
本文首发于微信订阅号“大数据风控官”,为汇百川信用原创作品,未经允许不得转载。
说起“反欺诈系统”,或许在三年前大家对此还比较陌生,这种面向企业级的应用一般深藏在银行、保险等金融行业的内部系统中,或者是各大互联网公司安全系统中,不免有一些神秘感。近些年,随着“互联网+金融”的迅速壮大,诞生出了不少专门为金融机构提供风控和反欺诈服务的第三方公司, “反欺诈系统”从而在技术圈逐渐为大家知晓。
面对形形色色的欺诈份子和欺诈手段,作为一名反欺诈斗士,没有得心应手的武器怎么行?笔者大致整理了反欺诈系统中常用到的相关技术或者开源工具,无意中与古龙笔下的“七种武器”联系起来,借此给枯燥乏味的技术文章增加些许趣味。
反欺诈系统看似没有复杂的业务逻辑,却涉及方方面面、五花八门的服务端以及大数据相关技术。鉴于篇幅的关系,本文作为一个索引把各种技术和工具在反欺诈系统架构的作用进行简单介绍。在后续的系列文章中,会对每一种技术进行较为详细和深入的介绍。
长生剑 — Open API
前段时间看到一篇文章《The Rise of the API-based SaaS》,猛然发现,面向企业的SaaS服务真的进入了“告别界面,进入API”的时代。一般来讲,“反欺诈”是作为金融机构整体业务流程的一个环节,因此第三方的服务需要无缝地集成到客户的业务系统当中,那么基于web的API就成了反欺诈服务最常见的产品形态。
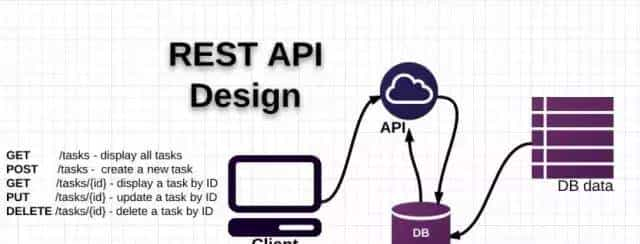
说到基于web的API,大家可能会想到一个挺常见的名词“Restful”。如果按照Fielding 在2000年提出“REST”架构风格的那篇博士论文为标准,目前的工业界里面,真心没找到严格符合“REST”的web API设计。貌似最接近的是Facebook的“Graph API”,它是由Node(资源)和Edge(转移)构成了一个通过状态转移连接而成的资源图。因此,笔者把“REST”当做一套web API设计的最佳实践,和大家分享。
那么一个好的Restful web API设计需要哪些最佳实践呢?相关文章不少,笔者挑几个重大的,结合自己的认识来讲讲:
1、无状态与幂等性
这里的无状态指的是客户端和服务端交互时的无状态性,也就是说服务器端不维护每次客户端请求对资源状态的影响。服务端对资源的表述完全由客户端请求时的信息而决定。这样做的好处是,客户端请求时能明确知道得到的结果,而不必去纠结资源状态在服务端产生了什么样的变化。由于我们讨论的是web API,因此这里的幂等性特指HTTP协议的相关性质。从定义来看,HTTP方法的幂等性是指一次和多次请求某一个资源应该产生同样的副作用。
为什么要强调无状态和幂等呢?这是由于web API 实际上是运行在一个分布式网络环境当中的系统,环境复杂,调用失败而后重试是一种常见的情况,因此幂等性保证了失败后的调用依旧能够取得正常预期的结果,多次调用不会造成操作结果最终的不一致性。反欺诈系统大部分是读取和匹配操作,写操作较少,那么对应HTTP的GET请求,本身的语意就应该是幂等性的。这里笔者不禁又扯出一个话题,时下函数式编程被提及的越来越多,也是由于函数式编程对数据状态的不可变操作,很好地支持了程序并发/并行的需求。
2、使用统一的接口和标准的HTTP谓词
有一种说法是,尽量把对资源操作的CRUD操作,对应到HTTP谓词上,例如,对资源的读取操作对应HTTP的GET请求。这一点虽然颇具争议,但是笔者也看到各种API(不乏一些一二线公司)采用动宾短语,这样一来GET、POST亦或是PUT、DELETE请求都无所谓了。个人认为,最好还是不要这样,容易造成开发人员对系统领域模型、资源、状态等概念认识不到位,动宾短语写法过多,规范性较差,也造成不必要的沟通障碍。
孔雀翎 — 微服务(MicroService)
如果说Open API是作为反欺诈系统的外在产品形态,那么微服务则是反欺诈系统内部的架构模式。微服务架构并不是一个全新的事物,大家必定还记得SOA(面向服务的架构模式)。实则,在微服务提出之前,许多互联网应用就已经开始进行基于SOA风格的架构重构系统,将系统进行垂直切分,切分的组件(服务组)独立地运行维护,组件对外通过暴露服务的形式,与其他组件协同(运行态的协同,而不是静态的依赖关系,这一点很重大),实现完整的业务逻辑。这样做的好处是在业务层面,增强了系统的扩展性和可靠性(根据CAP理论,损失了一致性,不过目前大部分场景中,可以通过最终一致性来弥补)。
