
深度学习框架:Tensorflow, Keras, PyTorch, Paddle
- Tensorflow 2.0, 2019年发布,相比于1.0更加简洁,Pytorch,由Facebook开发,Python + Torch科学计算库,用来取代Numpy,可以有效利用GPUs。
- 动态图设计,可以高效地进行神经网络的构造,学术界用的多。

一样点:
- 神经网络不是一个新的概念,端到端的黑盒,可解释性较差,自适应完成特征提取;
不同点:
- 深度学习强调了模型的深度(GoogleNet网络为22层,ResNet可以达到50,101,152层)。
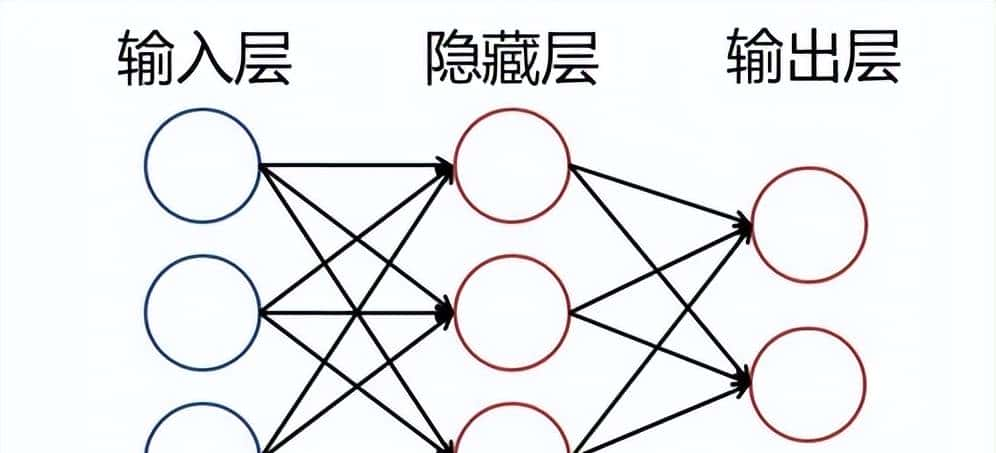
- 类比生物神经元:单个神经细胞只有两种状态:兴奋和抑制。
- 网络中的每个节点(神经元)接收输入信号,如果所有信号的加权总和超过一个“阈值”,它就被“激活”(兴奋),并向下传递信息;否则就保持“抑制”。这种简单的开关机制,构成了整个网络决策和学习的根本。
这个“简单的开关机制”是如何来实现的?
- 通过激活函数来实现的,它构成了网络学习的根本。
- 一个神经元就是一个决策小单元。它接收许多上游传来的信号,同时它需要做一个“决定”:我收到的这些信息足够重大吗?我需要把这个信息继续往下传递吗?
- 激活函数就是这个决策的“开关”。它将所有输入信号的加权总和作为输入,然后输出一个值。最简单的激活函数(阶跃函数)就像一个纯粹的开关:输入总和超过阈值,就输出1(兴奋=>传递);否则输出0(抑制=>不传递)。
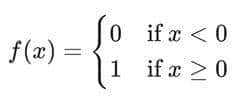
- 整个神经网络由无数个神经元组成。当这些成千上万的简单决策汇集在一起时=> 整个网络就能做出极其复杂的决策。
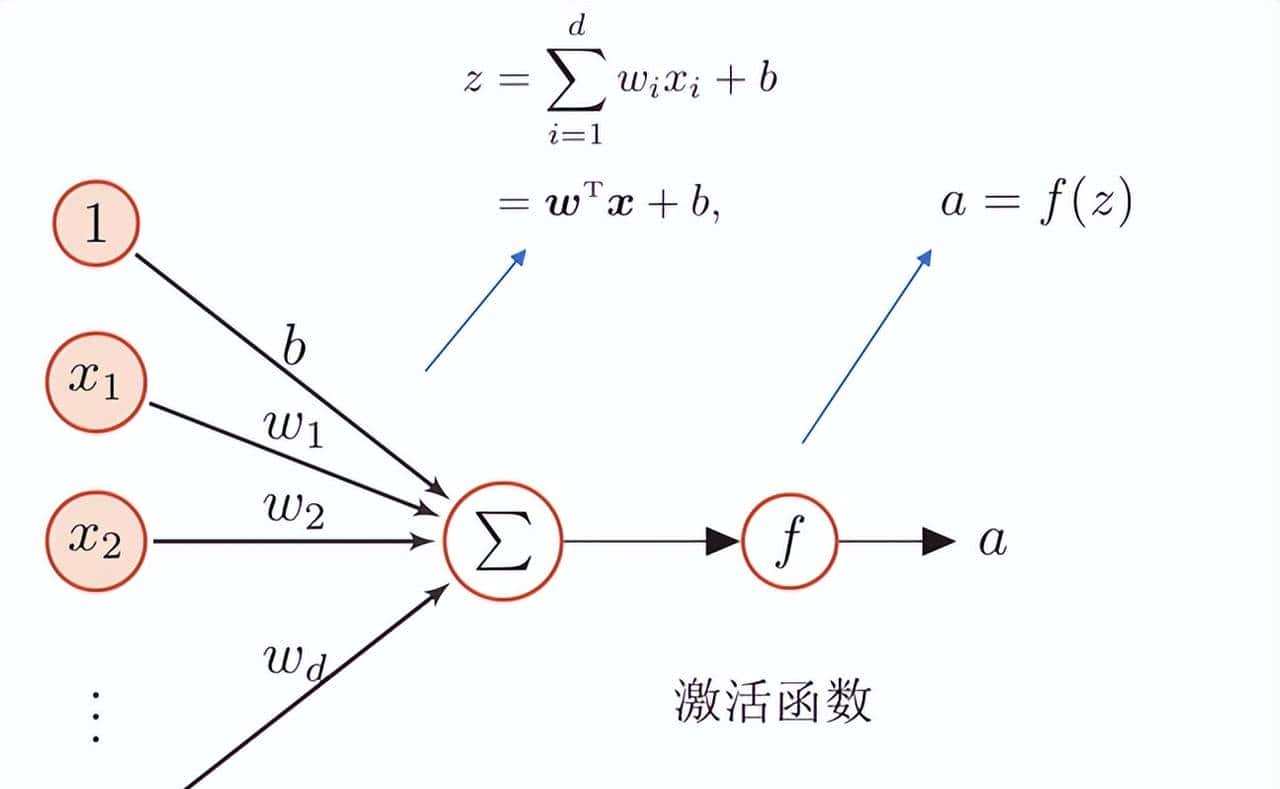
使用numpy模拟前向传播
- Step1,初始化网络
- 设置3层神经网络的W和b
- Step2,定义激活函数
- 第一层,第二层的激活函数使用sigmoid,输出层的激活函数使用恒等函数,即g(x)=x
- Step3,前向传播
- 前向传播比较简单,就是向量点乘(即加权求和),然后经过一个激活函数。最终输出预测结构Y‘。
Python代码实现:
import numpy as np
# 初始化网络(初始权重和偏置)
def init_network():
network = dict()
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
# sigmoid激活函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 恒等函数,作为输出层的激活函数
def identity_function(x):
return x
# 前向传播
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
