
10个Python宝藏库,让你的机器学习工作流真正可控

引言:从AI“战场”到有序系统——告别数据集与实验的噩梦
在人工智能(AI)项目的“战场”前线摸爬滚打,经历过无数的数据集混乱、实验组合爆炸(combinatorics)、模型在训练中途的崩溃,以及重现性(reproducibility)的噩梦。这些混乱不仅仅是技术难题,更是吞噬时间和精力的效率杀手。
在这一过程中,我逐步积累了一个至关重大的“工具箱”,里面的库不仅仅是提供“协助”那么简单——它们是能够组织整个AI工作流的骨架。它们不是华而不实的工具(fluff tools),而是真正的脚手架,让那些机智的想法能够在真实的代码中存活下来,最终形成可维护的系统。
本文将深入介绍10个隐秘但至关重大(hidden-but-essential)的Python库,它们是将混乱的AI项目转化为可维护系统的关键。它们是实现专业化、工程化AI开发不可或缺的利器。
第一大支柱:数据与模型资产的版本化与可重现性
1. DVC (Data Version Control):像管理代码一样管理数据、模型和流水线
核心价值:将数据和模型视为一等公民(first-class)的版本化资产
为什么DVC如此重大?由于它彻底改变了我们对AI项目资产的管理方式。通过DVC,你可以将数据集(datasets)、模型检查点(model checkpoints),甚至数据预处理步骤(preprocessing steps)都视为一等公民的版本化工件(versioned artifacts)。
这意味着,你的AI工作将真正实现可重现性。当模型表现出现问题时,你可以清晰地回溯到任何一个历史版本的数据集、模型或流水线配置。
️ 应用场景与功能解析
DVC的核心命令简单而强劲:
dvc init
dvc add data/raw_images
git commit -m "Add data via DVC"- ◉dvc init: 初始化DVC,为项目搭建起数据版本控制的基础。
- ◉dvc add data/raw_images: 这行代码指示DVC开始跟踪 data/raw_images 这个数据集。请注意,DVC一般不会将数据文件本身放入Git仓库,而是放入一个外部存储(如S3、Google Drive等)或本地缓存,Git只存储一个小的元数据文件,从而实现对大文件的版本控制。
- ◉git commit: 随后,用户像往常一样使用Git提交,但这次提交中包含了DVC跟踪的数据元信息。
深度洞察:流水线的自动化重构
DVC的强劲之处远不止于数据版本化。通过 dvc repro 命令,你可以自动重建流水线(rebuild pipelines automatically)。这意味着从原始数据到最终模型的所有步骤,都可以根据定义好的依赖关系一键重现。
作者曾提到一个真实的案例:通过使用DVC的检查点(checkpoints),他成功地逆转(reversed)了一个长达六个月的模型漂移(model drift)。这充分证明了DVC在长期项目维护和问题回溯方面的无可替代性。
第二大支柱:实验过程的轻量级跟踪与可视化
2. aim:轻量级实验跟踪,提供实时、开箱即用的仪表板
核心价值:告别臃肿,追求极简、快速、开放的实验管理
在AI项目中,实验跟踪是必不可少的,但许多ML跟踪系统往往过于臃肿(bloated)。Aim提供了一个完美的替代方案:它是一款轻量级(minimal)、开放(open)、且**快速(fast)**的实验跟踪系统。
它最引人注目的特点是提供了**美观的UI(beautiful UIs)以及开箱即用的指标分组(metric grouping out of the box)**功能。这让实验结果的比较和分析变得直观和高效。
️ 应用场景与功能解析
使用Aim进行跟踪超级简单,只需要在训练脚本中集成几行代码:
import aim
session = aim.Session()
for epoch in range(5):
