
来源:3D视觉工坊
添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附行业细分群
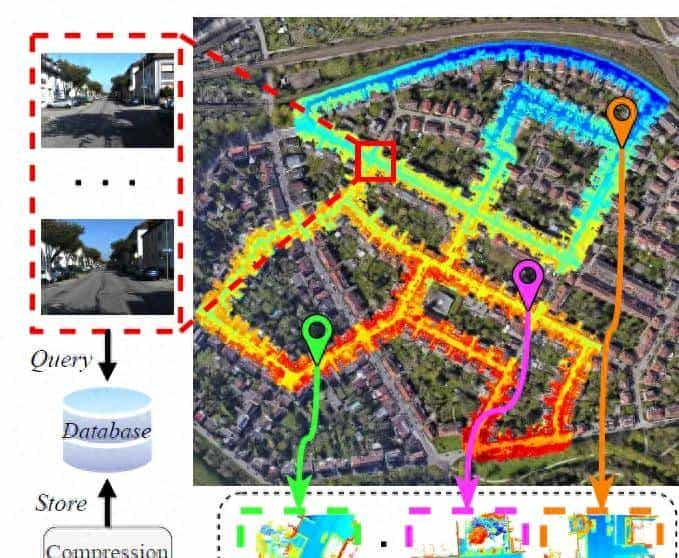
传统的视觉位置识别(VPR)主要依赖于图像对图像查询,使用附带地理信息的图像数据库作为地图。然后,通过使用实时捕获的图像来查询图像数据库来完成地点识别。不过,图像数据库本身对外观变化(例如,视角、照明、季节)的准确度和稳健性受到影响。相反,激光雷达地图对于天气和照明变化更加稳健。这激发了对图像到激光雷达地点识别的兴趣,即在激光雷达地图中确定图像的拍摄位置。不过,由于城市尺度点云需要大量的存储消耗,一般采用压缩来有效存储城市尺度激光雷达地图。压缩加剧了模态间隙和图像到激光雷达地点识别的难度。
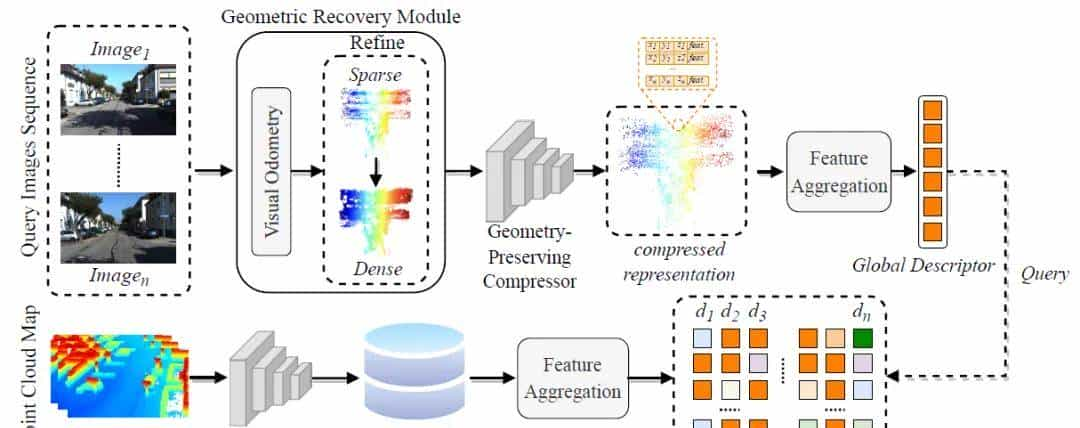
作者提出了VOLoc,一个新颖的框架,利用几何类似性来解决图像到激光雷达位置识别的挑战,而无需解压激光雷达地图。关键思想是利用几何信息作为中间表明来消除模态间隙。一方面,利用几何保持压缩器(GPC)来压缩分段的激光雷达地图,这些地图用作位置数据库。值得注意的是,GPC通过聚类和下采样压缩点云,以保留几何结构并确保压缩是可逆的。可逆压缩对于下游准确的六自由度姿态估计至关重大。然后,提出了基于注意力的聚合模块,将压缩的子地图转换为全局描述符,以集成邻域信息以便查询。在线阶段,通过在线几何恢复模块(GRM)重建相机周围的局部几何结构,该模块包括视觉测距模块和点云优化模块。GRM努力恢复尽可能多的局部结构信息,并将重建的点云输出为查询点云。然后,一样的GPC将QPC压缩,并通过一样的聚合模块汇总为查询全局描述符。然后,返回数据库中与最接近的向量距离的位置索引作为地点识别结果。
下面一起来阅读一下这项工作~
标题:VOLoc: Visual Place Recognition by Querying Compressed Lidar Map
作者:Xudong Cai, Yongcai Wang, Zhe Huang, Yu Shao, Deying Li
机构:中国人民大学
原文链接:https://arxiv.org/abs/2402.15961
代码链接:https://github.com/Master-cai/VOLoc
