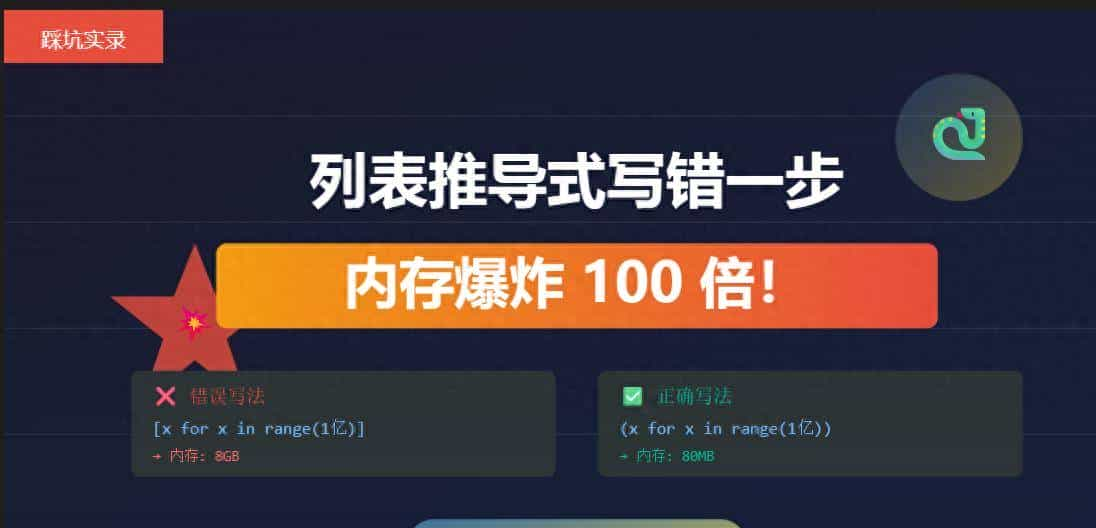
你以为列表推导式很简单?
一行代码写错,内存直接从 80MB 飙到 8GB!
今天分享一个真实踩坑经历,看完你就知道为什么了。
▶ 先看问题代码
同事写了一段处理数据的代码,跑着跑着服务器就 OOM 了。
```python
# ❌ 错误写法:内存爆炸
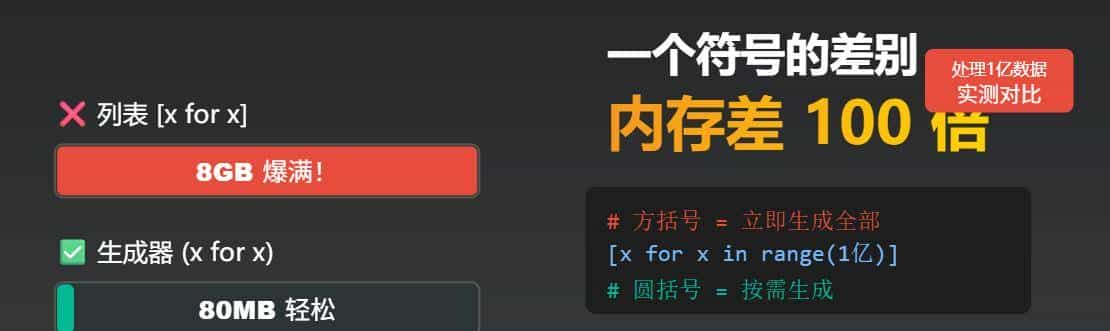
data = [x * 2 for x in range(100000000)] # 1亿条数据
```这行代码看起来没问题,但它会**立即在内存中创建 1 亿个元素的列表**!
我用 memory_profiler 测了一下:
```python
from memory_profiler import profile
@profile
def bad_example():
data = [x * 2 for x in range(100000000)]
return sum(data)
bad_example()
```结果:内存占用 8GB!
▶ 正确写法:生成器表达式
只需要把方括号 `[]` 换成圆括号 `()`:
```python
# ✅ 正确写法:内存友善
data = (x * 2 for x in range(100000000)) # 生成器
```同样的测试:
```python
@profile
def good_example():
data = (x * 2 for x in range(100000000))
return sum(data)
good_example()
```结果:内存占用只有 80MB!
差了 100 倍!
▶ 为什么差这么多?
