在现代分布式系统中,“锁”已从简单的多线程互斥,演进为跨机器、跨节点、跨服务的全局协调核心。用之不当,轻则业务重复执行,重则引发库存超卖、资金错乱、甚至系统雪崩。
Redis、etcd、Zookeeper 和数据库,作为实现分布式锁的四大主流中间件,它们有何不同?又该如何选择?本文将为您彻底揭晓。
一、核心诉求:一把可靠的分布式锁应具备什么?
分布式锁的本质,是在一个分布式系统中,对所有进程/节点可见的、互斥的“信号量”。一个健壮的实现必须满足以下核心要求:
|
核心要求 |
说明 |
如不满足的风险 |
|
互斥性 |
在任意时刻,只有一个客户端能持有锁。 |
锁根本失效,数据一致性遭破坏。 |
|
避免死锁 |
锁必须有自动释放机制(如超时),防止客户端宕机后锁永远无法释放。 |
系统出现永久性死锁,需要人工干预。 |
|
高可用 |
锁服务本身需要高可用,即使部分节点宕机,客户端也能正常进行加锁和解锁。 |
锁服务成为单点,一旦故障,整个系统停滞。 |
|
安全释放 |
只能由锁的持有者来释放锁,防止误删他人的锁。 |
锁被意外释放,导致多个客户端同时进入临界区。 |
|
性能可观 |
加锁、解锁的操作延迟不能成为系统瓶颈。 |
高并发下,锁本身成为性能瓶颈。 |
二、实现原理:四大方案技术内幕
所有分布式锁都依赖于一个所有客户端都能访问的中央存储系统,利用该系统的原子操作或一致性协议来保证互斥。
1. Redis 分布式锁:性能王者
Redis 因其极高的性能成为最流行的选择,其核心指令是原子性的 SET 命令。
加锁逻辑
# 关键命令:SET lock_key unique_value NX EX expire_time
SET stock_lock:product_001 8aadc8f9-90f1-4b4c-bf39-84ea89d73a42 NX EX 30- NX:仅当 lock_key 不存在时设置成功,保证互斥性。
- EX 30:设置 30 秒过期时间,保证避免死锁。
- unique_value(如 UUID):作为客户端的唯一标识,保证安全释放。
解锁逻辑(Lua 脚本保证原子性)
// unlock.lua
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end# 命令行调用
redis-cli --eval unlock.lua stock_lock:product_001 , 8aadc8f9-90f1-4b4c-bf39-84ea89d73a42核心挑战与解决方案
- 锁续期(Watch Dog):如果业务执行时间超过 30 秒,需要自动续期。可使用 Redisson 库的 WatchDog 机制。
- 主从切换风险(锁丢失):在异步复制的场景下,若主节点宕机,锁可能未同步到从节点,导致锁失效。
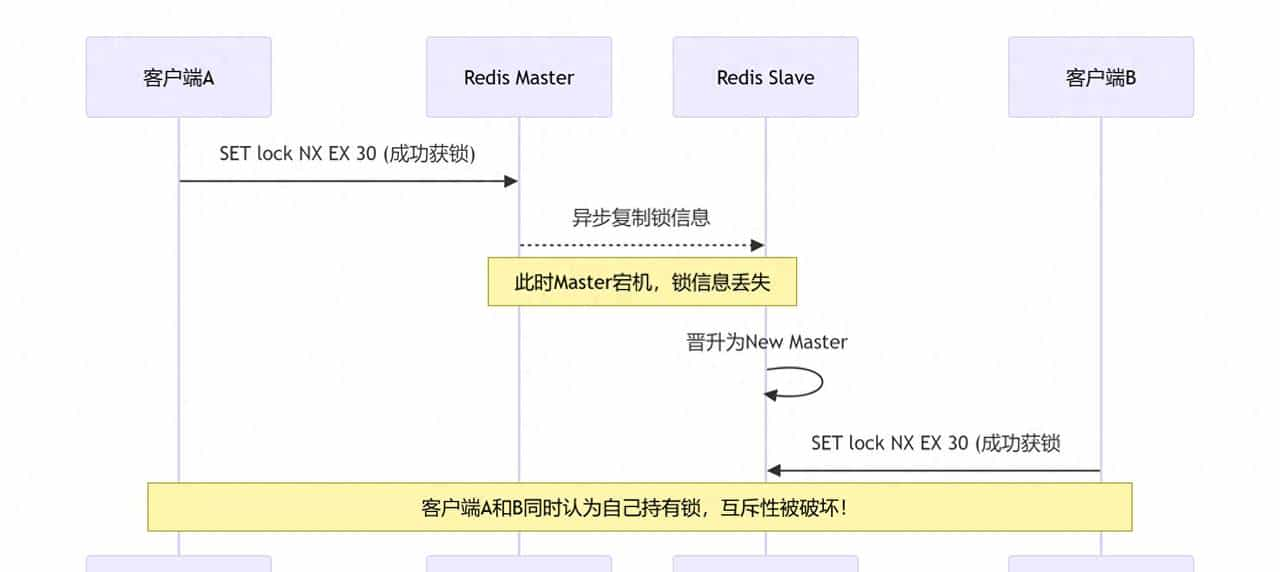
优点:性能极致、实现简单(有 Redisson 等成熟框架)。
缺点:在非强一致模式下存在锁丢失风险。
2. etcd 分布式锁:云原生新贵
