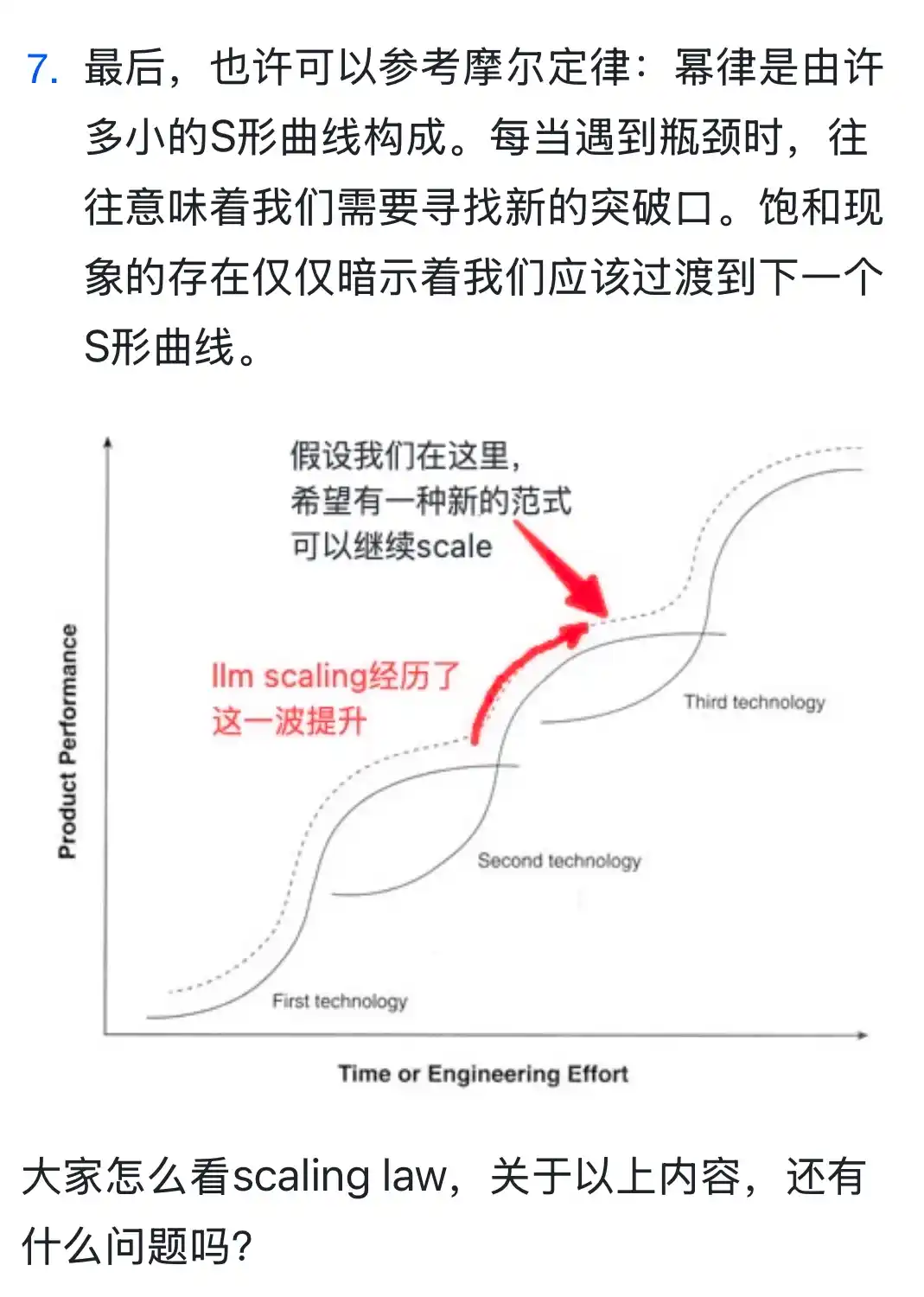
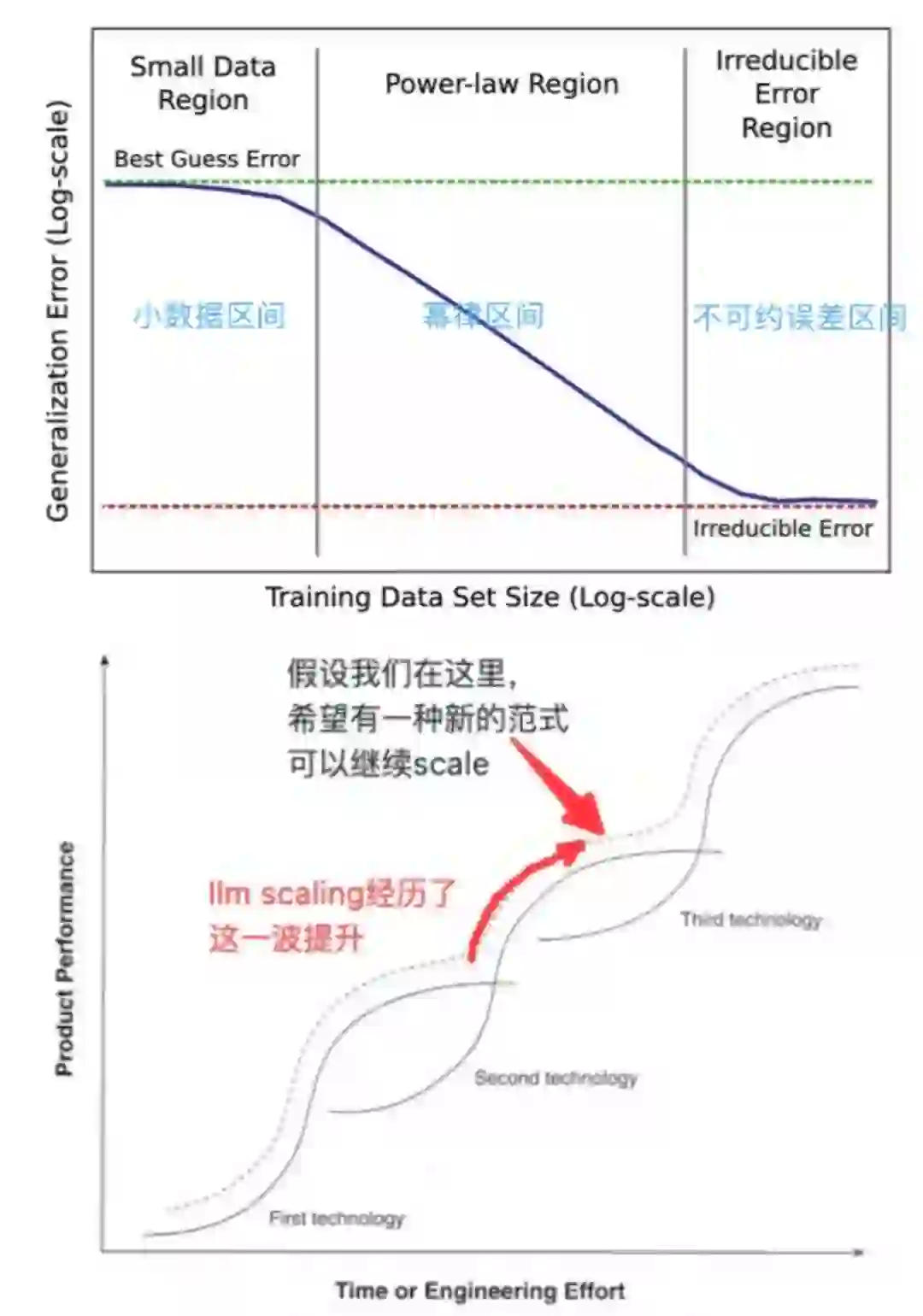
自从大模型火起来,Scaling law这个词就不绝于耳。scaling law指的是随着模型规模、训练数据和算力的增长,语言模型的性能会按照可预测的幂律关系提升。 正好看到meta前具身智能负责人Dhruv Batra关于Scaling的重复饱和现象的精彩见解。 我们也为大家带来关于Scaling law的解读,写的挺好的




 自从大模型火起来,Scaling law这个词就不绝于耳。scaling law指的是随着模型规模、训练数据和算力的增长,语言模型的性能会按照可预测的幂律关系提升。
自从大模型火起来,Scaling law这个词就不绝于耳。scaling law指的是随着模型规模、训练数据和算力的增长,语言模型的性能会按照可预测的幂律关系提升。









谢谢。还是有认真读的
都觉得互联网上数据许多,实则上互联网上的数据bias超级大,许多日常人感官接受到的信息是互联网上没有的
看了这篇论述,感觉像是在读AI的致青春,从模型小白到大佬,简直是AI界的逆袭传奇!📈🤖🌟