
不知道你有没遇到过这种情况。
同样是 AI Coding Agent,有人拿它写需求、改 bug、补测试,越来越顺;也有人今天让它修个问题,代码看着像那么回事,一跑就歪,再改几轮,最后还得自己下场收拾残局。

许多人会把缘由归到模型上:是不是模型不够强,IDE 不够好,或者 provider 不够稳。 但真做深了就会发现,许多时候问题根本不在这里。

Agent写代码稳不稳,关键不只是它“聪不机智”,而是你有没有给它一个能稳定工作的环境。 这个环境搭不好,模型再强,结果也很容易漂。
为什么大多数团队用了 AI Coding Agent,效果还是不稳定?
目前几乎每个技术团队都在试 AI Coding Agent。有人用 Claude Code,有人用 Cursor,有人自己接 workflow,有人开始折腾 agent + MCP。表面看起来,大家都在同一条船上,结果却差得很远。
有的团队已经把Agent接进了日常开发,能写功能、补测试、做 review,效率的确 上来了。 有的团队也在用,但总觉得不踏实:今天写对了,明天就跑偏;一个需求本来想省时间,最后花更多时间返工。
这事我目前越来越确定,问题往往不在模型。
真正决定 AI 编码效果的,不是谁模型更新、上下文更长、宣传更猛,而是你有没有把Agent工作的那套环境设计出来。这个东西,叫 agent harness。
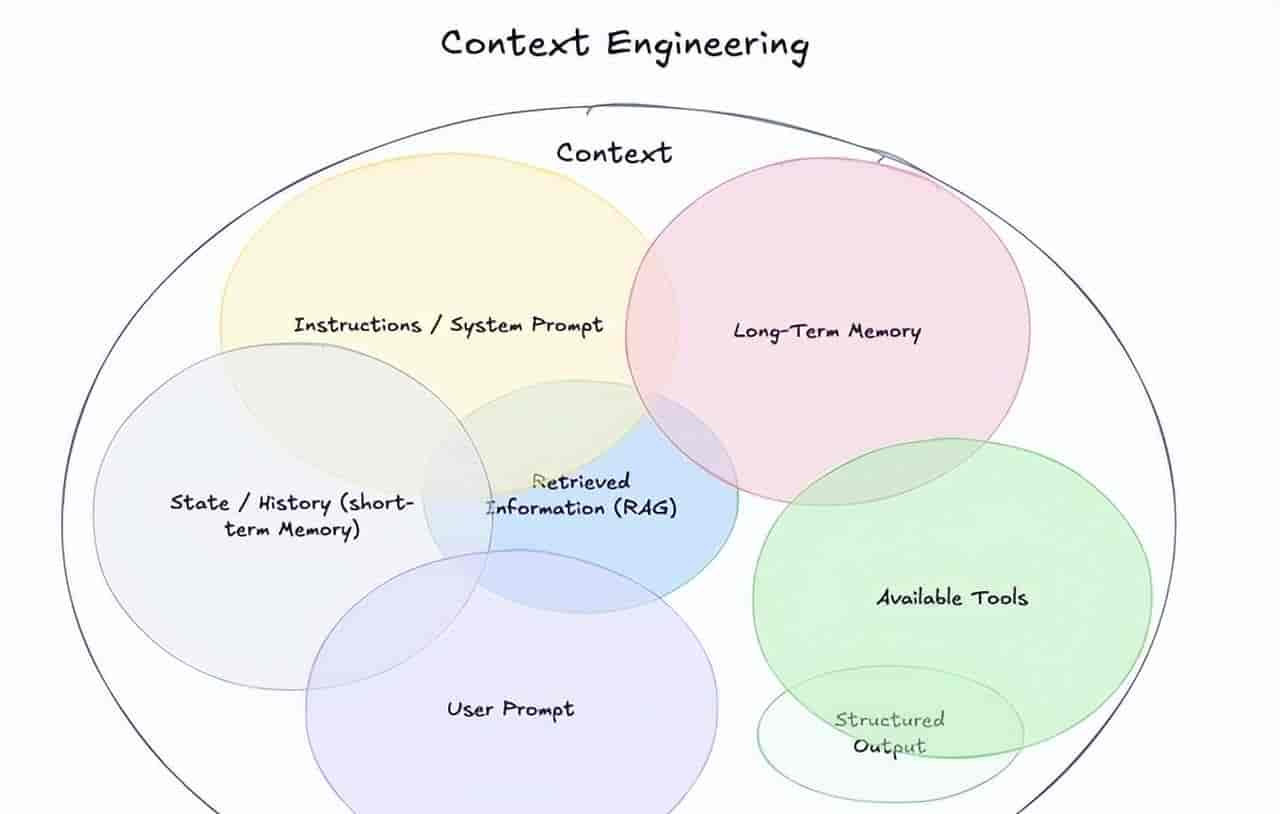
它不是一个 prompt,也不是几个规则文件那么简单。它更像是Agent的“工作系统”: 它知道什么,能调什么,按什么边界做事,出了错会被什么机制拦下来,最后都由这套系统决定。
