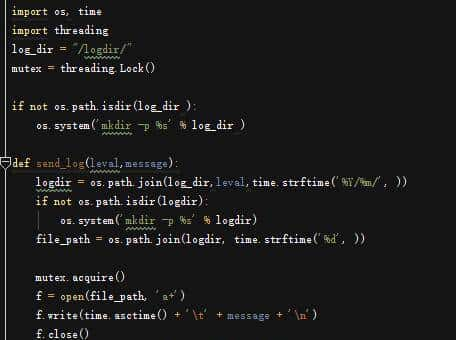
从上一篇的文章,我们知道了什么是梯度对抗攻击和前沿攻击的方向推演,那么接下来,我们就开始进行实战演练解说,本文从原来的经典攻击上升到可能未来的攻击的手段大致方向,当然,我也会列举出可能的攻击方向。
但是我要注意告知,我们的这个代码是作用于代码原理逻辑教学,不涉及到攻击具体目标,仅用于教学演练。
好的,那么我们从最基本的三种梯度对抗攻击方法说起,在开始从这三种攻击的角度去推演出更多的可能性,最后再次去做防御的架构体系,我会去阐明可以从哪些方面进行攻击,我也会去说从哪些方面去防御,针对哪些方向,做出的相应的调整,在文章的最后,我会告诉大家我的总结和个人的观点。
首先,对于这个攻击,我们要搞清楚这是怎么攻击的,我自己写了一副图,给大家说明一下,具体的流程是怎么样的:
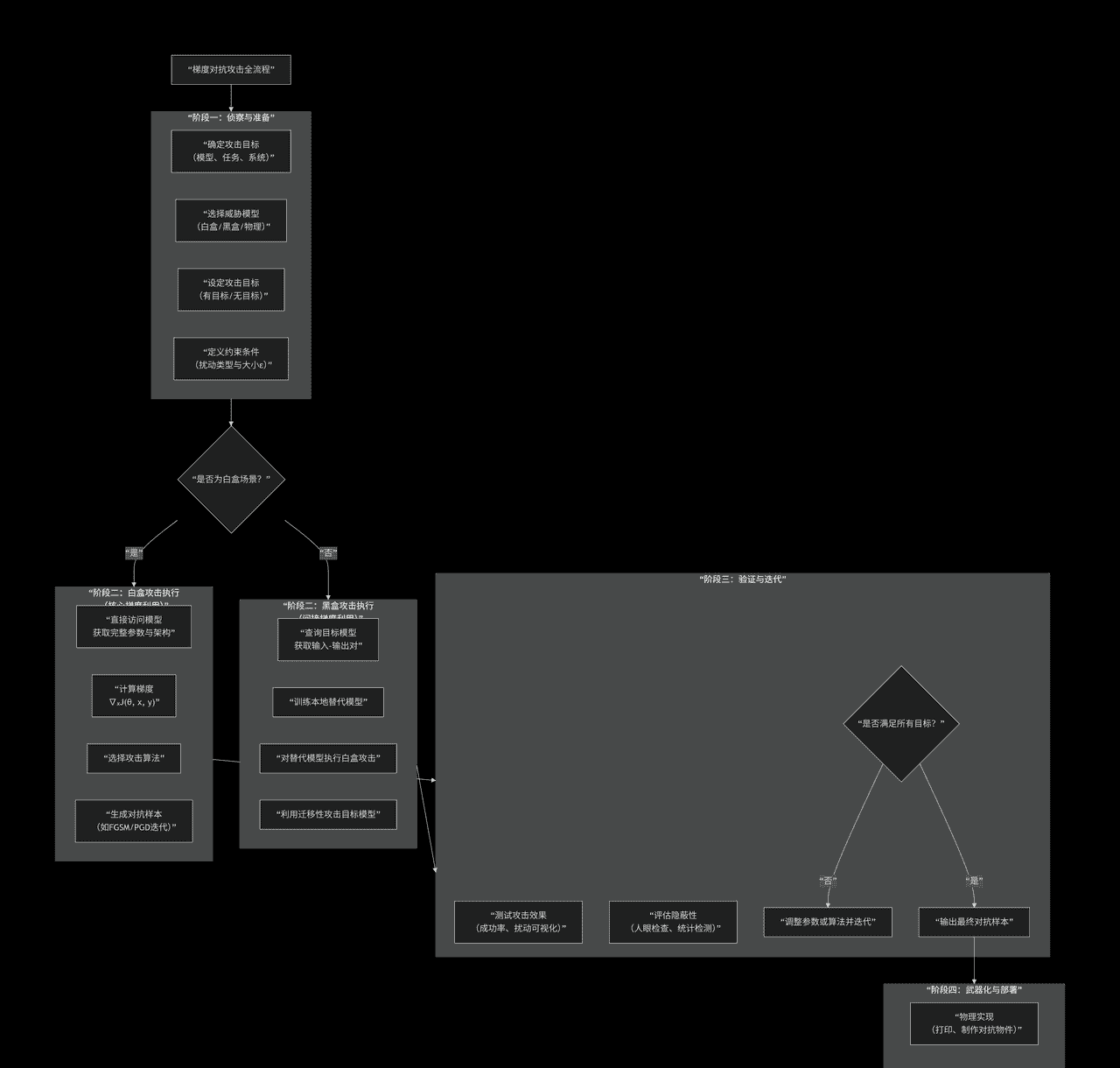
了解到了上述工作流程,那么我们接下来就开始去做一些测试类型的攻击脚本,但是我要告诉各位读者,我的这个攻击不涉及到攻击具体目标,对于任何使用我的攻击代码的角度去攻击任何的AI大模型,本人一律不负责。
一,FGSM攻击原理流程和代码解释
1,原理:
FGSM(Fast Gradient Sign Method)是由Goodfellow等人提出的一种快速对抗攻击方法。其核心思想是:沿着损失函数梯度方向添加扰动,使模型产生错误分类。
2,流程
前向传播计算损失反向传播计算梯度获取梯度的符号方向添加扰动到原始输入
3,代码
class FGSMAttack:
def __init__(self, model, epsilon=0.03):
"""
初始化FGSM攻击器
参数:
model: 目标模型
epsilon: 扰动强度
"""
self.model = model
self.epsilon = epsilon
self.criterion = nn.CrossEntropyLoss()
def attack(self, images, labels):
"""
执行FGSM攻击
参数:
images: 原始图像 [batch, channels, height, width]
labels: 真实标签
返回:
perturbed_images: 对抗样本
"""
# 确保梯度计算
images.requires_grad = True
# 前向传播
outputs = self.model(images)
loss = self.criterion(outputs, labels)
# 清空梯度并反向传播
self.model.zero_grad()
loss.backward()
# 获取梯度符号
gradient_sign = images.grad.data.sign()
# 生成对抗样本
perturbed_images = images + self.epsilon * gradient_sign
# 确保像素值在合理范围 [0, 1]
perturbed_images = torch.clamp(perturbedimages,0,1)
return perturbed_images.detach()这里说明一下
requires_grad=True
sign()
clamp()
二,FGSM防御原理流程和代码解释
1,原理:
针对FGSM的防御主要采用对抗训练,即在训练过程中加入对抗样本,提高模型鲁棒性。
2,流程:
正常训练模型
对训练数据生成对抗样本
混合原始样本和对抗样本进行训练
重复直到收敛
3,代码:
class FGSMDefense:
def __init__(self, model, epsilon=0.03, alpha=0.01):
"""
初始化FGSM对抗训练防御
参数:
model: 待训练的模型
epsilon: 攻击扰动强度
alpha: 训练学习率
"""
self.model = model
self.epsilon = epsilon
self.alpha = alpha
self.criterion = nn.CrossEntropyLoss()
self.optimizer = torch.optim.Adam(model.parameters(), lr=alpha)
def adversarial_training_step(self, images, labels):
"""
单步对抗训练
参数:
images: 训练图像
labels: 训练标签
返回:
loss: 训练损失
"""
# 生成对抗样本
attacker = FGSMAttack(self.model, self.epsilon)
adv_images = attacker.attack(images, labels)
# 混合原始和对抗样本
mixed_images = torch.cat([images, adv_images], dim=0)
mixed_labels = torch.cat([labels, labels], dim=0)
# 模型训练
self.model.train()
self.optimizer.zero_grad()
outputs = self.model(mixed_images)
loss = self.criterion(outputs, mixed_labels)
loss.backward()
self.optimizer.step()
return loss.item()我这里也要去总结一下:
使用FGSM攻击器生成对抗样本
将原始样本和对抗样本混合
在混合数据上训练模型
这种方法能有效提升模型对FGSM攻击的鲁棒性
三,BIM攻击原理,流程和代码解释
1,原理:
BIM(Basic Iterative Method)是FGSM的迭代版本,通过多次小步扰动来增强攻击效果。
2,流程:
初始化对抗样本为原始样本重复N次:
计算当前对抗样本的梯度添加一小步扰动裁剪到允许范围,最后返回最终对抗样本
3,代码:
class BIMAttack:
def __init__(self, model, epsilon=0.03, alpha=0.01, iterations=10):
"""
初始化BIM攻击器
参数:
model: 目标模型
epsilon: 总扰动上限
alpha: 单步扰动大小
iterations: 迭代次数
"""
self.model = model
self.epsilon = epsilon
self.alpha = alpha
self.iterations = iterations
self.criterion = nn.CrossEntropyLoss()
