
国产编程语言终于支棱起来了?!华为仓颉语言实测报告来啦✨
家人们谁懂啊!前几天蹲华为开发者大会直播,看到仓颉编程语言发布的时候,本大神直接一个垂死病中惊坐起!这可是咱们中国人自己从头研发的编程语言啊!我今天特意写了个程序跑了起来,实测完,必须来和大家唠唠真实体验~

(仓颉语言logo)

(仓颉语言的结构和语法)
测试背景:
作为资深的架构师,现作为产品经理,以前也是天天和C++/Java打交道的码农,我连夜下载了仓颉环境包(安装过程超简单,实则要开发环境就下载压缩包解压后配置好path就行,给华为点个赞)。为了验证官方说的”高性能”,我花了半天时间用vscode作为编码环境搞了个对比实验:用仓颉和C语言分别写了个程序,实现三个程序功能
- 百万次循环计数
- 双重循环(内层指数爆炸增长)
- 斐波那契数列递归计算
实测结果:
程序体积:仓颉编译的.exe文件1.95MB,C语言才57KB(仓颉宝宝你膨胀了)
我说明一下:仓颉语言刚开发我只写一个简单“Hello World”时编译出来的程序只有792KB的,后来加了上面那3个功能,引入了仓颉自带的时间处理包(std.time),编译出来就变大了。
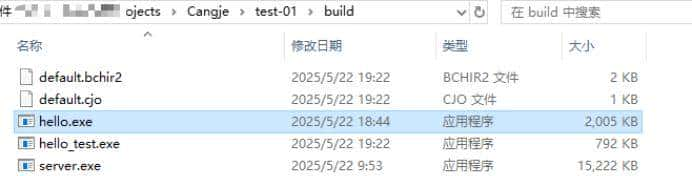
(仓颉语言编译的目标程序)

(C语言编译的目标程序)
实则大家也不用感到意外,我用Rust定的一个“Hello World”时编译出来的程序也有2.05MB,所以仓颉语言编译出来的程序已是很好了。
运行速度:
- 普通循环:仓颉慢3倍左右
- 递归计算:直接拉开3.3倍差距
(大家是否当场哀嚎:说好的高性能呢?!)
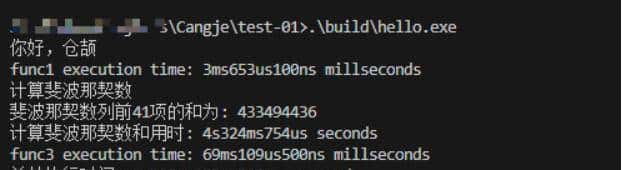
(仓颉编译的程序执行效率)
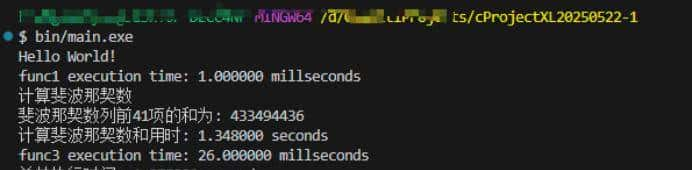
(C语言编译的程序执行效率)
破案时刻:
但!是!当我们扒开代码看本质,发现事情并不简单:
✅ 安全防护拉满:仓颉自带”内存安全气囊”,每次递归都自动检查内存泄漏(C语言得自己手动搞,容易翻车)
✅ 开发效率王者:写代码时智能提示多到爆!变量类型都不用声明(var一键搞定)
✅ 隐藏大招:双重循环测试时,仓颉和C语言的速度曲线几乎重合!说明基础性能并不拉胯
意外收获:
测试过程中还触发了3次整型溢出拦截,还有C语言编译出来程序在windows下中文是乱码的!由于C语言默认不是UTF-8的,要特殊编译参数指定为gbk才行,如果你与遇到过这种问题,你真的会谢我的!
