
本文将详细介绍并实践以下内容:
-LangChain 各组件(LLM、工具、链、记忆、Agent、提示、RAG、Retriever 等)在完整项目中的协作关系
- 结合 DeepSeek + bge-small-zh + FAISS + DuckDuckGoSearch
- 提供模块化代码示例,说明每部分的职责与灵活性
- 使用 FastAPI 将 Agent 封装成 API 服务,可用于 Web 前端接入
- Tool 封装规范、Agent 执行中间状态管理、复杂提示结构设计等
本文章将系统讲解如何基于 LangChain 框架构建一个功能齐全、可部署的智能问答 Agent。我们将结合前文核心概念(ReAct 架构、RAG 检索增强、提示工程、工具调用等)逐步展开,选用 DeepSeek 聊天模型作为 LLM、BAAI/bge-small-zh-v1.5 作为中文嵌入模型、FAISS 作为向量数据库、DuckDuckGoSearchRun 作为联网搜索工具,最终封装成 RESTful 服务。
一、LangChain框架概述
什么是LangChain?
LangChain是一个用于开发由语言模型驱动的应用程序的框架。它允许开发者将大型语言模型(LLMs)与其他计算或知识源连接起来,从而创建更强劲、更灵活的AI应用。
LangChain核心组件
LangChain包含多个核心模块,这些模块可以组合使用来构建复杂的AI Agent:
- Models:支持多种语言模型接口
- Prompts:提示管理、优化和序列化
- Memory:短期和长期记忆管理
- Indexes:文档加载、处理和检索
- Chains:调用序列和组合
- Agents:动态决策和工具使用
- Callbacks:日志和流式传输
二、核心概念回顾
-
ReAct 框架:是一种将推理(Reasoning)与动作(Action)相结合的交互式提示方式。LangChain 的 ReAct Agent 可以让模型在对话过程中思考 (Thought:)、采取动作 (Action:) 并观察结果 (Observation:),从而动态调用外部工具。例如,当模型面临复杂问题时,可以通过调用搜索工具或数据库工具来获取补充信息,再结合生成能力给出答案。
-
RAG(检索增强生成):指在生成回答时通过检索相关文档来提供上下文或证据的技术。RAG 适用于将领域知识融入对话,避免模型只凭「记忆」回答超出能力的问题。我们会使用向量数据库(FAISS)和文本嵌入来实现 RAG,从海量文档中检索与用户问题最相关的内容,再输入模型生成答案。
-
提示工程:通过 PromptTemplate 等机制设计和组织模型提示,将任务指令、示例和变量拼接成最终输入。好的提示可以大幅提升模型理解和回答能力。我们将定制提示模板,明确说明用户意图及可用工具等,引导模型在 ReAct 交互中正确使用工具。
-
工具调用:Agent 能访问的工具(如搜索引擎、知识库查询、计算器等)需封装为符合接口的 Tool 对象,包含名称、调用函数和用途说明。在 ReAct 策略下,模型可以选择某个工具并按指定格式传入参数。本文示例中,将集成联网搜索与本地向量检索两种工具供 Agent 使用。
-
多轮对话与记忆:使用 ConversationBufferMemory 记录会话历史,实现上下文连续性。当用户提问时,上下文记忆会作为提示变量注入,让模型参考前文对话内容,使回答更具连贯性。
三、系统架构与组件选型
3.1 语言模型与嵌入
- LLM(聊天模型):选用 DeepSeek 提供的 deepseek-chat 模型作为对话模型。DeepSeek 是一系列开源模型,支持结构化输入、工具调用等能力。DeepSeek API 使用与 OpenAI 兼容的 API 格式,可使用 LangChain 的 ChatOpenAI 进行接入,如下所示:
第一准备环境,由于版本需要对齐:
pip install langchain==0.3.26 --force-reinstall
pip install langchain-core==0.3.66 --force-reinstall
pip install langchain-community==0.3.27 --force-reinstall
pip install langchain-text-splitters==0.3.8 --force-reinstall
import os
from langchain_community.chat_models import ChatOpenAI
API_KEY = os.getenv( DEEPSEEK_API_KEY )
llm = ChatOpenAI(
model= deepseek-chat , # 指定使用的模型名称,如 gpt-4、deepseek-chat 等
openai_api_key=API_KEY, # 设置 API 密钥
openai_api_base= https://api.deepseek.com/v1 , # 自定义模型地址(如 DeepSeek)
temperature=0.7, # 控制输出的随机性,越低越保守,越高越发散
max_tokens=1024, # 设置生成回复的最大 token 数
model_kwargs={ # 额外的模型参数(可选)
"top_p": 1,
"frequency_penalty": 0.0,
"presence_penalty": 0.0
