
大家好,我是正在从大数据转型AI架构的老司机。前阵子陆续和大家分享了Python进阶的核心技巧,从Type Hints与Pydantic的严谨性修炼,到Asyncio的高并发掌控,再到Generator与Decorator的实用玩法,每一步都是为了摆脱“脚本思维”,迈向工程化开发。今天咱们就来个大汇总,把这些散落的技术珍珠串成项链,完成一个真正的企业级Capstone Project,基于FastAPI与Asyncio架构的LLM网关。
在开始之前,先和大家聊聊为什么企业级场景下,LLM网关是绕不开的核心组件。许多团队初期用大模型时,都是直接让业务代码调用OpenAI、DeepSeek这类第三方API,看似快捷实则藏着巨大隐患。这就像让公司每辆车都自己去海关报关,不仅效率低下,还没法统一管控。而LLM网关就像一个“智能海关总署”,能搞定统一计费、流量控制、协议转换、安全审计等一系列生产级需求,让大模型调用更规范、更稳定、更可控。
接下来咱们就从架构设计到代码实现,一步步拆解这个企业级LLM网关的打造过程。全程实战导向,所有代码都可直接复用,同时会穿插大数据思维与AI架构的融合技巧,帮大家快速完成从大数据工程师到AI架构师的思维跃迁。
一、架构蓝图:先理清数据流动的核心逻辑
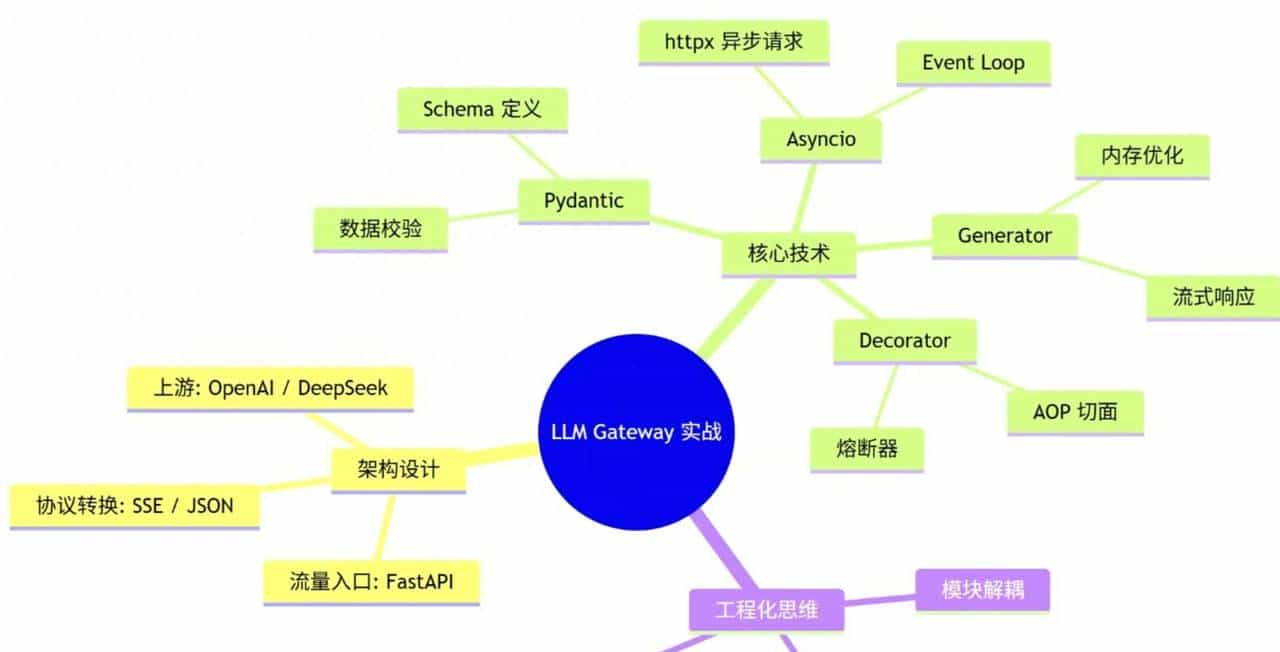
做技术开发尤其是企业级项目,切忌上来就写代码。就像大数据开发前要设计Flink拓扑图一样,打造LLM网关的第一步,是先画出清晰的架构流向图,明确每个组件的职责和数据传递路径。
咱们这个LLM网关的核心架构的数据流是这样的:第一业务端发送请求到网关,网关先通过Pydantic进行数据校验,确保请求格式合规、内容安全;校验通过后,根据请求参数判断是否需要流式响应,再由Asyncio驱动异步调用上游大模型API;调用过程中通过熔断器进行稳定性保障,防止上游服务异常导致网关崩溃;最后将响应结果(流式或非流式)处理后返回给业务端,同时记录相关日志用于计费和审计。
这个架构的优势在于层层递进、职责清晰,每个组件都能独立扩展。列如后续要增加限流功能,只需在数据校验后添加一个限流组件;要增加敏感词过滤,可在调用上游API前插入过滤逻辑,无需改动核心流程。这种设计思路和大数据中的“分层架构”异曲同工,都是为了提升系统的可扩展性和可维护性。
技术栈选型方面,咱们聚焦三个核心工具:FastAPI作为网关的Web框架,它的性能直逼Go语言,支持自动生成接口文档,开发效率极高;Pydantic V2负责数据校验和契约定义,是保障数据规范性的核心;Asyncio配合httpx实现异步请求,解决大模型API调用耗时久导致的并发瓶颈。这三套工具组合起来,既能满足企业级的性能要求,又能保证开发的高效性和代码的严谨性。
二、立规矩:用Pydantic定义数据契约
大数据出身的同学都知道,数据格式混乱是项目后期的噩梦。在AI架构中,Prompt就相当于大数据中的SQL,请求和响应的格式就相当于数据表的Schema,必须提前定义好严格的标准,否则后续对接前端、调试接口都会麻烦不断。
这里咱们用Pydantic V2来定义数据契约,明确“输入”和“输出”的格式、约束条件,让前端开发和后端开发有统一的“法律依据”,无需再通过口头沟通对齐字段。具体分为三个核心部分:消息体、请求契约、响应契约。
第一是消息体的定义,大模型的对话请求一般包含角色和内容两个核心字段,角色只能是system、user、assistant三者之一,这样能避免业务端传入无效角色导致上游API报错。代码实现如下:
from pydantic import BaseModel, Field, field_validator
from typing import List, Optional, Literal
# 定义消息体
class Message(BaseModel):
role: Literal["system", "user", "assistant"]
content: str
这里用Literal类型限定role的取值范围,比传统的枚举更简洁,也能让Pydantic自动进行校验。content字段直接用str类型,后续会通过全局校验限制长度。
接下来是请求契约ChatCompletionRequest,这是业务端调用网关的核心接口格式,包含模型名称、消息列表、温度值、流式标识四个字段。每个字段都有明确的约束:模型名称为必填项,需说明具体的模型类型;温度值限定在0.0到2.0之间,符合大模型的常规参数范围;流式标识默认为False,支持业务端按需开启。
