
本期速递
- HCNN-PSI: A hybrid CNN with partial semantic information for space target recognition
- GaitNet: An end-to-end network for gait based human identification
标题:HCNN-PSI: A hybrid CNN with partial semantic information for space target recognition
期刊:Pattern Recognition
年份:2020.7 YLN
主要内容列举:
- :采用数据增强与图像处理方法来描绘太空背景下的空间目标的图像
- :提出一种新的定位法,由最小边界矩形模型(minimum bounding rectangle ,MBR)完善而来
- :提出一种可以整合多元信息的混合网络
(一)数据方面
- 数据集
1)dataset I:该数据集是作者的模拟数据,共554张图片,训练集与测试集占比为80%与20%。
2)BUAA SID 1.0:该数据集是公开数据集,包含20个卫星模型,每个模型有230张图像,100个训练集与100个测试集。作者没类别选用100张图像作为训练集,30张图像作为训练验证集,100张图像作为测试集。
(二)方法方面
- 创新工作
在将空间目标识别应用至太空中卫星识别等情况,主要问题在于如何为卫星的不同部件分配语义信息的权重以提升具有巨大差异的特征的类别决定功能。作者提出一种带有部分语义信息的混合CNN(HCNN-PSI)用于深空目标识别。广域图像的目标定位,部件分割和多源输入识别将通过三个主要过程逐步实现。第一,作者提出一种基于深空图像特征的两阶段目标检测,然后采用Mask R-CNN来分割被检测到的卫星的主要部件。最后被检测到的目标和被分割的部件被送至混和提取器以训练混合网络,以及分类出卫星的类别。这种混合的网络架构可以整合全局语义信息与局部语义信息,利于增强决定性部位的权重。
2.模型结构
该网络的模型架构如下图:
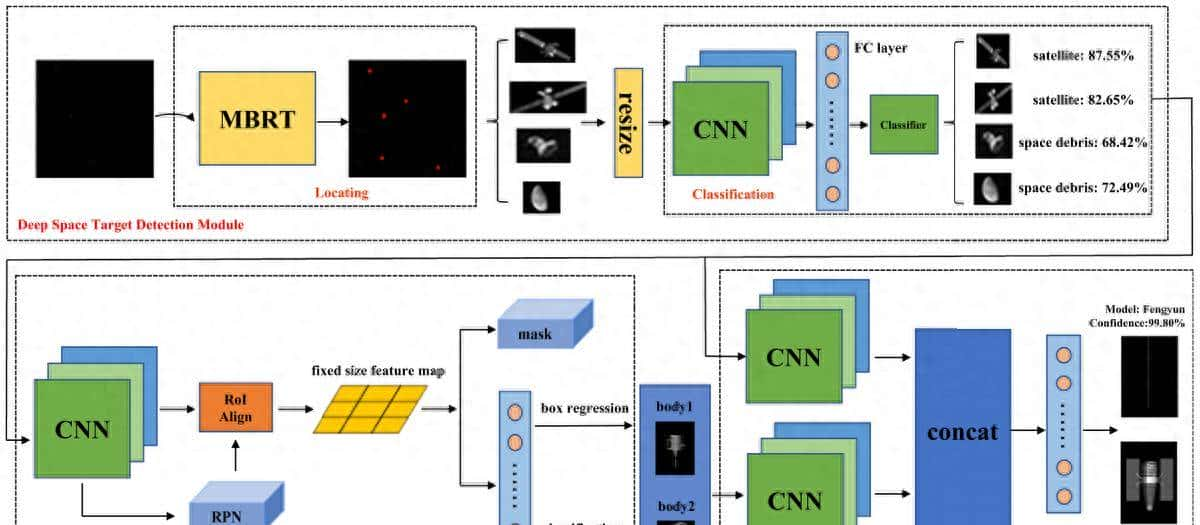
该模型可分为以下三个阶段:
1)深空目标检测:
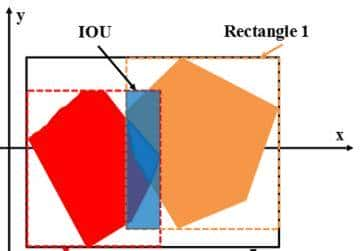