许多团队目前的问题,不是不会用 AI,而是还在把 AI 当成一个会自动吐代码的工具。这样当然也能跑出一些结果,但稳定性会很差。你今天靠运气拿到一次不错的输出,不代表明天还能复现。
把 AI Coding Agent,当成一个刚入职的优秀新人
这个比喻我觉得特别准。

一个刚入职的新同事,脑子快,基础好,执行力也强。但他第一天进项目,不会天然知道这些事:
- 你们服务怎么拆
- 哪些库能用,哪些不能碰
- 测试到底写到什么程度
- 哪些历史坑反复出过问题
- 哪类需求是看起来简单,实际有隐藏业务约束
- 代码合了后来,CI 和发布流程里有哪些硬门槛
这时候你不会只给他一句“把这个功能做了”,然后等着一个完美结果。你会给文档,给规范,给样例,给工具权限,给 review 机制,必要时还会给一个更明确的 spec。
AI Coding Agent也一样。
它当然会写代码,但它不知道哪些东西在你的团队里属于“默认常识”。而工程现场最容易出事故的,恰恰就是这些“人觉得理所当然、机器却并不知道”的部分。
所以,问题不是Agent会不会写,而是你有没有把那些本来存在于团队经验里的东西,变成它能用、能遵守、能被校验的系统条件。
为什么Agent一开始挺机智,写着写着就乱了
由于它不是在一个无限清晰的空间里工作。它始终被上下文窗口限制着。
你可以把上下文窗口理解成Agent当前任务的工作台。 它手边能同时看到的规则、代码、历史消息、工具返回结果、终端输出,全部都要塞在这张台面上。台面一旦堆满,问题就来了。
最常见的情况是这样的:
- 一开始,你给了它一些看起来很完整的规则;
- 然后它去读仓库、查文件、跑命令、拉日志;