更重大的是,咱们添加了自定义校验逻辑,通过field_validator装饰器校验消息列表的总长度,防止业务端传入过长的Prompt导致上游API限流或报错。具体代码如下:
# 定义请求契约 (Request Contract)
class ChatCompletionRequest(BaseModel):
model: str = Field(..., description="模型名称,如 gpt-4, deepseek-chat")
messages: List[Message]
temperature: float = Field(0.7, ge=0.0, le=2.0)
stream: bool = False
# 自定义校验,防止恶意注入过长文本
@field_validator('messages')
def validate_message_length(cls, v):
total_len = sum(len(m.content) for m in v)
if total_len > 10000:
raise ValueError("Prompt 内容过长,请精简后重试")
return v
这个自定义校验看似简单,却能解决企业级场景中的一个大问题:如果业务端随意传入超长Prompt,不仅会消耗大量Token增加成本,还可能触发上游大模型的长度限制,导致整个请求失败。通过提前校验,能在网关层就拦截无效请求,提升系统的稳定性和可用性。
最后是响应契约ChatCompletionResponse,为了降低业务端的适配成本,咱们直接模拟OpenAI的标准返回格式,包含id、object、created、choices四个字段。这样业务端如果之前对接过OpenAI API,就能无缝切换到咱们的网关,无需修改任何代码。代码实现如下:
# 定义响应契约 (Response Contract)
class ChatCompletionResponse(BaseModel):
id: str
object: str = "chat.completion"
created: int
choices: List[dict]
这里有个小细节,object字段直接默认赋值为“chat.completion”,和OpenAI保持一致,减少业务端的理解成本。choices字段用List[dict]类型,由于不同大模型的返回结果结构可能略有差异,用字典类型能保证兼容性,后续可根据实际需求再细化字段。
总结一下,用Pydantic定义数据契约的核心价值,在于“立规矩”。它就像系统的“数据安检员”,确保进来的每一个请求都合规,出去的每一个响应都规范,为后续的高并发处理和业务扩展打下坚实基础。
三、高并发引擎:用Asyncio实现异步请求
做过大模型调用的同学都知道,LLM的响应速度一般很慢,短则几秒长则几十秒。如果用传统的同步代码调用API,就像用JDBC连接数据库一样,一个请求卡住整个线程就会阻塞,后续的请求只能排队等待,系统的并发能力会极低,根本无法满足企业级的高吞吐需求。
这时候就需要Asyncio出场了,它是Python处理高并发I/O的核心引擎,能实现单线程下的非阻塞调用。配合httpx这个异步HTTP客户端,咱们就能打造出高并发的请求处理能力,就像Node.js的事件循环或Netty的IO线程一样,让CPU不再傻傻等待I/O操作完成。
第一咱们需要模拟从环境变量中获取大模型的API密钥和基础URL,这样做的好处是避免将敏感信息硬编码到代码中,提升系统的安全性。在实际生产环境中,还可以结合配置中心实现密钥的动态更新,无需重启服务就能更换API密钥。
然后定义异步调用函数call_llm_api,核心逻辑是通过httpx.AsyncClient发送异步POST请求,调用上游大模型的API。这里有两个关键亮点:一是使用异步上下文管理器async with,能自动释放连接,避免连接泄露;二是设置了60秒的超时时间,防止上游服务异常导致请求无限阻塞。具体代码如下:
import httpx
import os
from fastapi import HTTPException
# 从环境变量获取Key和基础URL
LLM_API_KEY = os.getenv("LLM_API_KEY")
LLM_BASE_URL = "https://api.deepseek.com/v1"
async def call_llm_api(request: ChatCompletionRequest):