城市尺度的激光雷达地图的可用性使得利用移动摄像头进行城市尺度的地点识别成为可能。不过,城市尺度的激光雷达地图一般需要进行压缩以提高存储效率,这增加了在压缩的激光雷达地图中进行直接视觉地点识别的难度。本文提出了VOLoc,一种准确高效的视觉地点识别方法,利用几何类似性直接通过实时捕获的图像序列查询压缩的激光雷达地图。在离线阶段,VOLoc使用几何保持压缩器(GPC)压缩激光雷达地图,其中压缩是可逆的,这是下游6DoF姿态估计的一个关键要求。在线阶段,VOLoc提出了一个在线几何恢复模块(GRM),由在线视觉测距(VO)和点云优化模块组成,以便在线恢复相机周围的局部场景结构,构建查询点云(QPC)。然后,QPC通过一样的GPC进行压缩,并通过基于注意力的聚合模块聚合成全局描述符,以在向量空间中查询压缩的激光雷达地图。还提出了一种转移学习机制,以提高聚合网络的准确性和通用性。广泛的评估表明,VOLoc提供了比激光雷达到激光雷达位置识别甚至更好的定位准确性,为利用低端移动摄像头对压缩的激光雷达地图进行设置了新记录。
具体应用的描述,在压缩的雷达地图中识别图像的位置。
(1)探索几何类似性以实现图像到压缩激光雷达位置识别。
(2)利用几何保持压缩器(GPC)构建数据库,并提出几何恢复模块(GRM)从图像序列中恢复局部几何信息。
(3)提出一种转移学习方案来训练聚合模块,大大提高了准确性。
(4)构建基于KITTI的视觉到激光雷达定位数据集,用于评估所提出的方法和社会应用。
A. 问题描述
思考一个城市规模的点云地图M,该地图被分割成相等大小的序列。为了存储效率而压缩分段地图,并设置了一个数据库,即 DB = {c1,c2,…,cN},其中 ci 是第 i 个压缩序列。一个配有单目相机的终端使用其捕获的图像查询数据库,以找出终端可能位于的位置。
B. 方法概述
激光雷达子地图第一通过几何保持压缩器进行处理,然后通过特征聚合模块处理,转换成全局描述符 Dd = {d1,d2,…,dN}。查询图像经过几何恢复模块和一样的 GPC 处理,生成压缩的查询点云,然后使用一样的特征聚合模块将其转换为查询全局描述符 dq。然后通过在 Dd 中检索与 dq 最类似的描述符来进行位置识别。综合损失和迁移学习方案被应用于训练聚合模块。
定位性能和存储空间使用情况。表I报告了Recall@1、Recall@5和Recall@1%、平均查询子地图大小以及总地图大小。主要与两类方法进行比较:Lidar到未压缩地图(LtoU)方法、和Lidar到压缩地图(LtoC)方法。LtoU方法使用激光雷达点云查询未压缩地图。LtoC方法在压缩地图中检索点云。