etcd 基于 Raft 协议,天生强一致,是 Kubernetes 的基石,超级适合实现高可靠的分布式锁。
实现原理图解
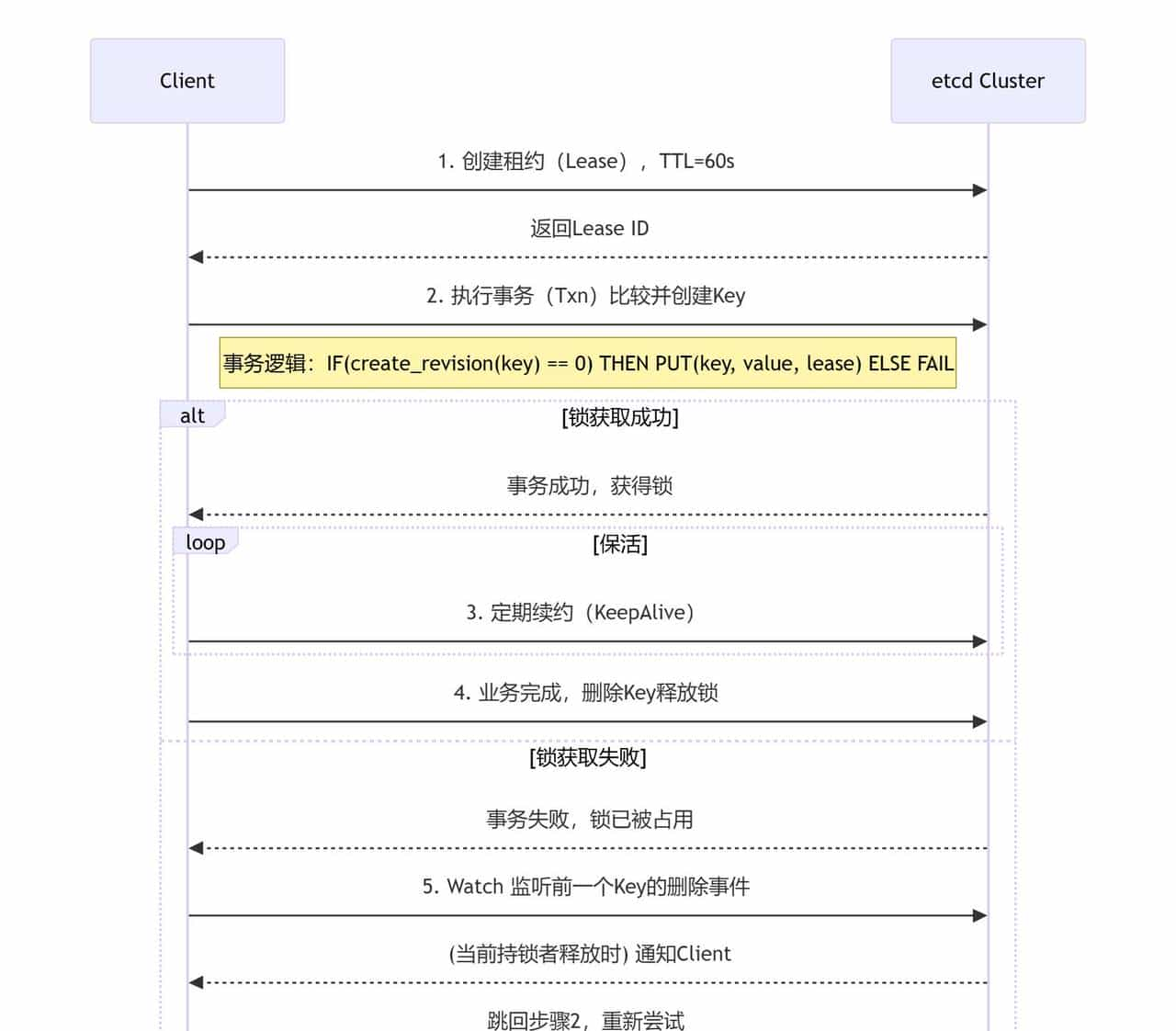
代码示例(Go)
// 使用 etcd/clientv3 包
func (m *Mutex) Lock(ctx context.Context) error {
// 1. 创建租约
leaseResp, err := m.client.Grant(ctx, 60)
if err != nil { return err }
m.leaseID = leaseResp.ID
// 2. 创建事务,尝试抢锁
cmp := v3.Compare(v3.CreateRevision(m.key), "=", 0) // Key不存在
put := v3.OpPut(m.key, m.val, v3.WithLease(m.leaseID))
get := v3.OpGet(m.key)
resp, err := m.client.Txn(ctx).If(cmp).Then(put).Else(get).Commit()
if !resp.Succeeded {
// 锁已存在,监听它(这里简化,实际应监听比自己序号小的key)
return errors.New("lock already held by another client")
}
// 抢锁成功,启动续约协程
m.keepAliveChan, err = m.client.KeepAlive(ctx, m.leaseID)
return err
}优点:强一致性、无锁丢失风险、Lease 机制简化续期。
缺点:性能低于 Redis、生态相对较新。
3. Zookeeper 分布式锁:一致性之王
ZK 通过临时有序节点(Ephemeral Sequential)和 Watch 机制实现公平的分布式锁。
实现流程
- 所有客户端在 /locks/lock_ 下创建临时有序子节点,例如:Client A 创建了 /locks/lock_000000001Client B 创建了 /locks/lock_000000002Client C 创建了 /locks/lock_000000003
- 检查序号:客户端检查自己创建的节点序号是否为当前最小。Client A 的序号是 1,最小,成功获取锁。
- 监听机制:非最小序号的客户端(如 Client B)监听比自己序号小 1 的节点(即监听 Client A 的节点)。
- 锁释放与唤醒:Client A 完成任务后,删除其节点 /locks/lock_000000001。ZK 会通知监听了该节点的 Client B。Client B 被唤醒后,重新检查序号,发现自己已是最小(此时只有 B 和 C),成功获取锁。
优点:强一致性、公平锁(先到先得)、临时节点自动删除防死锁。
缺点:性能较差(需频繁与 ZK 交互)、需要维护 ZK 集群,复杂度高。
4. 数据库分布式锁:简单备用方案
利用数据库的原子性实现,是最易理解但性能最低的方案。
方案1:基于唯一索引