# hidden layer 1
a1 = np.dot(x, W1) + b1
# 前向传播 使用sigmoid
z1 = sigmoid(a1)
# hidden layer 2
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
# output layer
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y
# 初始化网络
network = init_network()
# 设置输入值
x = np.array([1.0, 0.5])
# 前向传播
y = forward(network, x)
print(y)激活函数:
- 神经网络中的神经元接受上一层神经元的输出值作为输入值,输入层神经元节点会将输入属性值直接传递给下一层,在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数。
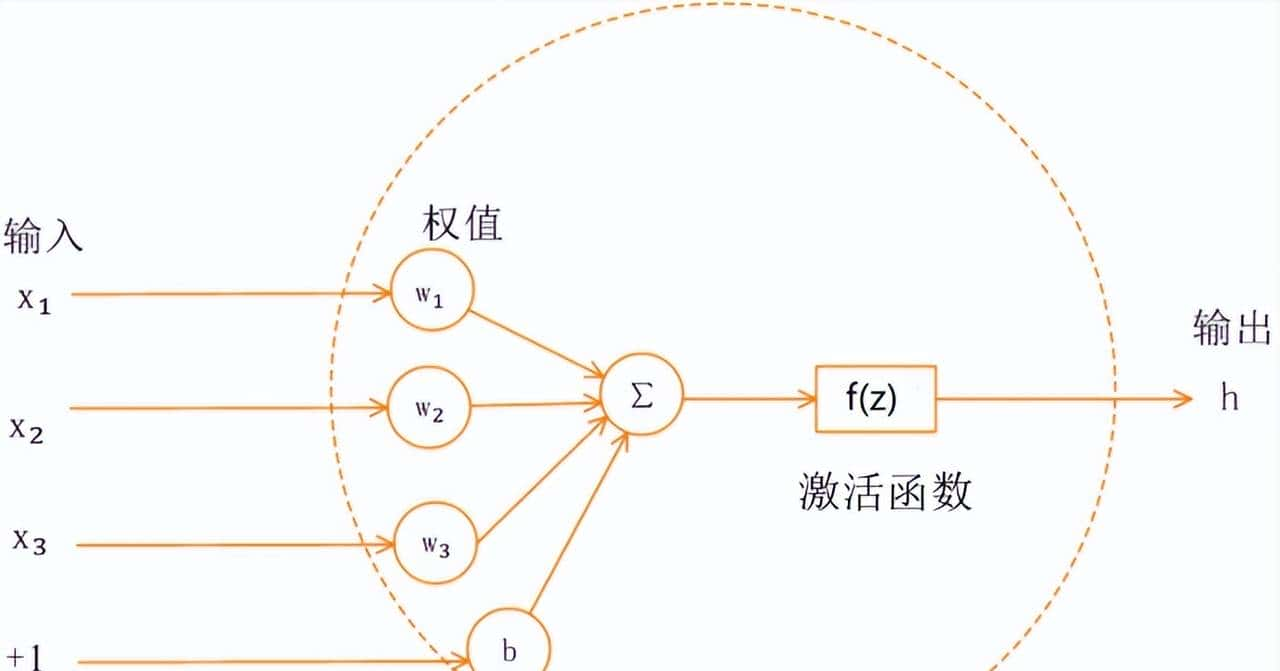
为什么需要激活函数:
- 如果不用激活函数,就相当于激励函数f(x) = x,此时每一层节点的输入都是上层输出的线性函数,那么无论神经网络有多少层,输出都是输入的线性组合=> 与没有隐藏层效果相当。
- 引入非线性函数作为激活函数,这样神经网络表达能力会更加强劲=> 不再是输入的线性组合,而是几乎可以逼近任意函数。
sigmoid激活函数:
- 输入为连续实值,输出结果为0和1之间,负无穷的输出结果为0,正无穷的输出结果为1。
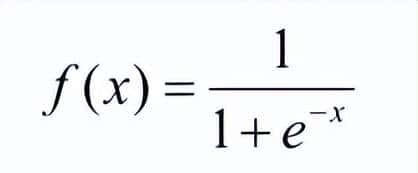
- 在深度神经网络中梯度反向传递时导致梯度爆炸和梯度消失,其中梯度爆炸发生的概率很小,而梯度消失发生的概率较大。
- 如果初始化神经网络的权值为[0,1] 之间的随机值,由反向传播算法可知,梯度从后向前传播时,每传递一层梯度值都会减小为原来的0.25倍。
- 如果神经网络层数多,那么梯度在多层传播后将变得很小(接近于0),即梯度消失
- 当网络权值初始化为(1,+∞) 区间内的值,则会出现梯度爆炸。
梯度消失的缘由:
- 假设有三个隐藏层,每层的神经元个数都是1,对应的非线性激活函数为:
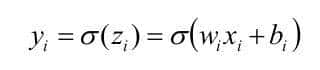
- 我们要更新b1,就需要求出损失函数对于b1的导数,如果初始化的神经网络权重|w|小于1,| δ’ ( z ) w | 0 . 25当层数增多时,小于1的值不断相乘,最后就导致梯度消 失的情况出现 同理,当权重|w|过大时,导致| δ’ (z) w|>1,最后大于1的值不断相乘,就会产生梯度爆炸。
relu激活函数:
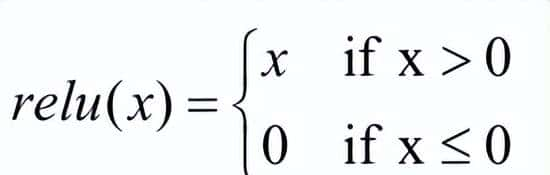
- 单侧抑制,它将所有负数输入都变成0,而正数则保持不变。