那么下面再列举几个笔者认为开发基于微服务架构系统时,需要注意的几个问题:
1、服务的划分和粒度
服务背后实则是业务实现,那么服务的划分,对应的就是业务的划分。在业务划分按照领域模型的关系紧密程度来划分服务组,列如电商平台可以按照用户、订单、商品、商家、仓储、快递等,对于服务组的划分并非一成不变,也可以按照系统演进的节奏,逐步实现。关于服务的粒度,原则就是尽量暴露能映射到原子业务的服务接口,最忌讳的是类似“大杂烩”或者“通用”接口。
2、服务治理和API Gateway
在单体架构中,组件的依赖都是静态的,组件提供什么接口,实现什么功能,在编码时基本上就已经是明确的,再借助类似Maven(特指Java)这样的依赖管理和构建工具,基本不会造成太大的组件协作问题。服务间的运行期分布式依赖就没那么容易管理了,虽然也有类似Zookeeper、Kubernetes等开源服务治理框架,但是在实践过程中,还是容易发生各种问题,这种分布式的复杂性,也是微服务被诟病的地方之一。按照笔者的经验,服务治理这块第一是人治,即接口的统一性和文档完备性很重大,当业务发展壮大,服务逐渐变多的时候,没有如果超级靠谱的接口规范,服务组开发的沟通成本会直线上升,使得开发效率,服务的可靠性受到较大影响。
API Gateway也是一个不得不提到的概念。Gateway,顾名思义,它是一个处于系统边界的东东,负责“大门口”的各项工作(实则上文提到的Open API,某种意义上就是一种API Gateway)。那么它的具体有哪些呢?
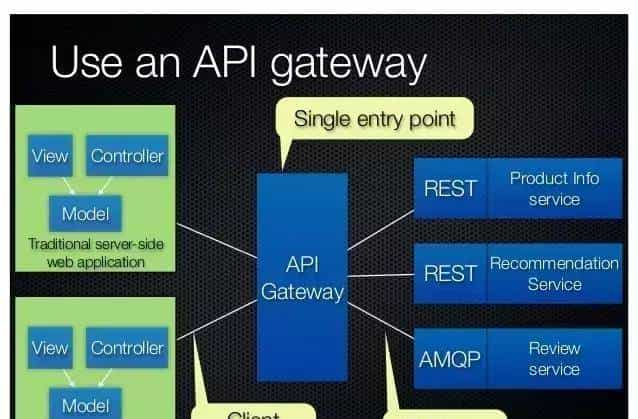
图片来源:
http://microservices.io/patterns/apigateway.html
其一,对细颗粒的服务进行包装,统一封装对外提供服务(这里有点类似设计模式中外观模式的意思);其二,负责适配,隐藏服务内部实现的细节,提供符合各种客户端调用需求的统一接口,包括路由、协议转换等工作;其三,安全、流控、屏蔽等通用性的应用横切面的相关工作。
碧玉刀 — 规则引擎
Open API和微服务看上去似乎和反欺诈系统没有很直接的关系。下面出场的“碧玉刀”规则引擎就不同了,它是许多反欺诈系统的重大组成部分。我们知道,反欺诈的核心业务逻辑实际上就是通过一些系列的规则组合,把可疑的操作排除在正常的业务之外。列如针对一个网络贷款进件,我们可以用如下规则过滤可疑申请(用户授权下):“在网时长规则”即申请的手机号必须在网大于必定时长,以避免欺诈份子临时办取手机号,进行业务申请,而后丢弃失联;“电信服务使用地理范围验证规则”,即申请者申请时的APP定位位置与手机电信服务使用地理范围不能有太大偏差,以避免被他人冒充信息办理业务; 还有基于实时数据统计的规则,列如某个手机号或者设备在短时间内发起大量的业务请求,那么就需要触发类似的限制规则。
那么,为什么要用规则引擎呢?在欺诈和反欺诈的博弈中,所谓“道高一尺,魔高一丈”,规则永远不是一成不变的,而且不同的业务形态、业务目标也决定了反欺诈的规则需要能都灵活配置和调整。“硬编码”是万万不能的,所以,这就是规则引擎发挥作用的地方。
一个合格的反欺诈规则引擎需要支持那些种类的规则呢?下面一一道来:
1、静态规则,就是基于某个静态值的限制性规则,列如三元验证一致、是否命中黑名单、常用联系人验证、电信服务使用地理范围验证等;
2、统计规则,是用统计计算的值来作为验证的条件,如来自某个设备或者IP的申请次数大于某个值;
3、关联规则,是指用户在进行了某个操作之后,又执行另外一个操作,带来的风险。例如,修改账号密码后,进行交易操作;
4、行为规则,是指用户的异常行为,例如用户在常驻地址或者某个特殊的时间如深夜,进行了交易操作,我们也认为具备必定的风险。
那么在开源软件的世界里,也有一款不错的规则引擎Drools,它是一个基于Java的开源规则引擎,可以将复杂多变的规则从硬编码中解放出来,以规则脚本的形式存放在文件中(drl文件或者xml文件),规则的变更不需要改动代码和重启机器就可以立即在线上环境生效。
离别钩 – 大数据OLAP引擎
