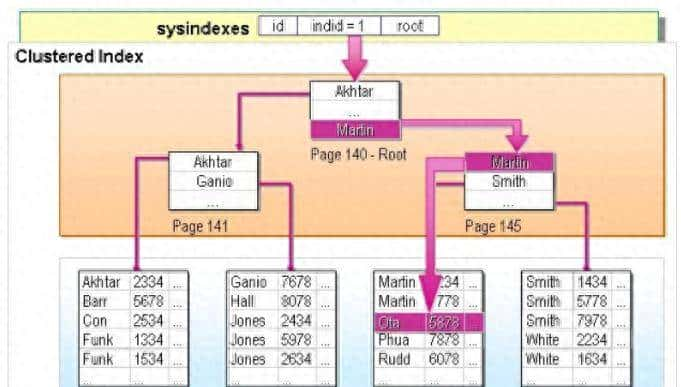
一、什么是 Prompt Engineering?
Prompt Engineering 是指通过精心设计和优化输入给大语言模型(Large Language Models, LLMs)或其他生成式 AI 系统的提示(prompt),以引导模型产生更准确、可靠、可控、符合任务目标的输出。它不是传统意义上的“编程”,而是一种人与 AI 协作的语言接口设计艺术与科学。
核心思想:你如何提问,决定了 AI 如何回答。
随着 GPT、LLaMA、Claude、Gemini 等模型能力的增强,prompt 已成为控制模型行为的关键杠杆。在没有微调(fine-tuning)或仅使用基础模型(base model)的情况下,prompt engineering 几乎是唯一可操作的干预手段。
二、为什么需要 Prompt Engineering?
- 模型是“黑盒”但可引导LLMs 虽然参数庞大,但其行为高度依赖输入上下文。好的 prompt 能激活模型中相关的知识与推理路径。
- 避免“幻觉”(Hallucination)模型可能编造实际。通过约束性 prompt(如“仅基于以下文本回答”),可显著降低错误率。
- 提升任务泛化能力同一模型可通过不同 prompt 执行翻译、摘要、代码生成、情感分析等数百种任务。
- 降低成本与延迟相比微调,prompt engineering 无需训练,部署快、成本低,适合快速迭代。
- 适配商业与合规需求可强制模型遵守格式、语气、隐私政策、法律条款等。
三、Prompt 的基本构成要素
一个高质量的 prompt 一般包含以下部分(不必定全部):
|
元素 |
说明 |
|
指令(Instruction) |
明确告知模型要做什么(如“总结以下文章”) |
|
上下文(Context) |
提供背景信息或参考资料(如用户历史、文档片段) |
|
输入数据(Input Data) |
待处理的具体内容(如一段文本、一个问题) |
|
输出指示(Output Indicator) |
指定期望的格式、长度、风格(如“用 JSON 返回”) |
|
示例(Examples) |
少样本(few-shot)学习中的输入-输出对 |
|
角色设定(Role) |
“你是一位资深律师…” 以激活特定知识域 |
|
约束条件(Constraints) |
“不要使用专业术语”、“仅回答是或否” |
✅ 示例完整 prompt:
你是一位经验丰富的科技记者。请根据以下新闻稿,撰写一篇不超过200字的中文摘要,突出产品创新点和市场意义。避免主观评价。
[新闻稿内容…]
输出格式:{“title”: “标题”, “summary”: “摘要”}
四、核心 Prompting 技术详解
1. Zero-Shot Prompting(零样本提示)
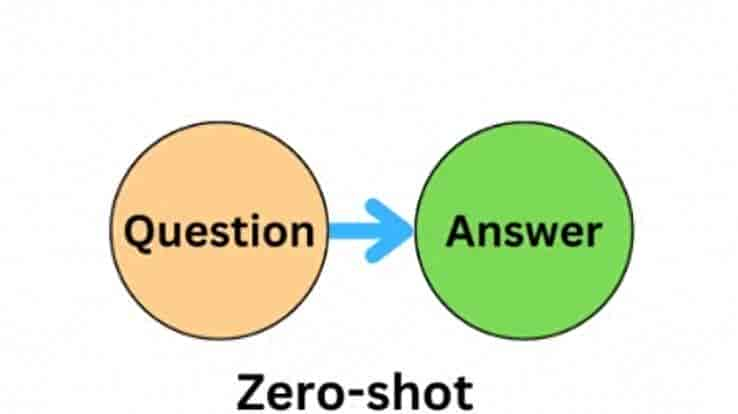
- 定义:不提供任何示例,仅靠指令完成任务。
- 适用场景:模型已预训练覆盖该任务(如问答、翻译)。
- 优点:简洁、高效。
- 缺点:对复杂任务效果有限。
- 示例:“将以下句子从英语翻译成法语:The weather is beautiful today.”