def attack(self, images, labels):
"""
执行BIM攻击
参数:
images: 原始图像
labels: 真实标签
返回:
perturbed_images: 对抗样本
"""
# 初始对抗样本
adv_images = images.clone().detach()
for i in range(self.iterations):
# 启用梯度计算
adv_images.requires_grad = True
# 前向传播
outputs = self.model(adv_images)
loss = self.criterion(outputs, labels)
# 清空梯度并反向传播
self.model.zero_grad()
loss.backward()
# 获取梯度符号
gradient_sign = adv_images.grad.data.sign()
# 更新对抗样本
adv_images = adv_images + self.alpha * gradient_sign
# 计算总扰动并裁剪
delta = torch.clamp(adv_images - images,
-self.epsilon, self.epsilon)
adv_images = torch.clamp(images + delta, 0, 1).detach()
return adv_images这里解释一下:
迭代执行多次FGSM-like攻击
每次迭代添加小扰动
确保总扰动不超过ε
四,BIM防御原理,流程和代码解释
1,原理:
针对BIM的防御采用更强的对抗训练,使用BIM生成的对抗样本进行训练。
2,流程:
使用BIM生成更强的对抗样本
混合原始样本和BIM对抗样本
在更难的对抗样本上训练
提高模型对迭代攻击的鲁棒性
3,代码:
class BIMDefense:
def __init__(self, model, epsilon=0.03, alpha=0.01,
iterations=10, lr=0.001):
"""
初始化BIM对抗训练防御
参数:
model: 待训练模型
epsilon: 攻击扰动上限
alpha: 攻击单步扰动
iterations: 攻击迭代次数
lr: 学习率
"""
self.model = model
self.epsilon = epsilon
self.alpha = alpha
self.iterations = iterations
self.criterion = nn.CrossEntropyLoss()
self.optimizer = torch.optim.Adam(model.parameters(), lr=lr)
def adversarial_training_step(self, images, labels):
"""
单步对抗训练
参数:
images: 训练图像
labels: 训练标签
"""
# 生成BIM对抗样本
attacker = BIMAttack(self.model, self.epsilon,
self.alpha, self.iterations)
adv_images = attacker.attack(images, labels)
# 准备训练数据
all_images = torch.cat([images, adv_images], dim=0)
all_labels = torch.cat([labels, labels], dim=0)
# 训练步骤
self.model.train()
self.optimizer.zero_grad()
outputs = self.model(all_images)
loss = self.criterion(outputs, all_labels)
loss.backward()
self.optimizer.step()
return loss.item()五,PGD攻击原理,流程和代码解释
1,原理:
PGD(Projected Gradient Descent)是目前最强大的对抗攻击之一,在BIM基础上添加随机初始化和投影操作。
2,流程:
随机初始化扰动
多次迭代:
计算梯度
添加扰动
投影到ε球内
裁剪到有效范围
3,代码:
class PGDAttack:
def __init__(self, model, epsilon=0.03, alpha=0.01,
iterations=20, random_start=True):
"""
初始化PGD攻击器
参数:
model: 目标模型
epsilon: 扰动上限
alpha: 步长
iterations: 迭代次数
random_start: 是否随机初始化
"""
self.model = model
self.epsilon = epsilon
self.alpha = alpha
self.iterations = iterations
self.random_start = random_start
self.criterion = nn.CrossEntropyLoss()
def attack(self, images, labels):
"""
执行PGD攻击
参数:
images: 原始图像
labels: 真实标签
返回:
adv_images: 对抗样本
"""
# 初始扰动
if self.random_start:
# 随机初始化扰动
delta = torch.empty_like(images).uniform_(-self.epsilon, self.epsilon)
adv_images = torch.clamp(images + delta, 0, 1)
else:
adv_images = images.clone()
for i in range(self.iterations):
adv_images.requires_grad = True
# 前向传播
outputs = self.model(adv_images)
loss = self.criterion(outputs, labels)
# 反向传播
self.model.zero_grad()
loss.backward()
# 更新扰动
grad = adv_images.grad.data
adv_images = adv_images.detach() + self.alpha * grad.sign()
# 投影到ε球内
delta = adv_images - images
delta = torch.clamp(delta, -self.epsilon, self.epsilon)