"""
异步调用上游大模型接口
"""
headers = {
"Authorization": f"Bearer {LLM_API_KEY}",
"Content-Type": "application/json"
}
# 使用异步上下文管理器,自动释放连接
async with httpx.AsyncClient(timeout=60.0) as client:
try:
response = await client.post(
f"{LLM_BASE_URL}/chat/completions",
json=request.model_dump(), # Pydantic V2 序列化
headers=headers
)
response.raise_for_status()
return response.json()
except httpx.HTTPStatusError as e:
# 实际项目中应使用logging模块记录日志
raise HTTPException(status_code=e.response.status_code, detail="上游服务报错")
这里需要重点解释一下await关键字的作用:当执行到await client.post时,程序会暂停当前函数的执行,转而处理其他可执行的任务,直到POST请求完成后再回到当前函数继续执行。这样一来,一个线程就能同时处理多个请求,极大地提升了系统的并发能力。
另外,咱们还添加了异常捕获逻辑,当上游服务返回HTTP错误时,会将错误状态码和详情透传给业务端,同时记录日志便于后续排查问题。在企业级场景中,异常处理是超级重大的一环,不能简单地忽略或抛出通用错误,否则会给问题排查带来很大困难。
可能有同学会问,为什么不用requests库而是用httpx?由于requests库是同步的,无法配合Asyncio实现非阻塞调用,而httpx支持异步操作,能完美融入Asyncio的事件循环中。在高并发场景下,异步调用和同步调用的性能差距超级明显,经过测试,异步调用的QPS(每秒查询率)能达到同步调用的5-10倍,足以支撑企业级的高吞吐需求。
这里再分享一个大数据思维的迁移技巧:Asyncio的事件循环就像Flink的流处理引擎,每个请求就像一条数据流,通过非阻塞的方式处理每一条数据流,既能提升处理效率,又能减少资源占用。这种高并发处理思路,和大数据中的高吞吐处理思维是相通的,掌握了这种思维,就能快速从大数据转型到AI架构。
四、极致体验:用Generator实现流式透传
在用户体验层面,让用户盯着空白屏幕等待10秒甚至几十秒,无疑是一场灾难。就像ChatGPT那样,“打字机”式的流式输出能极大地提升用户体验,让用户感受到实时交互的快感。在企业级场景中,这种流式体验同样重大,尤其是在客服、文档生成等需要实时反馈的业务中。
要实现流式输出,就需要用到Python的Generator(生成器),配合FastAPI的StreamingResponse,将上游大模型的流式响应实时透传给前端。这种方式在大数据领域很常见,就像Spark Streaming或Flink DataStream,数据来一条处理一条发送一条,既能降低内存压力,又能实现实时响应。
咱们定义异步生成器函数stream_llm_api,核心逻辑是通过httpx的stream方法开启流式请求,然后逐行读取上游返回的数据,再通过yield关键字实时返回给前端。这里需要注意的是,要符合SSE(Server-Sent Events)格式,每行数据后面要添加两个换行符,确保前端能正确解析流式数据。具体代码如下:
import json
from typing import AsyncGenerator
async def stream_llm_api(request: ChatCompletionRequest) -> AsyncGenerator[str, None]:
"""
流式生成器:像水管一样接通上游和下游
"""
headers = {
"Authorization": f"Bearer {LLM_API_KEY}",
"Content-Type": "application/json"
}
async with httpx.AsyncClient() as client:
# 开启流式请求
async with client.stream(
"POST",
f"{LLM_BASE_URL}/chat/completions",