- 对于被激活的神经元(输入为正数),其梯度恒定为1。在网络学习(反向传播)时,这意味着误差信号可以几乎无衰减地向后传递,不会像Sigmoid函数那样因逐层相乘而变得越来越小(梯度消失)。=>信号既然能有效传达,权重就能被持续更新,所以模型能学得又快又稳。
- 激活函数的特点是非线性,而数据的分布绝大多数是非线性的=> 可以强化网络的学习能力。不同的激活函数特点不同,应用也不同。sigmoid函数输出值在(0,1)之间 => 适合处理概率值,但会产生梯度消失=> 不适合深层网络训练。
- relu的有效导数是常数1,解决了深层网络中出现的梯度消失问题=> 更适合深层网络训练。
损失函数Loss Function:
- 用来衡量模型预测值与真实值不一致的程度,是一个非负实数函数。
反向传播:
- 假设,我们要买一辆汽车,价格为50万,购置税为10%,一次购买2辆。

- 汽车单价50万,最终需要支付110万。目前想知道汽车单价每波动1万,对最终支付价格的影响是多少。
- 从右向左依次求导,得到的值分别为:①110/110=1;②110/100=1.1;③100/50=2。最终价格相对于汽车单价的导数 为①×②×③=2.2。
- 反向传播就是通过链式法则,从最终结果开始,一层层地向后计算每个节点、每个参数对最终结果的“影响力”(即梯度)。
- 在真实的神经网络中,计算出这个“影响力”后,就可以根据它来微调参数=> 这就是“学习”的过程。
使用numpy实现一个神经网络:
- Step1,定义网络结构(指定输入层、隐藏层、输出层的大小)
- Step 2,初始化模型参数
- Step3,循环操作:
- 3.1 执行前向传播
- 3.2 计算损失函数
- 3.3 执行后向传播
- 3.4 权值更新
- 数据源:
- 样本大小为64
- 输入层维度为1000
- 输出层维度为10
- 隐藏层维度为100
- 数据通过numpy.random随机生成
Python代码实现:
# 使用numpy实现一个神经网络
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体,解决中文显示乱码问题
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'DejaVu Sans'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# n为样本大小,d_in为输入维度,h为隐藏层维度,d_out为输出维度
n, d_in, h, d_out = 64, 1000, 100, 10
# 随机生成输入数据x和目标输出y
x = np.random.randn(n, d_in) # 输入数据,形状为(64, 1000)
y = np.random.randn(n, d_out) # 目标输出,形状为(64, 10)