# 裁剪到有效范围
adv_images = torch.clamp(images + delta, 0, 1).detach()
return adv_images六,PGD防御原理,流程和代码解释
1,原理:
PGD对抗训练是目前最有效的防御方法之一,通过在最强的PGD攻击样本上训练模型。
2,流程:
对每个训练样本生成PGD对抗样本
在对抗样本上训练模型
最小化对抗损失
3,代码:
class PGDDefense:
def __init__(self, model, epsilon=0.03, alpha=0.01,
iterations=10, lr=0.001):
"""
初始化PGD对抗训练防御
参数:
model: 待训练模型
epsilon: 扰动上限
alpha: 攻击步长
iterations: 攻击迭代次数
lr: 学习率
"""
self.model = model
self.epsilon = epsilon
self.alpha = alpha
self.iterations = iterations
self.criterion = nn.CrossEntropyLoss()
self.optimizer = torch.optim.Adam(model.parameters(), lr=lr)
def adversarial_training_step(self, images, labels):
"""
单步PGD对抗训练
参数:
images: 训练图像
labels: 训练标签
返回:
loss: 训练损失
"""
# 生成PGD对抗样本
attacker = PGDAttack(self.model, self.epsilon,
self.alpha, self.iterations)
adv_images = attacker.attack(images, labels)
# 仅使用对抗样本训练(最严格的对抗训练)
self.model.train()
self.optimizer.zero_grad()
outputs = self.model(adv_images)
loss = self.criterion(outputs, labels)
loss.backward()
self.optimizer.step()
return loss.item()七,整体的代码攻击框架
1,代码:
class UnifiedAttackFramework:
"""
统一的对抗攻击框架
"""
def __init__(self, model):
"""
初始化攻击框架
参数:
model: 目标模型
"""
self.model = model
self.attacks = {
'fgsm': FGSMAttack,
'bim': BIMAttack,
'pgd': PGDAttack
}
def create_attack(self, attack_type, **kwargs):
"""
创建指定类型的攻击器
参数:
attack_type: 攻击类型 ('fgsm', 'bim', 'pgd')
**kwargs: 攻击参数
返回:
attack: 攻击器实例
"""
if attack_type not in self.attacks:
raise ValueError(f"不支持的攻击类型: {attack_type}")
return self.attacks[attack_type](self.model, **kwargs)
def evaluate_attack(self, dataloader, attack_type, **kwargs):
"""
评估攻击效果
参数:
dataloader: 数据加载器
attack_type: 攻击类型
**kwargs: 攻击参数
返回:
accuracy: 攻击后的准确率
"""
self.model.eval()
attack = self.create_attack(attack_type, **kwargs)
correct = 0
total = 0
for images, labels in dataloader:
# 生成对抗样本
adv_images = attack.attack(images, labels)
# 预测
with torch.no_grad():
outputs = self.model(adv_images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
return accuracy八,整体的代码防御框架
1,代码:
class UnifiedDefenseFramework:
"""
统一的对抗防御框架
"""
def __init__(self, model):
"""
初始化防御框架
参数:
model: 待防御模型
"""
self.model = model
self.defenses = {
'fgsm': FGSMDefense,
'bim': BIMDefense,
'pgd': PGDDefense
}
def create_defense(self, defense_type, **kwargs):
"""
创建指定类型的防御器
参数:
defense_type: 防御类型 ('fgsm', 'bim', 'pgd')
**kwargs: 防御参数
返回:
defense: 防御器实例
"""
if defense_type not in self.defenses:
raise ValueError(f"不支持的防御类型: {defense_type}")
return self.defenses[defense_type](self.model, **kwargs)
def train_with_defense(self, train_loader, defense_type,
epochs=10, **kwargs):
"""
使用指定防御方法训练模型
参数:
train_loader: 训练数据加载器
defense_type: 防御类型
epochs: 训练轮数
**kwargs: 防御参数
返回:
history: 训练历史记录
"""
defense = self.create_defense(defense_type, **kwargs)
history = {'loss': [], 'accuracy': []}
for epoch in range(epochs):
epoch_loss = 0
correct = 0
total = 0
for batch_idx, (images, labels) in enumerate(train_loader):
