

分割——识别哪些图像像素属于一个对象——是计算机视觉的核心任务,用于从分析科学图像到编辑照片的广泛应用。但是,为特定任务创建准确的分割模型一般需要技术专家进行高度专业化的工作,他们可以访问AI 培训基础设施和大量经过仔细注释的域内数据。
今天,我们的目标是通过引入 Segment Anything 项目来使分割民主化:正如我们在研究论文中所解释的那样,这是一种用于图像分割的新任务、数据集和模型。我们正在发布我们的通用Segment Anything 模型 (SAM)和我们的Segment Anything 1-Billion 掩码数据集 (SA-1B),这是有史以来最大的分割数据集,以支持广泛的应用程序并促进对计算机视觉基础模型的进一步研究. 我们正在使 SA-1B 数据集可用于研究目的,并且 Segment Anything Model 在开放许可 (Apache 2.0) 下可用。查看演示以使用您自己的图像尝试 SAM。
减少对特定于任务的建模专业知识、训练计算和用于图像分割的自定义数据注释的需求是 Segment Anything 项目的核心。为了实现这一愿景,我们的目标是建立一个图像分割的基础模型:一个可提示的模型,它在不同的数据上进行训练并且可以适应特定的任务,类似于在自然语言处理模型中使用提示的方式。不过,与互联网上丰富的图像、视频和文本不同,训练这种模型所需的分割数据在网上或其他地方并不容易获得。因此,借助 Segment Anything,我们着手同时开发一个通用的、可提示的分割模型,并使用它来创建一个规模空前的分割数据集。
SAM 已经了解了对象是什么的一般概念,它可以为任何图像或任何视频中的任何对象生成掩码,甚至包括它在训练期间没有遇到的对象和图像类型。SAM 的通用性足以涵盖广泛的用例,并且可以开箱即用地用于新的图像“领域”——无论是水下照片还是细胞显微镜——无需额外培训(这种能力一般被称为零镜头传输) .
将来,SAM 可用于协助需要在任何图像中查找和分割任何对象的众多领域中的应用程序。对于 AI 研究社区和其他人来说,SAM 可以成为更大的 AI 系统的一个组成部分,用于对世界进行更一般的多模态理解,例如,理解网页的视觉和文本内容。在 AR/VR 领域,SAM 可以根据用户的视线选择对象,然后将其“提升”为 3D。对于内容创作者,SAM 可以改善创意应用,例如提取图像区域以进行拼贴或视频编辑。SAM 还可用于协助对地球上什至太空中的自然事件进行科学研究,例如,通过定位动物或物体以在视频中进行研究和跟踪。我们信任可能性是广泛的,Segment Anything 的提示设计支持与其他系统的灵活集成。