# 随机初始化权重参数
# 输入层到隐藏层的权重(1000,100)
w1 = np.random.randn(d_in, h)
# 隐藏层到输出层的权重(100,10)
w2 = np.random.randn(h, d_out)
# 设置学习率
learning_rate = 1e-6
# 用于记录每次迭代的loss值
loss_history = []
# 训练500次
for t in range(500):
# 前向传播
temp = x.dot(w1) # 输入层到隐藏层的线性变换
temp_relu = np.maximum(temp, 0) # ReLU激活函数,隐藏层输出
y_pred = temp_relu.dot(w2) # 隐藏层到输出层的线性变换,得到预测值
# 计算损失函数(均方误差和)
loss = np.square(y_pred - y).sum()
loss_history.append(loss) # 记录loss值
print(t, loss)
# 反向传播,计算梯度
grad_y_pred = 2.0 * (y_pred - y) # 损失对预测输出的梯度
#print('grad_y_pred=', grad_y_pred.shape) #(64, 10)
grad_w2 = temp_relu.T.dot(grad_y_pred) # 损失对w2的梯度
grad_temp_relu = grad_y_pred.dot(w2.T) # 损失对隐藏层输出的梯度
grad_temp = grad_temp_relu.copy() # 复制一份用于ReLU处理
grad_temp[temp<0] = 0 # ReLU小于0的部分梯度置零
grad_w1 = x.T.dot(grad_temp) # 损失对w1的梯度
# 更新权重参数
w1 = w1 - learning_rate * grad_w1
w2 = w2 - learning_rate * grad_w2
# 绘制Loss曲线
plt.figure(figsize=(10, 6))
plt.plot(loss_history, 'b-', linewidth=2)
plt.title('训练过程中的Loss变化曲线', fontsize=14)
plt.xlabel('迭代次数', fontsize=12)
plt.ylabel('Loss值', fontsize=12)
plt.grid(True, alpha=0.3)
plt.show()
# 输出最终训练得到的权重参数
print(w1, w2)
# print(w1)
# print(w2) © 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...







![[理论篇-10]AI 工作流(AI Workflow)—— 让 AI 像流水线一样干活](https://www.dunling.com/img/1.jpg)



