当线上系统的QPS在毫无预警的情况下飙升100倍,整个技术团队会面临巨大的压力。此时,正确的应对流程至关重大,一步走错就可能导致雪崩式的服务崩溃。本文将系统性地阐述从 “紧急响应”到 “根本解决”再到 “架构进化”的完整应对策略。
第一阶段:紧急响应,快速止血(自动/手动)
当监控系统发出刺耳的警报,我们的第一要务不是探究“为什么”,而是“怎么办”。目标是保证系统不崩溃,核心服务可用。下图清晰地描绘了紧急响应的决策流程:
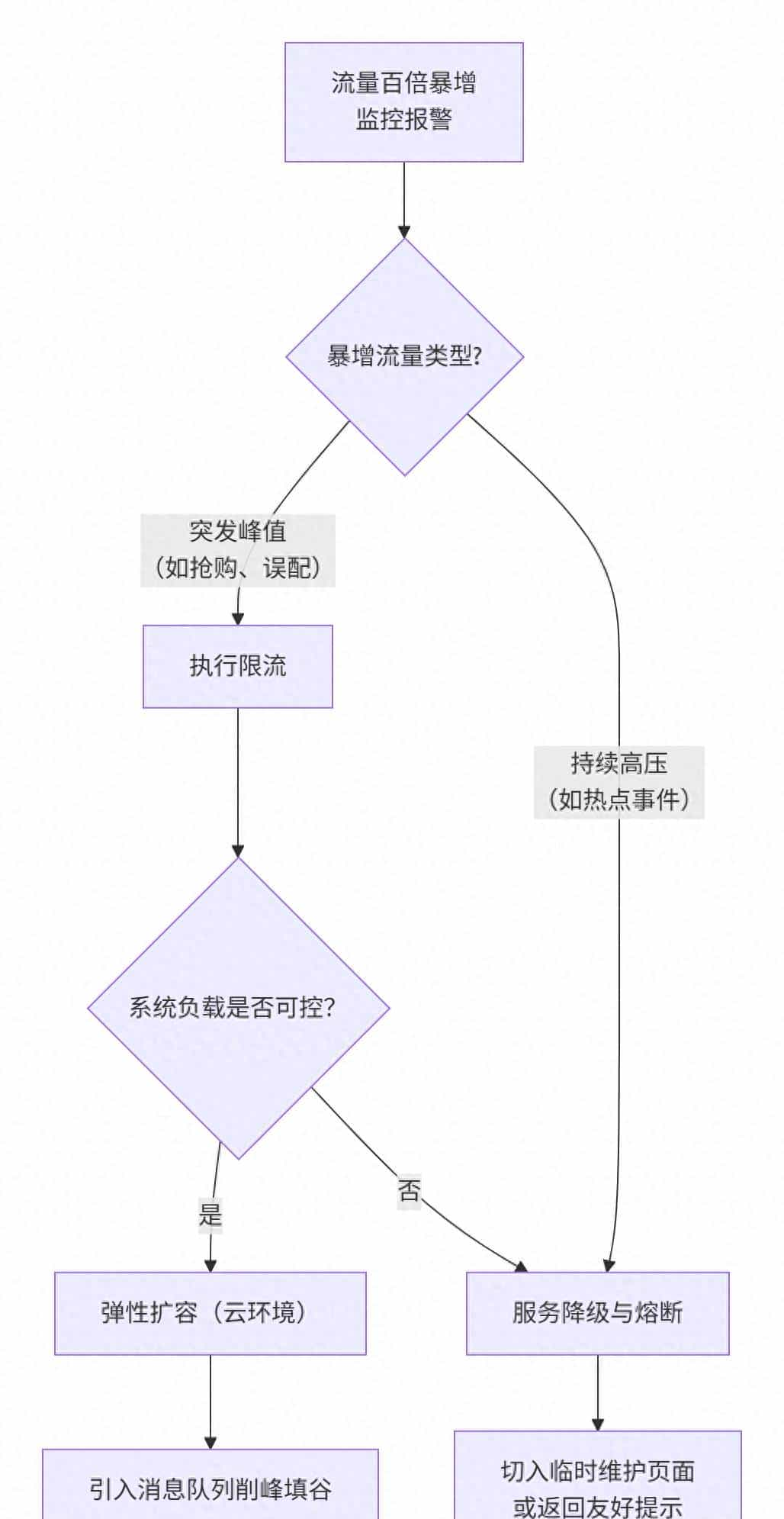
下面我们详解流程中的每一步:
1. 限流 – 守护系统的铁闸
限流是应对突发流量的第一道防线,其核心思想是:抛弃部分请求,保证系统不垮。
- 常用算法:
- 计数器算法:在特定时间窗口(如1秒)内,计数请求数,超过阈值则拒绝。
- 滑动窗口算法:解决计数器算法在时间窗口临界点的流量突刺问题,更准确。
- 令牌桶算法:以恒定速率向桶中放入令牌,请求需获取令牌才能通过。可以应对必定程度的突发流量。
- 漏桶算法:请求像水一样以恒定速率流出,平滑网络流量。
- 实施层面:
- 网关层限流(Nginx, API Gateway):全局流量入口处进行限制,最简单有效。例如,对某些非核心API直接配置QPS阈值。
- 应用层限流:在业务代码或框架(如Spring Cloud Gateway, Sentinel)中,对特定方法或接口进行限流。
2. 服务降级与熔断 – 弃车保帅
当系统压力过大时,主动关闭非核心功能,释放资源给核心服务。
- 服务降级:
- 示例:关闭商品推荐、用户积分、个性化签名等非核心功能;将某些动态内容(如评论)直接切换为静态缓存。
- 目标:保证核心交易链路(登录-查看商品-下单-支付)的畅通。
- 服务熔断:
- 当某个依赖服务(如积分服务)响应慢或失败率高时,熔断器会“跳闸”,后续请求直接返回降级策略(如默认值或错误提示),而不是一直等待,防止线程池被占满导致整个服务雪崩。Hystrix和Sentinel是实现熔断的常用工具。
3. 弹性扩容 – 增加处理能力
如果流量是持续性的,并且云环境允许,快速扩容是根本解决方法。
- 方式:
- 垂直扩容(Scale-up):增加单机性能(CPU、内存)。在云上操作较快,但有物理上限。
- 水平扩容(Scale-out):增加服务器实例数量。这是更推荐的方式,体现了分布式系统的优势。
- 关键:系统必须支持无状态化,即业务实例本身不保存会话(Session)数据,才能实现平滑扩容。Session应存储在外部缓存(如Redis)中。
4. 消息队列 – 削峰填谷的利器
对于高并发的写请求(如秒杀下单),引入消息队列进行异步化解耦。
- 流程:
