
本头条号专栏
欢迎加入人工智能学习圈子,可以领取相关资料
(此处已添加圈子卡片,请到今日头条客户端查看)
专栏
每天五分钟快速玩转深度学习算法
作者:幻风的AI之路
26.6币
612人已购
查看

专栏
每天5分钟快速玩转机器学习算法
作者:幻风的AI之路
56.88币
1,794人已购
查看
正文
本文将介绍一个超级基础的机器学习算法,这个算法叫做KNN,KNN算法是一个分类算法,它归于实例学习(instance-based learning)和懒惰学习(lazy learning),它的原理很简单:
为了判断未知实例的类别,以所有已知实例类别作为参考我们可以选择参数K,计算未知实例与所有已知实例距离(Euclidean Distance欧式距离、余弦值、相关度、曼哈顿距离(街区))
选择最近K个已知实例,在这K个实例中可能多种类别,我们遵循少数服从多数的原则,让未知实例归类为K个最近临近样本中最多数的类别

欧式距离
我们目前有这样的一个数据集

它的x坐标表明武打程度,y坐标表明爱情程度,根据这两个特征我们可以得出这部电影的类型,有两个类型一个是爱情成都,一个是动作程度。
目前我们有一个未知的样本:

我们要预测这个未知样本的准确度,我们的方法就是,用这个样本和所有的已知样本计算距离,然后找出K个最近的点,这K个最近的样本中哪个类别,这个G点就表明哪个类别
KNN算法的优缺点
优点:算法简单易于实现,而且通过对K的选择可具备丢噪音数据的健壮性,列如:
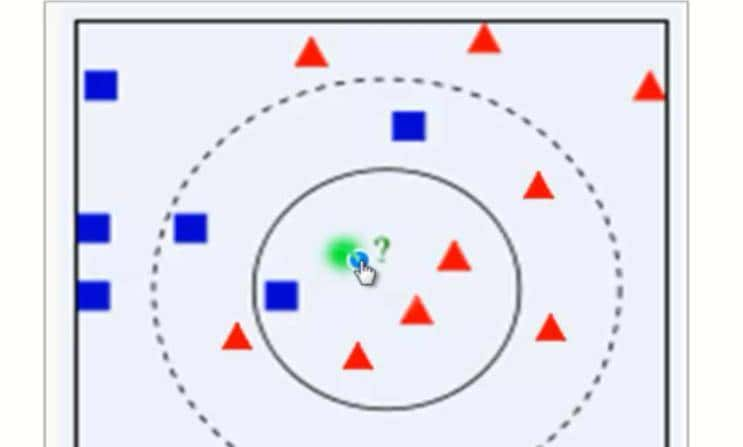
该图中,您认为这个未知样本?是什么类型的,实则我们一看就应该认为它是红三角的,由于它距离红三角比较近,但是这有一个问题就是,如果我们设置K=1,那么此时的未知样本?就被认为是蓝方块。这就是蓝色方块噪音对我们的影响。所以我们可以通过增加K,来达到去除噪音的作用,我们可以设置K=4,那么算法就会认为未知样本是红三角了,这就是增加K达到去噪的作用,这是KNN算法的优点
KNN算法的缺点:第一它需要大量的空间存储
算法复杂度高,需要将未知实例和所有的已知实例进行比较
当一类样本数量过大占主导地位的时候,K也设为很大的时候,新的未知实例容易被归类为这个主导样本,但有可能这个未知实例并不接近这个最多的样本类别,它可能更接近其它类别(为了解决这个问题,根据样本设置权重,列如权重为1/d(d为距离),距离越近权重越大。
KNN代码

