
第一篇我们讲了一个判断:Claude Code CLI 的价值,不是把聊天窗口搬进终端,而是让 AI 进入真实项目,围绕文件、命令、测试和 Git 结果工作。
这篇就接着往下拆。
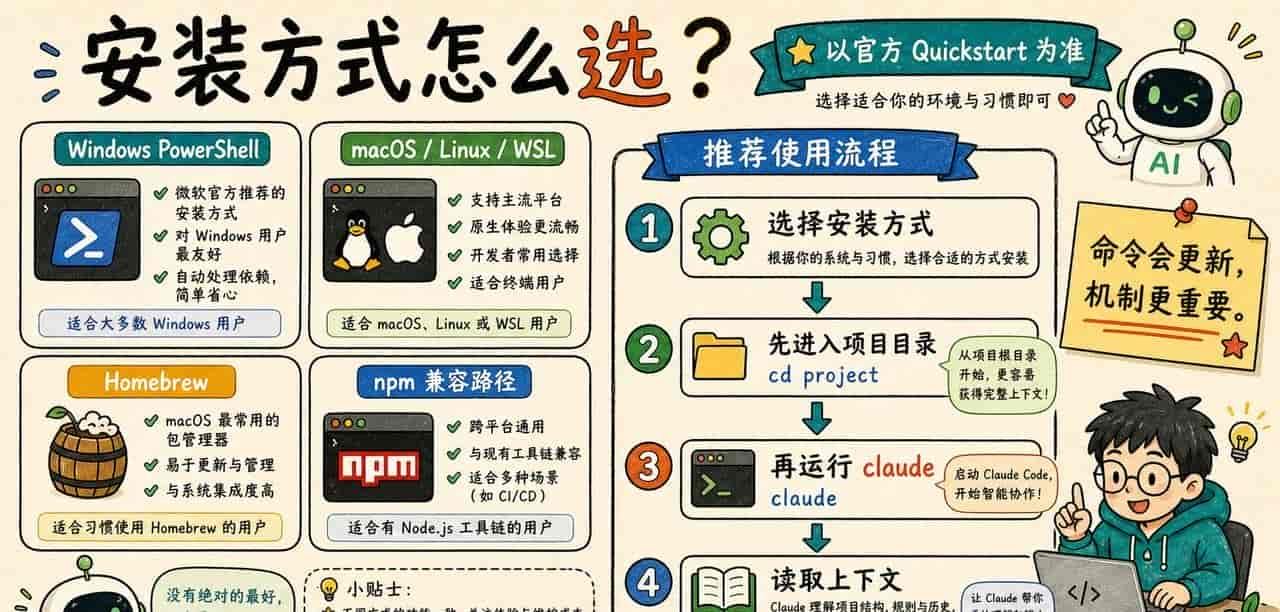
许多人第一次用 Claude Code,会把注意力全放在安装命令上:
irm https://claude.ai/install.ps1 | iex或者在 macOS、Linux、WSL 里运行:
curl -fsSL https://claude.ai/install.sh | bash命令当然重大,但它不是这篇文章的重点。真正决定 Claude Code 好不好用的,是你在哪个目录启动它、它能读到哪些项目规则、当前会话里已经塞进了哪些上下文。
也就是说,第一次使用 Claude Code 时,最该理解的不是“怎么装”,而是:
它启动后来,到底看到了什么?
官方 Quickstart 目前把原生安装放在主线位置。Windows PowerShell 使用 irm … | iex,macOS、Linux、WSL 使用 curl … | bash。你在一些文章里还会看到:
npm install -g @anthropic-ai/claude-code
这类路径曾经很常见,也可能在某些环境里还能用。但写文章和做教程时,不能只复制旧命令。比较稳的写法是:以当前官方 Quickstart 为准,把 npm 看成历史或兼容路径,不把它写成唯一推荐。
安装方式背后实则有三个问题:
第一,你的终端是什么。Windows PowerShell、CMD、Git Bash、WSL 不是一个东西。它们的路径格式、环境变量、Shell 能力、命令行为都可能不同。
第二,你的 Claude Code 从哪里启动。它不是在抽象空间里回答问题,而是在当前工作目录里开始理解项目。
第三,你愿意给它多大权限。Claude Code 能读文件、运行命令、编辑文件,这些能力很强,也意味着后面必须讲 settings、permissions 和 hooks。
所以我提议你把安装理解成“把工具放进终端”。真正的第一课,是进入一个项目目录,然后再启动它:
cd C:devmy-project
claude在这个动作里,cd 比你想象中更重大。
如果你在项目根目录运行 claude,Claude Code 面对的是整个项目。