为什么我还要吹爆它?
- 教学神器:调试工具直接可视化线程状态!给学生讲多线程再也不用手舞足蹈比划了
- 鸿蒙亲儿子:调用物联网设备API超方便,做智能家居项目不用折腾底层驱动
- 未来可期:协程开发模板已经预留了(虽然目前还没开放),分布式计算赛道潜力股
留下的思考:
你们是否会问:”大师,我们为什么要用比C慢的语言呀?”
我的回答是:
性能≠一切(想想Python怎么逆袭的!)
新手友善度+安全系数才是现代编程刚需
生态建设需要时间(还记得2006年的初代Android吗?)
✨实测彩蛋:
偷偷试了下用仓颉调用华为鸿蒙的分布式相机API——20行代码就搞定了多设备联拍!这要是用C语言,光写驱动就得秃头…
总结:
给想尝鲜的小伙伴划重点:
✔️ 目前适合物联网/教学场景
✔️ 新手友善度Max(比Java容易上手)
✔️ 等华为更新编译器优化(懂的都懂)
最后想说,看到仓颉语言里那些拼音命名的系统函数(列如”HuanCun”取代”Cache”),真的有点小激动呢~或许这就是技术自立的温度吧❤️
(附上实验室拍的测试对比图,有图有真相,在这也附上测试源代码,大家也测试下)
- 仓颉源代码:
// hello.cj
import std.time.*
func func1(n: Int64): Unit {
var k: Int64 = 0;
for (_ in 0..=n) {
k++;
}
}
func func3(n: Int64): Unit {
var k: Int64 = 0;
for (i in 0..=n) {
var j = 1;
while (j < n) {
k++;
j *= 2;
}
}
}
// 递归计算第n项的值
func fib(n:Int16): Int64 {
if (n == 1 || n == 2) {
return 1;
}
return fib(n-1) + fib(n-2);
}
// 递归计算前n项的和
func fib_sum(n:Int16): Int64 {
if (n == 1) {
return 1;
} else if (n == 2) {
return 2; // 1+1
} else {
return fib_sum(n-1) + fib(n);
}
}
// 迁移C的当前时间函数
func clock(): DateTime {
return DateTime.now();
}
main() {
println("你好,仓颉")
// 测试性能所用时间
var start: DateTime = DateTime.now();
var start0 = start;
var end = start;
var cpu_time_used: Duration;
let n = 1000000; // 可以调整n的值来测试不同规模的数据处理时间复杂度变化情况。
start = DateTime.now(); // 获取开始时间。
func1(n); // 调用函数func1。
end = DateTime.now(); // 获取结束时间。
cpu_time_used = ((end - start)) ; // 计算CPU时间。
println("func1 execution time: ${cpu_time_used} millseconds"); // 输出结果。
println("计算斐波那契数");
start = clock(); // 获取开始时间。
let a: Int16 = 41;
let sum: Int64 = fib_sum(a);
println("斐波那契数列前${a}项的和为: ${sum}");
end = clock(); // 获取结束时间。
cpu_time_used = (end - start); // 计算CPU时间。
println("计算斐波那契数和用时: ${cpu_time_used} seconds"); // 输出结果。
start = DateTime.now(); // 获取开始时间。
func3(n); // 调用函数func3。
end = DateTime.now(); // 获取结束时间。
cpu_time_used = ((end - start)) ; // 计算CPU时间。
println("func3 execution time: ${cpu_time_used} millseconds"); // 输出结果。
cpu_time_used = (end - start0); // 计算总共CPU时间。
println("总共执行时间: ${cpu_time_used} seconds."); // 输出结果。
}- C语言源代码:
// main.c
#include <stdio.h>
#include <time.h>
void func1(long long n) {
long long k = 0;
for (long long i = 0; i < n; i++) {
k++;
}
}
// 递归计算第n项的值
int fib(int n) {
if (n == 1 || n == 2) {
return 1;
}
return fib(n-1) + fib(n-2);
}
// 递归计算前n项的和
int fib_sum(int n) {
if (n == 1) {
return 1;
} else if (n == 2) {
return 2; // 1+1
} else {
return fib_sum(n-1) + fib(n);
}
}
void func3(long long n) {
long long k = 0;
for (long long i = 0; i < n; i++) {
for (long long j = 1; j < n; j *= 2) {
k++;
}
}
}
int main()
{
printf("Hello World!