# 对抗训练步骤
loss = defense.adversarial_training_step(images, labels)
epoch_loss += loss
# 计算准确率
with torch.no_grad():
outputs = self.model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
if batch_idx % 100 == 0:
print(f'Epoch: {epoch+1}, Batch: {batch_idx}, Loss: {loss:.4f}')
epoch_acc = 100 * correct / total
avg_loss = epoch_loss / len(train_loader)
history['loss'].append(avg_loss)
history['accuracy'].append(epoch_acc)
print(f'Epoch {epoch+1}/{epochs}, Loss: {avg_loss:.4f}, Accuracy: {epoch_acc:.2f}%')
return history
def evaluate_robustness(self, test_loader, attack_framework):
"""
评估模型鲁棒性
参数:
test_loader: 测试数据加载器
attack_framework: 攻击框架实例
返回:
results: 鲁棒性评估结果
"""
results = {}
for attack_type in ['fgsm', 'bim', 'pgd']:
accuracy = attack_framework.evaluate_attack(
test_loader, attack_type)
results[attack_type] = accuracy
print(f'{attack_type.upper()}攻击后准确率: {accuracy:.2f}%')
return results九,整体的代码库引用:
# 基础库
import numpy as np
import matplotlib.pyplot as plt
import os
import sys
from pathlib import Path
import time
import copy
import random
from tqdm import tqdm
import json
import pickle
from collections import defaultdict
# PyTorch核心库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset, TensorDataset
# PyTorch视觉库(如果你使用图像数据)
import torchvision
import torchvision.transforms as transforms
from torchvision import datasets, models
# 可选:用于数据处理和可视化
import pandas as pd
import seaborn as sns
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 可选:用于3D可视化
from mpl_toolkits.mplot3d import Axes3D
# 设置随机种子保证可重复性
def set_seed(seed=42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
set_seed(42)十,简单的CNN模型示例:
# 简单CNN模型示例
class SimpleCNN(nn.Module):
def __init__(self, num_classes=10):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, num_classes)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
return x十一,测试和可视化部分:
def visualize_attack_results(original, adversarial, predictions, save_path=None):
"""
可视化原始图像、对抗图像和预测结果
"""
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 5, figsize=(15, 6))
for i in range(5):
# 原始图像
ax = axes[0, i]
ax.imshow(original[i].squeeze(), cmap='gray')
ax.set_title(f'Original
True: {predictions["true"][i]}
Pred: {predictions["orig_pred"][i]}')
ax.axis('off')
# 对抗图像
ax = axes[1, i]
ax.imshow(adversarial[i].squeeze(), cmap='gray')
ax.set_title(f'Adversarial
Pred: {predictions["adv_pred"][i]}')
ax.axis('off')
plt.tight_layout()
if save_path:
plt.savefig(save_path)
plt.show()十二,完整工作示例:
#!/usr/bin/env python3
"""
对抗攻击与防御完整示例
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
def main():
# 1. 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 2. 加载数据
train_loader, test_loader = load_mnist_data()
# 3. 初始化模型
model = SimpleCNN().to(device)
# 4. 创建攻击框架
attack_framework = UnifiedAttackFramework(model)
# 5. 创建防御框架
defense_framework = UnifiedDefenseFramework(model)
# 6. 正常训练模型
print("正常训练模型...")