session.track(loss, name="loss", epoch=epoch)
session.track(acc, name="accuracy", epoch=epoch)- import aim 和 aim.Session(): 建立一个实验会话。
- session.track(…): 在每个训练周期(epoch)中,记录关键指标,例如 loss 和 accuracy,并为它们命名和标记所属的周期。
完成代码集成后,只需运行:
aim up此时,所有指标(metrics)、直方图(histograms)、参数扫描(parameter sweeps)和日志(logs)都将被组织起来。用户无需花费精力去制作手工制作的仪表板(artisan dashboards),Aim已经为你做好了所有组织和可视化工作。
️ 第三大支柱:配置与数据的预先结构化与验证
3. Pydantic + 智能逻辑融合:验证模型配置、超参数和数据集结构
核心价值:在训练开始前,消除配置错误和类型不匹配的风险
AI训练脚本一般需要读取JSON或YAML格式的配置文件来设置模型结构和超参数。如果配置文件中缺少一个dropout值或者某个参数类型错误,往往会导致运行时(runtime)错误,浪费宝贵的训练时间。
Pydantic通过**自动执行和转换(enforce and transform automatically)**配置,完美解决了这个问题。
️ 应用场景与功能解析
Pydantic的核心是通过Python的**类型提示(type hints)**来定义一个数据模型:
from pydantic import BaseModel, conint, confloat
class ModelConfig(BaseModel):
layers: int = 3
dropout: confloat(ge=0.0, le=1.0)
hidden_size: conint(gt=0)
cfg = ModelConfig.parse_file("config.yaml")- ◉BaseModel: ModelConfig 继承自它,使其具备验证和解析功能。
- ◉int = 3: 为 layers 字段设置了整数类型和默认值。
- ◉confloat(ge=0.0, le=1.0): 这不仅要求 dropout 是浮点数,还通过约束(constraint)强制要求其值必须在0.0到1.0之间(大于等于0.0,小于等于1.0)。
- ◉conint(gt=0): 要求 hidden_size 是一个大于零的整数。
- ◉ModelConfig.parse_file(“config.yaml”): Pydantic会自动从配置文件中加载数据,并根据上述定义进行类型检查和值域验证。
通过这种方式,你的配置就变成了:健壮的(robust)、有文档的(documented)、有类型的(typed),并在**训练开始之前(before training starts)**就得到了验证。
4. Great Expectations:用“测试”而非“猜测”来断言数据集质量
核心价值:在脏数据毒害训练之前,提前捕获它们
一个带有坏值(bad values)的数据集会悄无声息地毁掉你的训练过程(kill your training silently)。你可能会在浪费了数小时甚至数天的计算资源后,才发现结果毫无意义。
Great Expectations(GE)允许你为数据集编写期望(expectations),这些期望本质上是针对数据的测试,而不是基于直觉的猜测。
️ 应用场景与功能解析
GE允许你为数据的列(columns)、类型(types)、**值域(ranges)以及空值(nulls)**编写测试:
from great_expectations.dataset import PandasDataset
import pandas as pd
class MyDataset(PandasDataset):
def expect_age_in_range(self):