如果你在 srcpayment 这种子目录运行它,它更容易先围绕这个局部模块理解问题。
如果你随手在桌面、下载目录、临时目录里运行它,再问“帮我分析项目”,它看到的起点就已经歪了。
这就是 CLI Agent 和网页聊天最大的差异之一:网页聊天靠你粘贴上下文,Claude Code 先从当前工作目录拿上下文。
可以这样理解:
当前终端目录
-> Claude Code 的项目入口
-> 文件搜索的起点
-> CLAUDE.md 规则查找的起点
-> Git / 测试 / 构建命令运行的现场这不是说 Claude Code 永远不能访问目录外的内容。真实边界还要看系统权限、工具权限和 settings 配置。这里讲的是“默认理解项目时,它从哪里开始”。
启动目录选错,后面的回答就会变形。
你让它解释项目结构,它可能只能看到一个子模块。
你让它找测试命令,它可能错过根目录的 package.json、pyproject.toml、Cargo.toml、go.mod。
你让它遵守团队规则,它可能没加载到上层的 CLAUDE.md。
所以第二篇先讲这个。
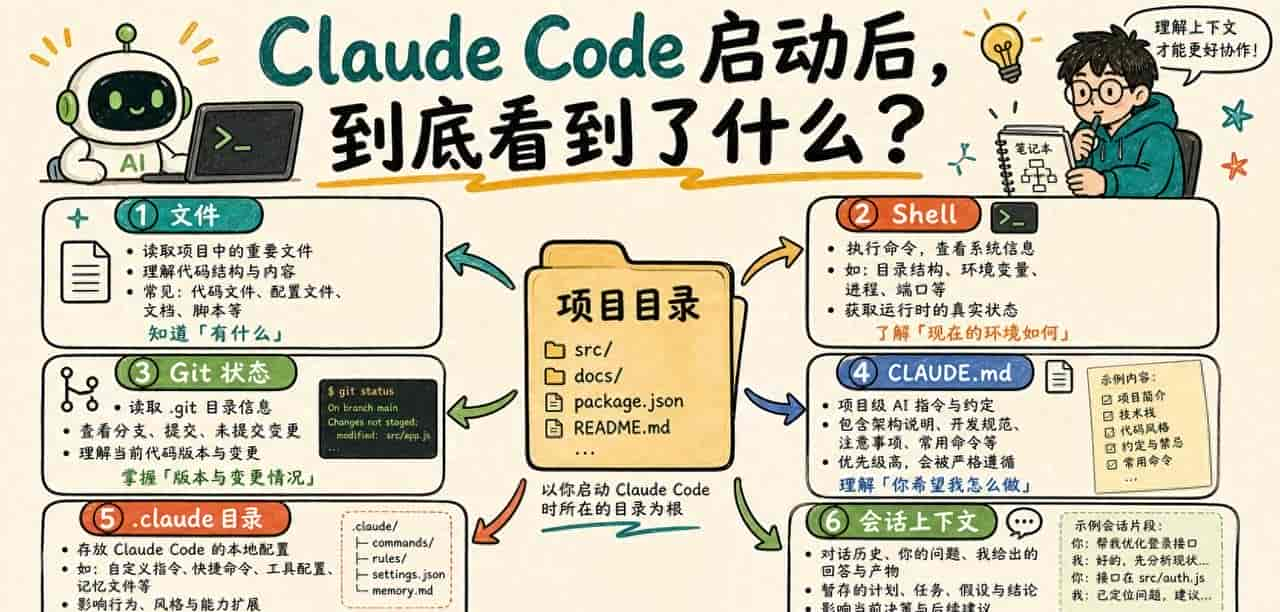
Claude Code 的上下文不是只有你输入的那一句话。它会从几个地方组合信息。
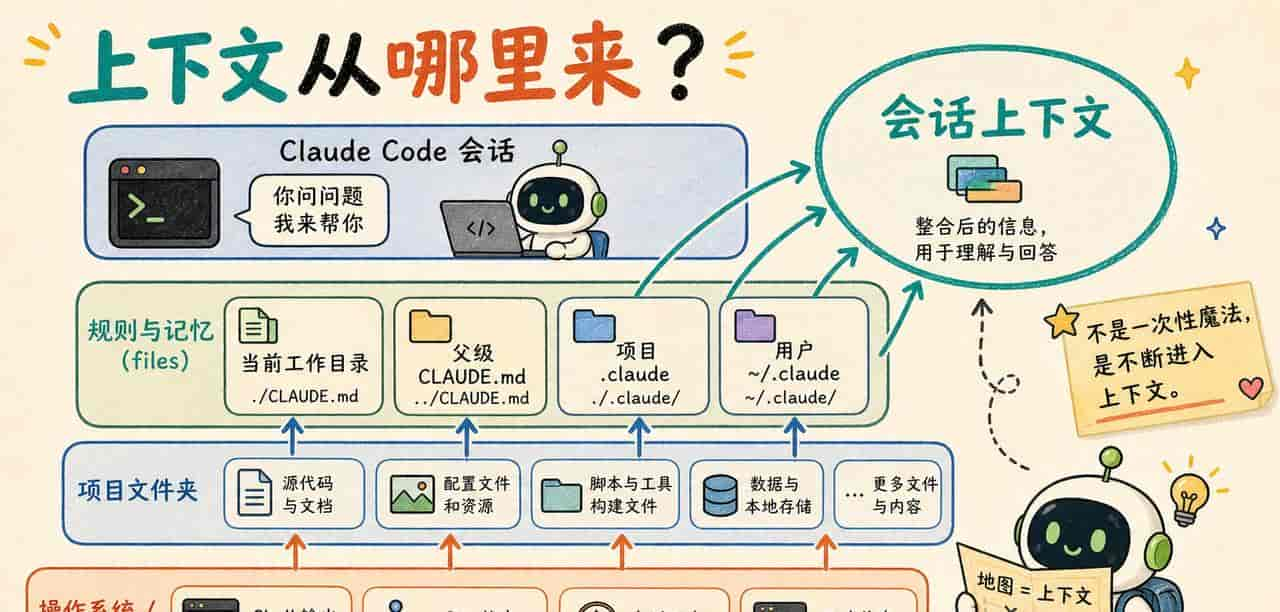
第一类是项目文件。
你启动在项目目录后,它可以读目录结构、打开文件、搜索关键字。你问它“入口文件在哪”,它不是凭感觉猜,而是可以看 README、配置文件、脚本和源码。
第二类是 Shell 环境。
Claude Code 运行在终端里,所以命令输出也会进入工作流。你让它跑测试,它能看到失败日志;你让它执行构建,它能看到编译错误;你用 Bash mode 的 ! 运行命令,命令和输出也会进入会话上下文。
第三类是 Git 状态。
这对真实项目很关键。修改前先看 git status,修改后看 git diff,比“只听 AI 解释它改了什么”可靠许多。
第四类是项目规则。
官方 Memory 文档里,CLAUDE.md 是超级关键的项目记忆文件。Claude Code 会从当前工作目录向上查找相关的 CLAUDE.md、CLAUDE.local.md,把项目说明、命令、风格约定、注意事项放进上下文。
第五类是 .claude 目录。
