最近为了写一个同步程序,由于odbc需要额外下载使用,于是选择了pymssql来进行数据库连接。
最后发现同步过去的数据,只要是varchar类型的字段,都出现乱码,于是按照网上的解决方案来,发现依旧出现这种情况:×ÓÉ豸:ÒüÈý˳£ºµç±í
于是,我查看了我的源码:
获取结果并处理编码(解决中文乱码)
results = []
for row in cursor.fetchall():
processed_row = {}
for key, value in row.items():
# 若字段是bytes类型(非Unicode),用GBK解码为字符串
if isinstance(value, bytes):
processed_row[key] = value.decode(SQLSERVER_CONFIG['charset'], errors='replace')
else:
processed_row[key] = value # 其他类型(数字、日期等)直接保留
results.append(processed_row)发现这一步并没有执行:
if isinstance(value, bytes):
processed_row[key] = value.decode(SQLSERVER_CONFIG['charset'], errors='replace')什么意思呢?就是字符集并没有匹配上,差了该数据的字符集,输出如下:
--------------------------------------------------
字段名:order_number 类型:未知类型(代码:1)
字段名:order_type 类型:未知类型(代码:3)
字段名:amount 类型:smallint
字段名:equipment_code 类型:未知类型(代码:1)
字段名:order_type_desc 类型:未知类型(代码:1)
字段名:equipment_number 类型:未知类型(代码:3)
字段名:univalent 类型:smallint
字段名:pre_number 类型:未知类型(代码:3)
字段名:balance 类型:smallint
字段名:creation_time 类型:int
字段名:remark 类型:未知类型(代码:1)
字段名:create_time 类型:int
字段名:s1 类型:未知类型(代码:3)
字段名:s2 类型:未知类型(代码:3)
--------------------------------------------------原来根本没有识别出该字段的字段类型,于是我做出以下改动:
# 处理数据映射(根据字段类型代码进行解码)
target_fields = list(task.field_mapping.keys())
data_to_insert = []
for row in source_data:
row_data = []
for field in target_fields:
source_field = task.field_mapping[field]
value = row[source_field]
field_type = field_type_map.get(source_field, 0)
# 根据字段类型代码进行针对性解码
if field_type in (1, 3): # 处理未知类型代码1和3
if isinstance(value, bytes):
# 类型代码1: 尝试GBK解码(适用于varchar/char)
if field_type == 1:
value = value.decode('gbk', errors='replace')
# 类型代码3: 尝试UTF-16LE解码(适用于nvarchar/nchar)
elif field_type == 3:
value = value.decode('utf-16le', errors='replace')
elif isinstance(value, str):
# 已为字符串但可能存在编码问题,尝试重新编码转换
value = value.encode('latin-1', errors='replace').decode('gbk', errors='replace')
# 数值类型保持原样(smallint/int等)
row_data.append(value)
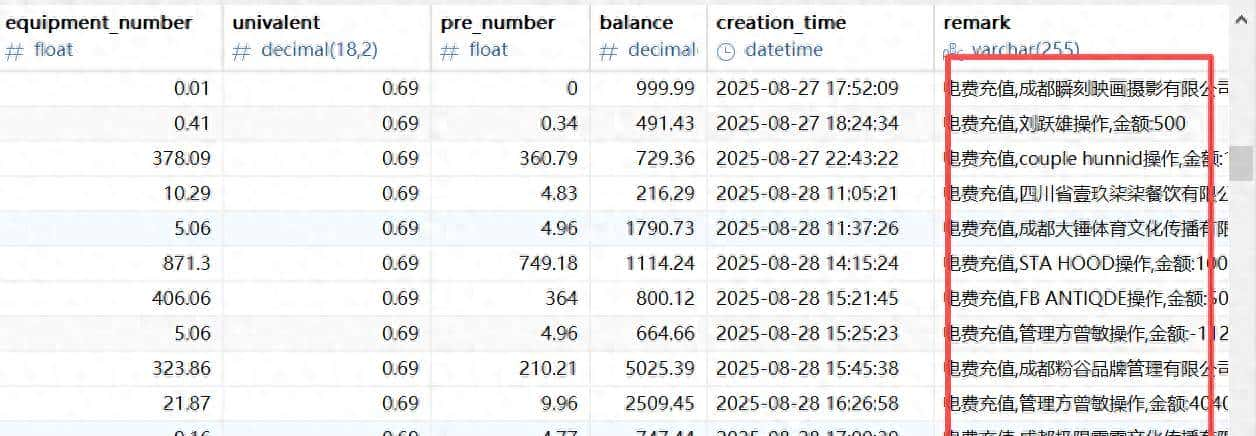
data_to_insert.append(tuple(row_data))更改后输出数据就正常了:
© 版权声明
文章版权归作者所有,未经允许请勿转载。











👍🌹
谢谢肯发
肯定