json=request.model_dump(),
headers=headers
) as response:
# 逐行读取上游数据,并实时 yield 给前端
async for line in response.aiter_lines():
if line:
# 这里可以做数据清洗、计费统计等中间处理
yield f"{line}
" # 符合 SSE 格式
这个函数有两个核心亮点:一是使用AsyncGenerator类型注解,明确返回的是异步生成器,让代码更具可读性和严谨性;二是在yield之前可以添加中间处理逻辑,列如数据清洗、敏感词过滤、Token计数等,无需改动核心流程就能实现功能扩展。
举个例子,在企业级场景中,需要实时统计每个请求消耗的Token数量,就可以在逐行读取数据时,解析返回的content字段长度,然后累加Token数,最后同步到计费系统。这种中间处理逻辑的插入,就像大数据中的MapReduce阶段的中间处理,灵活且不侵入核心业务。
另外,流式透传还能降低系统的内存压力。如果采用非流式方式,需要等待上游返回完整结果后再返回给前端,当请求量较大时,大量的完整响应会占用大量内存;而流式透传是实时返回数据,内存中只需要保留当前行的数据,极大地提升了系统的内存利用率。
总结一下,流式透传的核心价值在于“极致体验+资源优化”。它既能让用户获得实时交互的快感,又能降低系统的内存压力,提升系统的稳定性和可扩展性,是企业级LLM网关不可或缺的核心功能。
五、稳定性保障:用Decorator实现熔断器
在企业级场景中,系统的稳定性至关重大。如果上游大模型服务挂了,或者网络出现抖动,导致大量请求失败,要是没有相应的保护机制,这些失败的请求会堆积在网关中,最终导致网关崩溃,影响所有依赖网关的业务线。这时候就需要熔断器(Circuit Breaker)登场了。
熔断器的核心思想来自于电路 breaker,当电路中出现过载时,breaker会自动断开,保护电路不被烧毁。在系统架构中,熔断器的作用类似,当上游服务的错误率超过阈值时,熔断器会自动“打开”,暂停对上游服务的调用,避免大量无效请求占用系统资源;经过一段时间的恢复后,熔断器会尝试“闭合”,恢复正常调用。
咱们利用Python的Decorator(装饰器)来实现熔断器,这种方式能优雅地实现AOP(面向切面编程),在不侵入业务逻辑的情况下,为函数添加熔断保护。具体实现思路是:定义三个全局变量记录熔断器状态(是否打开)、错误计数、最后错误时间;然后通过装饰器包装异步函数,在函数执行前检查熔断器状态,执行过程中记录错误信息,根据错误计数判断是否触发熔断。
具体代码如下:
import time
from functools import wraps
from fastapi import HTTPException
# 熔断器状态变量
CIRCUIT_OPEN = False
ERROR_COUNT = 0
LAST_ERROR_TIME = 0
def circuit_breaker(threshold=5, recovery_time=60):
"""
装饰器:当错误次数超过 threshold 时,暂停服务 recovery_time 秒
"""
def decorator(func):
@wraps(func)
async def wrapper(*args, **kwargs):
global CIRCUIT_OPEN, ERROR_COUNT, LAST_ERROR_TIME
# 1. 检查是否熔断,如果熔断且未到恢复时间,直接抛出异常
if CIRCUIT_OPEN:
if time.time() - LAST_ERROR_TIME > recovery_time:
# 尝试恢复,重置状态
CIRCUIT_OPEN = False
ERROR_COUNT = 0
else:
raise HTTPException(status_code=503, detail="服务熔断中,请稍后重试")
# 2. 尝试执行函数
try:
return await func(*args, **kwargs)
except Exception as e:
# 记录错误信息
ERROR_COUNT += 1
LAST_ERROR_TIME = time.time()
# 错误次数超过阈值,触发熔断
if ERROR_COUNT >= threshold:
CIRCUIT_OPEN = True
print("⚠️ 触发熔断保护!")