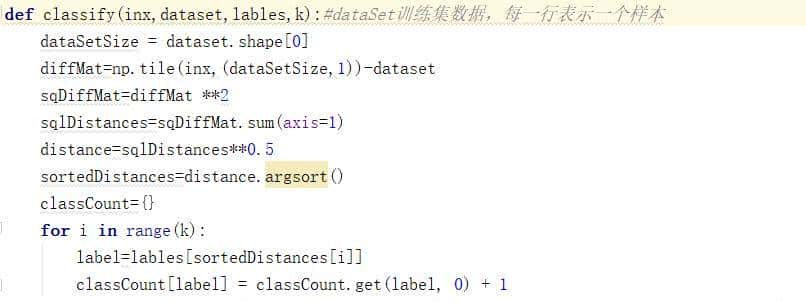
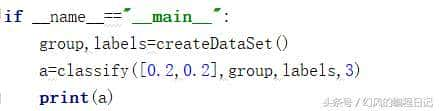
这个就是KNN的算法,createDataSet()是手动创建我们的数据集,该方法返回group样本和lables标注
我们有了训练集之后,我们就可以通过classify方法来对我们的未知样本[0.2,0.2]来进行分类,我们需要传递给该方法group和labels和K
我们来分析一下classify方法
dataset是我们的数据它是一个矩阵,dataset.shape[0]表明矩阵的行数,每一行表明一个样本
tile:numpy中的函数。tile将原来的一个数组inx,扩充成了dataSetSize个一样的数组,也就是矩阵。
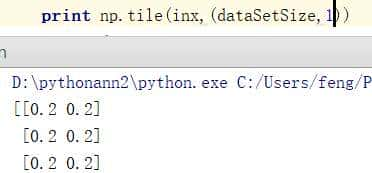
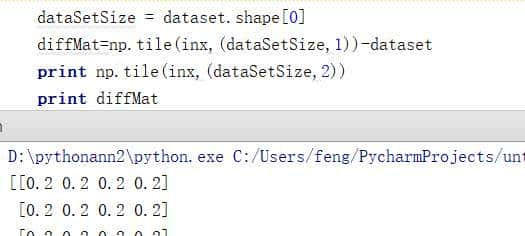
通过这两幅图就应该知道了tile的用法了,我们然后用它减去dataset,每一行对应相减,得到的结果是未知样本与所有训练样本之间的差值diffMat

上面代码是求出每个样本与未知样本之间的欧式距离,distance依然是一个矩阵,每一行表明已经样本与未知样本之间的欧式距离。
数组排序(小到大):列排列np.msort(a),行排列np.sort(a),np.argsort(a)排序(升序排列)后返回下标
输出sortedDistances的结果为:

这个表明我们sqDiffMat矩阵中欧式距离最小的为索引3也就是第四行,然后第三行,然后第二行,然后第一行
那么欧式距离的排序就出来,下面我们要找到前K个最小的,方法就是遍历K次,sortedDistances里前K个索引就是我们所需要的欧式距离最小的样本索引的
sortedDistances[i]拿到索引
lables[sortedDistances[i]]拿到索引对应的标注,也就是类型A,B
我们要统计是A多还是B多,哪个多就表明未知样本是哪一类
classCount[label] = classCount.get(label, 0) + 1
这个代码是这个意思,classCount表明一个字典,在字典中获取label建,如果没有则赋值为0,如果有则在此基础上加1

实则我们目前可以看出来了就是在未知样本的K(3)个周围中A占有1个,B占有2个,所以这个未知样本是B类
sortClassCount =sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)排序,reverse从大到小来排序

classCount.iteritems是将字典类型转成列表[('A', 1), ('B', 2)],由于sort中只能排序列表或者迭代器,key的参数为一个函数或者lambda函数,而operator.itemgetter(1)表明的不是一个值,而是一个函数所以它能赋值给key,operator.itemgetter(1)表明根据第二个域进行排序,第二个域就是2,1。然后排序为从大到小,由于reverse=True
sorted函数也可以进行多级排序,例如要根据第二个域和第三个域进行排序,可以这么写:
sorted(students, key=operator.itemgetter(1,2))
最后我们输出sortClassCount,结果为:[('B', 2), ('A', 1)],而sortClassCount[0][0]就是B,就是我们想要的未知样本的类别了。
以上代码是在python2中运行的,但是在3中会出问题

改成这个3版本就能运行了,缘由是Python 3.x 里面,iteritems() 和 viewitems() 这两个方法都已经废除了,而 items() 得到的结果是和 2.x 里面 viewitems() 一致的。在3.x 里 用 items()替换iteritems() ,可以用于 for 来循环遍历。
我们还可以拿已经封装好的sklearn库中的KNN来完成KNN算法
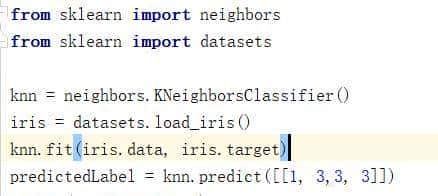
这里我们使用的鸢尾花数据集,它在python中自带的数据集。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










