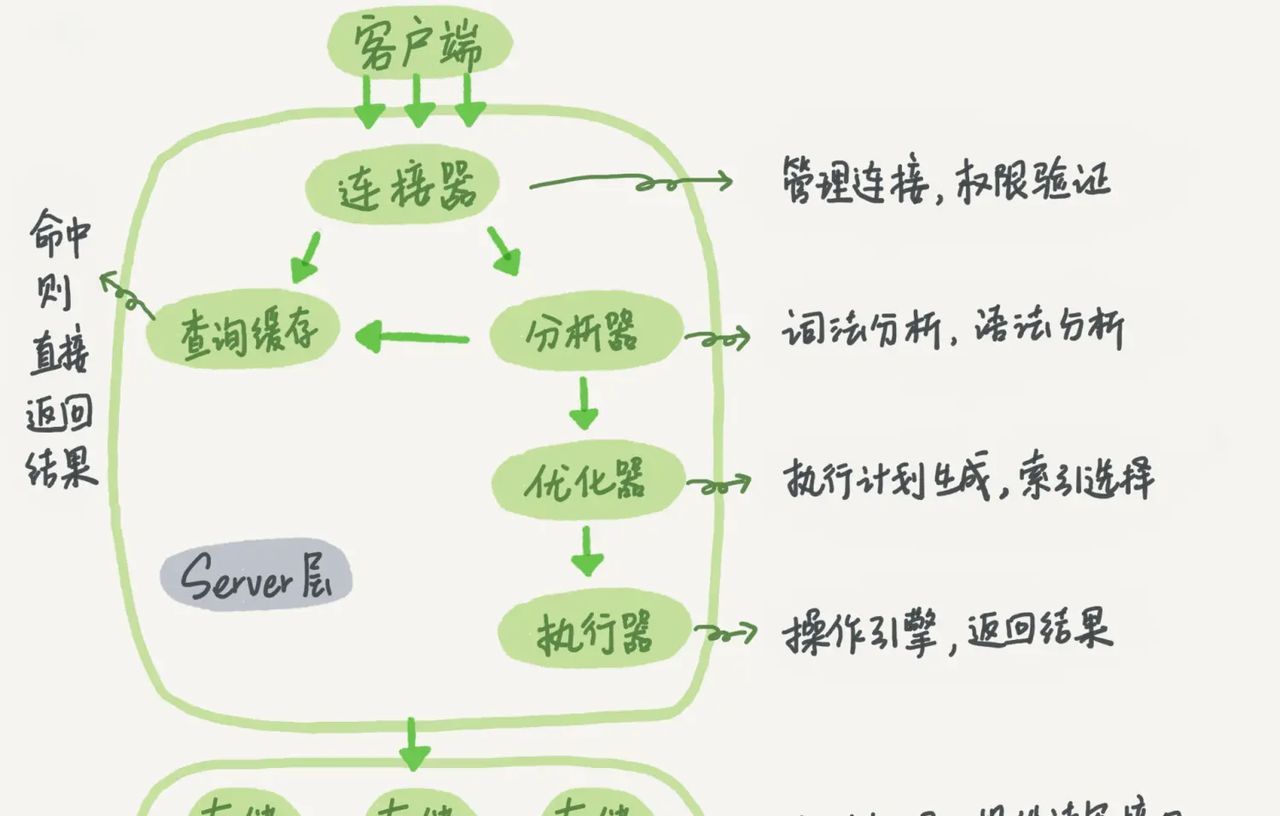
背景
看了许多dify的资料和视频,但是动起手来之后,才发现有许多知识自己理解的不是很透彻,所以需要实现许多的案例来加深对知识的理解。第一个案例就是对话框输入sql,然后通过两种工作流节点:代码执行和http请求,测试dify的工作流节点+python使用flash搭建基本服务器的过程。
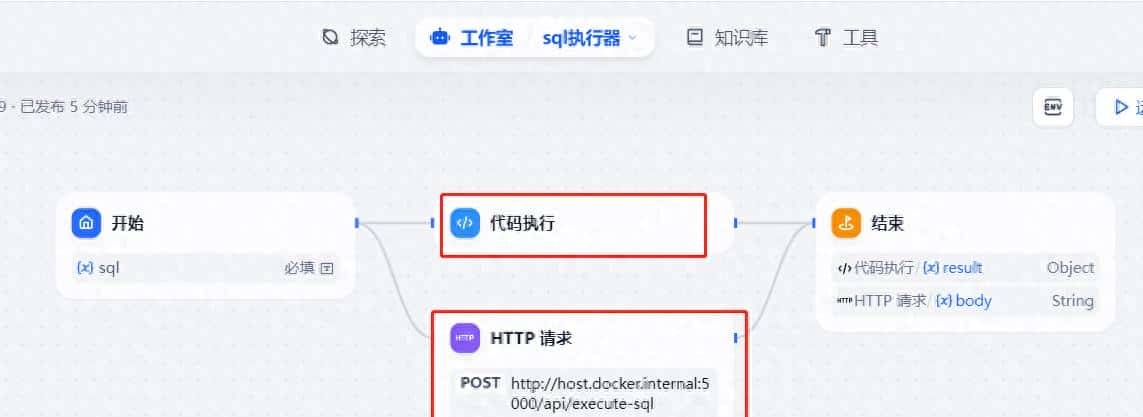
最终效果
python搭建后台服务
基本代码如下,强烈提议大家使用ai工具编写,cursor或者trae,即使python许多工具不会,也能快速搭建服务,新建server.py:
from flask import Flask, request, jsonify
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import text
# 创建Flask应用
app = Flask(__name__)
# 数据库配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:123456@localhost:3306/ry'
# 初始化数据库
db = SQLAlchemy(app)
# 自定义接口
@app.route('/api/execute-sql', methods=['POST'])