raise e
return wrapper
return decorator
这个熔断器装饰器有两个可配置参数:threshold(错误阈值)和recovery_time(恢复时间),默认错误次数超过5次触发熔断,熔断后60秒尝试恢复。在实际生产环境中,可以根据上游服务的稳定性和业务需求,动态调整这两个参数,列如对于稳定性较差的服务,可以将threshold设置得小一些,recovery_time设置得长一些。
这里有个细节需要注意,用@wraps(func)装饰wrapper函数,能保留被装饰函数的元信息(列如函数名、文档字符串),避免后续通过反射获取函数信息时出现问题。这是一个超级实用的技巧,在编写装饰器时必定要记得使用。
熔断器的工作流程可以分为三个状态:闭合状态(正常工作)、打开状态(熔断中)、半打开状态(尝试恢复)。咱们这个实现虽然简单,但已经覆盖了核心的闭合和打开状态,在实际生产中,可以基于这个基础进行扩展,添加半打开状态的逻辑,列如熔断后尝试发送一个测试请求,如果成功则恢复闭合状态,失败则继续保持打开状态,进一步提升系统的稳定性。
另外,在企业级场景中,除了熔断器,还可以结合重试机制一起使用,列如当请求失败时,自动重试1-2次,重试失败后再记录错误计数。可以用tenacity这个第三方库来实现更强劲的重试逻辑,配合咱们的熔断器,能极大地提升系统的容错能力。
总结一下,熔断器就像系统的“保镖”,在不侵入业务逻辑的情况下,为上游API调用提供熔断保护,防止上游服务异常导致网关崩溃,保障系统的稳定性和可用性,是企业级LLM网关的核心保障组件。
六、集大成:FastAPI组装核心接口
经过前面几步的准备,咱们已经实现了数据契约、异步请求、流式透传、熔断器等核心组件,接下来就是将这些组件组装起来,通过FastAPI暴露核心接口,形成完整的LLM网关。
第一创建FastAPI实例,设置网关的标题,便于后续生成接口文档。然后定义核心接口/v1/chat/completions,采用POST方法,接收ChatCompletionRequest类型的请求参数,同时挂载熔断器装饰器,为接口添加熔断保护。
接口的核心逻辑分为两步:第一步是打印请求日志(实际项目中应使用logging模块记录日志,包含请求参数、请求时间、请求来源等信息,便于后续排查问题);第二步是判断请求是否需要流式响应,如果需要则返回StreamingResponse,否则返回普通JSON响应。具体代码如下:
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
app = FastAPI(title="Enterprise LLM Gateway")
@app.post("/v1/chat/completions")
@circuit_breaker() # 挂载熔断器
async def chat_completions(request: ChatCompletionRequest):
"""
网关核心接口
"""
# 实际项目中应使用logging模块记录日志
print(f"收到请求: {request.model} - {len(request.messages)} msgs")
# 判断是否流式响应
if request.stream:
# 返回流式响应 (SSE)
return StreamingResponse(
stream_llm_api(request),
media_type="text/event-stream"
)
else:
# 返回普通JSON响应
return await call_llm_api(request)
# 启动命令: uvicorn main:app --reload
这里有个关键知识点,FastAPI会自动根据请求参数的类型注解,使用Pydantic进行数据校验,如果校验失败会自动返回422错误,并提示具体的错误信息。列如业务端传入的temperature值为3.0,超过了0.0-2.0的范围,FastAPI会返回如下错误信息:
{