normal_train(model, train_loader, epochs=5)
# 7. 测试原始准确率
original_acc = test_accuracy(model, test_loader)
print(f"原始模型准确率: {original_acc:.2f}%")
# 8. 评估对抗攻击
print("
评估对抗攻击效果:")
attack_results = defense_framework.evaluate_robustness(
test_loader, attack_framework)
# 9. 对抗训练
print("
进行PGD对抗训练...")
defense_framework.train_with_defense(
train_loader, 'pgd', epochs=5, epsilon=0.03, alpha=0.01, iterations=10)
# 10. 再次评估鲁棒性
print("
对抗训练后的鲁棒性:")
robust_results = defense_framework.evaluate_robustness(
test_loader, attack_framework)
# 11. 可视化结果
visualize_comparison(original_acc, attack_results, robust_results)
if __name__ == "__main__":
main()好了,这个是经典的工作流程教学。接下来,我们玩一些变种,看看能不能做出一些不同的攻击视角,以下的攻击手段也有一些是网上出现了的,包括C&W攻击,对于这些攻击只是做一些搬运,感谢理解
1,MIFGSM(Momentum Iterative FGSM,动量迭代快速梯度符号方法)
1,本质:基于物理动量概念和优化理论发展的改进攻击方法。
2,核心思想:
动量机制:借鉴物理学中的动量概念,在梯度更新中引入历史梯度信息稳定优化:通过累积梯度方向,减少更新过程中的振荡跳出局部最优:动量帮助算法跳出局部最小值,找到更强的攻击方向
3,技术优势
加速收敛:动量项使更新方向更一致,加快收敛速度
避免振荡:减少梯度方向频繁变化导致的振荡
提高成功率:实验表明MIFGSM比标准FGSM和BIM成功率提高5-15%
增强迁移性:生成的对抗样本在不同模型间迁移性更好
4,理论解释
动量在优化中起到两个关键作用:
惯性效应:类似于球滚动下坡时积累速度,梯度更新保持方向惯性
平滑效应:对梯度噪声具有滤波作用,使优化路径更平滑
在对抗攻击中,动量帮助攻击者:
更有效地探索对抗空间
避免陷入较差的局部最优解
生成更稳定的对抗扰动
5,代码实现:
class MIFGSMAttack:
def __init__(self, model, epsilon=0.03, alpha=0.01,
iterations=10, decay=0.9):
self.model = model
self.epsilon = epsilon
self.alpha = alpha
self.iterations = iterations
self.decay = decay
self.criterion = nn.CrossEntropyLoss()
def attack(self, images, labels):
adv_images = images.clone().detach()
momentum = torch.zeros_like(images)
for i in range(self.iterations):
adv_images.requires_grad = True
outputs = self.model(adv_images)
loss = self.criterion(outputs, labels)
self.model.zero_grad()
loss.backward()
grad = adv_images.grad.data
# 动量更新
momentum = self.decay * momentum + grad / torch.mean(
torch.abs(grad), dim=(1,2,3), keepdim=True)
adv_images = adv_images.detach() + self.alpha * torch.sign(momentum)
# 投影到ε球内
delta = torch.clamp(adv_images - images, -self.epsilon, self.epsilon)
adv_images = torch.clamp(images + delta, 0, 1)
return adv_images2,Nesterov Accelerated Gradient (NAG) Attack
1,本质:
NAG攻击基于Nesterov加速梯度优化算法,这是一种”前瞻性”优化方法。
2,核心思想:
前瞻更新:先基于当前动量更新位置,再计算该位置的梯度
更好估计:在梯度计算点之前就考虑动量影响
二阶近似:相当于对损失函数进行了二阶近似
3,理论优势
更准确的梯度估计:在前瞻位置计算梯度,考虑了动量影响
减少振荡:更平滑的收敛路径
理论保证:对于凸问题,NAG有O(1/t²)的收敛率,优于标准动量的O(1/t)
适应性:在”陡峭谷底”问题中表现更好
4,在对抗攻击中的应用
更精确的攻击方向:前瞻梯度提供了更好的攻击方向估计
更快收敛:通常比MIFGSM收敛更快
强攻击效果:能生成更强扰动,攻击成功率更高
5,代码实现:
class NAGAttack:
def __init__(self, model, epsilon=0.03, alpha=0.01,
iterations=10, momentum=0.9):
self.model = model
self.epsilon = epsilon
self.alpha = alpha
self.iterations = iterations
self.momentum = momentum
self.criterion = nn.CrossEntropyLoss()
def attack(self, images, labels):
adv_images = images.clone().detach()
velocity = torch.zeros_like(images)
for i in range(self.iterations):
# Nesterov: 先使用动量更新位置
lookahead_images = adv_images + self.momentum * velocity
lookahead_images.requires_grad = True
outputs = self.model(lookahead_images)
loss = self.criterion(outputs, labels)
self.model.zero_grad()
loss.backward()
grad = lookahead_images.grad.data
# Nesterov动量更新
velocity = self.momentum * velocity + self.alpha * torch.sign(grad)
adv_images = adv_images + velocity
