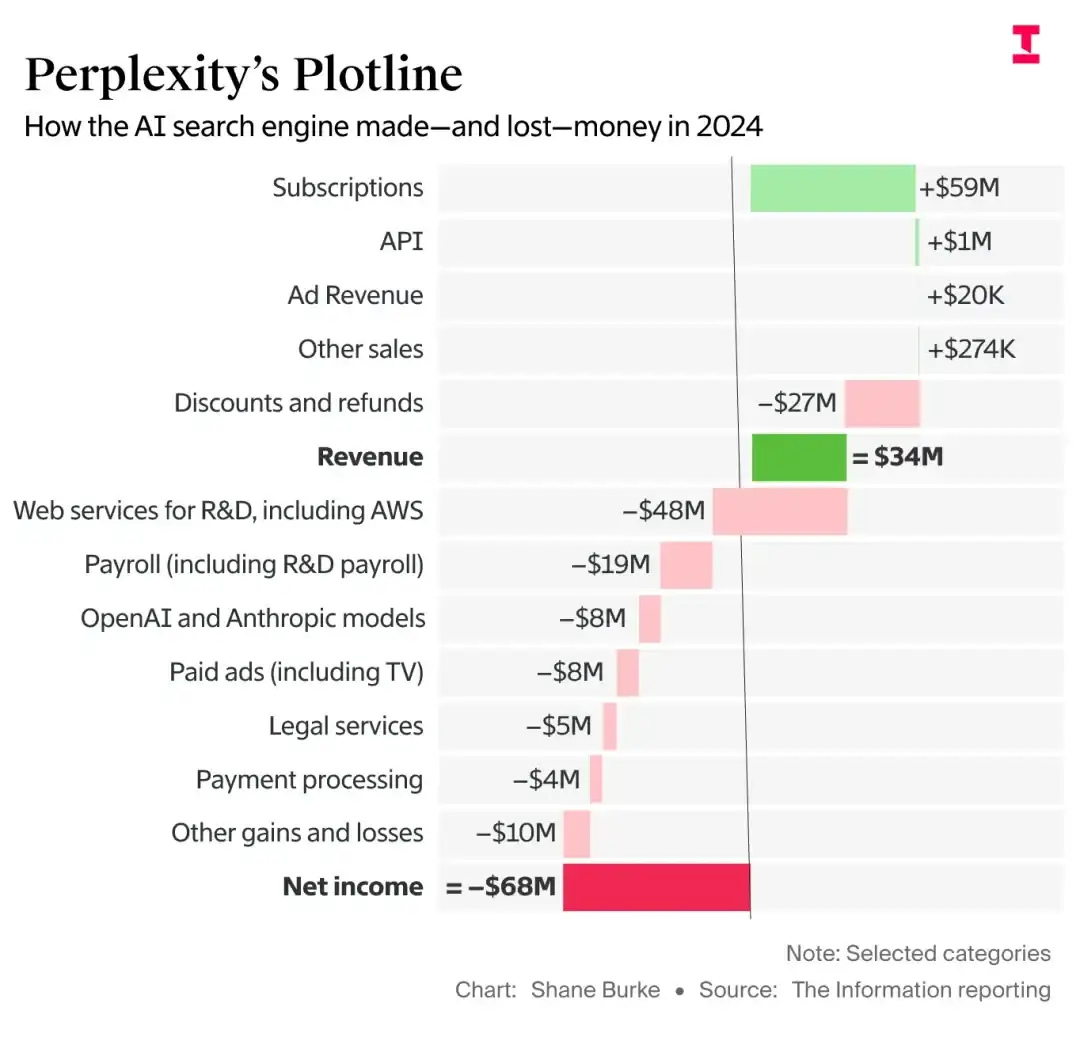
过去一个多月,不少开发者都在吐槽,Claude Code怎么像突然没那么机智了,回答变短了,前文记不住了,写代码也没以前稳了,甚至有人直接说它“降智”了。结果就在今天凌晨GPT-5.5亮相后,Anthropic也放出一份技术说明,正面回应这场风波。
它的说法很直接,不是模型本身退化了,是3次产品层面的改动撞在一起,最后把体验拖下去了。问题聚焦在Claude Code、Claude Agent SDK和Claude Cowork,核心API没有受影响。到4月20日,相关问题已经修完,4月23日起,所有订阅用户的额度也被重置了。
到底是哪3刀,砍出了这种“变笨”的感觉?