- 前端请求发送到消息队列(如Kafka, RocketMQ)后立即返回“请求已接受,正在处理中”的提示。
- 后端服务按照自身处理能力,从队列中匀速消费消息,完成业务逻辑(如扣库存、生成订单)。
- 效果:将瞬时的流量洪峰压平为一段时间的匀速消费,极大地减轻了数据库的压力。
第二阶段:分析根因,对症下药
在系统暂时稳定后,立即组织力量分析流量暴增的缘由。
- 是正常业务吗?如热点营销活动、顶流网红带货。如果是,说明技术准备不足。
- 是恶意攻击吗?如DDos攻击、爬虫刷接口。需要联动安全团队进行识别和封禁。
- 是程序BUG吗?如代码死循环、误配置导致的重试风暴。
根据缘由,制定长期的技术优化方案。
第三阶段:架构升级,防患于未然
一次流量危机是最好的压力测试,暴露了系统的薄弱环节。以下是长期的架构优化方向:
1. 横向扩展与微服务拆分
- 横向扩展:建立自动化的弹性伸缩机制,根据CPU、负载或自定义指标(如消息队列堆积量)自动增减实例。
- 微服务拆分:将巨型单体应用拆分为松耦合的微服务。这样可以对压力大的服务(如商品详情)单独扩容,避免一个不重大的功能拖垮整个系统。
2. 数据库优化
- 池化技术:使用数据库连接池(如HikariCP)、Redis连接池,避免频繁创建销毁连接的开销。
- 读写分离:主库负责写,多个从库负责读,极大提升读并发能力。
- 分库分表:当单表数据量巨大时,进行水平拆分或垂直拆分,这是解决数据库瓶颈的终极手段之一。
- 使用缓存:
- 客户端缓存:HTTP缓存头(如Cache-Control)。
- CDN缓存:将静态资源(图片、JS、CSS)推送到边缘节点。
- 应用缓存:大量使用Redis、Memcached等缓存热点数据,减少数据库访问。注意缓存穿透、击穿、雪崩问题。
3. 异步化设计
- 在所有可能的环节采用异步,如异步RPC调用、异步处理任务。这能有效提高线程资源利用率和系统吞吐量。
4. 常态化压力测试与混沌工程
- 压力测试:在上线前和日常,定期对系统进行全链路压测,准确评估系统容量和瓶颈点。
- 混沌工程:主动模拟故障(如随机杀进程、模拟网络延迟),检验系统的容错和自愈能力,避免在真实故障面前手足无措。
总结
应对百倍流量暴增,是一个系统工程,需要清晰的预案和强劲的技术执行力。
- 短期:遵循 “限流 -> 降级/熔断 -> 扩容 -> 队列削峰”的流程快速止血。
- 长期:围绕微服务、缓存、异步、分库分表等核心技术,构建一个高可用、可伸缩的分布式架构。
- 机制:建立完善的监控告警体系和常态化压测机制,让团队对系统容量心中有数,面对突发状况从容不迫。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...