SAM 可以接收输入提示,例如来自 AR/VR 耳机的用户注视。
SAM:一种通用的分割方法
以前,要解决任何类型的分割问题,有两类方法。第一种是交互式分割,允许分割任何类别的对象,但需要一个人通过迭代细化掩码来指导该方法。第二种,自动分割,允许分割提前定义的特定对象类别(例如,猫或椅子),但需要大量的手动注释对象来训练(例如,数千甚至数万个分割猫的例子),连同计算资源和技术专长一起训练分割模型。这两种方法都没有提供通用的、全自动的分割方法。
SAM 是这两类方法的概括。它是一个单一的模型,可以轻松地执行交互式分割和自动分割。该模型的可提示界面(稍后描述)允许以灵活的方式使用它,只需为模型设计正确的提示(点击、框、文本等),就可以完成范围广泛的分割任务。此外,SAM 在包含超过 10 亿个掩码(作为该项目的一部分收集)的多样化、高质量数据集上进行训练,这使其能够泛化到新类型的对象和图像,超出其在训练期间观察到的内容。这种概括能力意味着,总的来说,从业者将不再需要收集他们自己的细分数据并为他们的用例微调模型。
总而言之,这些功能使 SAM 能够泛化到新任务和新领域。这种灵活性在图像分割领域尚属首创。
这是一段展示 SAM 部分功能的短片:

(1) SAM 允许用户通过单击或通过交互式单击点来分割对象以包含和排除对象。还可以使用边界框提示模型。
(2) SAM在面对被分割对象的歧义时可以输出多个有效掩码,这是解决现实世界中分割问题的重大且必要的能力。
(3) SAM 可以自动发现并屏蔽图像中的所有对象。
(4) SAM 可以在预计算图像嵌入后实时为任何提示生成分割掩码,允许与模型进行实时交互。
SAM 的工作原理:即时分割
在自然语言处理和最近的计算机视觉领域,最令人兴奋的发展之一是基础模型的发展,这些基础模型可以使用“提示”技术对新数据集和任务执行零样本和少样本学习。我们从这行工作中汲取了灵感。