- 接着你又来回补了几轮需求说明;
- 最后它看到的信息越来越多,但真正关键的信息反而被冲淡了。
于是它开始出现一种很典型的状态:
不是完全不会做,而是“似懂非懂”。看起来方向对,细节却不断偏;语法没问题,工程决策却越来越虚;它还在继续输出,但已经不再真正对齐你的目标。
许多团队的误区就在这里:
总觉得上下文越多越好,给得越全越保险。实际上不是。无关信息、冗长规则、没筛过的日志、过量工具输出,都会把Agent的判断质量慢慢拖下去。
所以稳定性不是靠“堆上下文”换来的,而是靠“把该给的给准,不该给的别塞进去”。
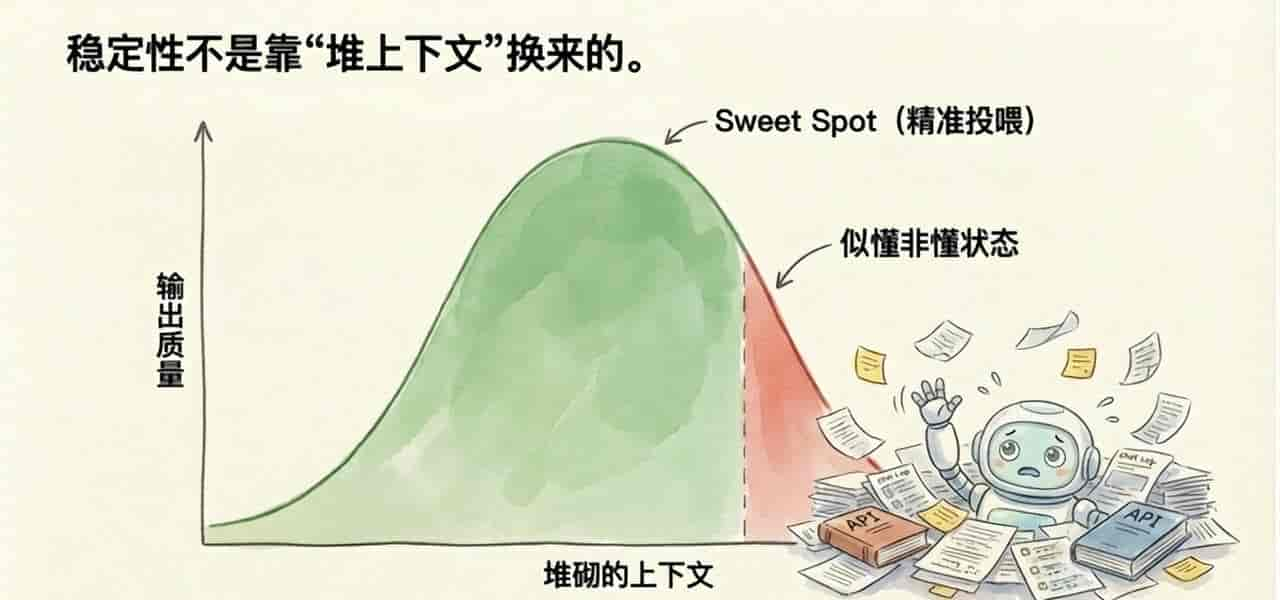
真正有用的,是四个东西
如果把 agent harness 说得再直白一点,它最核心就四样。
1)自定义规则
这是最先该做的,而且大多数团队做这一层就已经能明显改善效果。
你要告知Agent:
- 项目技术栈是什么
- 常见架构模式是什么
- 命名和目录约定是什么
- 测试怎么写
- 哪些坑以前已经踩过
- 哪些写法在这个仓库里明确不要出现

这里最容易犯的错,不是写少了,而是写废了。 把整份 API 文档、长篇原则、空泛口号全塞进去,最后Agent没记住真正重大的约束,反而被噪音淹了。
好的规则文件应该像团队里的老同事写给新人的“避坑说明”,短,具体,真有用。
2)工具能力
Agent只会读写文件和跑命令,实则远远不够。

它许多时候还需要知道数据库 schema、内部接口契约、业务文档、设计稿、CI 状态,甚至需要去读真实环境里的一些限制条件。没有这些,它只能对着仓库猜。猜对了是运气,猜错了是常态。