# 投影和裁剪
delta = torch.clamp(adv_images - images, -self.epsilon, self.epsilon)
adv_images = torch.clamp(images + delta, 0, 1).detach()
return adv_images3,C&W Attack(Carlini & Wagner Attack)
1,本质:
C&W攻击是基于优化的对抗攻击方法的里程碑工作,提出了一种系统化的攻击框架。
2,核心思想:
优化视角:将攻击问题形式化为约束优化问题
可调参数:通过参数控制扰动大小和攻击强度平衡
理论严密:提供严格的数学形式和理论分析
3,攻击方法:
L₀攻击:通过迭代优化最小化改变的像素数
L∞攻击:通过转换将L∞约束转化为可优化形式
4,代码实现:
class CWLoss(nn.Module):
"""C&W攻击的定制损失函数"""
def __init__(self, confidence=0):
super(CWLoss, self).__init__()
self.confidence = confidence
def forward(self, logits, target):
target_onehot = torch.zeros_like(logits).scatter_(1, target.unsqueeze(1), 1)
# 正确类别的logit
target_logit = torch.sum(logits * target_onehot, dim=1)
# 其他类别的最大logit
other_logit = torch.max(logits - 1e4 * target_onehot, dim=1)[0]
# C&W损失
loss = torch.clamp(other_logit - target_logit + self.confidence, min=0)
return loss.mean()
class CWAttack:
def __init__(self, model, c=1e-4, kappa=0, lr=0.01, iterations=1000):
self.model = model
self.c = c # 正则化系数
self.kappa = kappa # 置信度
self.lr = lr
self.iterations = iterations
self.cw_loss = CWLoss(confidence=kappa)
def attack(self, images, labels):
# 使用tanh空间进行优化,避免裁剪
w = torch.zeros_like(images, requires_grad=True)
optimizer = optim.Adam([w], lr=self.lr)
# tanh变换保证像素值在[0,1]
def tanh_space(x):
return 0.5 * (torch.tanh(x) + 1)
for i in range(self.iterations):
adv_images = tanh_space(w)
# 计算两个损失项
logits = self.model(adv_images)
# 1) 攻击损失:使模型错误分类
loss_attack = self.cw_loss(logits, labels)
# 2) L2距离损失:最小化扰动
loss_l2 = torch.norm(adv_images - images, p=2)
# 总损失
total_loss = loss_attack + self.c * loss_l2
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
return tanh_space(w).detach()4,Ensemble Attack(集成攻击)
1,本质:
集成攻击基于集成学习和迁移学习的理论,针对多个模型生成对抗样本。
2,核心思想:
多样性利用:利用多个模型的梯度信息
通用性追求:生成对多个模型都有效的对抗样本
迁移性增强:提高对抗样本在不同模型间的迁移性
3,理论依据
偏差-方差分解:
单个模型的梯度可能存在偏差
集成减少方差,得到更稳健的梯度方向
特征共同性:
不同模型学习到相似的特征表示
集成攻击针对这些共同特征
迁移学习理论:
对抗样本的迁移性与模型间的决策边界相似性相关
集成攻击增强了边界扰动的通用性
4,代码实现:
class EnsembleAttack:
def __init__(self, models, epsilon=0.03, alpha=0.01, iterations=10):
self.models = models # 模型列表
self.epsilon = epsilon
self.alpha = alpha
self.iterations = iterations
self.criterion = nn.CrossEntropyLoss()
def attack(self, images, labels):
adv_images = images.clone().detach()
for i in range(self.iterations):
adv_images.requires_grad = True
total_grad = 0
for model in self.models:
outputs = model(adv_images)
loss = self.criterion(outputs, labels)
model.zero_grad()
loss.backward()
total_grad += adv_images.grad.data.clone()
# 平均梯度
avg_grad = total_grad / len(self.models)
adv_images = adv_images.detach() + self.alpha * torch.sign(avg_grad)
delta = torch.clamp(adv_images - images, -self.epsilon, self.epsilon)
adv_images = torch.clamp(images + delta, 0, 1).detach()
return adv_images5,Sparse Attack(稀疏攻击)
1,本质:
稀疏攻击基于压缩感知和稀疏表示理论,强调扰动的稀疏性而非小幅度。
2,核心思想:
稀疏扰动:仅修改少量像素
人类不可感知:分散的微小变化难以察觉
高效攻击:用最少修改实现攻击目标
3,主要方法
单像素攻击:
仅修改一个像素
通过优化找到最关键像素
局部稀疏攻击:
修改小区域内的像素
保持局部连续性
结构化稀疏攻击:修改具有特定模式(如线段、点阵)的像素
4,代码实现:
class SparseFGSM:
def __init__(self, model, epsilon=0.1, sparsity=0.01):
self.model = model
self.epsilon = epsilon
self.sparsity = sparsity # 扰动像素比例
self.criterion = nn.CrossEntropyLoss()
def attack(self, images, labels):
images.requires_grad = True