该部分模型主要负责深空图像中卫星的定位以及识别,基于MBRT的目标检测包含两步:定位与分类。而深空图像的分辨率过高,于CNN而言难以提取特征,加之大规模的矩阵运算会耗费大量时间,故采用滑动窗口的方法来检索候选以及候选区域网络RPN都是不实际的。作者借用MBR(minimum bounding rectangle,最小边界矩形模型)的想法,第一在连续的像素间隔上遍历所有像素的坐标值获得矩形目标框的左上角以及右下角坐标。思考到卫星部件间的而连接会被忽略造成像素不连续,作者加入阈值的最小边界矩形模型(MBRT)来解决此类问题。当两个矩形框的交并比IOU超过了合并阈值则合并这两个矩形框(如上左图所示)。获得候选区域后将其大小调整为256×256,并送至CNN中提取特征,然后已训练的分类器可识别候选区域的类别。识别部分所使用的网络为ResNet-50模型(具体设置如上右图所示)。
2)部件分割:
第一作者采用总体特征做出预测,分析样本的热图。热图中颜色越深,表明是卫星的可能性越大。为了获得获得卫星相关部件的信息,作者采用Mask R-CNN作为实例分割模型。由于部件对于卫星模型类别的决策是更重大的,实验证明Mask R-CNN能够更精准地识别部件,达到像素级别的分割效果,故采用Mask R-CNN是随后的多颗粒识别任务中的关键步骤。Mask R-CNN是Faster R-CNN的扩展,对于Faster R-CNN的每个候选区,使用全连接网络以进行语义分割。分割任务与定位以及分类任务同时进行,采用区域匹配方法取代区域池化来提升Mask的准确率。引入语义分割分支实现掩膜与类别预测的分离,掩膜分支只执行语义分割,类别预测由另一分支完成。RPN层使用滑动窗口来扫描图片寻找目标区域。ROI匹配层采用双线性差值在特征图的不同位置采样以解决输入大小不同的问题。类别与坐标值的预测通过全连接层获得。目标掩膜通过包含两个卷积层的掩膜网络获得。
3)细粒度识别:
获得了真实空间目标与部件之后,为了给更具据决定性的部分更大的权重,,作者将全局信息与局部信息输入CNN以分类目标,损失函数则为所有子损失函数的加权和。作者只思考太阳翼数量少于等于2的情况。当太阳翼的数量为2时,两个部件的图像通过维度连接,通过全连接层映射。若太阳翼的数量小于2,则丢失部分的图像被清零。
3.其他主要工作
作者采用了数据增强的方法来扩大数据量,包括旋转图像,模糊,裁剪,加入椒盐噪声等方法。
在模型的第一部分通过最小化交叉损失熵来获得理想模型。第二部分损失函数为混合损失函数。第三部分为各子损失函数的加权和。
各网络采用的参数一样。
使用了随机梯度下降优化功能,动量为0.9;学习率初始化为0.001;序列大小为64.
4.对比方法
无。
5.模型代码
无。
(三)结果方面