return self.expect_column_values_to_be_between("age", 0, 120)
df = MyDataset(pd.read_csv("users.csv"))
df.expect_age_in_range().success- 定义一个继承自 PandasDataset 的新类 MyDataset。
- 在其中定义一个期望方法 expect_age_in_range。这个方法使用了GE内置的功能:expect_column_values_to_be_between,它断言 “age” 列的值必须介于0和120之间。
- 加载数据并实例化 MyDataset 对象 df。
- 调用期望方法,.success 属性将告知你这个数据测试是否通过。
通过这种方式,你可以在它们毁掉训练之前(before they ruin training),捕获到坏标签(bad labels)或损坏的记录(corrupt records)。
⚡ 第四大支柱:大规模数据的高效处理与流式传输
5. WebDataset:高效流式传输大规模数据集(视频、图像、张量)
核心价值:解决内存限制,实现数据的高效分片和并行读取
当你的数据量太大而无法全部加载到内存中(too big to load in memory),或者需要使用**数据分片(shards)**时,WebDataset是一个革命性的工具。
WebDataset允许你从tar文件或HTTP中流式传输数据集,并且具备**智能缓存(smart caching)**能力。
️ 应用场景与功能解析
WebDataset的核心理念是将数据打包成tar格式的分片文件,然后进行高效的读取:
import webdataset as wds
dataset = wds.WebDataset("data/shard-{0000..0010}.tar").decode("pil").to_tuple("jpg", "cls")
for img, cls in dataset:
process(img, cls)- wds.WebDataset(“data/shard-{0000..0010}.tar”): 这会创建一个数据集,它将读取并连接从0000到0010的11个tar分片文件。
- .decode(“pil”): 指定解码方式,例如将图像解码为PIL格式。
- .to_tuple(“jpg”, “cls”): 这是一个方便的操作,它将每个数据样本中的**jpg(图像)和cls(类别标签)**提取出来,并将它们组织成元组 (img, cls) 供下游处理。
WebDataset能够自动处理索引(indexing)、分片(sharding)和并行读取(parallel reading)等复杂任务。它是许多大型实验室(many large-scale labs)内部使用的库,是处理大规模图像、视频或张量的理想选择。
⚙️ 第五大支柱:实验运行与超参数的自动化管理
6. Hydra Sweeper:原生管理超参数扫描(Hyperparameter Sweeps)
核心价值:通过配置而非代码,自动化和结构化多轮实验
当需要手动运行**数十个(dozens of runs)**不同配置的实验时,你不需要编写额外的“胶水代码(glue code)”来手动生成和管理这些运行。
Hydra的内置扫描器(sweepers)或其扩展(如Hydra-Fantasy / Hydra Ax)允许你通过配置文件来执行网格搜索(grid)、随机搜索(random)或基于Optuna等优化器的超参数扫描。
️ 应用场景与功能解析
通过简单的YAML配置,你可以定义需要扫描的参数空间:
# config.yaml
optimizer:
lr: 0.001
betas: [0.9, 0.999]
hydra:
sweep:
parameters:
optimizer.lr: [1e-3, 1e-4]