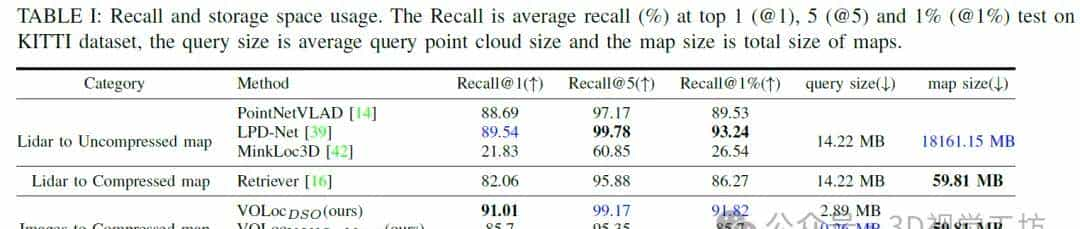
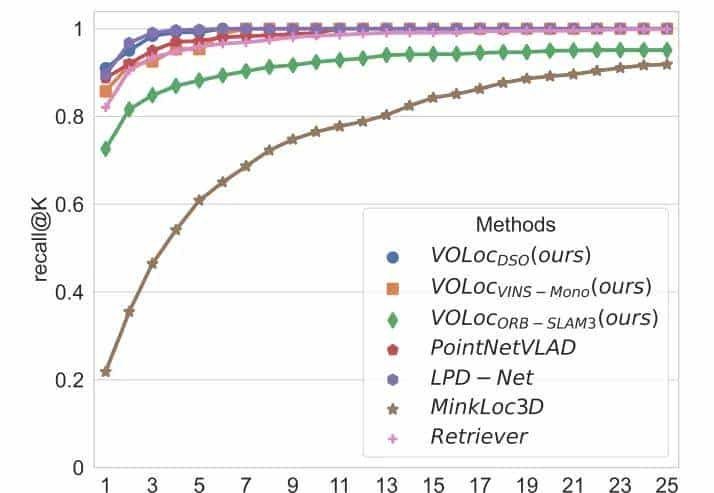
最佳模型(VOLocDSO)优于大多数基线方法,并略逊于在KITTI数据集上表现最佳的LPD-Net。其他两个模型(VOLocV INS−Mono和VOLocORB−SLAM3)也取得了与其他基线方法相当的性能。不过,这不是一个公平的比较,由于除了Retriever [16]之外的所有方法都在未压缩的点云中查询基于激光雷达的点云。表I显示,该方法的查询大小和地图大小要比Lidar到未压缩地图方法小得多。与Retriever相比,VOLocDSO和VOLocV INS−Mono方法在定位性能上表现更好,查询大小更小。因此,该方法的优势在于直接在压缩地图中定位图像,占用的额外空间很少(重构可视化点云)。这个方法适用于存储空间和传输带宽有限的移动设备。图4显示了KITTI数据集上的平均召回率@K。
消融实验
研究不同系统组件的影响,包括:
a)迁移学习:如表II所示,基本模型无论是否使用VO都表现不佳。通过提出的迁移学习策略,Recall@1分别提高了11.47%、7.33%和11.47%。迁移学习使模型学习更多的几何特征,增强了所有VO方法的性能。
b)组合损失:如表II所示,组合损失增强了定位性能。这意味着使QPCs的描述符更具有区分性有助于网络找到视觉和激光点云之间更好的相关性。基于DSO的方法的Recall@1已提高到91.34%,超过了LPD-Net(89.54%)。其他两种方法也有所改善(分别为7.83%和3.97%)。
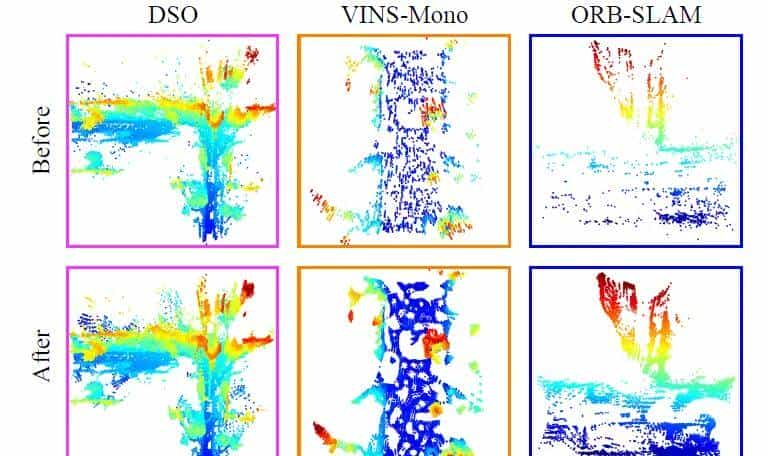
c)视觉点云细化:ORB-SLAM3和VINS-Mono的点云比DSO的点云更稀疏。表II显示,优化显着缩小了性能差距。优化对ORB-SLAM3方法有很大提升。它的Recall@1达到了72.62%。它还将VINS-Mono方法提高了6.82%,但对于DSO方法的影响较小,由于其固有密度。

定性结果和可视化
展示视觉点云细化的定性结果和检索结果:
a)视觉点云细化:图5显示了视觉点云细化的效果。它对DSO的点云影响轻微,但对VINS-Mono和ORB-SLAM3的点云有明显影响。