");
// 测试性能所用时间
clock_t start, start0, end;
double cpu_time_used;
long long n = 1000000LL; // 可以调整n的值来测试不同规模的数据处理时间复杂度变化情况。
start = clock(); // 获取开始时间。
start0 = start;
func1(n); // 调用函数func1。
end = clock(); // 获取结束时间。
cpu_time_used = ((double) (end - start)) ; // 计算CPU时间。
printf("func1 execution time: %f millseconds
", cpu_time_used); // 输出结果。
/* */
printf("计算斐波那契数
");
start = clock(); // 获取开始时间。
int a = 41;
int sum = fib_sum(a);
printf("斐波那契数列前%d项的和为: %d
", a, sum);
end = clock(); // 获取结束时间。
cpu_time_used = ((double) (end - start)) / CLOCKS_PER_SEC; // 计算CPU时间。
printf("计算斐波那契数和用时: %f seconds
", cpu_time_used); // 输出结果。
start = clock(); // 获取开始时间。
func3(n); // 调用函数func3。
end = clock(); // 获取结束时间。
cpu_time_used = ((double) (end - start)) ; // 计算CPU时间。
printf("func3 execution time: %f millseconds
", cpu_time_used); // 输出结果。
cpu_time_used = ((double) (end - start0)) / CLOCKS_PER_SEC; // 计算总共CPU时间。
printf("总共执行时间: %f seconds
", cpu_time_used); // 输出结果。
return 0;
}
© 版权声明
文章版权归作者所有,未经允许请勿转载。










溢出拦截,似是而非的名词。
C的套壳而已,这是誓要把套壳玩到底的节奏呀!
不懂别说,语言还有套壳?
c可以运行在51单片机,stm32,windows linux macos,几乎全世界所有能看到的x86 arm 处理器上。所以:大师,我们为什么要用比C慢的语言呀?
在您的测试中,c语言的func3,测试结果应该是耗时接近于0,达不到测试效果。
用了26毫秒的,还是有对比价值
数据类型放在后面的都是异端
这点应是学了一点delphi语言的特性
说好的“汉语编程”呢,怎么看到的都是C的影子呢
感觉汉语不太适合编程,现在可以了,用语音AI提示词就行了
使用编译器,需要下载gcc,懂吗
不需要,而RUST要GCC
包管理做的不好,不动态导入,不用的包导入了也会执行,如果你导入的是xx.*,不管你用不用,全部类,函数,都会放在内存中。
这个跟JAVA类似,自己优化就行
鼓励国产,但是每个成功的语言都有自己的特色,比如go协成php开发效率,找到自己痛点
仓颉像go还是rust?编译器开源没?
但愿有详尽、通俗的中文文档和示例,这样才有利于这个语言的推广。
类型大写让我感到非常不适,还有moonbit,本来很期待。不太符合人体功学
这哪里是汉语编程,最多是汉语说明
即然huancun更好,那func为什么不换成hanshu?
第三方托管中心还没有吧,没有这个不好写项目,什么东西都得亲自写
不懂别胡说,现代语言有各种语言的影子。c和Python融合,并弥补了其缺憾,这是我给的评价,所以说学习的难度应该在两者之间。
和C比体积有点流氓,应该和C++,JAVA比体积
跟Kotlin相似度可能达到80%
刚出的时候看了下,还是不习惯它的风格,算了吧
“huancun”戳中了我的笑点…