optimizer.betas.choice: [[0.9, 0.999], [0.95, 0.999]]- 基础配置: 在 optimizer 下定义了一个基础的学习率 lr 和 betas。
- 扫描定义: 在 hydra.sweep.parameters 中,你指定了要进行扫描的参数及其候选值:
- ◉optimizer.lr: [1e-3, 1e-4]: 学习率将分别取 1e-3 和 1e-4。
- ◉optimizer.betas.choice: [[0.9, 0.999], [0.95, 0.999]]: betas 参数将从两个元组配置中选择一个。
运行实验时,只需添加 –multirun 标志:
python train.py --multirun执行后,Hydra将为你生成结构化的输出(structured outputs)、组织化的日志记录(organized logging)和可转换的摘要(convertible summaries),所有这些都无需任何胶水代码。
第六大支柱:训练过程的鲁棒性与内存诊断
7. TorchSnapshot / Checkpointing Libraries:原子化、可恢复的快照
核心价值:确保崩溃可恢复,杜绝部分写入导致的检查点损坏
在AI训练过程中,崩溃(Crashes)是不可避免的。更危险的是部分写入(Partial writes),即在保存模型状态时,由于进程中断导致文件只写入了一部分,从而产生**损坏(corrupt)**的检查点文件。
使用像TorchSnapshot这样的鲁棒(robust)检查点工具,可以确保原子性写入(atomic writes)和轻松恢复(easy resume)。
️ 应用场景与功能解析
TorchSnapshot的使用模式超级直接,确保了数据的完整性:
from torchsnapshot import SnapshotWriter
writer = SnapshotWriter("./snapshots")
# inside training loop
writer.write({"model": model.state_dict(), "optim": optimizer.state_dict()}, tag=f"epoch_{epoch}")- SnapshotWriter(“./snapshots”): 初始化一个快照写入器,指定存储目录。
- writer.write(…): 在训练循环内部调用此方法,将需要保存的**模型状态字典(model.state_dict())和优化器状态字典(optimizer.state_dict())保存为一个快照,并用当前的周期数(epoch)**打上标签 tag。
关键在于,如果训练在写入过程中停止,你可以从上一个有效的快照(last valid snapshot)恢复——这彻底消除了**损坏文件(corrupt files)**的风险。
8. Memray:专为AI工作负载设计的内存分析器
核心价值:定位沉默的内存泄露,防止集群性能下降
AI代码,特别是涉及大量数据和计算图的代码,很容易悄无声息地泄露GPU缓冲区缓存(silently leak GPU buffer caches)或Python对象。内存问题常常是导致训练速度变慢或集群性能下降的“幕后黑手”。
Memray可以提供行级分辨率(line-level resolution)的内存分析,协助你准确地找到内存消耗的罪魁祸首(culprits)。
️ 应用场景与功能解析
使用Memray来分析内存超级简单,只需要一个上下文管理器:
import memray
with memray.Tracker("memray-out.bin"):
train() # your training function- memray.Tracker(…): 将你的训练函数 train() 包装在这个上下文中。Memray将记录这个代码块执行期间所有的内存分配情况,并保存到一个二进制文件(memray-out.bin)中。
分析结果通过命令行查看:
memray summary memray-out.bin你可以通过 memray summary 命令来检查内存峰值(memory peaks)和罪魁祸首(culprits)。通过这种分析,你可以找到忘记释放的对象(objects you forgot to free)或不当的重用(bad reuse),在它们**拖垮你的集群之前(before they tank your cluster)**解决问题。
️ 第七大支柱:模型调试与数据集的可视化检查
9. fiftyone:交互式数据集检查、切片与标注
核心价值:通过可视化调试模型,聚焦于错误分类的边缘案例
AI开发中一个主要的痛点是对错误分类的图像(misclassified images)、标签错误(label errors)和边缘案例(edge cases)进行可视化检查(visual inspection)。
FiftyOne提供了一个基于数据集的UI(a UI over datasets),用户可以在其中:
- ◉筛选(filter)
- ◉选择(select)
- ◉导出子集(export subsets)
- ◉连接到模型预测(connect to model predictions)
️ 应用场景与功能解析
使用FiftyOne启动交互式会话:
import fiftyone as fo
dataset = fo.Dataset.from_dir("/path/to/images", fo.types.ImageClassificationDirectoryTree)
session = fo.launch_app(dataset)
# open browser, filter mispredictions, export a subset- fo.Dataset.from_dir(…): 从磁盘加载图像分类数据集。
- fo.launch_app(dataset): 启动一个Web浏览器中的会话(session)。
在浏览器界面中,用户可以执行以下关键操作:
- ◉筛选错误预测: 例如,筛选出“模型预测为'cat'但标签显示'dog'”的样本。
- ◉导出子集: 可以将这些筛选出的错误样本(mispredictions)切片出来(slice out),并**导出(export)**为一个新的子数据集。
- ◉迭代优化: 模型可以专注于对这些特定的子数据集进行**迭代(iterate)**和改善。
FiftyOne是**严肃实验室(serious labs)用来以可视化方式调试模型(debug models visually)**的重大工具。
结论:打造高效、可控、专业的AI工程化流程
我们已经详细探讨了10个能够将混乱的AI项目转化为可维护系统的关键Python库。这些工具并非仅仅是提升效率的辅助品,它们是工程化(Engineering)AI工作流的基础:
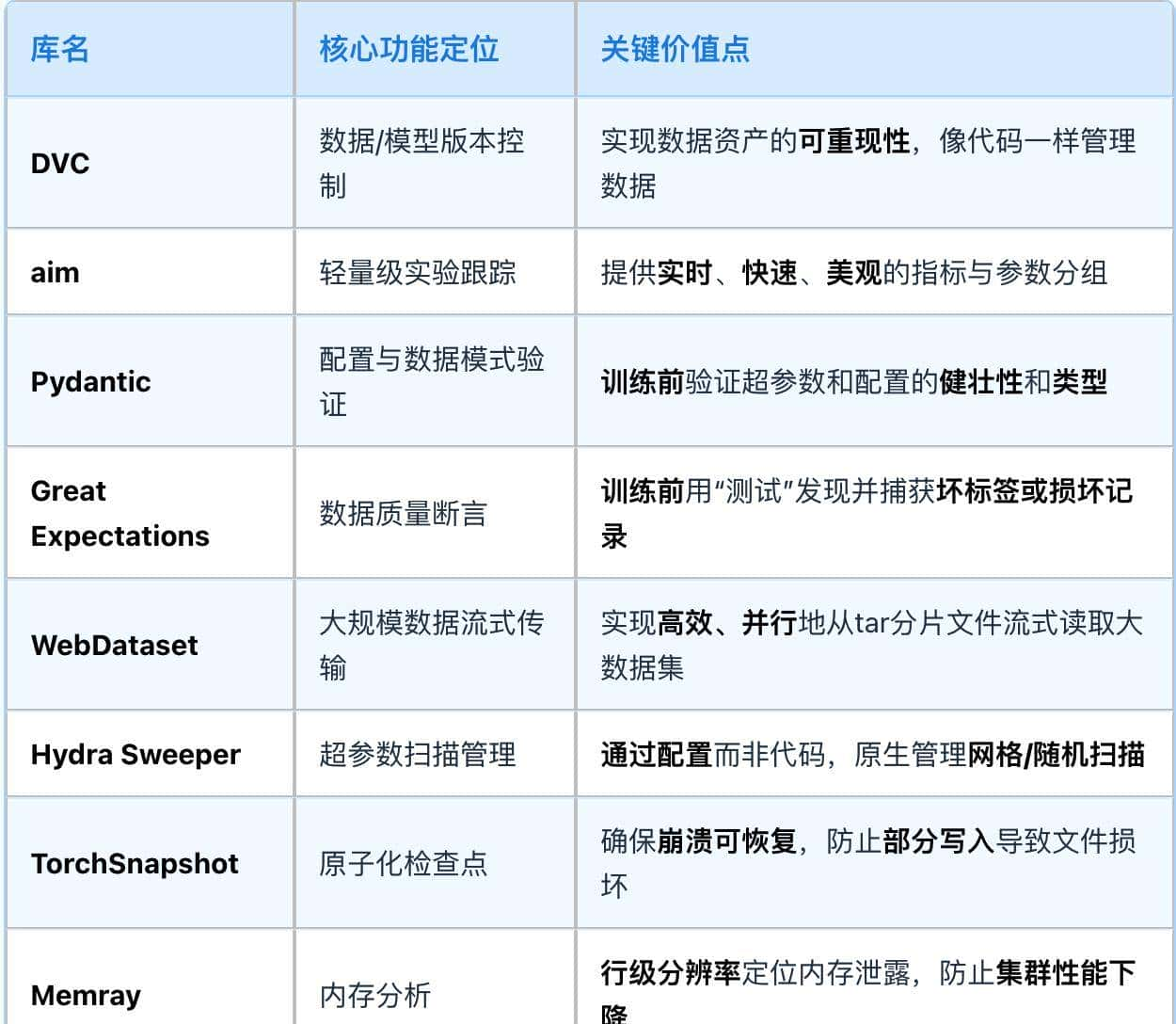
从数据版本化到实验跟踪,从配置验证到内存分析,再到可视化调试,这一整套工具链为AI开发者提供了一个组织完整AI工作流(organize entire AI workflows)的全能工具箱。它们是将机智的想法转化为能够存活下来的真实代码的关键。掌握这些库,你就能在AI的“战场”中,始终保持可控、高效、专业的状态。
感谢您的阅读!
© 版权声明
文章版权归作者所有,未经允许请勿转载。












我们已经详细探讨了10个能够将混乱的AI项目转化为可维护系统的关键Python库。这些工具并非仅仅是提升效率的辅助品,它们是工程化(Engineering)AI工作流的基础:从数据版本化到实验跟踪,从配置验证到内存分析,再到可视化调试,这一整套工具链为AI开发者提供了一个组织完整AI工作流(organize entire AI workflows)的全能工具箱。它们是将聪明的想法转化为能够存活下来的真实代码的关键。掌握这些库,你就能在AI的“战场”中,始终保持可控、高效、专业的状态。
收藏了,感谢分享