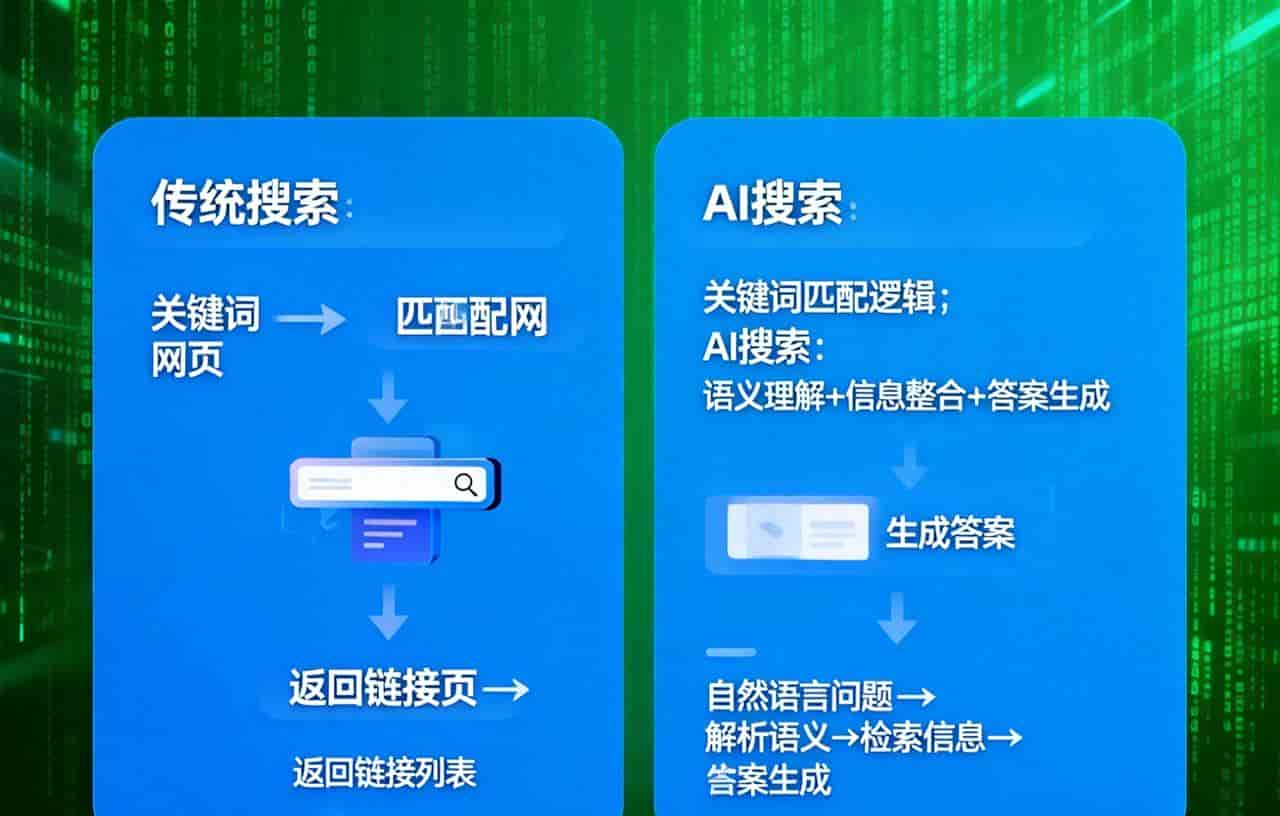
一、系统资源监控
1.1 CPU过载自动诊断脚本
#!/bin/bash
# CPU过载检测与修复脚本
THRESHOLD=80 # 阈值设为80%
ALERT_EMAIL="admin@example.com"
# 检测CPU负载
LOAD=$(uptime | awk '{print $(NF-2)}' | sed 's/,//')
if (( $(echo "$LOAD > $THRESHOLD" | bc -l) )); then
echo "警报:CPU负载[$LOAD]超过阈值[$THRESHOLD]!" | mail -s "CPU过载警告" $ALERT_EMAIL
# 自动杀死高CPU进程
ps aux --sort=-%cpu | head -n 5 | awk '{print $2}' | xargs -I {} sudo kill -9 {}
fi1.2 内存泄漏实时监控工具
# 内存泄漏检测脚本(需安装psutil)
import psutil
import time
import smtplib
def check_memory():
mem = psutil.virtual_memory()
return mem.percent
THRESHOLD = 90
while True:
current = check_memory()
if current > THRESHOLD:
with open("/var/log/mem_leak_alert.log", "a") as f:
f.write(f"[{time.ctime()}] 内存使用率:{current}%
")
# 发送邮件通知
server = smtplib.SMTP('smtp.example.com', 587)
server.sendmail("monitor@localhost", "admin@example.com",
f"主题:内存泄漏警告
内存使用率已达到{current}%")
server.quit()
time.sleep(60)二、网络故障排查
2.1 端口扫描自动化工具
#!/bin/bash
# 多协议端口扫描脚本
TARGET=$1
PORTS="22,80,443,3306,6379"
PROTOCOLS="tcp udp"
echo "开始扫描$TARGET的$PORTS端口..."