def execute_sql():
try:
data = request.get_json()
sql = data.get('sql')
if not sql:
return jsonify({
'success': False,
'message': 'SQL语句不能为空'
}), 400
# 执行SQL查询
result = db.session.execute(text(sql))
# 获取结果
if result.returns_rows:
columns = result.keys()
rows = [dict(zip(columns, row)) for row in result.fetchall()]
return jsonify({
'success': True,
'data': rows,
'message': '查询执行成功'
})
else:
return jsonify({
'success': True,
'message': 'SQL执行成功'
})
except Exception as e:
return jsonify({
'success': False,
'message': f'执行SQL时发生错误: {str(e)}'
}), 500
if __name__ == '__main__':
# 启动服务
app.run(debug=True, host='0.0.0.0', port=5000) 启动服务:python server.py,出现如下信息,启动成功,端口是5000
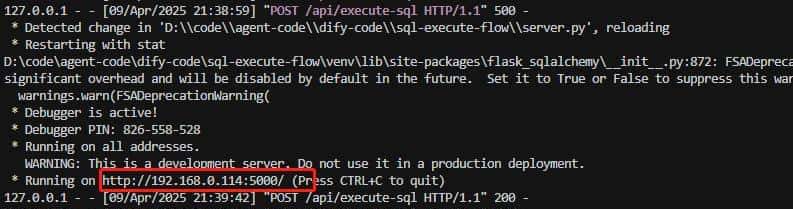
启动服务成功
代码执行节点
最后查询的节点,必定要使用result封装,否则会报错result没有返回值,我在这里踩了个坑
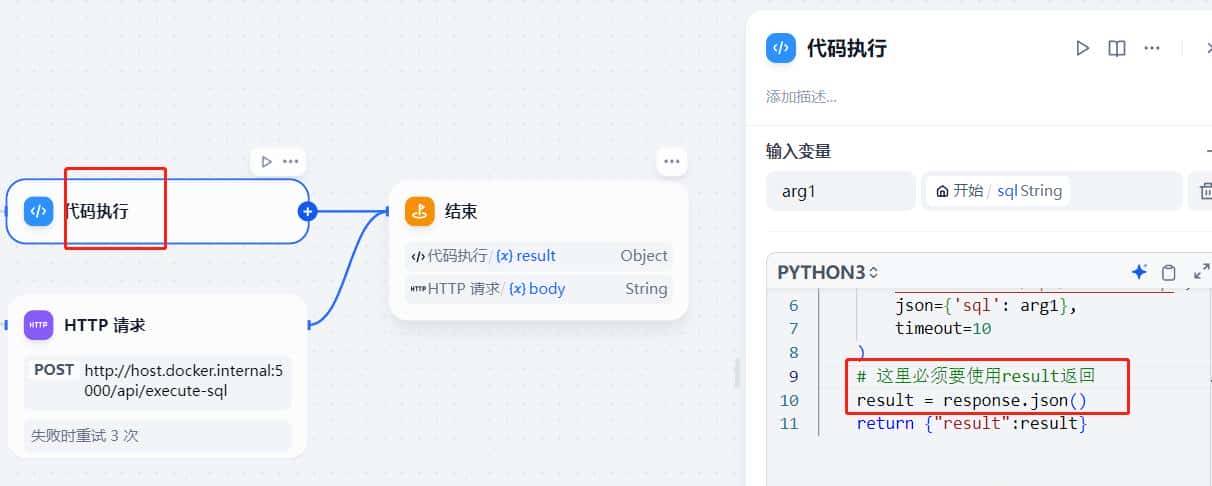
官网对输出格式做了限定,所以必定要按照固定的格式返回
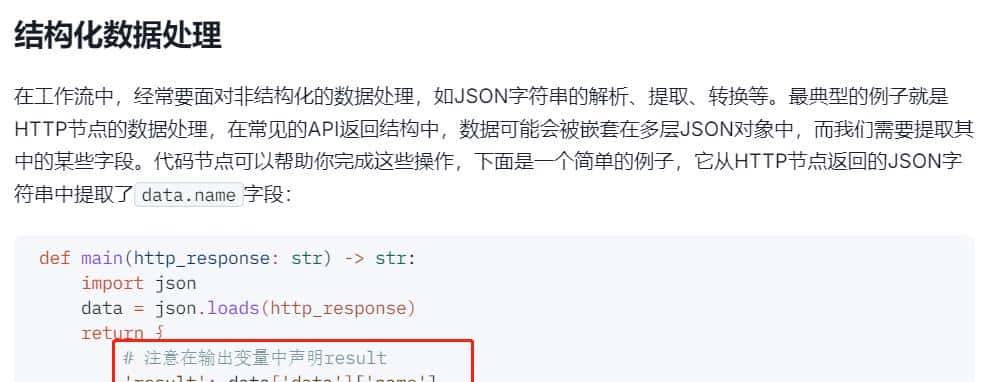
执行代码:就是发起http请求,然后返回结果,可以参考下,我的代码是经过测试通过的,可以直接使用。注意这里的host.docker.internal地址,不要写localhost,由于dify是在docker容器里面启动的,而docker容器无法直接使用localhost访问宿主机。
def main(arg1: str) -> str:
import requests
# 设置超时时间为 10 秒
response = requests.post(
f'http://host.docker.internal:5000/api/execute-sql',
json={'sql': arg1},
timeout=10
)