工具能力接得越对,Agent越接近一个真正能干活的工程师;接得越乱,它越像一个权限许多、但判断常常失真的实习生。
3)skills
许多高频任务,实则不该每次重新解释。
列如:
- 给老项目补单元测试
- 按团队规范写接口层代码
- 对 PR 做一次结构化 review
- 先读 spec 再拆任务
- 遇到前端表单类需求时优先检查哪些点
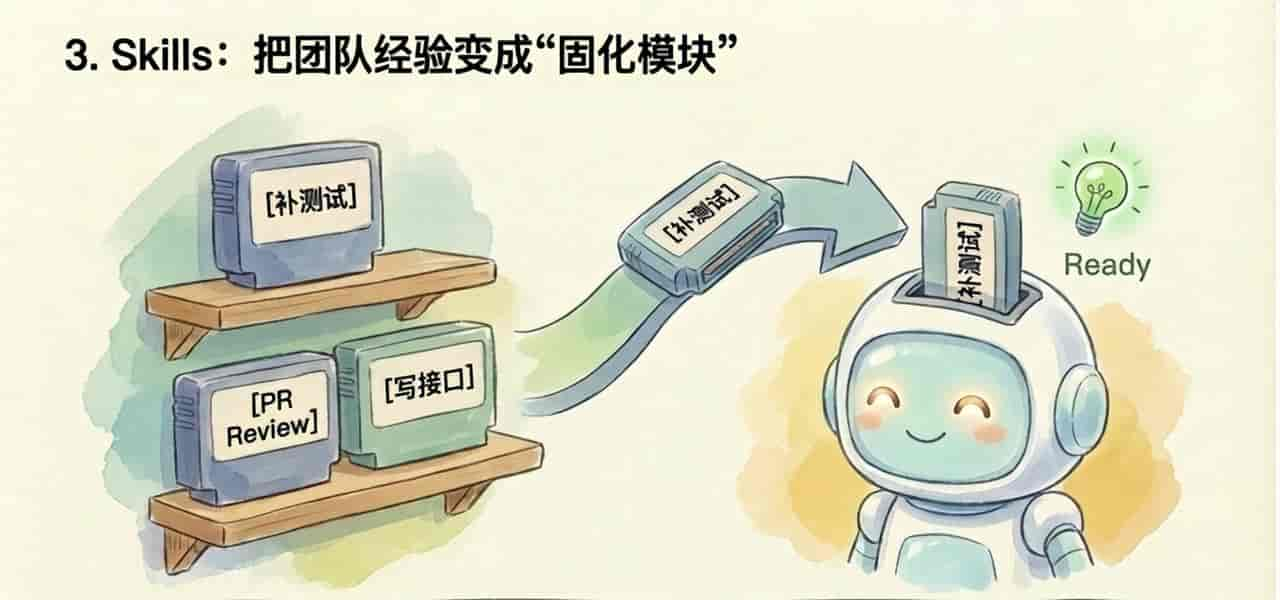
这些都很适合沉淀成 skill。平时不占上下文,触发时再加载完整说明。 这样做有两个好处:一是省上下文,二是把团队经验变成可以复用的操作单元。
说到底,skill 的价值不在“花哨”,而在“把重复解释变成稳定执行”。
4)spec
许多Agent翻车,不是代码能力不够,而是需求输入太含糊。
你给它一句:
“做个后台新增功能。”
这句话对人来说也许够了,由于人脑会自动补全许多默认前提。 但对Agent来说,这几乎等于没说。
- 新增到哪里?
- 有无权限限制?
- 是否要求幂等?
- 重复提交怎么办?
- 字段校验在哪一层做?
- 是否要补审计日志?
- 失败回滚怎么处理?
- 测试验收以什么为准?
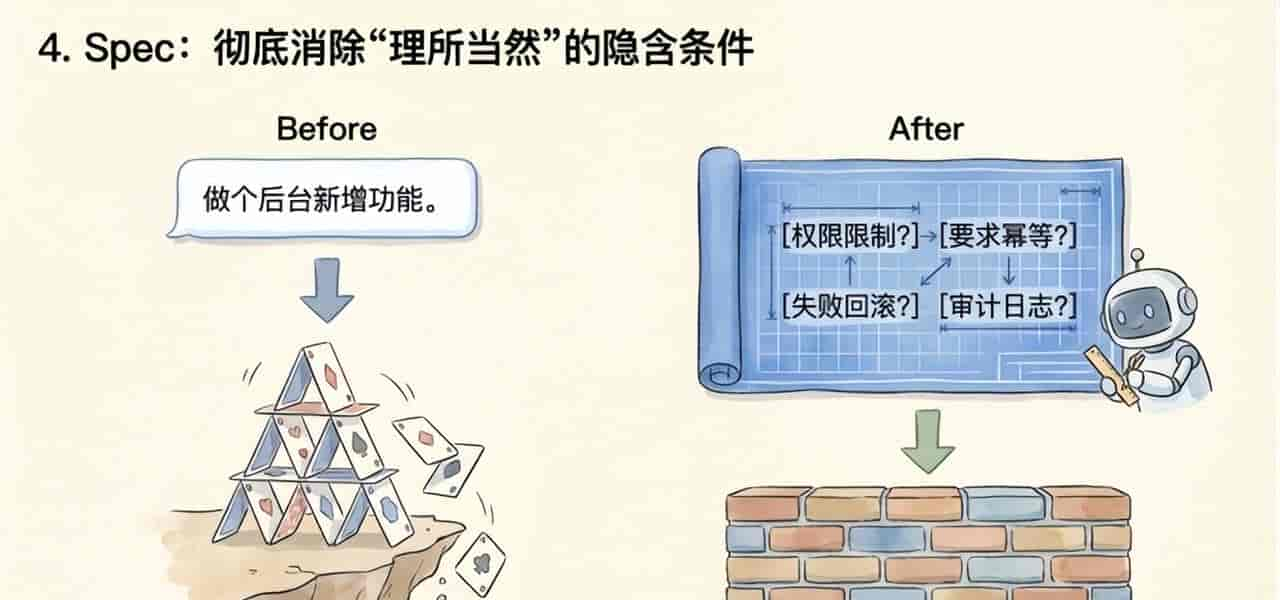
这些如果不说,Agent就只能自己猜。它能写出一个“看起来能跑”的版本,但工程上最容易出问题的,偏偏就是这些你没写出来的隐含条件。
所以 spec 的价值很直接:别让Agent猜。你先把事情说清楚,再让它做。
一个很典型的失败案例
举个特别常见、也特别像真实团队里会发生的例子。
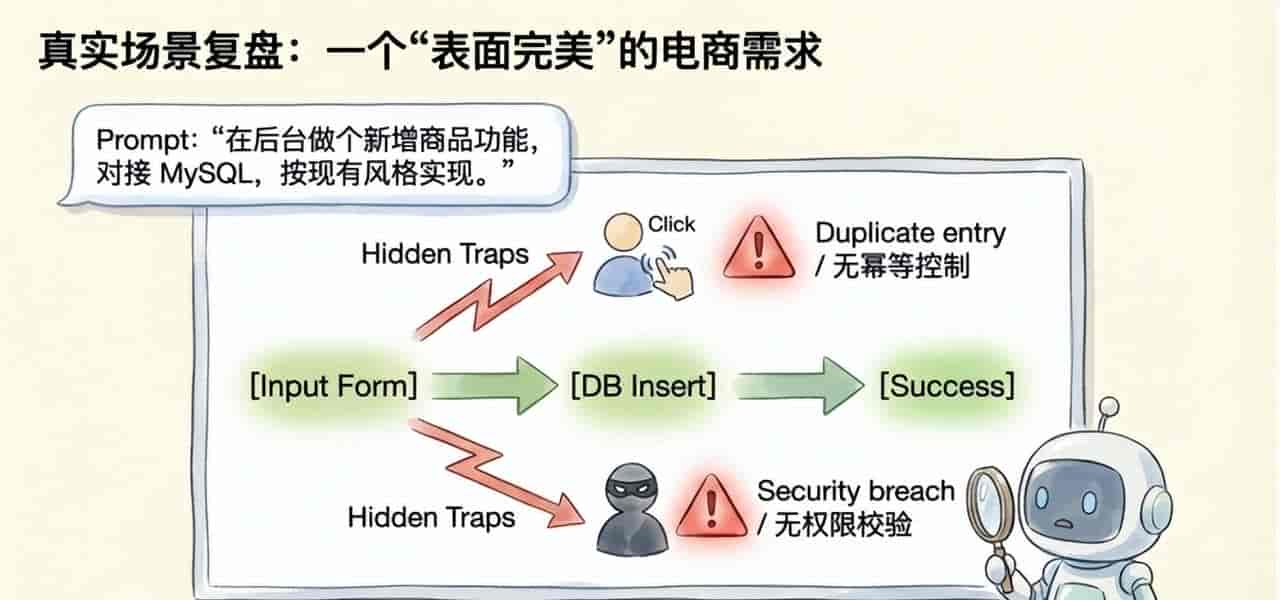