我们训练 SAM 为任何提示返回有效的分割掩码,其中提示可以是前景/背景点、粗框或掩码、自由格式文本,或者一般来说,指示图像中要分割的内容的任何信息。有效掩码的要求仅仅意味着即使提示不明确并且可能指代多个对象(例如,衬衫上的一个点可能表明衬衫或穿着它的人),输出也应该是一个合理的掩码这些对象之一。此任务用于预训练模型并通过提示解决一般的下游分割任务。
我们观察到预训练任务和交互式数据收集对模型设计施加了特定的约束。特别是,该模型需要在 Web 浏览器的 CPU 上实时运行,以允许我们的注释者实时交互地使用 SAM 以高效地进行注释。虽然运行时约束意味着质量和运行时之间的权衡,但我们发现简单的设计在实践中会产生良好的结果。
在引擎盖下,图像编码器为图像生成一次性嵌入,而轻量级编码器将任何提示实时转换为嵌入向量。然后将这两个信息源组合在一个预测分割掩码的轻量级解码器中。在计算图像嵌入后,SAM 可以在 50 毫秒内根据网络浏览器中的任何提示生成一个片段。
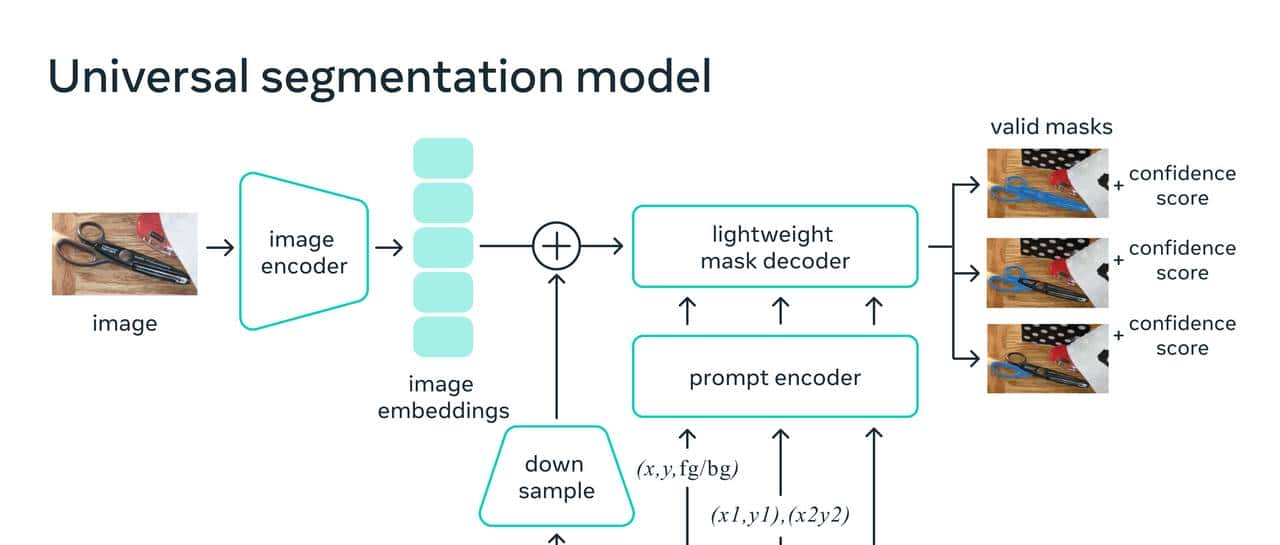
在 Web 浏览器中,SAM 有效地映射图像特征和一组提示嵌入以生成分割掩码。
分割 10 亿个口罩:我们如何构建 SA-1B
为了训练我们的模型,我们需要大量多样的数据源,这在我们工作开始时并不存在。我们今天发布的分割数据集是迄今为止(迄今为止)最大的。使用 SAM 收集数据。特别是,标注者使用 SAM 交互式地标注图像,然后使用新标注的数据依次更新 SAM。我们多次重复此循环以迭代改善模型和数据集。
使用 SAM,收集新的分割掩码比以往任何时候都快。使用我们的工具,只需大约 14 秒就可以交互式地注释掩码。我们的每个掩码注释过程仅比注释边界框慢 2 倍,使用最快的注释接口大约需要 7 秒。与之前的大规模分割数据收集工作相比,我们的模型比 COCO 全手动基于多边形的掩码注释快 6.5 倍,比之前最大的数据注释工作快 2 倍,后者也是模型辅助的。
不过,依靠交互式注释掩码并不能充分扩展来创建我们的 10 亿掩码数据集。因此,我们构建了一个数据引擎来创建我们的 SA-1B 数据集。该数据引擎具有三个“齿轮”。在第一档中,模型协助注释器,如上所述。第二档是全自动标注与辅助标注相结合,有助于增加收集口罩的多样性。数据引擎的最后一个齿轮是全自动掩码创建,允许我们的数据集扩展。
我们的最终数据集包括在大约 1100 万张许可和隐私保护图像上收集的超过 11 亿个分割掩码。SA-1B 的掩码比任何现有的分割数据集多 400 倍,并且经人工评估研究证实,这些掩码具有高质量和多样性,在某些情况下甚至在质量上可与之前更小、完全手动注释的数据集的掩码相媲美.