由上table1可见,当第一阶段的卷积网络采用ResNet-50时能获得最好的准确率,最小的平均损失以及较少的迭代次数。


由上第一第二张图片可见,当图片中加入干扰噪声时,模型仍可准确提取深度特征,映射出正确输出。由第三张图片可见第二阶段的分割网络抗噪能力也十分出色。
标题:GaitNet: An end-to-end network for gait based human identification
期刊:Pattern Recognition
年份:2019.7 YLN
主要内容列举:
- :提出GaitNet,是一个整合了人类轮廓提取与步态识别的单网络模型
- :在度量学习中加入Siamese损失
- :在实验中提供了大量的实证评价
(一)数据方面
1.数据集
1) CASIA-B:包含124个人在室内三种情况下的原始步态图片和对应加工好的二进制文件。其中,前74个被用于训练,余下50个用于测试。
2) SZU RGB-D Gait :包含99个被测对象两个视角的步行的彩色与深度图像,每个视角有四段影像序列。其中前49个用于训练,余下用于测试。
3) Outdoor-Gait.:作者为增加复杂度与准确性而创立的数据集,包含具有挑战性的户外场景,例如画面中有移动的汽车与自行车,光线差异也很大。数据聚焦包含138个被测对象着三种着装在三种不同场景下的影像。其中,前69个用以训练,余下用于测试。未提供数据集链接。
2.预处理
作者第一将输入图片的尺寸大小调整为64 × 64,再通过减去平均值的方式标准化,缩放255倍。没有使用数据增强的方法。
(二)方法方面
1.创新工作
大部分现有的步态识别网络架构中轮廓分割,特征提取,特征学习和类似性度量等模块是相互独立的,在面对具有挑战性的任务时表现不能达到理想状况。于是作者将这些步骤整合为一个端到端的网络GaitNet,该网络由两个卷积神经网络组成,一个用于步态分割,一个用于分类。这两个网络在联合学习过程中被建立起来,,共同训练。这种策略极大地简化了传统的分步的方法。联合学习可以自动调整每个部分以适应全局最优目标,相比分离训练,能带来明显的改善。
2.模型结构

GaitNet包含两部分,分割网络与识别网络。
1) 步态分割网络
此部分,作者设计了一个全卷积网络FCN,包含用于特征提取的7个卷积层与获得最终分割的1个反卷积层。N张图片构成一个组合,使用一样的参数。输入图片先通过一个单卷积步长48个卷积核的卷积,再经过3 × 3步长为2最大池化,池化的特征随后被标准化,这是第1与第2个卷积层结构。第3至第5个卷积层则只包含卷积,第6与第7个卷积层则包含dropout。反卷积层将第7个卷积层输出的特征生成64 × 64的预测。在反卷积后采用了sigmoid激活函数。为了学习具有对比损失的判别特征,作者同时训练两个FCN模型,为保持分割学习的连贯性,模型间共享参数。
2) 时间融合
对于一个步态视频中连续的N帧,已训练的FCN模型可以生成对应分割,然后需将其结合以生成步态模板作为识别网络的输入。作者采用空间平均池化作为默认的时间融合方法。
3) 步态识别网络
该部分采用基于CNN的多尺度情景感知网络(Multi-Scale Context-Aware Network ,MSCAN),MSCAN包含四个卷积层与两个全连接层,每个卷积层可采用不同尺度的卷积操作,全连接层在soft-max损失函数的指导下学习步态特征。为学习更具判别性的特征,作者引进加入了Siamese损失的度量学习以减少特征对间的距离与使特征对内部微小的距离得以保持。
4) 联合学习
为提升识别为导向的步态分割,作者用一个加权损失函数(如下)将分割与识别联合训练。

式中,Lseg为分割损失,Lrec为识别损失,分割损失发挥着注意力机制的作用,使网络专注于人体区域而不是背景。
3.其他主要工作
使用随机梯度下降通过后向传播来训练GaitNet。
分割网络学习率固定为0.0001。识别网络学习率为0.01至0.0001不等。联合学习部分学习率为0.0001。
4.对比方法
对比方法:VTM,ViDP,LRDF,C3A,MGANs,CNN等
对比指标:第一张匹配平均正确率
5.模型代码
无。
(三)结果方面

如上表,可见加入了MSCAN,联合学习,Siamese损失的网络表现优于基本网络(未加入MSCAN,联合学习与Siamese损失),证明MSCAN,联合学习,Siamese损失可提升第一张匹配平均正确率。

如上表,可见GaitNet的表现优于最先进的方法,证明了作者所提出的方法的有效性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。












主播辛苦了
收藏了,感谢分享