需求是给 一个电商后台 增加一个“新增商品”的入口。产品看上去很简单:填表单,点提交,数据入库,页面提示成功。
开发把任务丢给Agent,大意就是:
“在后台做一个新增商品功能,对接现有 MySQL,按现有风格实现。”
Agent读了代码库,找到了现有表结构,补了接口,前端页面也生成了,看起来一切都很顺。第一次点击提交,商品成功入库,联调通过。
问题出在第二次点击。
由于表单重复提交时没有做幂等控制,同一条商品被插入了两次。再往下查,又发现权限也没兜住,本来只有特定角色可以新增商品,但这个逻辑在需求里没写,代码里也没被Agent准确推断出来。
最后回过头看,问题不在代码生成本身,而在输入太薄:
- 没写“按商品 ID 保证幂等”
- 没写“只有某个角色能新增”
- 没写“重复提交要给用户什么反馈”
- 没写“接口层和服务层谁负责兜底”
- 没写“测试里要覆盖重复点击场景”
结果就是:Agent写出来的是一个 MVP,不是一个可上线的实现。
这类问题,我认为是目前许多团队误判 AI 编码能力的根源。它不是完全不会做,而是在缺少 spec、规则和反馈回路的时候,只能交付一个“差不多像”的版本。
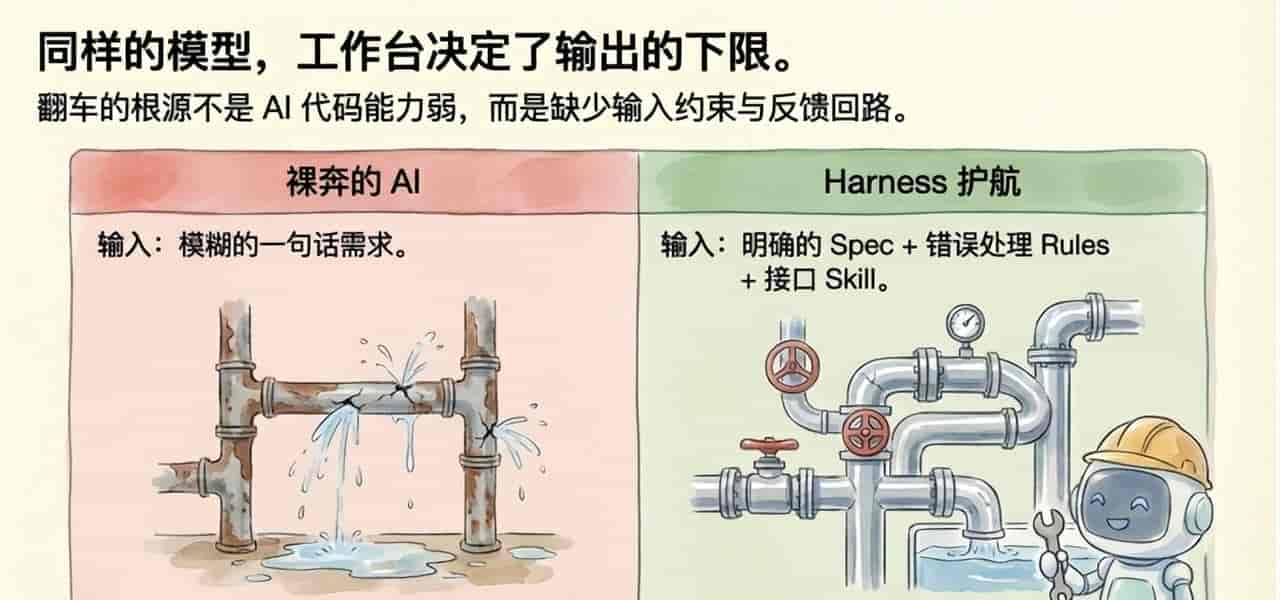
最后能不能稳,靠的是反馈回路
许多人会把注意力全放在“怎么让Agent更懂我”,却忽略了另一件更重大的事:怎么让它在做错后来,自己能被拉回来。
测试、lint、类型检查、build、review,这些东西以前本来就是工程体系的一部分。到了 agent 时代,它们不只是质量保证工具,更是Agent的反馈系统。