},
request_timeout=60, # 请求超时时间(秒)
streaming=False, # 是否使用流式响应
verbose=False # 是否打印调试信息
)
✅ 参数使用提议
- 温度设置:
- temperature=0.0 适合问答、摘要、代码生成等确定性任务;
- temperature=0.7~1.0 更适合生成富有创意的内容。
-
兼容模型:
- 若使用 DeepSeek、Moonshot、Azure OpenAI 等非官方 API,务必设置 openai_api_base。
-
高阶用法:
- 可结合 LLMChain 或 AgentExecutor 构建复杂流程。
这样实例化后,llm.invoke([消息列表]) 即可获得模型回复。
response = llm.invoke("请简要说明“量子计算”和“经典计算”的主要区别。")
print(response)
输出:
content= 量子计算与经典计算的核心区别主要体目前以下方面:
### 1. **信息表明方式**
- **经典计算**:使用二进制位(bit),每个bit只能是0或1。
- **量子计算**:使用量子位(qubit),可处于0、1或两者的叠加态(量子叠加),同时表明多种状态。
### 2. **并行计算能力**
- **经典计算**:逐次处理任务,N位处理器一次处理一个N位状态。
- **量子计算**:N个qubit可同时处理2^N个状态(量子并行性),适合大规模并行问题(如因数分解、搜索)。
### 3. **操作原理**
- **经典计算**:基于布尔逻辑门(AND/OR/NOT等),确定性操作。
- **量子计算**:通过量子门操作(如Hadamard门、CNOT门),支持叠加态和纠缠态的操作,具有概率性。
### 4. **纠缠与关联性**
- **经典计算**:比特间独立或通过经典关联。
- **量子计算**:qubit可纠缠(entanglement),一个qubit状态变化立即影响另一个,即使相距遥远(非局域性)。
### 5. **算法效率**
- **经典计算**:解决常规问题(如排序、数据库查询)效率高。
- **量子计算**:特定问题指数级加速,如Shor算法(因数分解)、Grover算法(无序搜索)。
### 6. **错误处理**
- **经典计算**:通过冗余校验(如重复编码)纠错。
- **量子计算**:需量子纠错码(如表面码),因量子态脆弱易受退相干影响。
### 7. **物理实现**
- **经典计算**:基于硅基半导体(CPU/GPU),技术成熟。
- **量子计算**:需极端环境(超导、离子阱、光量子等),维持量子态难度大。
### 8. **应用领域**
- **经典计算**:通用计算,覆盖日常需求。
- **量子计算**:专长于优化、模拟量子系统、密码学等,无法完全替代经典计算。
### 总结
量子计算利用量子力学特性(叠加、纠缠)突破经典限制,但在通用性和稳定性上仍面临挑战。两者未来可能互补共存,量子处理特定任务,经典负责其余部分。 additional_kwargs={} response_metadata={ token_usage : { completion_tokens : 499, prompt_tokens : 18, total_tokens : 517, prompt_tokens_details : { cached_tokens : 0}, prompt_cache_hit_tokens : 0, prompt_cache_miss_tokens : 18}, model_name : deepseek-chat , system_fingerprint : fp_8802369eaa_prod0425fp8 , finish_reason : stop , logprobs : None} id= run--95a492b6-37f7-4e73-b5cf-12265c945c46-0
3.2 文档加载与预处理
在构建 Agent 之前,我们需要先将原始文档转化为可以检索的向量形式,具体包括:
(1)加载本地文档
LangChain 提供多种 Loader 来读取不同格式的文档。
- 读取 Markdown 文件(.md):
from langchain_community.document_loaders import TextLoader
loader = TextLoader( ./docs/智能体简介.md , encoding= utf-8 )
documents = loader.load()
- 读取整个目录下的 Markdown 文件:
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader( ./docs , glob= **/*.md , loader_cls=TextLoader, loader_kwargs={ encoding : utf-8 })
documents = loader.load()
- 读取 PDF 文件:
对于 PDF 文件,可以使用 PyPDFLoader 进行加载。它会按页读取并自动转为 Document 对象。
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader( ./docs/RAG测试.pdf )