上面我们提到了统计型规则,统计型规则本身并不复杂,关键的是如何进行灵活的和实时的统计计算。例如,我们要设置这样规则“来自某个IP或者设备指纹在60秒内的请求高于某个值”,就触发拒绝动作。类似这些规则,没有一个好的大数据OLAP引擎(区别于传统的OLAP)是难以支撑的。在这方面,业内有不少不错的开源工具,这里推荐两款工具Druid和Kylin。这两者都是为了解决大规模数据的情况下,如何更灵活地进行OLAP而生的工具,但是各有侧重点,读者可以根据自身需求来选择。
Druid更适合做实时统计,能更好地集成Kafka作为数据源,进行实时流式数据分析处理,而Kylin的特点是支持MOLAP Cube,通过预计算的方式将用户设定的多维立方体缓存到HBase中,因此它的侧重点是实现较为复杂或者涉及大量数据(billion级别)计算的OLAP分析。从对外接口上来看,Kylin支持标准的SQL,并且能和Tableau或者Excel等BI可视化工具集成;而Druid目前还不支持这些。
还有一个不能不说的工具,Elasticsearch,原本是一款分布式(文本)搜索引擎,由于支持在大数据环境中进行实时数据分析,因此目前也被越来越多用于OLAP,大家也可以多多关注。
霸王枪 — 机器学习
在业界各方的努力下,欺诈的成本是越来越高的,一个小白单枪匹马已经很难钻到空子了。团伙作案是欺诈行为的大趋势,他们有组织,有反侦察的经验,懂得伪装和隐藏自己,一般在一个团伙中,会有明确的分工。从一个个独立的规则,无论是基于设备指纹+黑名单,还是某种特殊的数据源,都很难将团伙作案完全识别。因此,如何防范团伙欺诈,是未来一段时期反欺诈工作的重大课题。是时候介绍当前技术界的当红炸子鸡“机器学习”霸气出场了(还有红的发紫的深度学习,都属于人工智能的范畴,透露一下,下篇文章会涉及这方面的内容喔)。
同样的套路,笔者介绍目前三种基于机器学习的反欺诈策略。
其一,对于养卡号码的识别。欺诈份子想要逃避罪责,必然不会使用任何有可能暴露自己的真实身份的手段和信息来进行欺诈活动。逃避“设备指纹”换一部手机就可以了,但是新的手机号码是无法使用的(还记得在网时长的限制吗?),因此,他们手头上必须有长期养起来的电话卡。通过我们对一些养卡样本的分析,养卡的行为还是比较明显的,基于养卡样本建立预测模型,在养卡号码识别上,得到了不错的效果。
其二,对申请人背后的社交圈的挖掘和交叉关联。从同一个地址申请;一样的联系人;类似的行为等等,欺诈份子虽然能改变一部分的欺诈行为,但是他在活动中产生的各种关联,是难以模拟和抹去的。对数据进行图计算和挖掘,能对欺诈团伙的识别起到不小的作用。
其三,除去一些超级强的规则,基于部分规则的反欺诈策略过于简单粗暴,缺乏柔性判定。不少机构或者公司为了控制风险,往往将规则限定的超级紧,但是在控制风险的情况下,同时也大量流失了正常用户。而机器学习的目的是,基于样本学习一个能够讲好坏人群进行一个稳定的预测,然后通过调节利率,来实现企业利润最大化的目的。当然,区分度越高是越好的,但也不必非要执着于此。
多情环 — 日志存储和分析引擎
无论是OLAP还是机器学习,没有数据,一切都是空谈。数据从哪来?实则,一切用于分析的数据,包括业务产生的数据,笔者认为都是日志的范畴,或者说都需要用强有力的工具,将这些数据汇聚和存储,这是分析的基础。
目前最流行的组合基本上是这样,Flume+Kafka 作为日志汇聚和存储的组件,通过Kafka(基于生产者-消费者的消息队列),接入Storm、Spark Streaming或者Druid、Elasticsearch等数据处理和分析引擎。当然,也有许多其他的组合,大家可以根据自身的数据情况和业务需求来学习和使用这些工具。
第七种武器 没有武器
没错,第七种武器就是没有武器。这里想强调的是,反欺诈领域没有“银弹”,还是那句话,“道高一尺,魔高一丈”,所谓武器只是帮我们实现思想的工具。只有深刻理解业务,了解各种欺诈场景和欺诈份子的动机,不断地快速迭代,才能有效地防范欺诈,为公民的正常经济生活和国家的金融秩序保驾护航。
作者:来自汇百川信用的技术大神
注意:原创作品,未经允许不得转载
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