2. Few-Shot Prompting(少样本提示)
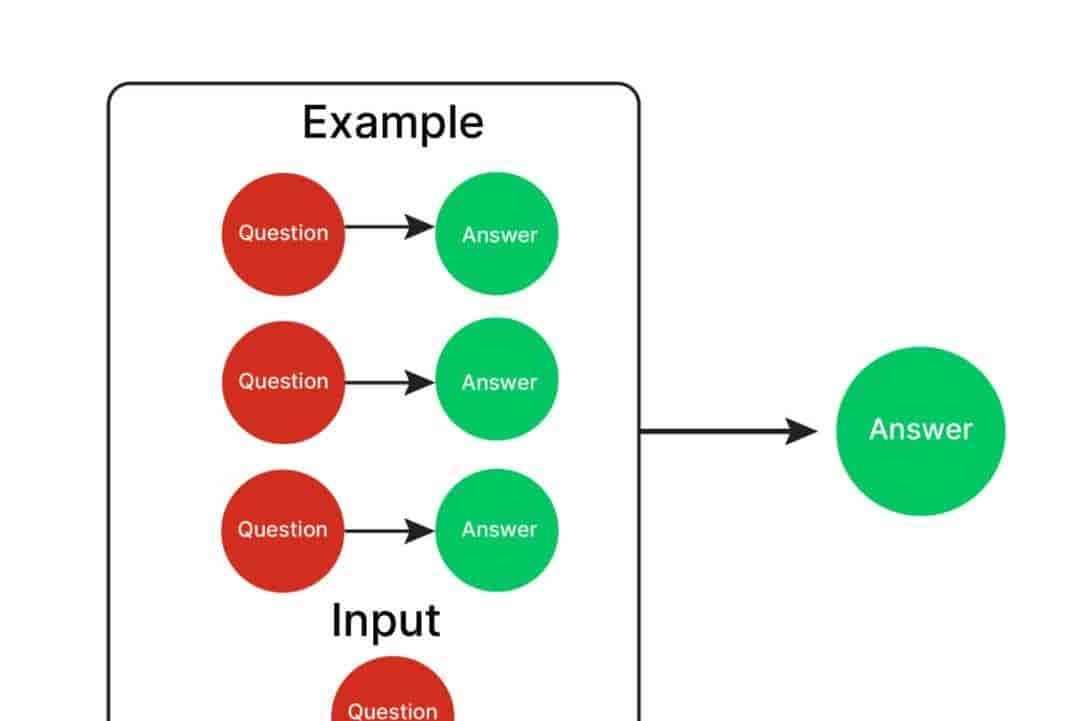
- 定义:在 prompt 中提供少量(一般 2–10 个)输入-输出示例。
- 原理:利用模型的 in-context learning 能力,模仿示例模式。
- 关键:示例需高质量、具代表性、格式一致。
- 示例:输入:北京 → 输出:中国
输入:巴黎 → 输出:法国
输入:东京 → 输出:
3. Chain-of-Thought (CoT) Prompting(思维链提示)
- 提出者:Google Research (2022)
- 核心:引导模型“逐步思考”,显式生成中间推理步骤。
- 适用:数学、逻辑、多跳问答等复杂推理任务。
- 触发语句:
- “让我们一步一步思考。”
- “请先分析问题,再给出答案。”
- 效果:在 GSM8K 等数学数据集上,性能提升数倍。
- 示例:问题:小明有 5 个苹果,吃了 2 个,又买了 4 个,目前有几个?思维链:开始有 5 个 → 吃掉 2 个,剩下 3 个 → 买 4 个,共 3+4=7 个。答案:7
4. Self-Consistency with CoT
- 在 CoT 基础上,多次采样不同推理路径,选择最一致的答案(如多数投票)。
- 显著提升推理鲁棒性。
5. Role Prompting(角色提示)
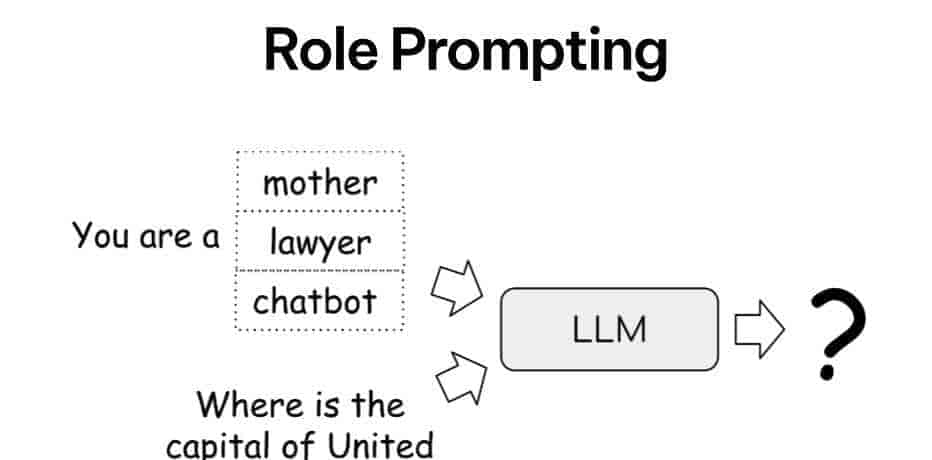
- 让模型扮演特定身份(医生、程序员、客服等),激活相关知识库与语气风格。
- 示例:“你是一位 Python 高级工程师,请解释装饰器的工作原理,并给出一个实用示例。”
6. Instruction Tuning Style Prompting
- 使用清晰、结构化、无歧义的指令。
- 避免模糊词(如“好一点”、“差不多”),改用具体指标(“不超过100字”、“列出3个缘由”)。
7. Negative Prompting(负向提示)

- 明确告知模型不要做什么。
- 示例:“不要提及敏感话题;不要使用缩写;不要假设用户性别。”
8. Output Formatting Control

- 强制模型按指定格式输出,便于程序解析。