documents = loader.load()
如果你希望将多个来源的文档合并处理,只需拼接多个 documents 列表即可:
all_documents = md_documents + pdf_documents + other_documents
(2)文档切分
为了让长文档适配向量数据库,我们需要按段落或语义块进行切分。推荐使用 RecursiveCharacterTextSplitter:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["
", "
", "。", "!", "?", ".", "!", "?"]
)
split_docs = text_splitter.split_documents(documents)
此操作会将文档拆成多个短文本块,既保留上下文连续性,又便于后续的向量化处理。
与CharacterTextSplitter的区别:
from langchain.text_splitter import CharacterTextSplitter
# 示例文本
text = "Python 是一种广泛使用的高级编程语言,具有简单易学的语法。"
# 初始化 CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size=20, # 每块最大字符数
chunk_overlap=5 # 块之间的重叠字符数
)
# 切分文本
chunks = text_splitter.split_text(text)
# 输出结果
for i, chunk in enumerate(chunks):
print(f"Chunk {i + 1}: {chunk}")
Chunk 1: Python 是一种广泛使用的高级编程
Chunk 2: 使用的高级编程语言,具有简单易学
Chunk 3: 具有简单易学的语法。
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 示例文本
text = """
Python 是一种广泛使用的高级编程语言,具有简单易学的语法。
它支持多种编程范式,包括面向对象、函数式编程和过程式编程。
"""
# 初始化 RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=50, # 每块最大字符数
chunk_overlap=10, # 块之间的重叠字符数
separators=["
", " ", ""] # 分隔符优先级
)
# 切分文本
chunks = text_splitter.split_text(text)
# 输出结果
for i, chunk in enumerate(chunks):
print(f"Chunk {i + 1}: {chunk}")
Chunk 1: Python 是一种广泛使用的高级编程语言,
Chunk 2: 具有简单易学的语法。它支持多种编程范式,
Chunk 3: 包括面向对象、函数式编程和过程式编程。
对比总结
| 特性 | CharacterTextSplitter | RecursiveCharacterTextSplitter |
|---|---|---|
| 分割方式 | 按固定字符长度切分 | 按分隔符递归切分,优先保留语义 |
| 分隔符支持 | 不支持 | 支持多级分隔符(如段落、句子、单词) |
| 适用场景 | 适合结构化文本或固定格式文本 | 适合自然语言文本,保留语义完整性 |
| 复杂性 | 简单 | 较复杂 |
| 上下文保留 | 通过 chunk_overlap 保留部分上下文 通 | 过递归分割和 chunk_overlap 保留上下文 |
| 灵活性 | 较低 | 较高 |
3.3 向量化与嵌入模型选型
我们选用了性能与体积兼顾的中文向量模型 —— BAAI/bge-small-zh-v1.5。它支持短语级语义检索,能生成可用于类似度计算的高质量文本向量。
from langchain_community.embeddings import HuggingFaceEmbeddings
# 初始化一个中文 BGE 嵌入模型,用于将文本转换为向量表明
embed_model = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5", # 使用 BAAI 提供的 bge-small-zh 中文语义嵌入模型
model_kwargs={"device": "cpu"}, # 指定运行设备为 CPU,如有 GPU 可改为 "cuda"
encode_kwargs={"normalize_embeddings": True} # 对输出的向量进行归一化,有助于类似度计算
)
- 嵌入模型(Embedding Model) 的核心功能是将自然语言文本转换为数值向量(embedding),使得我们可以基于向量做类似度检索、聚类、语义匹配等操作。在 LangChain 中,embedding model 一般用于以下两个场景:
1.文档入库(embedding + 存入向量数据库)
2.用户查询转换(embedding + 类似文档检索)
3.BGE 模型推荐在 embed_query() 之前添加查询指令(query_instruction),以获得更好的效果。
query_instruction = "为这个句子生成表明以用于检索相关文章:"