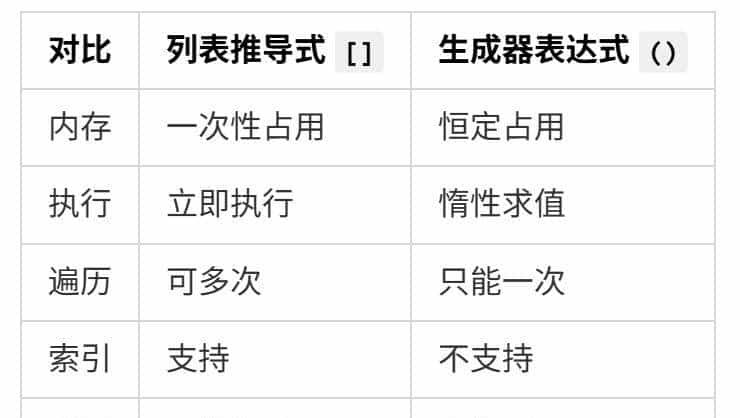
列表推导式 `[]`:
- 立即执行,一次性生成所有元素
- 所有数据都存在内存里
- 数据量大时,内存直接爆炸
生成器表达式 `()`:
- 惰性求值,用到才计算
- 每次只生成一个元素
- 内存占用恒定,不随数据量增长
```python
# 列表:立即生成全部
[x for x in range(1000000)] # 内存中有100万个元素
# 生成器:按需生成
(x for x in range(1000000)) # 内存中只有1个元素
```▶ 什么时候用哪个?
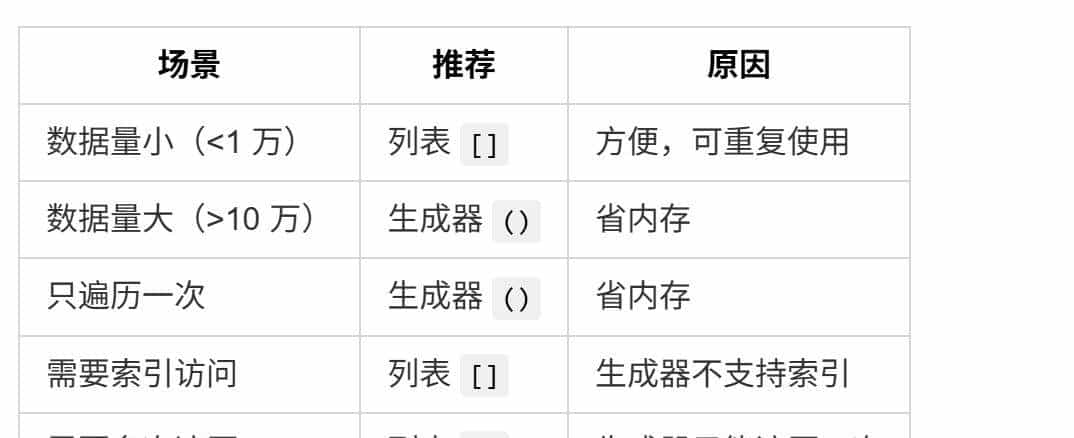
记住这个原则:
数据量大 + 只遍历一次 = 用生成器!

▶ 实战对比
处理一个 1000 万行的日志文件:
```python
# ❌ 错误:一次性读入内存
lines = [line.strip() for line in open('huge.log')]
result = [line for line in lines if 'ERROR' in line]
# ✅ 正确:流式处理
lines = (line.strip() for line in open('huge.log'))
result = (line for line in lines if 'ERROR' in line)
# 只在需要时才真正读取
for error_line in result:
print(error_line)
```效果:
- 错误写法:内存占用 2GB+
- 正确写法:内存占用 < 10MB
▶ 更多省内存技巧
1、用 itertools 处理大数据
```python
import itertools
# 取前100个
first_100 = itertools.islice(huge_generator, 100)
# 链接多个生成器
combined = itertools.chain(gen1, gen2, gen3)
```2、用 yield 写生成器函数
```python
def read_large_file(file_path):
with open(file_path) as f:
for line in f:
yield line.strip()
# 使用
for line in read_large_file('huge.log'):
process(line)
```3、pandas 分块读取
```python
import pandas as pd
# ❌ 一次性读取
df = pd.read_csv('huge.csv') # 内存爆炸
# ✅ 分块读取
for chunk in pd.read_csv('huge.csv', chunksize=10000):
process(chunk)
```▶ 常见误区
误区 1:生成器更慢?
不必定!生成器省去了内存分配的开销,有时反而更快。
误区 2:生成器可以重复使用?
不行!生成器只能遍历一次,遍历完就空了。
```python
gen = (x for x in range(5))
print(list(gen)) # [0, 1, 2, 3, 4]
print(list(gen)) # [] 空了!
```误区 3:所有地方都用生成器?
不对!数据量小的时候,列表更方便,可以索引、切片、多次遍历。
【总结】
一句话总结:
数据量大就用 `()`,数据量小就用 `[]`,别搞混了!
━━━━━━━━━━━━━━━━━━━━
觉得有用的话,点个赞收藏一下吧!
有问题可以在评论区留言,我会回复的~
关注我,持续分享 Python 实战技巧!#程序员##开发##代码##Python#
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...