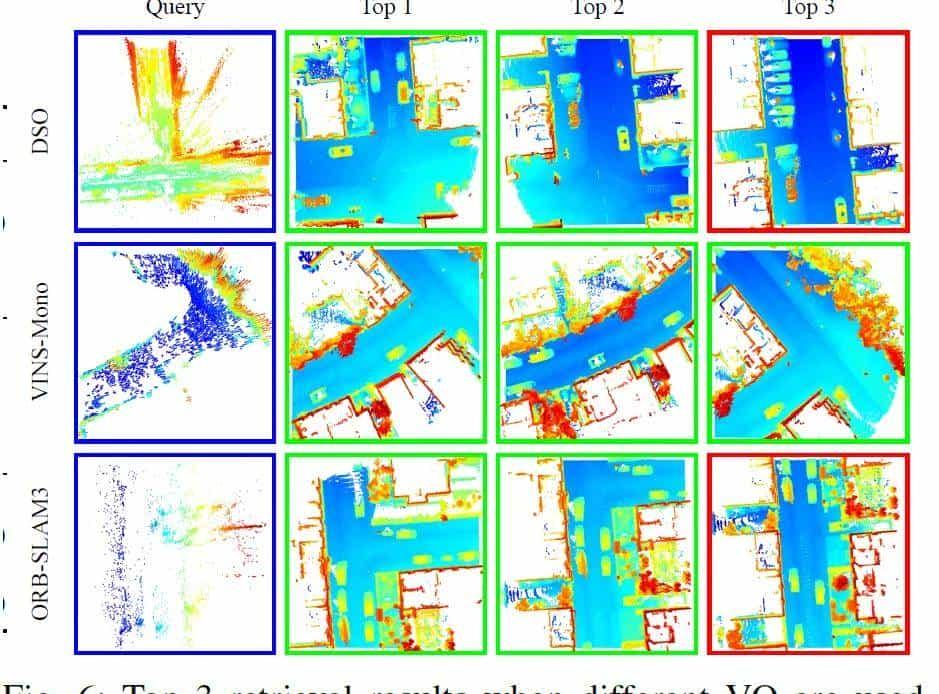
b)检索结果:图6展示了三种不同VO方法的前3个检索结果。显示的查询未经过细化,检索到的子地图是激光雷达子地图。视觉点云和激光雷达子地图之间的差距是明显的,但我们的方法在大多数情况下都能工作。不过,来自不同位置的子地图可能类似,导致错误匹配。
时间消耗
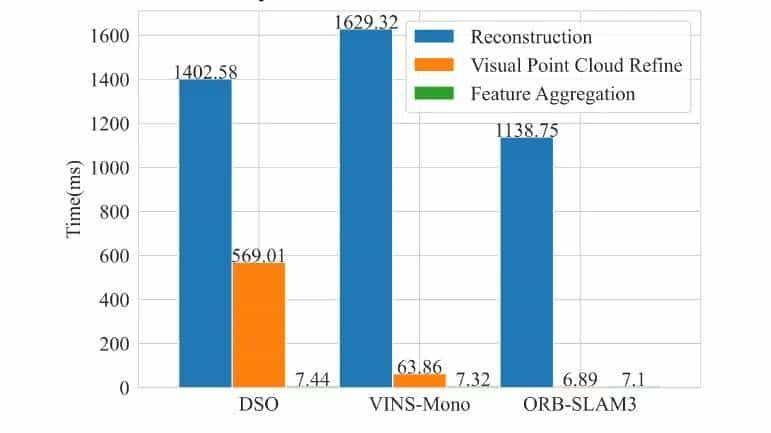
测试了各部分的时间成本,如图7所示。视觉点云细化和特征聚合模块的时间远远小于VO重新构建子地图所需的时间,对于由DSO生成的子地图的稠密化略微耗时,但对于由VINS-Mono和ORB-SLAM3重新构建的子地图超级高效,并且显着提高了定位精度。
这篇文章介绍了VOLoc,它利用几何类似性来定位压缩的激光雷达地图中的图像。提出的GRM模块从图像中恢复几何结构并对其进行优化以获得更好的几何质量。利用GPC对激光雷达地图进行压缩,同时保持几何一致性。提出了一种转移学习方案来训练基于注意力的聚合网络,这对网络聚焦注意力于重大点至关重大。结果表明,所提出的方法在内存效率上表现出色,并且与激光雷达到激光雷达的位置识别方法相当。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊交流群
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、大模型、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
大模型:NLP、CV、ASR、生成对抗大模型、强化学习大模型、对话大模型等
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
除了这些,还有求职、硬件选型、视觉产品落地、最新论文、3D视觉最新产品、3D视觉行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。
3D视觉工坊知识星球
3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、三维视觉C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪,无人机等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