question = "人工智能是一门研究如何让计算机具有人类智能的科学"
query = query_instruction + question
vector = embed_model.embed_query(query) # 得到向量表明(用于查询)
print(vector)
- 向量数据库:使用 FAISS 存储文档向量。FAISS 是 Facebook 提供的高效类似度检索库,专门用于密集向量搜索。将待检索的文档列表通过 embed_model 编码后,使用 FAISS.from_documents() 构建向量索引。例如:
1. 将前面切分后的 split_docs 向量化,并存入 FAISS
from langchain.vectorstores import FAISS
vectorstore = FAISS.from_documents(split_docs, embed_model)
# 保存本地索引以供后续检索调用
vectorstore.save_local("faiss_index")

这样即可快速从 FAISS 中根据用户查询检索相关文档。
2. 检索器构造(Retriever)
我们通过 vectorstore.as_retriever() 构造一个语义检索器,支持基于向量类似度的文段召回:
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 2})
query = "台湾省天气状况?"
docs = retriever.invoke(query)
for i, doc in enumerate(docs, 1):
print(f"[文档 {i}]: {doc.page_content}
")
docs内容:
[Document(metadata={total_pages : 5, page : 0, page_label : 1 }, page_content= 北京市天气状况:1
上海市天气状况:2
天津市天气状况:3 ),
Document(metadata={ total_pages : 5, page : 1, page_label : 2 }, page_content= 重庆市天气状况:4
河北省天气状况:5
山西省天气状况:6
辽宁省天气状况:7 ),
Document(metadata={ total_pages : 5, page : 2, page_label : 3 }, page_content= 吉林省天气状况:8
黑龙江省天气状况:9
江苏省天气状况:10
浙江省天气状况:11 ),
Document(metadata={ total_pages : 5, page : 3, page_label : 4 }, page_content= 安徽省天气状况:12
福建省天气状况:13
江西省天气状况:14 ),
Document(metadata={ total_pages : 5, page : 3, page_label : 4 }, page_content= 山东省天气状况:15
河南省天气状况:16
湖北省天气状况:17
湖南省天气状况:18 ),
Document(metadata={ total_pages : 5, page : 4, page_label : 5 }, page_content= 广东省天气状况:19
海南省天气状况:20
四川省天气状况:21 ),
Document(metadata={ total_pages : 5, page : 4, page_label : 5 }, page_content= 贵州省天气状况:22
云南省天气状况:23
陕西省天气状况:24 ),
Document(metadata={ total_pages : 5, page : 4, page_label : 5 }, page_content= 甘肃省天气状况:25
青海省天气状况:26
内蒙古自治区天气状况:27 ),
Document(metadata={ total_pages : 5, page : 4, page_label : 5 }, page_content= 广西壮族自治区天气状况:28
西藏自治区天气状况:29
宁夏回族自治区天气状况:30 ),
Document(metadata={ total_pages : 5, page : 4, page_label : 5 }, page_content= 新疆维吾尔自治区天气状况:31
香港特别行政区天气状况:32 ),
Document(metadata={ total_pages : 5, page : 4, page_label : 5 }, page_content= 澳门特别行政区天气状况:33
台湾省天气状况:34 )]
运行后:
文档 0: 澳门特别行政区天气状况:33
台湾省天气状况:34
文档 1: 安徽省天气状况:12
福建省天气状况:13
江西省天气状况:14
文档0的类似度最高,文档1的次之
3.4 联网搜索工具
使用 DuckDuckGo 搜索工具进行实时查询。LangChain 社区提供了 DuckDuckGoSearchRun 封装,可直接调用 DuckDuckGo API。示例:
from langchain_community.tools import DuckDuckGoSearchRun
query = "台湾省天气状况?"
