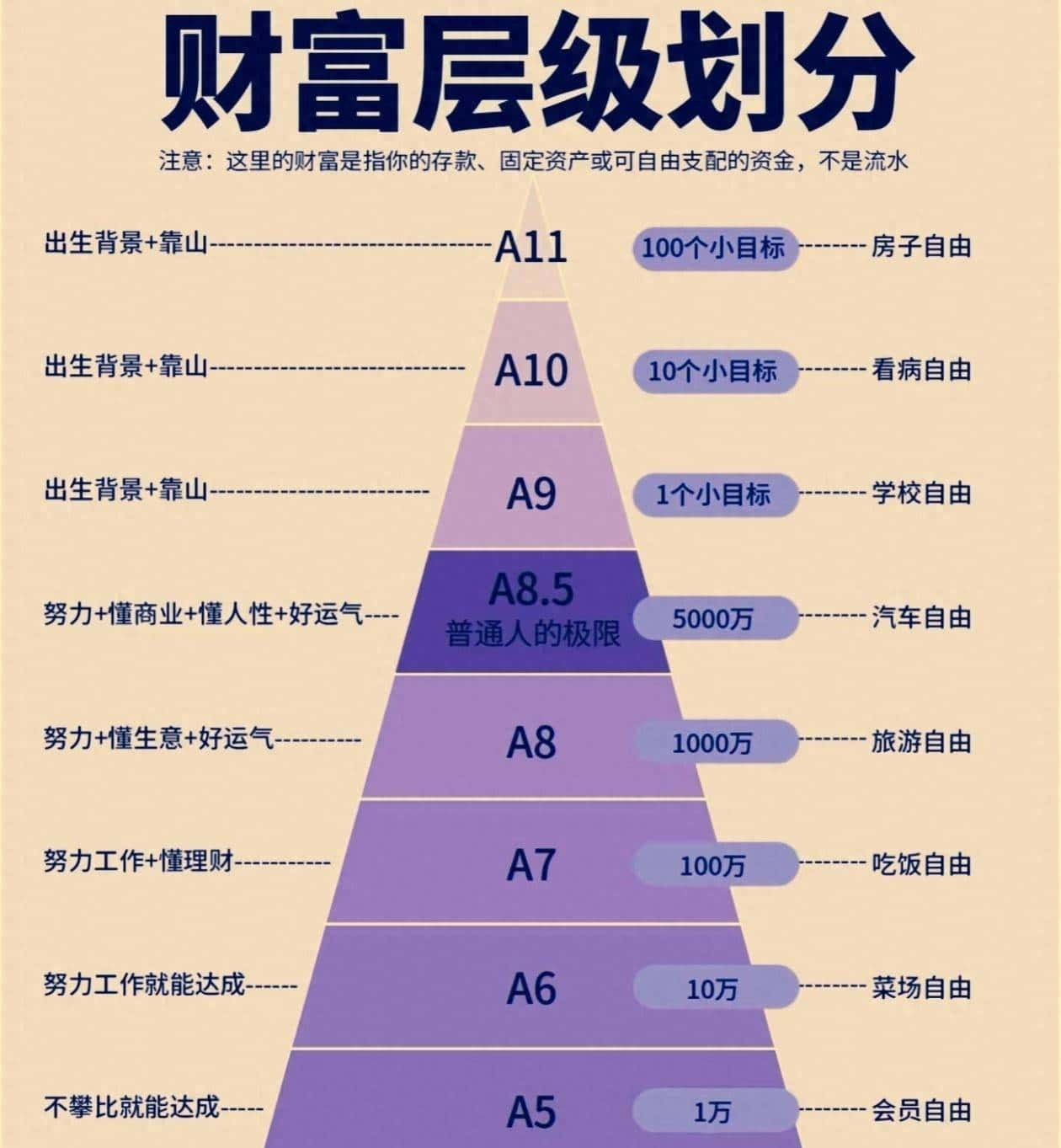
系统已经上线,能把复杂的多角色任务拆成好几步,按流程跑完,而且每一步都有可回放的记录。出现问题能追到哪个 Agent、哪个工具和哪次调用出错。运行结果不像刚拼了个 prompt 那样靠运气,能看到每个环节的耗时、重试次数和成本,异常也能触发告警。
回头看看这是怎么做到的。中间做了不少工程工作,把原来单次调用的思路扩展成完整的工作流系统。最核心的是把「模型、外部工具、多个智能体和多步流程」当成一个整体来管理。系统里把每次对话、每次工具调用都当成可追踪的事件,能够可视化地回放,方便排查和审计。为了让不同角色协作顺利,我们给每个 Agent 定义了职责、输入输出和能用的工具集合,Agent 间的数据流明确,权限也被限制住,避免相互越界。
具体到跑起来的流程,有个简化的 Demo,当时就用来验证基本思路。用户提交一个问题,先由“研究员 Agent”去把背景资料收集整理,列出要点和可能的证据链;接着“写手 Agent”拿到研究结果,按照结构化模板写出说明文档。系统里还设了环境变量来控制模型选择、API Key、外部检索的配置等,方便在不同环境下切换。代码上参考了 LangGraph 的官方文档,做了简化处理,实际工程里根据需求扩展。这个 Demo 本身很朴素,但能体现几个必须有的点:流程编排、事件追踪、角色分工、可回放的执行记录。
为什么不能再靠单条 prompt?一开始大家都是这么玩的:一句 prompt,最多加个 RAG 检索,能解决不少场景。但一上生产,你就会遇到好几类问题。列如任务跨多步、需要不同角色合作时,单次调用没法拆清楚责任;又列如要接入公司内部的工具或数据库,模型直接调用外部系统缺乏安全和审计;还有并发和稳定性问题,当量级上来,模型调用的失败、重试和超时需要系统化处理,不然就乱套。最容易被忽略的是可观测性:没有可追溯的调用记录,就不知道谁在什么时候做了什么,排错只能靠猜。
这些痛点就催生了目前的 Workflow / Agentic 框架。它们不是把模型换成更机智的 prompt,而是把整套运行时场景建模起来:把 LLM、工具、Agent、多步骤流程统一成可视化的图谱,支持回放、监控和审计。针对不同团队和栈,有几类典型适配场景:一是已经用 LangChain 的团队,想要对复杂的多步骤、多 Agent 流程做更细的控制;二是偏好 Python 的工程组,希望把零散脚本升级成带 UI、控制台和监控的 Agent 系统;三是企业级环境,列如 Azure 平台、混合 .NET / Python 技术栈,需要深度集成和合规支持;四是做内容生产、调研或写代码等场景,涉及多角色协同,想快速把多 Agent 原型落地验证。
在工程实践里,有一些常见做法几乎是标配。每个步骤都会产生日志和结构化事件,存成可回放的 trace;系统会定义超时和重试策略,避免一个慢调用拖垮整个流程;对外部工具调用做沙箱化和权限管理,防止越权访问;模型版本和参数都要可配置,便于回滚和比对结果;成本和延迟要有监控,异常时能自动降级或限流。为了方便排查,还会把输入输出、工具调用的请求与响应等原始数据保留一段时间,支持 Debug 和合规审计。
