对于运维来说,业务故障是无法避免的,所以故障排查是一个运维的必备技能,有完善的排查思路可以快速定位问题。
今天分享一下业务无法访问的排查方法。
对于运维来说,业务故障是无法避免的,所以故障排查是一个运维的必备技能,有完善的排查思路可以快速定位问题,下面我整理了一些个人经验,主要从5个方向展开讲解,希望能协助到你。
1. 先确认问题范围
排查前别急着开命令,先问清楚:
- 影响范围:是单个用户?某个地区?还是全量业务?
- 业务范围:全站都挂?还是某个模块、某个接口?
- 时间规律:持续性还是间歇性?
- 技巧:越早圈定问题范围,定位就越快。
2. 分层排查思路
主要排查点:网络策略→ 系统 → 应用 → 数据库 → 外部依赖 → 安全设备
逐层排查,才能不遗漏。
(1) 网络层:先看“通不通”
主要使用ping,traceroute,telnet,curl等命令。
# 测试服务器是否能通,ping域名或IP
ping -c 4 10.0.0.110
ping www.ligelinux.com
# 路由追踪,看看卡在哪一跳
traceroute 10.0.0.110
# 测试端口连通性
telnet 10.0.0.110 8089
# HTTP接口连通性
curl -I http://www.ligelinux.com常见问题:网络策略变动,路由抖动、运营商网络波动、防火墙规则更新。
(2) 系统层:资源够不够
# 查看CPU、内存、负载情况,资源是否充足
top
uptime
free -h
# 查看磁盘使用情况
df -h
du -sh /data/*
# 系统日志
journalctl -xe
tail -n 200 /var/log/messages常见问题:CPU打满、内存不足、磁盘满导致服务无响应。
(3) 应用层:服务是否正常
服务不正常一般会出现503错误

可以通过排查服务进程,端口和日志等信息
# 查看服务状态,列如的nginx,排查时更换成你的服务就行
systemctl status nginx
ps -ef | grep 服务名字
# 检查端口监听
ss -tulnp | grep 端口
# 查看应用日志
tail -f /var/log/xxx.log
# 本地检查应用是否正常
curl -v http://localhost:your-port/health常见问题:进程挂掉、端口没监听、依赖服务未启动。
(4) 数据层:库和缓存撑不住
主要检查数据库是否正常。连不上一般会在日志里报错
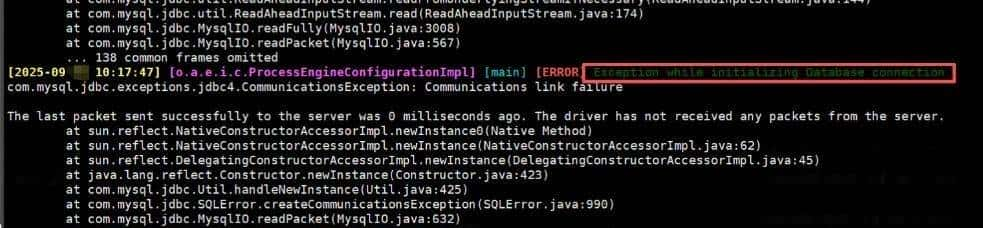
主要排查数据库是否正常:
# MySQL是否能连
mysql -uroot -p
# MySQL是否卡锁
mysql -e "show full processlist;"
# Redis连通性
redis-cli -h redis-host ping
# Redis慢日志
redis-cli -h redis-host slowlog get 10常见问题:数据库连接数爆满、慢查询、Redis阻塞。
(5) 外部依赖
有些系统会调用外部接口,也有可能是外部应用出问题了。
# 测试外部API健康性
curl -I https://xxx.com/health
# DNS解析
nslookup xxx.com
dig xxx.com
# CDN是否正常
curl -v https://xxx.com | grep -i "cache"常见问题:第三方接口超时、DNS劫持、CDN缓存异常。
(6) 安全设备层:别忽略“拦路虎”
许多时候,业务并不是挂了,而是被 安全设备拦截,一般是出现403字样。
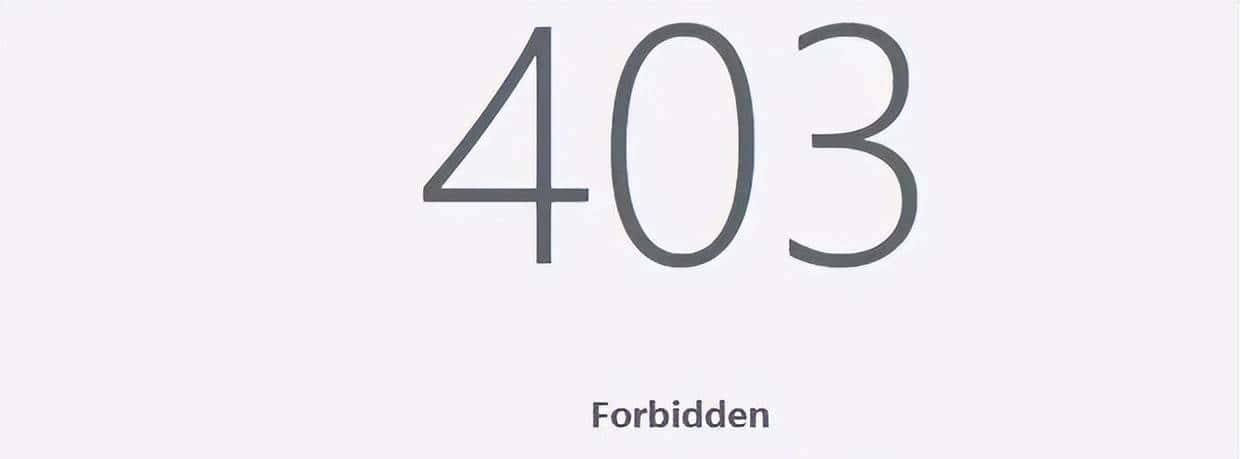
这种情况一般是触发了安全设备拦截规则,这时就要找安全团队看看安全设备是否有拦截记录。
- WAF(Web应用防火墙):拦截了特定请求,列如带有敏感参数或 SQL 关键字。
- 防火墙/安全组:有时候策略更新导致流量被拦截。
iptables -L -n -v
firewall-cmd --list-all- IDS/IPS(入侵检测/防御系统):突然发现请求量大,被判定为攻击流量。 提议与安全团队对接,确认是否有误拦。
常见问题:安全策略过严、误拦合法流量、规则变更未通知。可以通过加白解决。
3. 排查信息收集清单
排查时必须收集以下信息:
- 用户报错截图
- 相关服务日志
- 系统指标:CPU、内存、磁盘、网络
- 应用指标:进程,端口,日志
- 外部依赖状态
- 安全设备:WAF拦截,FW策略,IPS日志
信息齐全,排查效率提升 3 倍以上。
4. 复盘与预防
排查只是第一步,问题解决后一般会做下面的事情:
- 缘由复盘:是配置、流量、资源,还是安全设备?
- 监控优化:关键指标全链路监控,异常提前预警。
- 自动化排查:脚本化常用检测命令,一键定位问题。
- 知识沉淀:把排查经验写成 SOP,让团队少踩坑。
业务不可访问时,真正考验的不是你会多少命令,而是有没有 完整的排查思路。
只要照着 网络 → 系统 → 应用 → 数据 → 外部依赖 → 安全设备 这一链路去走,信息收集全面,就能快速找到根因。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...