search_tool = DuckDuckGoSearchRun()
result = search_tool.invoke(query)
print(result)
这个工具方便集成到 Agent 中,实现“需要联网搜索”时的补充信息。
由于DuckDuckGo 不稳定,我们可以使用Serper取代:
-
在使用Google Serper API之前,需要访问serper.dev注册一个免费账户,并获取API密钥。
-
在使用API之前,需要设置环境变量:
os.environ["SERPER_API_KEY"] = "your_serper_api_key"
from langchain_community.utilities import GoogleSerperAPIWrapper
# 初始化搜索实例
search = GoogleSerperAPIWrapper()
# 执行搜索
result = search.results("广东省天气状况?")
print(result)
("搜索结果: { searchParameters : { q : 广东省天气状况? , gl : us , hl : en , type : "
" search , num : 10, engine : google }, organic : [{ title : 广东 - "
"中国气象局-天气预报-城市预报 , link : https://weather.cma.cn/web/weather/59287.html , "
" snippet : 时间, 05:00, 08:00, 11:00, 14:00, 17:00, 20:00, 23:00, 02:00. 天气. "
"气温, 18.3℃, 17.2℃, 27.8℃, 25.5℃, 23.4℃, 22.7℃, 19.8℃, 17.5℃. , position : "
"1}, { title : 广东天气预报- 广东 , link : https://gd.weather.com.cn/index.shtml , "
" snippet : 天气排行 ; 最高气温. 遂溪, 29.0°C ; 最低气温. 连州, 12.7°C ; 昼夜温差. 大埔, 13.7°C. , "
" sitelinks : [{ title : 广州 , link : "
" https://gd.weather.com.cn/guangzhou/index.shtml }, { title : 深圳 , link : "
" https://gd.weather.com.cn/shenzhen/index.shtml }, { title : 天气实况 , link : "
" https://gd.weather.com.cn/tqsk/index.shtml }, { title : 东莞 , link : "
" https://gd.weather.com.cn/dongguan/index.shtml }], position : 2}, "
"{ title : 天气实况与预报 - 深圳市气象局(台) , link : "
" https://weather.sz.gov.cn/qixiangfuwu/yubaofuwu/index.html , snippet : "
" 深圳市气象局门户网站为您提供权威、及时、准确的深圳天气预警、天气预报、天气实况、台风路径、深圳气候等信息服务,为深圳及其周边城市的生产生活提供全面可靠的气象 "
"... , position : 3}, { title : 广州-天气预报 , link : "
" https://www.nmc.cn/publish/forecast/AGD/guangzhou.html , snippet : 11:00 "
· 12.1℃. 7.9m/s · 1022.3hPa. 49.5% ; 14:00 · 14.8℃. 7.8m/s · 1019hPa. 51.9%
"; 17:00 · 13.4℃. 7.4m/s · 1017.9hPa. 62.8%. , position : 4}, { title : "
" 广东省气象局 , link : http://gd.cma.gov.cn/ , snippet : 首页 · 政务公开 · 政务服务 · "
"天气预报 · 台风路径 · 地市气象; 搜索. 快速找到您想要的. 气象预警. 暂无预警信息! 周末. 广东省气象局局史馆正式开馆. , "
" sitelinks : [{ title : 天气预报 , link : http://gd.cma.gov.cn/qxfw/tqyb/ }, "
"{ title : 机构与职能 , link : http://gd.cma.gov.cn/zfxxgk/zwgk/jgyzn/ }, "
"{ title : 查看更多 , link : "
" http://gd.cma.gov.cn/zwgk/zwyw/gzdt/mo_index_12342.html }, { title : "
" 征集调查 , link : http://gd.cma.gov.cn/gzhd/yjzj/mo_index_12342.html }], "