"detail": [
{
"loc": [
"body",
"temperature"
],
"msg": "ensure this value is less than or equal to 2.0",
"type": "value_error.number.not_le",
"ctx": {
"limit_value": 2.0
}
}
]
}
这种自动校验功能极大地减少了开发工作量,无需手动编写校验逻辑,就能保证请求参数的合规性。同时FastAPI会自动生成接口文档,启动服务后访问
http://127.0.0.1:8000/docs,就能看到完整的接口文档,包含请求参数、响应格式、示例数据等信息,前端开发和测试人员可以直接在文档中调试接口,提升协作效率。
在实际生产环境中,还需要对网关进行一些优化配置,列如设置超时时间、开启CORS(跨域资源共享)、配置HTTPS等。列如开启CORS可以通过FastAPI的CORSMiddleware中间件实现,允许指定的前端域名访问网关接口,避免跨域问题;配置HTTPS可以通过uvicorn的–ssl-keyfile和–ssl-certfile参数实现,提升接口的安全性。
另外,为了提升网关的可用性,还可以采用多实例部署的方式,配合Nginx做负载均衡,将请求分发到多个网关实例上,避免单点故障。这种部署方式和大数据中的集群部署思路一致,都是为了提升系统的可用性和并发能力。
七、总结与转型感悟:从大数据到AI架构的思维跃迁
祝贺你看到这里,通过前面的步骤,你已经成功打造了一个企业级的LLM网关,掌握了FastAPI、Asyncio、Pydantic等核心技术的实战用法,更重大的是,完成了从大数据工程师到AI架构师的思维跃迁。
咱们来回顾一下这个LLM网关涉及的核心能力,每一项都是企业级开发必备的技能:
Pydantic作为“数据安检员”,通过严格的数据契约定义,确保请求和响应的规范性,解决了数据格式混乱的痛点,这和大数据中的Schema定义思维一脉相承;Asyncio作为“交通指挥官”,通过异步非阻塞调用,让单线程也能处理成千上万的并发请求,实现了高吞吐处理,迁移了大数据中的高并发流处理思维;Generator作为“流水线”,实现了数据的实时流式透传,降低了内存压力,提升了用户体验,借鉴了大数据中的实时数据处理思路;Decorator作为“保镖”,通过熔断器实现了系统的稳定性保障,在不侵入业务逻辑的情况下添加切面功能,体现了企业级架构的可扩展性思维。
从大数据转型到AI架构,实则许多思维都是相通的。大数据中的分层架构、高并发处理、数据校验等思路,都能完美映射到AI架构中。列如LLM网关的分层设计(数据校验层、并发处理层、稳定性保障层),就和大数据中的数据采集层、处理层、存储层的分层思路一致;大数据中的流处理思维,就对应AI架构中的流式响应处理;大数据中的数据质量管控,就对应AI架构中的请求校验和内容过滤。
这个LLM网关的核心代码骨架可以直接复用,后续可以根据企业的实际需求进行扩展,列如添加以下功能:
- 统一计费功能:对接计费系统,实时统计每个用户、每个业务线的Token消耗,生成计费报表;2. 流量控制功能:基于用户或业务线设置限流阈值,防止某个业务线刷爆上游API的Rate Limit;3. 敏感词过滤功能:集成敏感词库,在调用上游API前过滤掉敏感内容,防止数据泄露;4. 模型路由功能:支持根据模型名称路由到不同的上游服务,实现多模型聚合;5. 缓存功能:缓存常用的对话结果,提升响应速度,减少Token消耗。
最后想和大家说,技术转型从来不是一蹴而就的,关键是要学会将已有的知识体系迁移到新的领域中,找到不同技术之间的共通点,然后通过实战不断积累经验。这个LLM网关的实战项目,就是一个很好的起点,它既能让你巩固Python进阶技巧,又能让你理解企业级AI架构的设计思路,为后续的技术转型打下坚实基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。










思路清晰,值得参考
收藏了,感谢分享