这件事一旦想清楚,工作方式会变许多。
Agent不是你说一句“这里好像不太对”,然后靠它自己悟; 更好的办法是让它直接面对一个清晰的失败信号。
测试没过,就改。 类型检查挂了,就修。 构建没过,就继续处理。 review agent 报高优先级问题,就先解决那个。
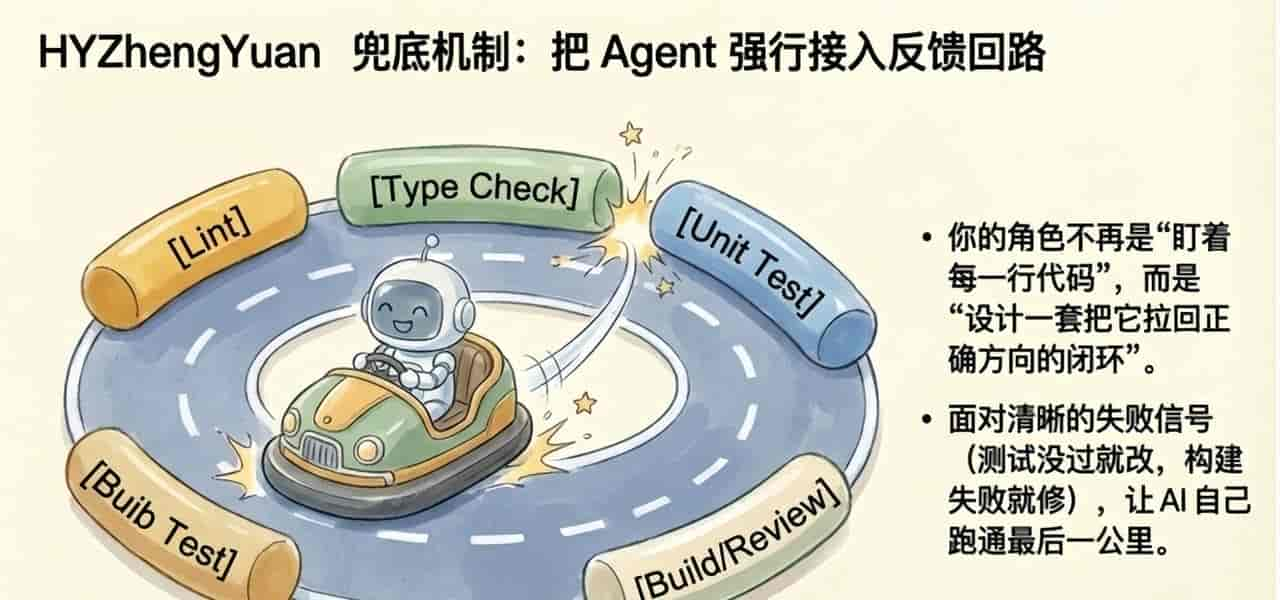
到了这一步,人的角色开始变化。你不再是在每个细节上盯着它,而是在设计一套能把它不断拉回正确方向的闭环。
真正成熟的团队,甚至会把这些校验接进固定钩子里。Agent不过关,就结束不了任务。这样它才不是“偶尔能帮点忙”,而是真正被接进了工程生产线。
如果团队目前就想开始,最小落地清单可以这样做
不要一上来就想着做一个大而全的 AI 开发平台。大多数团队,先把下面这几步做好,效果就会很不一样。
1)先写一份真的有用的规则文件
别写大而全的宣言。 就写你们项目里最常见、最容易错、最值得提前说清楚的东西。
至少包括:
- 技术栈和目录约定
- 测试要求
- 不能用的库或模式
- 常见反模式
- review 时最看重的几条规则
2)把校验接进固定流程
至少先做到这几样自动跑起来:
- lint
- type check
- unit test
- build
让Agent每次改完都必须面对这些反馈,而不是改完就结束。
3)把 2 到 3 个高频任务沉淀成 skill
先别贪多。 就选你们最常重复解释、最适合标准化的任务,列如:
- 补测试
- 写接口
- 做 PR review
- 处理常见表单类需求
4)重大需求先写 spec,再让Agent动手
