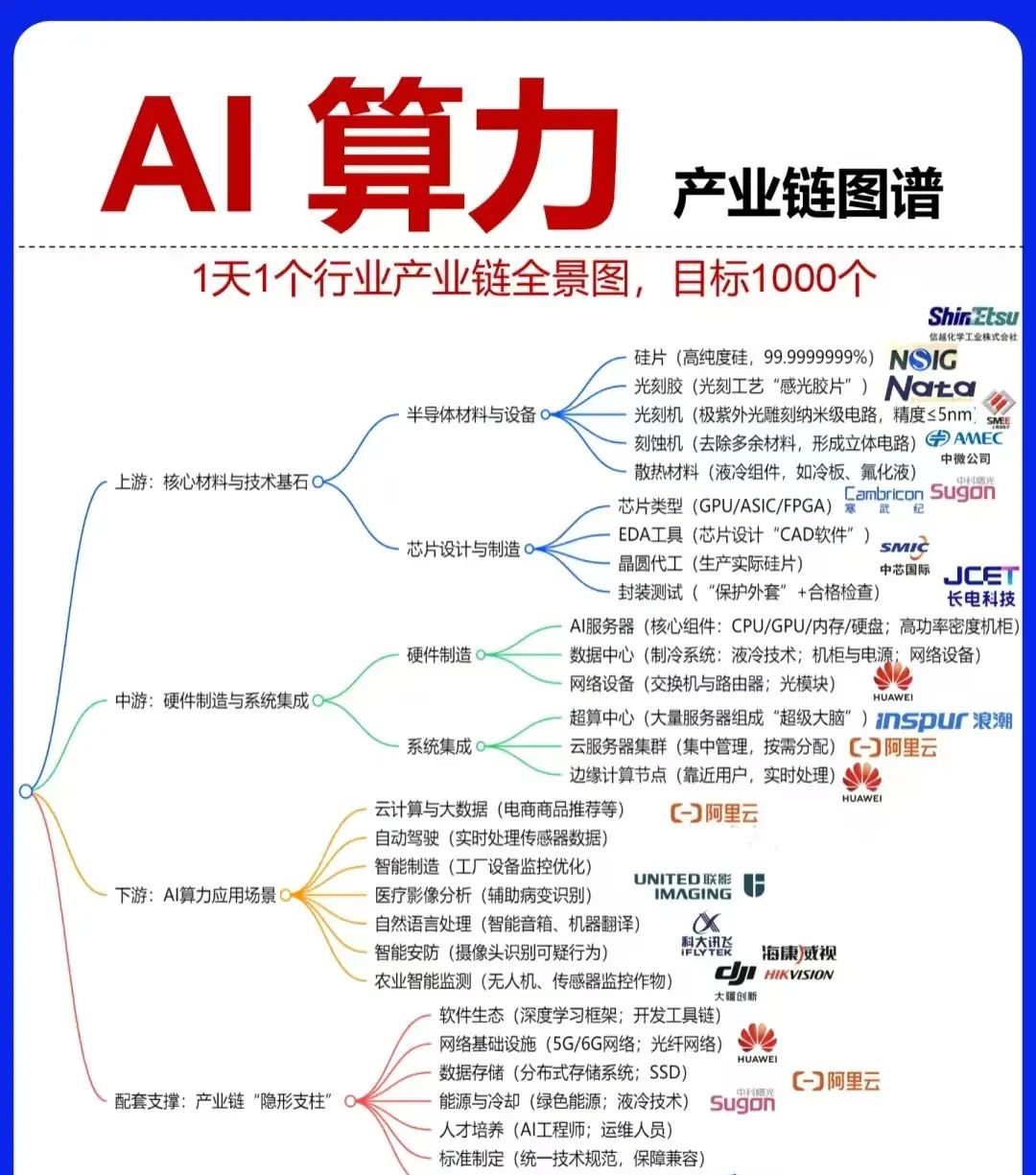
利用word2vec预训练的词向量进行文本分类
利用word2vec预训练的词向量进行文本分类
读取词向量文件
import gensim
from gensim import word2vec
model= gensim.models.KeyedVectors.load_word2vec_format( ./data/.vector_cache/word2vec_779845.bin ,binary=True)# 这是读取二进制的词向量文件, 不可以再进行训练
#model = word2vec.Word2Vec(path)
将词向量变作权重tensor
weights = torch.FloatTensor(model.vectors)
weights = torch.FloatTensor(model.wv.vectors)
分词函数
def tokenizer(sentence):
sentence = re,sub( [^u4e00-u9fa5aA-Za-z0-9] , )
return [word for word in jieba.lcut(sentence)]
定义Field,声明如何处理数据
text = data.Feild(sequential = True, tokenize = tokenizer, fix_length=50)
label = data.Feild(sequential = False, use_vocab = False)
划分数据集
train, val = data.TabulardataSet.splits(path= ./ ,
tarin = train.csv , validation=
dev.csv , format = csv ,
Feild = [( text , text), ( label , label)])
建立vocab
这里不需要指明词向量的位置和名称了,由于要用自己训练的词向量权重直接加进去
text.build_vocab(train, max_size = 100000, min_freq = 10)
label.build_voacb(train)
构建迭代器
train_iter, val_iter = data.Iterator.split((train, val),sort_key = lambda x:
len(x.text), batch_size = (1000,100))
模型的构建
class Net(nn.Module):
def __init__(self, embedding_size, hidden_size):
super(Net, self).__init__()
self.embedding = nn.Embedding(len(text.vocab), 100)
self.embedding.weight = torch.nn.Parameters(weights)
self.embedding.required_grad = False
self.encode = nn.LSTM(embedding_size, hidden_size, bi_direction, num_layer)
self.decode = nn.Linear(4*hidden_size, 2)
def forward(self, x):
x = self.embedding(x)# num_steps, batch_size, embedding_size
y,_ = self.encode(x)# num_steos, batch_size, 2*hidden_size
y = self.decode(torch.cat((y[-1], y[0]), -1)) # batch_size, output_size
return y
<font color=#0099ff size=3 face=”黑体”>color=#0099ff size=72 face=”黑体”</font>
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