官方 .claude directory 文档把这块拆得很清楚:项目目录里的 .claude 和用户主目录里的 ~/.claude 都可能存放 instructions、settings、commands、skills、subagents、memory 等内容。
这也是为什么我不提议你第一次上来就说“帮我实现登录功能”。你还没确认它读到了什么,就让它动手,等于把方向盘交出去再看地图。
许多教程会写:
安装 -> 登录 -> claude -> /init -> 开始写代码
这个顺序没错,但太容易让人误解 /init。
/init 的价值不是“开启 Claude Code 的隐藏能力”,而是协助你生成或整理项目说明,一般会落到 CLAUDE.md 这类记忆文件里。
一个好的 CLAUDE.md,应该回答这些问题:
Project Notes
这个项目解决什么问题,主要用户是谁。
· 安装依赖:
· 本地启动:
· 运行测试:
· 代码检查:
· src/:
· tests/:
· docs/:
· 不要随意改公共 API。
· 修改前先说明影响范围。
· 提交前必须跑测试。
· 不读取 .env。
· 不打印 token、cookie、私钥。
· 涉及删除文件或批量替换时先确认。这东西看起来朴素,但它很像团队给 AI 的“项目说明书”。没有它,Claude Code 只能边看边猜。有它,Claude Code 至少知道你希望它怎么工作。
不过这里也要克制:不要把 CLAUDE.md 写成小说。太长、太散、太多废话,反而会污染上下文。
好的规则应该短、硬、可执行。
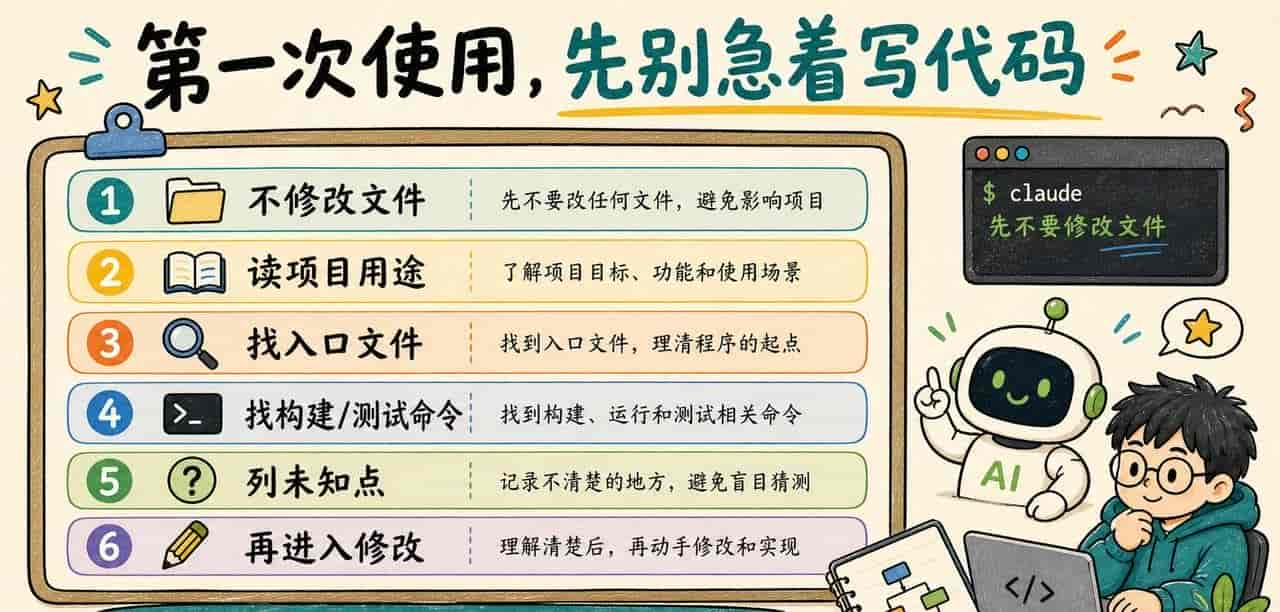
第一次打开 Claude Code,我提议先做一个“只读项目”的实践。
不要这样问:
帮我写一个登录功能。也不要这样问:
这个项目有 bug,你修一下。更稳的起手式是:
先不要修改任何文件。
请只做项目理解:
1. 总结这个项目的用途。
2. 识别主要技术栈。
3. 找出入口文件和核心目录。
4. 找出安装、启动、测试、构建命令。
5. 找出你目前还不确定、需要我确认的信息。
6. 最后给出一个“下一步可以安全执行”的计划。这个提示词看起来啰嗦,但它能帮你观察 Claude Code 的上下文是否正常。
你要看它有没有读 README。
你要看它有没有找到真正的入口。
你要看它有没有乱编命令。
你要看它有没有把不确定的地方说出来。
如果第一轮项目理解都不稳,后面让它改代码只会更危险。
我的习惯是:
第一次进项目,从根目录启动。
确认项目结构后来,再按任务缩小范围。
如果是 monorepo,可以先在根目录问“这个仓库如何组织”,再进入具体 package 做开发。
Claude Code 用久了,另一个常见坑是会话上下文太杂。
你刚让它分析支付模块,下一句又让它修登录模块;中间还跑了十几个命令;最后它开始引用旧任务里的假设。这个时候不是模型“突然变笨”,而是上下文脏了。
几个命令要分清:
/clear开启一个空上下文的新对话。官方文档说明,之前的对话不是被删除,依旧可以通过 /resume 找回。
/compact压缩当前对话的上下文,适合长任务继续做。它不是清空,而是把已有内容总结后继续。
/resume恢复以前的会话,适合回到一个中断过的任务。
我的提议很简单:
换任务,用 /clear。
同一任务太长,用 /compact。
隔天回来接着做,用 /resume。
不要把所有任务都塞进一个永远不清理的会话里。
常见的误区有:
第一个误区:把安装命令当成教程重点。
安装命令会变,官方文档会更新。真正长期有价值的是理解运行环境、工作目录和上下文来源。
第二个误区:第一次就让它改代码。
这很容易翻车。项目结构没读清楚、测试命令没找到、规则没加载,就开始改文件,后面只能靠运气。
第三个误区:把 CLAUDE.md 写成万能记忆。
它很重大,但不是越长越好。规则要可执行,命令要准确,边界要明确。
第四个误区:会话一直不清理。
任务切换时还沿用旧上下文,最容易出现“它怎么突然开始引用上个任务”的情况。
第五个误区:把启动目录当成安全边界。
启动目录影响 Claude Code 理解项目的起点,但不等于安全沙箱。真正的权限控制还要看 settings、permissions、系统权限和你的确认习惯。
第二篇的结论可以压成五句话:
1. 安装方式要看官方最新文档,不要只复制旧教程。
2. 第一次使用先进入项目根目录,再运行 claude。
3. 先让它读项目,不要直接让它写功能。
4. 用 CLAUDE.md 沉淀项目命令、规则和边界。
5. 换任务及时 /clear,长任务再思考 /compact。
下一篇我们进入真正的开发工作流:从读项目到改代码,Claude Code 应该怎么定位问题、提出计划、修改文件、跑测试、看 diff。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...