不是所有事都值得写长 spec,但只要满足下面任一条件,就提议先写:
- 有权限逻辑
- 有幂等要求
- 有跨服务调用
- 有历史包袱
- 出错成本高
5)复盘Agent最近 5 次失败场景
别只说“它不太稳定”。 把最近几次失败拿出来看,然后总结出问题:
这次失败,本来应该通过哪条规则、哪个 spec 字段、哪种反馈机制提前拦住?
这个动作很关键。由于 harness 不是设计出来就一劳永逸的,它本来就是要不断自我进化的过程。
真正拉开差距的,不是谁换了更强的模型
我目前越来越信任,未来团队之间的差距,未必第一体目前模型选型上,而会体目前谁更早把这一整套东西做成工程系统。
模型当然重大,但那更像引擎。

真正决定你这辆车能不能长期稳定跑的,是路、方向盘、刹车、仪表盘和维护流程。
AI Coding Agent也一样。
没有 harness,它就只是一台偶尔给你惊喜、偶尔给你惊吓的机器。
有了 harness,它才可能成为一个真正稳定的工程角色。
所以如果你问我,为什么许多团队已经用了 AI Coding Agent,效果还是不稳定?
我的答案很直接: 不是模型不够强。 是你还没有把它放进一套能稳定工作的系统里。
你们团队目前在用 AI Coding Agent时,最常翻车的是哪一类问题?
- 是需求说不清,Agent总靠猜?
- 是规则太散,写出来的代码风格老是跑偏?
- 还是测试和校验没接好,最后还得人肉兜底?
欢迎一起来交流讨论。
如果你也正在AI Coding,也欢迎把这篇转给正在折腾 AI coding workflow 的同事!
© 版权声明
文章版权归作者所有,未经允许请勿转载。














[db:评论]