- 支持:JSON、XML、Markdown、表格、列表等。
- 技巧:
- 在 prompt 末尾给出格式模板。
- 使用分隔符(如 —)隔离指令与输出。
- 示例:“请以如下 JSON 格式返回:{ “name”: “…”, “age”: …, “city”: “…” }”
9. Prompt Chaining(提示链)
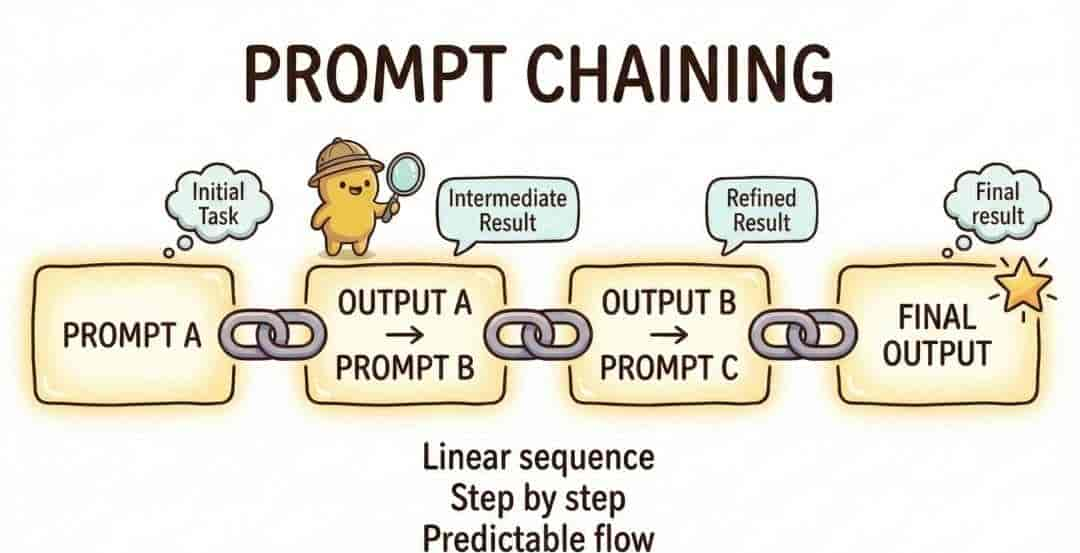
- 将复杂任务拆解为多个子任务,依次执行,前一步输出作为后一步输入。
- 应用场景:
- 文档分析 → 提取关键实体 → 生成报告 → 翻译成英文
- 优势:降低单次推理负担,提高准确性。
10. Generated Knowledge Prompting
- 第一步:让模型生成与问题相关的背景知识。
- 第二步:结合生成的知识回答问题。
- 适用于开放域问答,弥补模型知识盲区。
11. Tree of Thoughts (ToT)
- 将推理过程建模为树状搜索,每个节点是一个“thought”(中间状态)。
- 允许回溯、评估、剪枝。
- 需要外部控制器(如代码)协调,非纯 prompt 实现,但理念源于 prompt design。
12. Automatic Prompt Engineering(自动提示工程)
- 使用算法(如梯度搜索、强化学习、LLM 自我优化)自动生成最优 prompt。
- 工具如:APE (Automatic Prompt Engineer)、PromptAgent、PromptBreeder。
- 仍处研究阶段,但潜力巨大。
五、高级策略与最佳实践
✅ 上下文管理
- 利用模型最大上下文窗口(如 128K tokens),但注意关键信息靠前(因注意力衰减)。
- 使用 “倒金字塔”结构:最重大指令放最前。
✅ 温度(Temperature)与 Top-p 控制
- 虽非 prompt 本身,但与 prompt 协同:
- 低 temperature(0.1–0.5):确定性高,适合实际问答、代码生成。
- 高 temperature(0.7–1.0):创意性强,适合写作、头脑风暴。
✅ 对抗性测试
- 测试 prompt 在边界情况下的表现:
- 输入为空?