outputs = self.model(images)
loss = self.criterion(outputs, labels)
self.model.zero_grad()
loss.backward()
grad = images.grad.data
# 创建稀疏掩码
batch_size = images.size(0)
num_pixels = images[0].numel()
num_perturb = int(self.sparsity * num_pixels)
perturbed_images = images.clone()
for i in range(batch_size):
# 选择梯度绝对值最大的像素
abs_grad = torch.abs(grad[i].flatten())
_, indices = torch.topk(abs_grad, num_perturb)
# 创建扰动
perturbation = torch.zeros_like(images[i].flatten())
perturbation[indices] = self.epsilon * torch.sign(grad[i].flatten()[indices])
perturbed_images[i] = torch.clamp(
images[i] + perturbation.reshape(images[i].shape), 0, 1
)
return perturbed_images.detach()6,Feature Attack(特征空间攻击)
1,本质:
特征空间攻击基于深度学习表示理论,直接在特征空间而非像素空间进行攻击。
2,核心思想:
特征扰动:修改中间层特征而非输入像素
语义攻击:在语义层面干扰模型决策
高效攻击:特征空间的维度通常低于像素空间
3,攻击类型
中间特征攻击:
针对特定层的特征表示
最大化特征差异
深度特征攻击:
针对深层语义特征
改变高级语义表示
对抗特征生成:
生成具有特定特征模式的对抗样本
特征损失攻击:
特征对抗生成:
4,理论优势
维度优势:特征空间通常维度更低,优化更高效
语义控制:可直接控制语义层面的变化
迁移性强:特征空间攻击在不同架构间迁移性更好
5,代码实现:
class FeatureSpaceAttack:
def __init__(self, model, epsilon=0.03, layer_name='fc1'):
self.model = model
self.epsilon = epsilon
self.layer_name = layer_name
self.feature_hook = None
# 注册钩子获取中间特征
self._register_hook()
def _register_hook(self):
def get_features(module, input, output):
self.features = output
# 查找目标层
for name, module in self.model.named_modules():
if name == self.layer_name:
self.feature_hook = module.register_forward_hook(get_features)
break
def attack(self, images, labels):
# 获取原始特征
with torch.no_grad():
_ = self.model(images)
original_features = self.features.clone()
images.requires_grad = True
# 前向传播
outputs = self.model(images)
current_features = self.features
# 特征空间损失
feature_loss = F.mse_loss(current_features, original_features)
classification_loss = F.cross_entropy(outputs, labels)
# 最大化特征变化,最小化分类损失
total_loss = feature_loss - classification_loss
self.model.zero_grad()
total_loss.backward()
grad = images.grad.data
perturbed_images = images + self.epsilon * torch.sign(grad)
perturbed_images = torch.clamp(perturbed_images, 0, 1)
return perturbed_images.detach()好了,我们分析一下各种方法的优势:
| 攻击方法 | 理论基础 | 优化空间 | 扰动特性 | 主要优势 |
|---|---|---|---|---|
| MIFGSM | 动量优化 | 梯度方向 | 密集,有界 | 收敛快,稳定性好 |
| NAG | 前瞻优化 | 梯度方向 | 密集,有界 | 更准确,收敛更快 |
| C&W | 约束优化 | 多种范数 | 可调,优化 | 攻击力强,灵活 |
| Ensemble | 集成学习 | 多模型梯度 | 通用,迁移 | 迁移性强,实用 |
| Sparse | 稀疏表示 | L0约束 | 稀疏,局部 | 隐蔽性好 |
| Feature | 表示学习 | 特征空间 | 语义级 | 高效,可解释 |
好了,攻击我们讲完了,我们开始讲一些防御,我的这个防御手段只是演示,不高,不能贴切上述的每一种分析,大家仅作为参考就好,谢谢大家,下面的一些名字是利用数学的一些想法去整合的。
1,Adversarial Logit Pairing (ALP,这里用了AI去做一些名字的选取)
1,核心思想:最小化原始样本和对立样本在logit空间的差异
2,代码实现:
class ALPDefense:
def __init__(self, model, epsilon=0.03, alpha=0.5, lr=0.001):
self.model = model
self.epsilon = epsilon
self.alpha = alpha # ALP损失权重
self.criterion = nn.CrossEntropyLoss()
self.optimizer = optim.Adam(model.parameters(), lr=lr)
def training_step(self, images, labels):
# 生成对抗样本
attacker = FGSMAttack(self.model, self.epsilon)
adv_images = attacker.attack(images, labels)
# 前向传播
clean_outputs = self.model(images)
adv_outputs = self.model(adv_images)
# 分类损失
cls_loss = self.criterion(clean_outputs, labels)
# ALP损失:logit配对
alp_loss = F.mse_loss(clean_outputs, adv_outputs)