" position : 5}, { title : 粵.港.澳大灣區天氣網站 , link : "
" https://www.gbaweather.net/ , snippet : 廣東省氣象局, 香港天文台, 澳門地球物理氣象局. 搜尋地點. "
"搜尋地點. X ... 天氣警告. 天氣預報. 天氣預報. 氣溫. 氣溫. 相對濕度. 相對濕度. 風. 風. 一小時雨量. 一 ... , "
" position : 6}, { title : 廣州, 廣東省, 中國三日天氣預報 - AccuWeather , link : "
" https://www.accuweather.com/zh/cn/guangzhou/102255/weather-forecast/102255 , "
" snippet : 每日預報 ; 今天. 11/17. 87° 58° · 8% ; 周二. 11/18. 60° 52° · 25% ; 周三. "
"11/19. 63° 54° · 2%. , position : 7}, { title : 廣東省主要城市天氣預報 , link : "
" https://www.hko.gov.hk/textonly/v2/other/wfgc.htm , snippet : "
" 廣東省主要城市天氣預報. 香港天文台於2025 年11 月16 日18 時30 分發出之天氣報告 "
"(有效時間:11月16日下午8時到11月17日下午8時) 最低溫度最高溫度城市(攝氏度) (攝氏度) ... , position : 8}, "
"{ title : 广东天气预报 , link : "
" https://www.weather.com.cn/html/province/guangdong.shtml , snippet : 天气排行 "
"; 最高气温. 遂溪, 29.0°C ; 最低气温. 连州, 12.7°C ; 昼夜温差. 大埔, 13.7°C. , position : 9}, "
"{ title : 广州天气-广州市气象台,tqyb , link : http://www.tqyb.com.cn/ , snippet : "
" 七天精细化预报 ; 最高气温[南沙区]null:24.8℃. 最低气温[从化区]大岭山林场:15.7℃. 站点气温分布(℃) ; "
"最大雨量[黄埔区]湖街综合保障中心:0mm. 最小雨量[黄埔区]湖街综合 ... , sitelinks : [{ title : 天气雷达回波 , "
" link : http://www.tqyb.com.cn/gz/weatherLive/radar/ }, { title : 天气预警 , "
" link : http://www.tqyb.com.cn/gz/weatherAlarm/otherCity/ }, { title : "
" 广州观测实况 , link : http://www.tqyb.com.cn/gz/weatherLive/distribution/ }, "
"{ title : 天气实况 , link : http://www.tqyb.com.cn/gz/weatherLive/tqgc/ }], "
" position : 10}], relatedSearches : [{ query : 广州天气预报15天 }, { query : "
" 广东实时天气 }, { query : 广州天气预报20天 }, { query : 廣東天氣10天 }, { query : "
" 广东广州天气 }, { query : 广州天气预报40天 }, { query : 广东深圳天气 }, { query : "
" 广州天气预报7天 }], credits : 1}")
3.5 工具系统设计
所有工具统一封装为 Tool 对象,包含名称、执行函数和描述。例如,我们可以准备两个工具:网络搜索 和 向量检索。
from langchain.agents import Tool
tools = [
Tool(
name="Search",
func=lambda q: GoogleSerperAPIWrapper().results(q),
description="在互联网上搜索答案"
),
Tool(
name="Lookup",
func=lambda q: "
".join([doc.page_content for doc in retriever.invoke(q)]),
description="从本地向量数据库中检索相关文档"
),
# 可扩展其他工具
]
这样 Agent 在对话过程中如果决定“搜索网页”就会调用第一个工具,如果需要“查看知识库”则调用第二个。
四、代码组织与协同方式
按照 LangChain 组件化设计,我们将主要功能模块划分为不同文件或类以便维护:
Embedding 模块:
负责加载 HuggingFaceBgeEmbeddings 模型并构建 FAISS 数据库。示例代码如上,将用于后续检索。
Tool 模块:
定义各种工具。可以把搜索和检索函数封装在此,例如前述的 Search、Retrieve。
Prompt 模板:
使用 PromptTemplate 定义 ReAct 提示格式,插入工具列表和对话历史等变量,例如:
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template(
"你是一个智能问答助手。你可以使用以下工具:
{tools}
"
"请根据用户问题和工具结果给出答案。
"
"用户问题: {input}
"
"{agent_scratchpad}"
)
记忆模块:
通过 ConversationBufferMemory 保存对话记录。
ConversationBufferMemory 介绍:
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
# 初始化 ConversationBufferMemory
memory = ConversationBufferMemory()
# 创建对话链
conversation = ConversationChain(
llm=llm,
memory=memory,
verbose=True
)
# 开始对话
response1 = conversation.predict(input="你好!你是谁?")
print(response1)
response2 = conversation.predict(input="你能做什么?")
print(response2)
response3 = conversation.predict(input="你还记得我刚才说了什么吗?")
print(response3)
输出:
Human: 你好!你是谁?
AI: 你好!我是DeepSeek,由深度求索公司创造的AI助手!😊
Human: 你能做什么?
AI: 我能做的事情可多了!让我详细为你介绍一下:
...
Human: 你还记得我刚才说了什么吗?
AI:
> Finished chain.
当然记得!在我们当前的对话中,你刚才问的是:“**你还记得我刚才说了什么吗?**”
Agent 构建:
使用 LangChain 的 ReAct Agent 构造器创建可调用的 Agent:
from langchain.agents import initialize_agent
from langchain.agents.agent_types import AgentType
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history")
agent_executor = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.REACT_DOCSTORE, # 或 AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION
memory=memory,
verbose=True,
handle_parsing_errors=True
)
这样得到的 agent_executor.invoke({“input”: 用户问题}) 会返回模型对话输出,其中模型可以在生成过程中调用 Search 或 Lookup 等工具,并将返回结果纳入思考。
五、FastAPI 封装与示例
完成以上组件后,用 FastAPI 构建 API 服务接口:
from fastapi import FastAPI, Request
app = FastAPI()
@app.post("/chat")
async def chat_api(request: Request):
data = await request.json()
query = data.get("query", "")
# 调用 AgentExecutor 得到回答
result = agent_executor.invoke({"input": query})
answer = result["output"]
return {"answer": answer}
启动:
os.environ[ HF_ENDPOINT ] = https://hf-mirror.com
# 安装依赖
def install_requirements():
try:
import fastapi, uvicorn, langchain
print("✅ 依赖已安装")
except ImportError:
print("📦 安装依赖中...")
subprocess.check_call([sys.executable, "-m", "pip", "install",
"fastapi>=0.104.0",
"uvicorn[standard]>=0.24.0",
"langchain>=0.1.0",
"langchain-community>=0.0.10",
"langsmith>=0.0.70",
"pydantic>=2.0.0",
"python-multipart>=0.0.6"])
print("✅ 依赖安装完成")
if __name__ == "__main__":
install_requirements()
# 启动服务器
print("🚀 启动服务器...")