- 包含误导信息?
- 多语言混合?
- 构建“红队测试”(Red Teaming)用例。
✅ 多语言 Prompting
- 在非英语场景中,使用目标语言写 prompt 效果一般更好。
- 但某些模型在英语指令下表现更稳定(需实测)。
六、评估 Prompt 效果的方法
|
方法 |
说明 |
|
人工评估 |
专家打分(相关性、流畅性、准确性) |
|
自动指标 |
BLEU, ROUGE, METEOR(适用于摘要/翻译) |
|
任务准确率 |
分类正确率、QA F1 分数等 |
|
A/B 测试 |
对比两个 prompt 在真实用户中的点击率、满意度 |
|
失败案例分析 |
收集 bad cases,反向优化 prompt |
|
Latency & Cost Tracking |
token 使用量、响应时间是否可接受 |
七、常用工具与平台
|
类别 |
工具 |
|
开发调试 |
OpenAI Playground, Anthropic Console, Google Vertex AI, Hugging Face Chat UI |
|
应用框架 |
LangChain, LlamaIndex, Semantic Kernel |
|
Prompt 管理 |
PromptHub, PromptLayer, Braintrust |
|
实验跟踪 |
Weights & Biases, MLflow, LangSmith |
|
自动化生成 |
APE, PromptAgent, DSPy(Declarative Self-improving Programs) |
DSPy 是新兴范式:将 prompt 视为可学习模块,通过优化器自动调整,实现“programmable prompting”。
八、典型应用场景示例
|
场景 |
Prompt 设计要点 |
|
客服对话 |
角色设定 + FAQ 示例 + 情绪安抚话术 + 转人工触发条件 |
|
代码生成 |
明确语言 + 输入输出规范 + 错误处理要求 |
|
营销文案 |
品牌 tone of voice + 目标人群 + CTA(行动号召) |
|
学术写作 |
引用格式(APA/MLA)+ 避免抄袭 + 逻辑结构要求 |
|
法律合同审查 |
仅基于给定条款判断 + 高亮风险点 + 不推测未提及内容 |
|
教育辅导 |
Socratic 提问法 + 逐步提示 + 防止直接给答案 |
九、局限性与挑战
- 不可预测性:一样 prompt 在不同模型/版本上表现差异大。
- 上下文遗忘:长上下文中早期指令可能被忽略。
- 安全绕过风险:恶意用户可能通过 prompt injection 劫持模型行为。
- 缺乏理论基础:多数技巧基于经验,缺乏统一理论框架。
- 多模态扩展难:图像、音频等模态的 prompt engineering 尚不成熟。
十、未来趋势
- 从 Prompt Engineering 到 Prompt Programming—— 使用 DSL(领域特定语言)或框架(如 DSPy)将 prompt 模块化、可组合、可优化。
- 与 RAG(检索增强生成)深度融合—— prompt 不仅引导推理,还控制检索策略与知识融合方式。
- 个性化 Prompt—— 基于用户画像动态生成定制化 prompt。
- AI 自我改善 Prompt—— 模型自动反思输出质量,并重写自身 prompt(Self-Refine)。
结语
Prompt Engineering 是连接人类意图与 AI 能力的桥梁。它既是技术,也是艺术;既需逻辑严谨,也需语言敏感。随着模型能力演进,prompt 的设计将从“技巧堆砌”走向“系统工程”,最终成为 AI 应用开发的核心技能之一。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