# 总损失
total_loss = cls_loss + self.alpha * alp_loss
self.optimizer.zero_grad()
total_loss.backward()
self.optimizer.step()
return total_loss.item()2,Feature Denoising(特征去噪)
1,核心思想:在网络的中间层添加去噪模块
2,代码实现:
class DenoisingBlock(nn.Module):
"""特征去噪块"""
def __init__(self, channels, kernel_size=3):
super(DenoisingBlock, self).__init__()
self.denoise = nn.Sequential(
nn.Conv2d(channels, channels, kernel_size, padding=kernel_size//2),
nn.BatchNorm2d(channels),
nn.ReLU(),
nn.Conv2d(channels, channels, kernel_size, padding=kernel_size//2),
nn.BatchNorm2d(channels)
)
def forward(self, x):
identity = x
denoised = self.denoise(x)
return identity + denoised # 残差连接
class DenoisingCNN(nn.Module):
def __init__(self, num_classes=10):
super(DenoisingCNN, self).__init__()
# 基础特征提取
self.features = nn.Sequential(
nn.Conv2d(1, 32, 3, padding=1),
nn.ReLU(),
DenoisingBlock(32), # 添加去噪块
nn.Conv2d(32, 64, 3, padding=1),
nn.ReLU(),
DenoisingBlock(64), # 添加去噪块
nn.MaxPool2d(2),
nn.Dropout2d(0.25)
)
self.classifier = nn.Sequential(
nn.Linear(64*14*14, 128),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(128, num_classes)
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x3,Randomized Smoothing(随机平滑)
1,核心思想:在推理时添加随机噪声,通过投票获得稳定预测
2,代码实现:
class RandomizedSmoothing:
def __init__(self, base_model, sigma=0.1, n_samples=100):
self.base_model = base_model
self.sigma = sigma # 噪声标准差
self.n_samples = n_samples # 采样次数
def predict(self, images):
batch_size = images.size(0)
# 扩展批次维度用于多次采样
expanded_images = images.unsqueeze(1).repeat(1, self.n_samples, 1, 1, 1)
expanded_images = expanded_images.view(-1, *images.shape[1:])
# 添加高斯噪声
noise = torch.randn_like(expanded_images) * self.sigma
noisy_images = expanded_images + noise
noisy_images = torch.clamp(noisy_images, 0, 1)
# 批量预测
with torch.no_grad():
outputs = self.base_model(noisy_images)
predictions = torch.argmax(outputs, dim=1)
# 重塑并投票
predictions = predictions.view(batch_size, self.n_samples)
final_predictions = []
for i in range(batch_size):
counts = torch.bincount(predictions[i])
final_predictions.append(torch.argmax(counts).item())
return torch.tensor(final_predictions)4,Gradient Masking Defense(梯度掩蔽)
1,核心思想:隐藏或混淆模型的梯度,使攻击者难以计算有效梯度
2,代码实现:
class GradientMaskingDefense(nn.Module):
def __init__(self, base_model, mask_prob=0.3):
super(GradientMaskingDefense, self).__init__()
self.base_model = base_model
self.mask_prob = mask_prob
# 注册梯度掩蔽钩子
self._register_gradient_masks()
def _register_gradient_masks(self):
def gradient_mask_hook(module, grad_input, grad_output):
# 随机掩蔽部分梯度
if isinstance(grad_input, tuple):
masked_grads = []
for grad in grad_input:
if grad is not None:
mask = torch.rand_like(grad) > self.mask_prob
masked_grads.append(grad * mask.float())
return tuple(masked_grads)
return grad_input
# 为某些层添加钩子
for name, module in self.base_model.named_modules():
if isinstance(module, nn.Conv2d) or isinstance(module, nn.Linear):
module.register_backward_hook(gradient_mask_hook)
def forward(self, x):
return self.base_model(x)好了,以上就是我的全部的想法,针对的是关于自己的梯度对抗攻击的一些思考,感兴趣的小伙伴可以自己去思考一下。
免责声明:
1. 本代码仅用于演示机器学习模型的攻击原理
2. 旨在帮助理解对抗样本的生成机制和防御重要性
3. 禁止用于任何实际攻击、非法或未经授权的测试
4. 使用者需遵守当地法律法规,自行承担使用后果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...