for PROTO in $PROTOCOLS; do
echo "===== $PROTO协议扫描结果 ====="
nmap -s$PROTO -p$PORTS $TARGET
done2.2 网络质量实时监测仪表盘
# 实时网络延迟/丢包监测
watch -n 1 "
echo '===== 网络质量监测 ====='
ping -c 1 google.com | grep 'time='
traceroute -n google.com | awk '{print $2}' | xargs -I{} ping -c1 {} | grep 'time='
"三、系统服务管理
3.1 服务自愈脚本(以Nginx为例)
# /etc/systemd/system/nginx.service.d/override.conf
[Unit]
Restart=always
RestartSec=5
[Service]
ExecStartPre=/bin/bash -c 'if ! curl -sSf http://localhost/healthcheck >/dev/null; then exit 1; fi'3.2 批量服务状态检查工具
#!/bin/bash
# 批量检查关键服务状态
SERVICES=("sshd" "nginx" "mysql" "redis")
echo "===== 服务状态检查 ====="
for SVC in "${SERVICES[@]}"; do
STATUS=$(systemctl is-active $SVC)
if [ "$STATUS" != "active" ]; then
echo "❌ 服务[$SVC]未运行!状态:$STATUS"
journalctl -u $SVC -f
else
echo "✅ 服务[$SVC]正在运行"
fi
done四、日志分析
4.1 错误日志聚合分析工具
#!/bin/bash
# 按时间聚合错误日志
LOG_FILE="/var/log/syslog"
KEYWORDS=("error" "fail" "critical")
echo "===== 错误日志聚合分析 ====="
for KW in "${KEYWORDS[@]}"; do
echo "===== 关键词[$KW] ====="
grep -Ei "$KW" $LOG_FILE | awk '{print $1,$2,$3}' | sort | uniq -c | sort -nr
done4.2 实时日志监控预警
# 实时监控日志并触发警报
tail -fn0 /var/log/auth.log | while read line ; do
if echo "$line" | grep -q "Failed password"; then
echo "$line" | mail -s "登录失败警告" admin@example.com
fi
done五、硬件故障排查
5.1 硬件健康状态监测脚本
# 硬件温度监控(需lm-sensors支持)
import subprocess
def get_sensor_data():
output = subprocess.check_output("sensors".split()).decode()
temps = {}
for line in output.split("
"):
if "+" in line and "temp" in line:
key = line.split(":")[0].strip()
val = line.split("+")[1].split()[0]
temps[key] = val
return temps
while True:
temps = get_sensor_data()
print("===== 硬件温度监测 =====")
for sensor, temp in temps.items():
print(f"{sensor}: {temp}°C")
if any(int(t[:-1]) > 80 for t in temps.values()):
print("⚠️ 温度过高!请立即检查硬件!")
time.sleep(60)六、性能优化
6.1 内核参数自动调优脚本
#!/bin/bash
# 自动优化TCP/IP协议栈
echo "正在优化网络性能..."
sysctl -w net.ipv4.tcp_syncookies=1
sysctl -w net.core.somaxconn=4096
sysctl -w net.ipv4.tcp_max_syn_backlog=8192
echo "优化完成!"6.2 磁盘IO调度算法优化
#!/bin/bash
# 根据存储类型自动选择IO调度器
BLOCK_DEVICES=$(lsblk -d -o NAME | grep -v sr0)
for DEV in $BLOCK_DEVICES; do
if blkid $DEV | grep -q "TYPE="ssd""; then
echo "SSD设备:$DEV -> 设置调度器为noop"
echo noop > /sys/block/$DEV/queue/scheduler
else
echo "HDD设备:$DEV -> 设置调度器为deadline"
echo deadline > /sys/block/$DEV/queue/scheduler
fi
done七、常见故障处理
7.1 系统启动失败修复流程
# 应急修复模式操作指南
1. 启动时按Shift进入GRUB菜单
2. 选择内核版本按e编辑
3. 在linux行末尾添加:
systemd.unit=rescue.target
4. 按Ctrl+X启动救援模式
5. 执行fsck -y /dev/sda1 修复文件系统
6. 重启系统
# 自动化修复脚本(需在救援模式运行)
#!/bin/bash
mount -o remount,rw /
fsck -y /dev/sda1
systemctl enable NetworkManager
exit八、自动化诊断工具箱
一键诊断脚本
#!/bin/bash
# 全系统快速诊断
echo "===== 系统诊断报告 ====="
echo "1. 系统信息"
uname -a
echo "2. 磁盘空间"
df -h
echo "3. 内存使用"
free -m
echo "4. 网络连接"
netstat -tunlp
echo "5. 进程状态"
top -bn1 | head -n 20
echo "6. 最近登录记录"
last -n 10
echo "7. 系统日志"
journalctl -xe | tail -n 50使用说明:
- 所有脚本需保存为.sh文件并通过chmod +x script.sh赋予执行权限
- 关键脚本提议配置定时任务(如每天凌晨执行):
- 0 0 * * * /path/to/disk_cleanup.sh >> /var/log/disk_cleanup.log 2>&1
- 生产环境使用前请先在测试环境验证
- 提议将日志输出到聚焦管理系统(如ELK/Elasticsearch)
该手册提供从基础监控到高级故障处理的完整解决方案,提议配合以下最佳实践:
- 定期备份关键数据(推荐使用rsync+inotify)
- 部署Prometheus+Grafana监控系统
- 建立标准化的服务部署流程
- 实施最小权限原则管理用户权限
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章













收藏了,感谢分享