上一篇写了一个基于 LeNet 的 CNN 模型模型 demo,这次搞个AlexNet。相较于LeNet,AlexNet在模型构造方面有本质的不同,理论层面的文章大家可以自行搜索学习,咱直接上 demo 干货,注释详细。
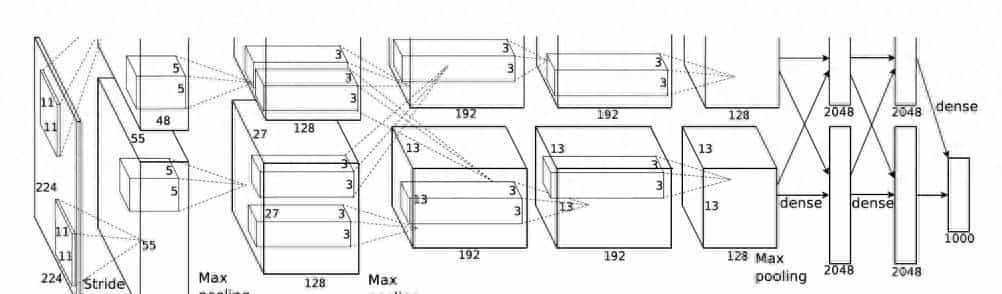
AlexNet CNN 网络结构
模型构造
import torch.nn as nn
import torch
class AlexNet(nn.Module): # AlexNet类
def __init__(self, num_classes=5, init_weights=False):
super(AlexNet, self).__init__() # 用nn.Sequential()将网络打包成一个模块,精简代码
self.features = nn.Sequential( # 卷积层提取图像特征
nn.Conv2d(in_channels=3, out_channels=48, kernel_size=11, stride=4, padding=0), # input[3, 227, 227] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(in_channels=48, out_channels=128, kernel_size=5, stride=1, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13],stride=1可省略
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential( # 全连接层对图像分类
nn.Linear(in_features=128 * 6 * 6, out_features=2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5), # Dropout 随机失活神经元,默认比例为0.5
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x): # 前向传播
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def _initialize_weights(self): # 网络权重初始化
for m in self.modules():
if isinstance(m, nn.Conv2d): # 若是卷积层
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') # 用何凯明法初始化权重
if m.bias is not None:
nn.init.constant_(m.bias, 0) # 初始化偏重为0
elif isinstance(m, nn.Linear): # 若是全连接层
nn.init.normal_(m.weight, 0, 0.01) # 正态分布初始化
nn.init.constant_(m.bias, 0) # 初始化偏重为0
喂数据训练模型
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
os.environ["OMP_NUM_THREADS"] = "1"
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import torch.optim as optim
from tqdm import tqdm
from model import AlexNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 判断用GPU或CPU训练
print("using {} device.".format(device))
data_transform = { # 图片变换
"train": transforms.Compose([transforms.RandomResizedCrop(227), # 随机裁剪,再缩放成 227×227
transforms.RandomHorizontalFlip(), # 随机在水平或者垂直方向翻转图片
transforms.ToTensor(), # 将灰度范围从[0,255]变换到[0,1]
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]), # 将数据转换为[-1,1]的标准高斯分布
"val": transforms.Compose([transforms.Resize((227, 227)), # 将输入图片转化为(227, 227)的输入特征图
