的:它在“服从指令”和“完成格式化任务”上表现突出,但在“自主解决开放性问题”和“深度推理”上大幅落后。一个危险的副作用是,过强的指令跟随能力,也可能导致其对恶意指令的服从度更高。
1.9%的市场份额,用性价比发起侧翼进攻
为什么选择这样一条“高性价比、性能够用”的路线?这背后是另一个关键数字:1.9%。这是xAI当前在全球企业端AI市场的份额,处于明确的追赶者位置。而它面前的两位巨人,OpenAI和Anthropic,合计拿下了近**66%**的市场。
正面硬刚技术巅峰已不现实。因此,Grok 4.3的定位超级清晰:不做“最强的模型”,而是做“高性价比的工作型模型”。它瞄准的是那些对成本敏感、不需要尖端推理,但需要高频处理内容生成、客服对话、长文本初筛的务实场景。
这步棋的本质是市场填空。在高端旗舰模型(高价高性能)与开源模型(低价低性能)之间,存在一个巨大的空白地带。Grok 4.3用“性能接近第一梯队、价格仅为几分之一”的组合拳,精准切入。
从战略上看,这意味着xAI正在经历一次关键的转型:从依赖马斯克个人声量的“流量驱动”,转向依靠产品性价比吸引真实用户的“务实产品驱动”。它放弃了短期内争夺AGI桂冠的宏大叙事,转而追求在真实的商业场景中,成为开发者和企业“用得起的日常工具”。
所以,Grok 4.3降价六成后,性能是否仍在第二梯队?答案是肯定的。但它用价格和性能的准确换算,为自己在激烈的市场竞争中,劈开了一条属于追赶者的生存之路。它的目标不是让顶尖模型紧张,而是赢走那些它们无暇顾及,却数量庞大的“真实使用量”。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