import uvicorn
uvicorn.run("app.main:app", host="0.0.0.0", port=8000, reload=True)
启动服务后,客户端即可通过 POST 请求访问,例如:
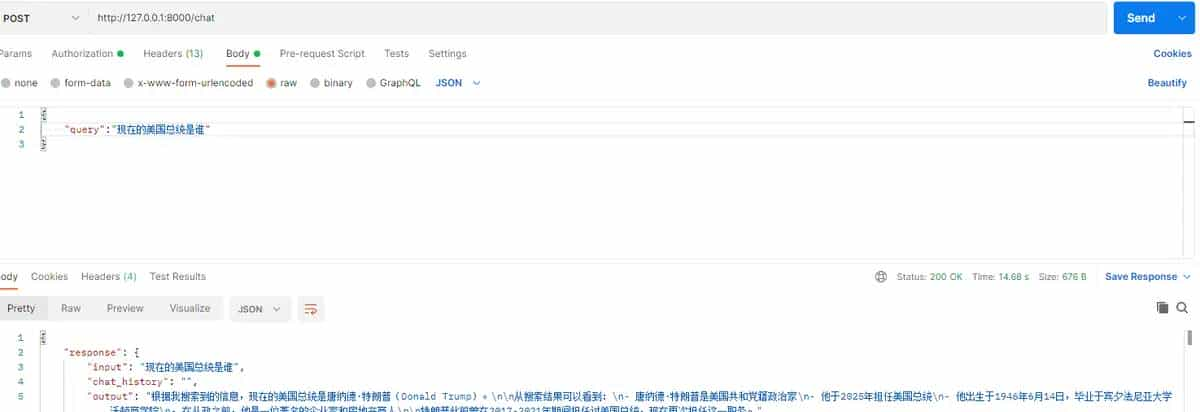
上述请求返回的 JSON 会包含智能体的回答。整个服务基于组件化设计,后续可替换模型、增加工具或更换向量数据库,而不影响主逻辑。
六、推荐阅读与项目结构示例
推荐阅读:深入了解 LangChain 文档,如 ReAct Agent 和工具调用机制,探索 LangGraph 新架构;学习 DeepSeek 和 BGE 模型的官方资料。
项目目录及代码详情(以模块化方式组织代码):
ai_agent_demo/
├── agents/
│ └── base_agent.py # 构建智能体
├── tools/
│ ├── search_tool.py # 搜索工具(DuckDuckGo)
│ ├── doc_reader.py # 文档读取工具
│ └── vectorstore.py # 构建向量数据库
├── multimodal/
│ └── image_captioning.py # 图像识别/图文描述工具
├── memory/
│ └── memory.py # 智能体记忆模块(新增)
├── app/
│ └── main.py # FastAPI 接口入口
├── sample.pdf # 示例文档
├── sample.jpg # 示例图像
├── main.py # 命令行入口
└── requirements.txt # 依赖管理
命令行交互入口(main.py)
from agents.base_agent import build_agent
def run():
agent = build_agent()
print("🔧 智能体已启动... 输入 exit 退出")
while True:
user_input = input("
🧑 用户: ")
if user_input.lower() in {"exit", "quit"}:
print("👋 再见!")
break
response = agent.invoke(user_input)
print(f"
🤖 Agent: {response}")
if __name__ == "__main__":
run()
FastAPI 部署接口(app/main.py)
# -*- coding: utf-8 -*-
from fastapi import FastAPI, UploadFile, File
from pydantic import BaseModel
from agents.base_agent import build_agent
app = FastAPI()
agent = build_agent()
class Query(BaseModel):
query: str
@app.post("/chat")
async def chat(q: Query):
response = agent.invoke(q.query)
return {"response": response}
@app.post("/upload")
async def upload_pdf(file: UploadFile = File(...)):
content = await file.read()
path = f"temp_{file.filename}"
with open(path, "wb") as f:
f.write(content)
response = agent.invoke(f"请阅读 {path} 文件内容")
return {"response": response}
七、 总结:
本文展示了如何将 RAG、工具调用、多轮记忆等技术融合到一个 LangChain Agent 中,结合 DeepSeek 聊天模型和本地向量数据库,实现实用的问答系统。该架构具有良好可扩展性,可根据需求添加更多工具或采用更强劲的模型,以满足复杂的应用场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