# 这里必须要使用result返回
result = response.json()
return {"result":result}http节点配置
这里需要注意的就是json参数的拼装,dify不会直接给变量加上双引号,需要我们显示手动加上
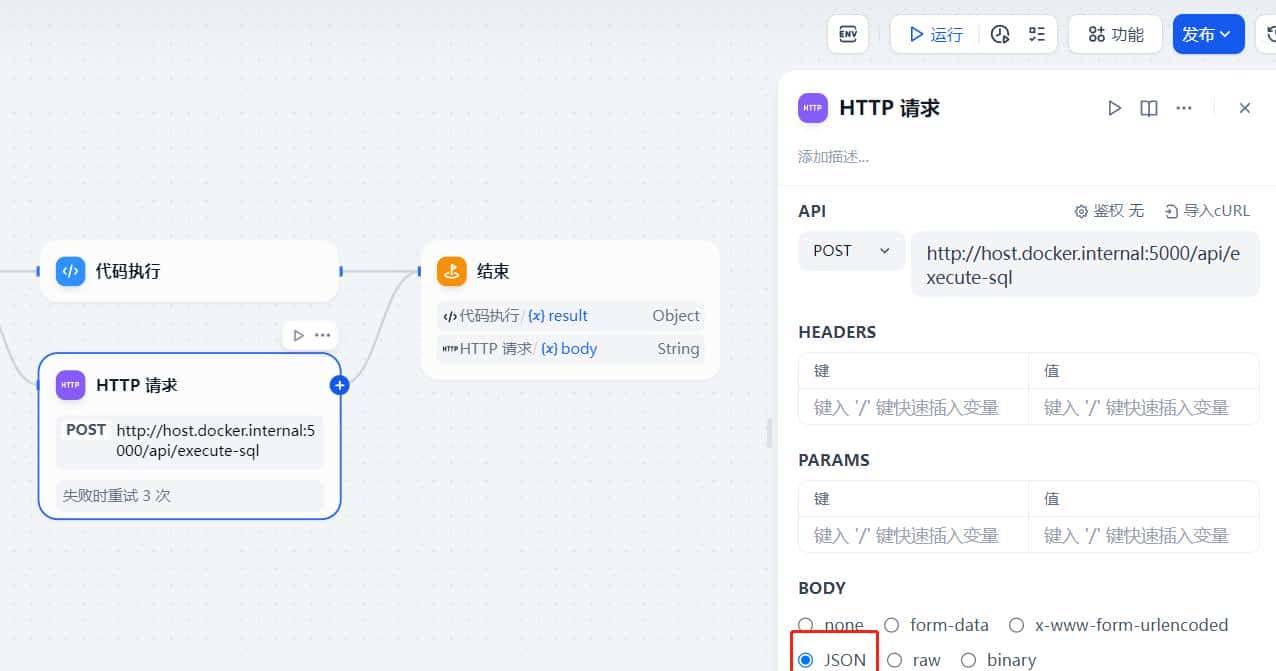
注意变量添加引号
执行结果
输入sql,点击开始运行
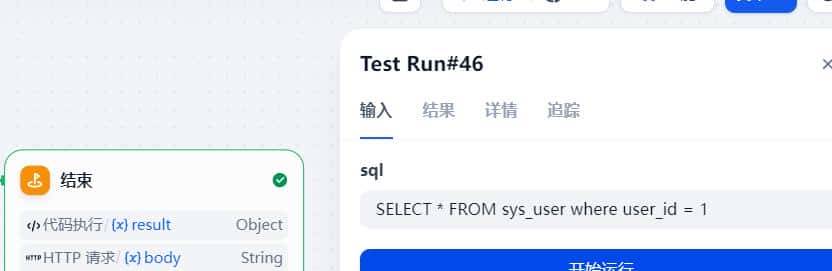
执行sql
查询结果
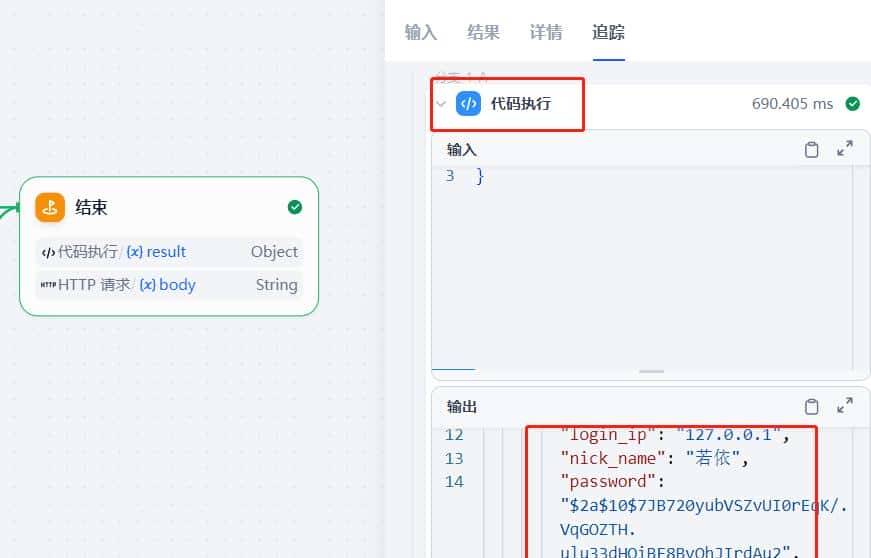
正确查询到数据
© 版权声明
文章版权归作者所有,未经允许请勿转载。








![西游H5圆美商业服务端游戏源码[教程+支持内充+GM后台]](https://img.dunling.com/smtb/20230825/64dd930b9af14cb7a041010bbcca032f.jpg)





自己写sql,用这玩意有什么用?
这是初级的,更进一步是让大模型自己读取表结构,自己生成SQL执行,自己获取数据,这样应用场景就比较多了!
有用,有用。本地部署大模型,dify,打通企业数据库,查询精确数据。
用vanna做自然语言转SQL执行
自己写sql?那你为啥要用这个?
这是初步,后面有自动生成SQL的案例
干货满满超棒呀
优秀💪
收藏了,感谢分享