先看第一处,默认推理强度被调低了。
今年2月,Anthropic把Opus 4.6放进Claude Code时,默认是高强度思考模式,目的很简单,就是让模型更机智一点。可上线后,问题也跟着来了,思考时间拉长,等待更久,Token消耗也更快。对许多人来说,这就像你让一个程序员每道题都深思熟虑,质量可能更高,但速度明显慢了,成本也更贵。
怎么办,团队在3月4日把默认档位从高调到了中。按内部测试,这样做能减少卡顿,效率更高。可用户不必定买账,许多开发者宁愿默认更强,也不想自己再手动切换。结果呢,大家直观感受到的就是,Claude没有以前“灵”了。
这个误差很典型,产品团队想优化流畅度,用户却更在意能力上限。后来Anthropic在4月7日把设置改回去了,Opus 4.7默认恢复到更高档位,其他模型也重新拉高。
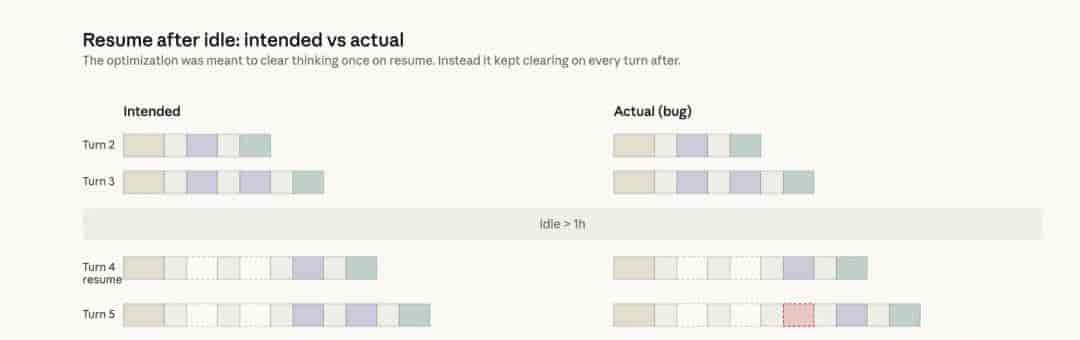
第二处问题更麻烦,是缓存优化出了漏洞,把模型搞“健忘”了。
3月26日,Anthropic上线会话缓存优化,本意是好事。简单说,就是会话闲置超过一小时后,系统清掉旧的思考记录,减轻负担,让恢复会话更快。正常设计下,这种清理只该发生一次,后面继续聊,历史再逐步接上。
但实际运行里,这个清理动作不是做一次就停,而是反复触发。只要会话进入那个状态,后续每一轮请求都可能继续丢历史。这样一来,模型表面上还在干活,实际上越来越记不清自己前面为什么这么做,结果就是回答重复,工具调用乱掉,上下文衔接也发飘。
不少人说,明明同一个项目接着聊,Claude却像中途失忆了,为什么?缘由就在这。更麻烦的是,历史反复丢失后,缓存命中变差,Token消耗反而更高,这也解释了为什么有用户发现额度掉得特别快。
这个漏洞4月10日修复。难点在于,它不是每次都出现,往往要在长时间闲置后才触发,内部测试一开始也没稳定复现。说白了,不是那种一眼就能抓住的毛病,而是藏在复杂交互里的小坑。
第三处问题,看着不起眼,影响却很实在,就是系统提示词改过头了。
随着Opus 4.7上线,模型处理复杂任务更强了,但话也更多了,输出更长,Token花得更快。为了压缩冗余,Anthropic在4月16日加了一条限制,要求工具调用之间的文字不超过25字,最终回复不超过100字,除非任务真的需要展开说。
乍一看,这像是在帮用户省钱省时间,谁不想要干脆利落的答案?问题在于,代码场景不是普通聊天,许多时候简短不等于高效,反而可能切掉关键解释、推理链和边界处理。后来更大范围测试发现,这条限制让Opus 4.6和Opus 4.7整体表现下降了约3%,团队在4月20日撤回了这项改动。
看到这里,许多人可能会问,一个默认档位,一个缓存漏洞,一个提示词限制,怎么会叠出这么明显的“降智感”?
关键就在叠加。单看任何一个改动,都像是局部优化。调低强度,是想减少等待。清缓存,是想提升效率。缩短输出,是想控制成本。每个动作都有道理,可它们同时作用到同一批用户身上,最后表现出来就是,想得没那么深了,记得没那么牢了,说得也没那么全了。用户当然会觉得,模型变弱了。
这种事实则不只发生在Anthropic。前些年,一些搜索产品为了提速,精简召回链路,结果首屏变快了,长尾问题却更难答准。还有自动驾驶软件更新后,城市路口表现更顺了,但在少见场景里会变保守,体验反而让老用户不适应。优化单点很容易,难的是别把别的地方带崩。
这次还有个细节挺有意思。Anthropic复盘时提到,用Opus 4.7回头分析相关代码提交,在给足代码仓库上下文后,它找出了那个漏洞,Opus 4.6却没发现。这至少说明一件事,模型能力本身没有统一往下掉,新版本在某些复杂分析任务上反而更强。
不过,用户感受也不是错的。你买的是产品,不是实验室指标。模型排行榜再美丽,真到每天写代码、接项目、改文件时,稳定、连贯、少出怪问题,这些才是最值钱的。谁会由于你理论上更强,就接受你一会机智一会失忆?
Anthropic目前给出的补救措施,包括扩大内部真实使用场景,收紧提示词修改流程,延长测试周期,还开了新的账号和讨论帖,专门对外同步进展。说得再直白一点,这次风波后,大模型公司要比的,已经不只是“谁更机智”,还有“谁更稳”。
眼下这个阶段,能力升级当然重大,但可靠性正变成新的分水岭。尤其在OpenAI、Anthropic这些厂商贴身竞争的时候,用户未必天天盯着榜单,他们更在意的是,今天打开工具,能不能像昨天一样好用,甚至更好用。
这次Claude没有真的“降智”,却被用户集体感知到“变笨”,本身就是个提醒。大模型时代,伤口不必定来自模型退步,许多时候,恰恰来自那些看起来合理的小修小补。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...