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
image_path = "flower_data" # flower data路径
# 导入训练集并进行预处理
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset) # 训练集有多少张图片
# 字典,类别:索引 {'daisy':0, 'dandelion':1, -='roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
# 将 flower_list 中的 key 和 val 调换位置
cla_dict = dict((val, key) for key, val in flower_list.items())
# 将 cla_dict 写入 json 文件中
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset, # 导入的训练集
batch_size=batch_size, # 每批训练的样本数
shuffle=True, # 是否打乱训练集
num_workers=nw) # 加载数据(batch)的线程数目
# 导入验证集并进行预处理
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
# 加载验证集
validate_loader = torch.utils.data.DataLoader(validate_dataset, # 导入的验证集
batch_size=4, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
net = AlexNet(num_classes=5, init_weights=True) # 实例化网络(输出类型为5,初始化权重)
net.to(device) # 分配网络到指定的设备(GPU/CPU)训练
loss_function = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = optim.Adam(net.parameters(), lr=0.0002) # 优化器(训练参数,学习率)
epochs = 10
save_path = './AlexNet.pth'
best_acc = 0.0 # 历史最优准确率
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train() # 训练过程中开启 Dropout
running_loss = 0.0 # 每个 epoch 都会对 running_loss 清零
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data # 获取训练集的图像和标签
optimizer.zero_grad() # 清除历史梯度
outputs = net(images.to(device)) # 正向传播
loss = loss_function(outputs, labels.to(device)) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 优化器更新参数
# 打印训练进度(使训练过程可视化)
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,loss)
# validate
net.eval() # 验证过程中关闭 Dropout
acc = 0.0 # 每次epoch清空累计验证正确样本个数
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device)) # 验证图片指认到device上,传到网络,进行正向传播,得到输出
predict_y = torch.max(outputs, dim=1)[1] # 以output中值最大位置对应的索引(标签)作为预测输出
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num # 验证集正确率 = 验证正确样本个数/总的样本数
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc: # 当前准确率大于历史最优的准确率
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
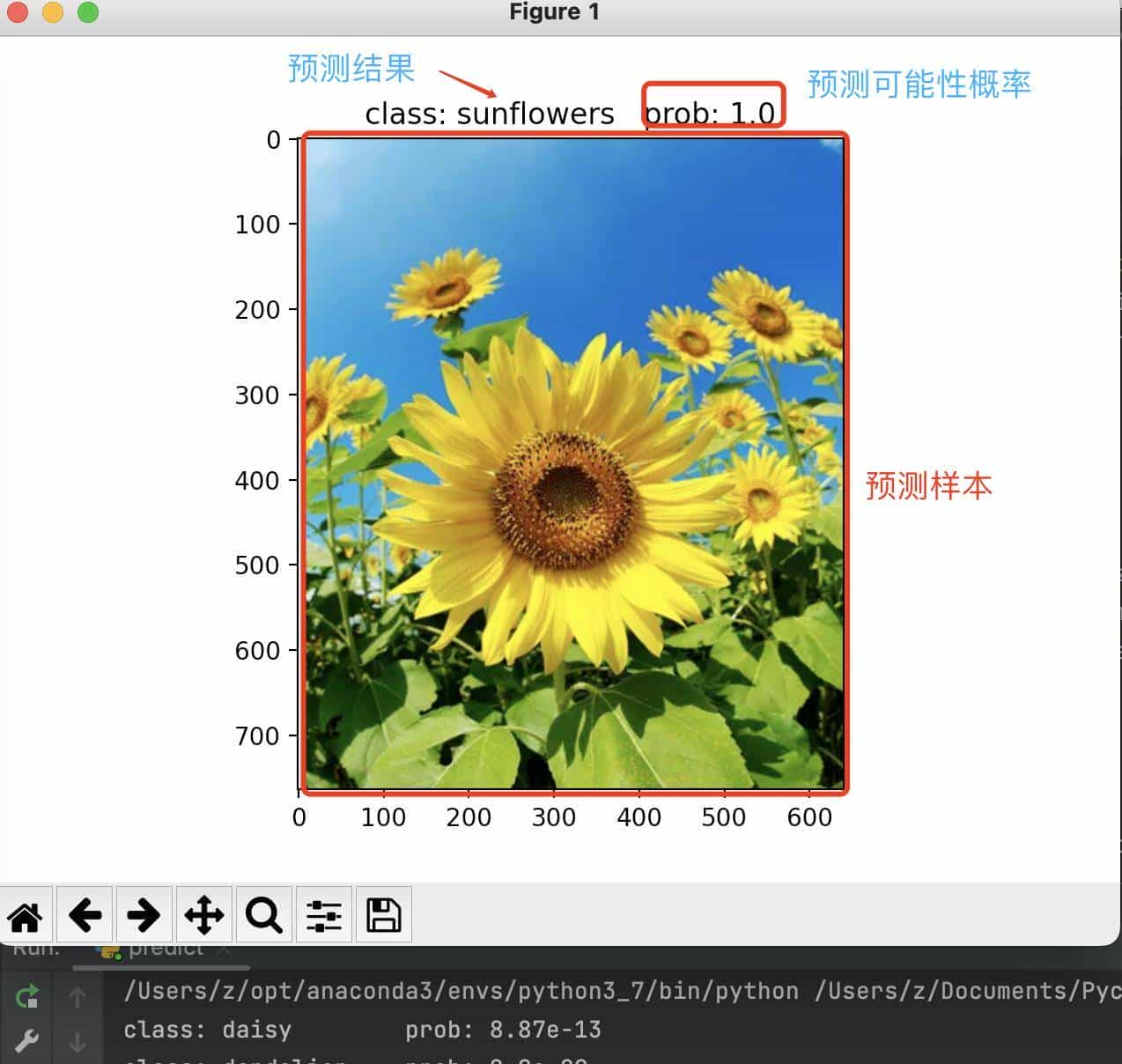
预测结果
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...