-- 创建锁表
CREATE TABLE distributed_lock (
id BIGINT NOT NULL AUTO_INCREMENT,
resource_name VARCHAR(128) NOT NULL UNIQUE, -- 唯一资源名
owner VARCHAR(256) NOT NULL, -- 持有者标识
expire_time TIMESTAMP NOT NULL, -- 过期时间
PRIMARY KEY (id)
);
-- 加锁(成功插入则获锁)
INSERT INTO distributed_lock(resource_name, owner, expire_time)
VALUES ('order_123', 'service_A_uuid', NOW() + INTERVAL 30 SECOND);
-- 解锁
DELETE FROM distributed_lock WHERE resource_name = 'order_123' AND owner = 'service_A_uuid';需额外启动定时任务,清理过期的锁记录。
方案2:基于行级排他锁(SELECT FOR UPDATE)
BEGIN;
-- 此行会被加锁,其他事务的SELECT FOR UPDATE需等待
SELECT * FROM distributed_lock WHERE resource_name = 'order_123' FOR UPDATE;
-- ... 执行业务逻辑
COMMIT; -- 提交事务,释放锁优点:无需引入新组件,利用现有数据库,简单。
缺点:数据库性能瓶颈、死锁处理复杂、锁过期机制需自行实现。
三、终极选型指南
|
维度 |
Redis |
etcd |
Zookeeper |
数据库 |
|
一致性模型 |
最终一致性(主从异步) |
强一致性(Raft) |
强一致性(ZAB) |
依赖数据库隔离级别 |
|
性能 |
极高 |
中高 |
中低 |
极低 |
|
实现复杂度 |
低(有框架) |
中 |
高(需维护集群) |
低(无新组件) |
|
可靠性风险 |
主从切换可能丢锁 |
无风险 |
无风险 |
死锁、性能瓶颈 |
|
锁类型 |
非公平锁 |
公平锁 |
公平锁 |
非公平锁 |
|
典型场景 |
高并发秒杀、缓存击穿防护 |
云原生环境、K8s Operator、调度系统 |
金融核心交易、大数据调度(如HBase) |
系统 |
总结:
- 追求极致性能,业务可容忍极低概率的锁不一致 -> Redis(并确保使用 Redisson 等框架)。
- 身处云原生环境,或要求高可靠性、强一致性 -> etcd。
- 传统强一致性场景(如金融),且已有 ZK 技术栈和运维能力 -> Zookeeper。
- 业务简单,并发量很低,作为临时或过渡方案 -> 数据库。
分布式锁的选型是一门权衡艺术,理解其底层原理与业务场景的匹配度,是做出正确架构决策的关键。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...