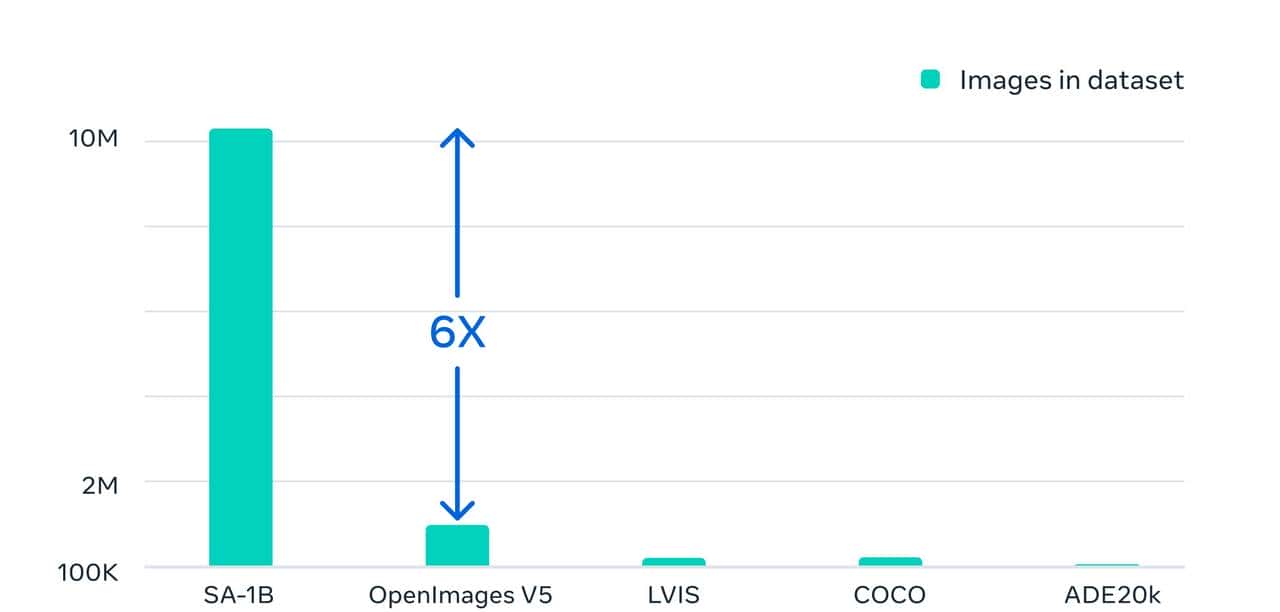
Segment Anything 的功能是对使用数据引擎收集的数百万张图像和掩码进行训练的结果。
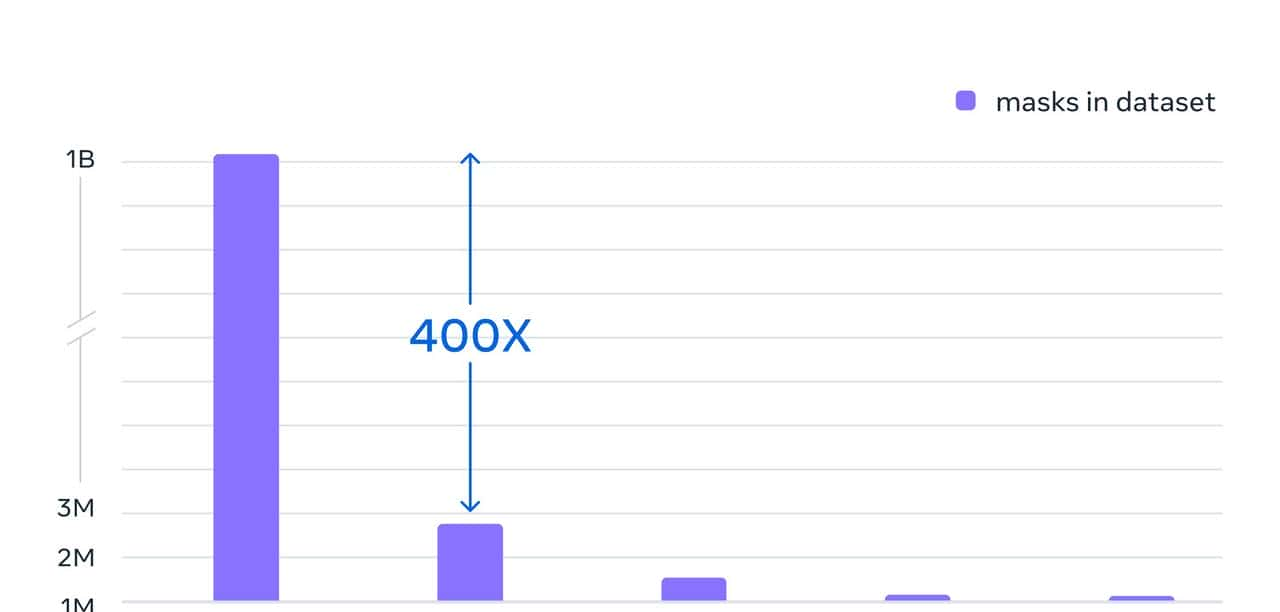
结果是一个包含超过 10 亿个分割掩码的数据集——比之前的任何分割数据集大 400 倍。
SA-1B 的图像来自多个国家/地区的照片提供商,这些国家/地区跨越不同的地理区域和收入水平。虽然我们认识到某些地理区域的代表性依旧不足,但与以前的分割数据集相比,SA-1B 拥有更多的图像,并且在所有地区的总体代表性更好。此外,我们分析了我们的模型在感知性别表现、感知肤色和感知年龄范围方面的潜在偏差,我们发现 SAM 在不同群体中的表现类似。我们希望这将使我们的工作更加公平地用于现实世界的用例。
虽然 SA-1B 使我们的研究成为可能,但它也可以让其他研究人员能够训练图像分割的基础模型。我们进一步希望这些数据可以成为带有附加注释的新数据集的基础,例如与每个面具相关的文本描述。

未来,SAM 可用于通过 AR 眼镜识别日常物品,向用户提示提醒和指示。

SAM 有可能影响广泛的领域——也许有一天会协助农业部门的农民或协助生物学家进行研究。
通过共享我们的研究和数据集,我们希望进一步加速对分割和更一般的图像和视频理解的研究。我们的可提示分割模型可以通过充当更大系统中的组件来执行分割任务。组合是一个强劲的工具,允许以可扩展的方式使用单个模型,有可能完成模型设计时未知的任务。我们预计,由提示工程等技术实现的可组合系统设计将比专门为一组固定任务训练的系统能够实现更广泛的应用程序,并且 SAM 可以成为 AR/VR、内容等领域的强劲组件创造、科学领域和更通用的人工智能系统。
附论文地址:
https://arxiv.org/pdf/2304.02643.pdf
github地址:
https://github.com/facebookresearch/segment-anything
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...