多 Agent、长工作流的场景下,最致命的就是缺乏 trace。没有完整的调用链和状态记录,排错就像闭着眼做手术。发生问题时,团队需要知道是哪一步失败、哪个 Agent 的输出带来下游错误、是外部服务超时还是模型回答不稳定。Trace 协助把这类问题还原成可复现的测试用例,从而改善模型指令或工具接口。
实现这些功能并不只靠框架本身,工程上也有不少细节要做。要设计一套清晰的 Agent 接口,包括输入输出格式、失败时的回退逻辑和错误等级;要做好状态存储,能在长流程中断后继续;要把敏感数据打标签并在日志中脱敏;要有模拟环境能做离线回放,避免在生产上频繁跑坏数据;还要有监控面板展示关键指标:成功率、平均响应时长、成本消耗、故障率等。对接企业身份系统和审计要求,也是常见工作项。
回到我们落地的例子,做法很直接也很实际。先在小范围内把常见任务抽象成几个 Agent:检索、分类、写作、校验。给每个 Agent 复盘失败场景,设计边界条件和补救措施。再把这些 Agent 用工作流编排器串起来,做到每次执行都有 ID、时间戳和执行记录。外部工具调用都走统一适配层,适配层负责超时重试、限流和安全校验。最后接入监控系统,设置告警阈值,确保出现异常时有人能及时介入。
这个过程中也碰到不少现实问题。列如怎么衡量 Agent 输出的质量?我们用结构化指标加人工抽检:对关键节点设定校验规则,规则不过关就返回到上一步或触发人工审查。又列如多团队协作时,接口标准化很重大,早期没有统一协议,大家各自扩展,最后很难合并。还有成本控制,如果没有按调用追踪,很容易由于模型调用频繁而超预算,所以对低风险步骤采用小模型或规则引擎,对高价值输出才用大模型。
要让系统在不同技术栈上顺利运行,必须思考集成方案。遇到 Azure、.NET 与 Python 混合的企业环境,提议把核心编排和可视化放在平台上,提供多语言 SDK 与适配层,让各端通过标准 API 对接。这样即便后端服务是 .NET,数据管道是 Python 写的,也能在统一的控制台里看到端到端的执行情况。对于已经用 LangChain 的团队,可以把现有逻辑迁移到更有监控的框架里,保留熟悉的接口,同时补充可观测性和治理能力。Python 团队如果想快速从脚本过渡到有 UI、控制台和监控的系统,优先搭好运行时和日志体系,再慢慢把界面和权限做上去。
把单次 LLM 调用比作一个机智的实习生,这话有道理。但真正能稳定产出的系统,不是单个更机智的实习生,而是给这个实习生配一群同事、一套流程、一个考核和监控机制。具体到产品设计上,就是把「怎么调用模型」的关注点扩展为「怎么保证模型在组织里的可控、可审计、可回放和可监控」。一句更机智的 prompt 改变不了组织协作、合规和工程稳定性的问题;要解决这些,就得把工作流、Agent、工具接入、监控与治理都当成工程一部分来做。
当时这个项目的起点实则很普通。团队一开始也只是把大模型当作一个外呼工具,写几句 prompt,顺手加个检索。能跑通原型就先行推进。等到流量上来、用例复杂、合规要求出现,问题逐个冒出来。那时候才意识到,不是把 prompt 再打磨几个回合就能解决的东西,必须搭一套能把整个执行过程管理起来的系统。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...