
目录
一、背景
二、ChatGPT 成功的原因
2.1、NLP 技术突破:强势整合技术资源
2.1.1、基于自回归的无监督训练
2.1.2、与人类意识对齐(Alignment)
2.1.3、突现能力(Emergent Ability)
2.2、超大规模数据集
2.2.1、基础模型 GPT-3 的训练数据
2.2.2、ChatGPT 的训练数据
2.3、大模型训练
2.4、产品化开放
2.4.1、便捷使用
2.4.2、适用场景多
2.4.3、使用效果好
2.5、工程化应用
本文来源:极客时间vip课程笔记
一、背景
2023 年 3 月开始,ChatGPT 燃爆中国互联网界。实际上国内外同一时期搞大模型的团队很多,为什么 ChatGPT 会突然火起来?还有在 ChatGPT 发布后,为什么各个大厂在短时间内相继发布大模型产品?比如 3 月百度发布文心一言,4 月阿里云发布通义千问,5 月科大讯飞发布星火认知大模型等等。

我们最容易想到的原因是,OpenAI 在自然语言处理(NLP)方面取得了突破性的进展,这是技术层面看到的。实际上,ChatGPT 背后包含了一系列的资源整合,包括技术、资金、大厂背书等等,以及多个国际巨头的通力合作,比如 OpenAI、微软、NVIDIA、GitHub 等。所以说,ChatGPT 不仅仅是技术上的突破,更是工程和产品的伟大胜利!
二、ChatGPT 成功的原因
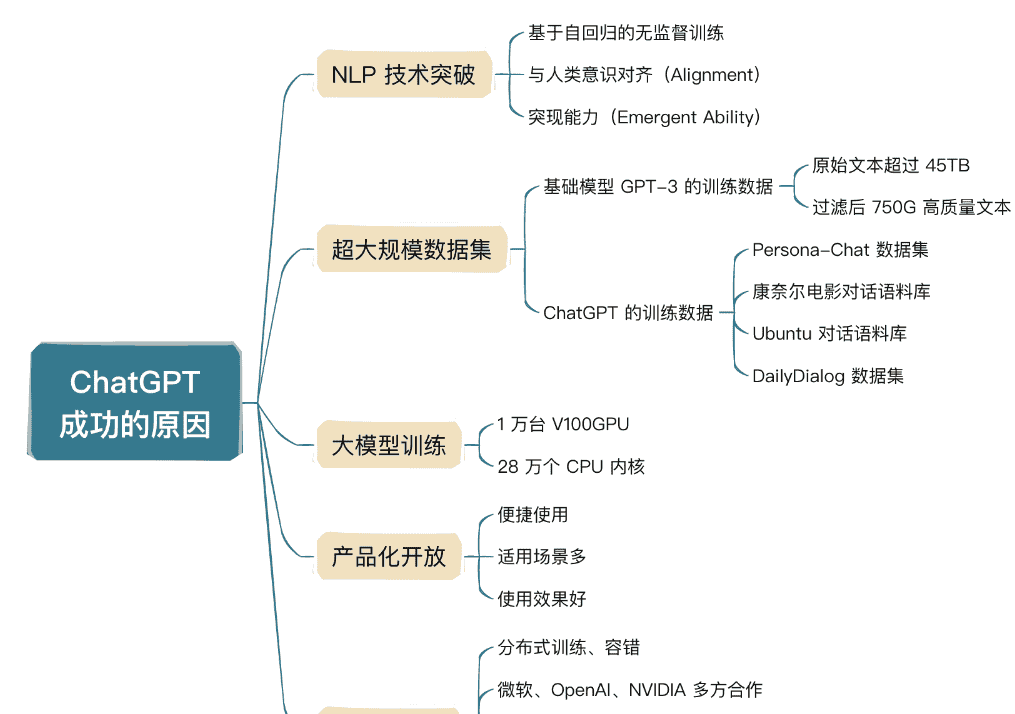
2.1、NLP 技术突破:强势整合技术资源
基于 Transformer 架构的语言模型大体上分为两类,一类是以 BERT 为代表的掩码语言模型(Masked Language Model,MLM),一类以 GPT 为代表的自回归语言模型(Autoregressive Language Model,ALM)。
2.1.1、基于自回归的无监督训练
GPT 系列的模型一直走的是和 BERT 不一样的线路,早些年压力巨大,毕竟 BERT 是 Google 发布的,非常权威。但是 OpenAI 一直认为自回归模型训练潜力更大,尤其在 GPT-2 引入 zero-shot 后,更加有信心了。
按照人类语言的习惯,语言本身就有先后顺序,而且我们日常说话也是下文依赖上文。所以有人猜测,自回归语言模型代表了标准的语言模型,利用上文信息预测下文,这比传统 AI 预测更加复杂,但是上限更高,更有望通向 AGI,这正是 OpenAI 的愿景。尽管在 GPT-1 和 GPT-2 的探索中没有取得压倒性的效果,但确实验证了标准语言模型在 zero-shot 等方面的潜在能力。
无监督自回归的训练方式,使 GPT 模型可以接受大量文本数据,所以后面有了 GPT-3,1750 亿的参数规模,使 GPT-3 直接问鼎当时最大的模型,GPT-3 使用了大约 45TB 的文本数据,一次训练费用近 460 万美元,在当时,相比上一代模型 GPT-2,效果已经非常好了,这也是人们所讲的大力出奇迹。
但是,我们现在来看这个问题,GPT-3 发布时间大概是 2020 年 3 月,当时的 GPT-3 还不具备直接和人类对话的能力。而 ChatGPT 所使用的模型是 GPT-3.5,爆火时间在 2022 年年底到 2023 年 3 月,期间将近 2 年的时间,OpenAI 在做什么呢?答案是他们在想办法让 GPT 模型可以优雅地和人类进行对话。
2.1.2、与人类意识对齐(Alignment)
我
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...










