
目录
前言:为什么你需要一套完整的监控系统
- 系统架构概览(附图)
- 组件介绍与职责分工
- 核心部署流程
- 监控指标分类与采集方案
- 告警规则与多通道通知
- 数据持久化与长期存储(Thanos)
- 可视化展示:Grafana 实例图
- 优化提议与常见问题处理
- 总结与展望
一、前言:为什么你需要一套完整的监控系统
- 当前运维与业务需求的变化
- 分布式架构下的可观测性挑战
- Prometheus 全家桶在社区与企业的广泛应用


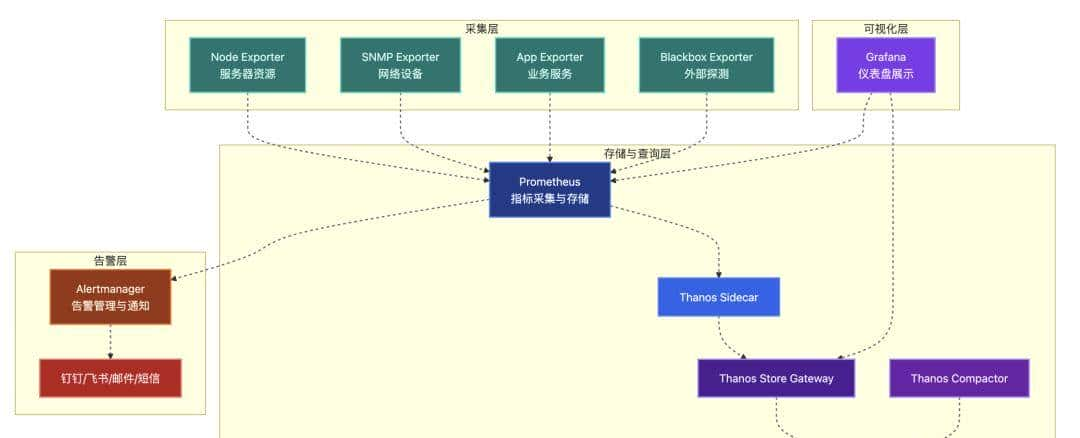
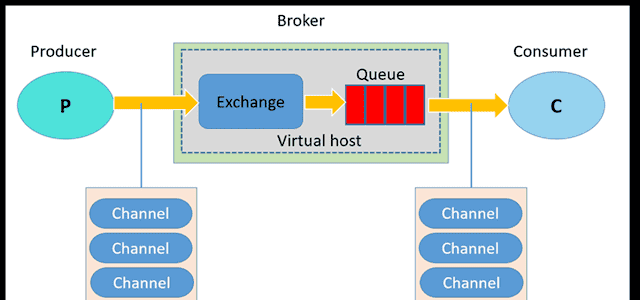
二、系统架构概览
- 核心理念:采集 → 存储 → 告警 → 可视化
- 各组件的协作关系说明
三、组件介绍与职责分工
|
组件 |
职责说明 |
|
Prometheus |
指标采集与规则引擎 |
|
Exporter |
将系统、服务、硬件等暴露为指标 |
|
Alertmanager |
告警聚合、抑制与路由 |
|
Thanos |
长期存储、跨 Prometheus 查询能力 |
|
Grafana |
可视化与数据洞察 |
四、核心部署流程
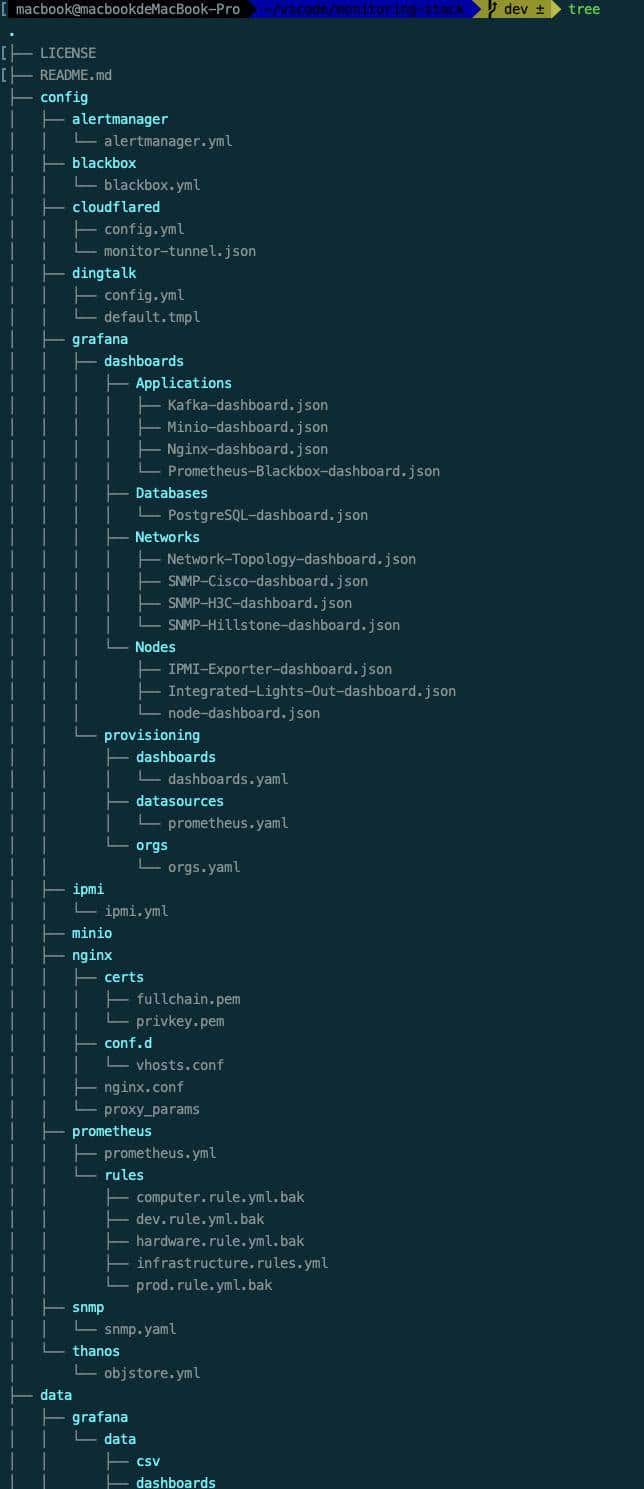
- 使用 Docker Compose 快速部署
- 持久化数据目录挂载说明
- 各组件之间网络连接说明
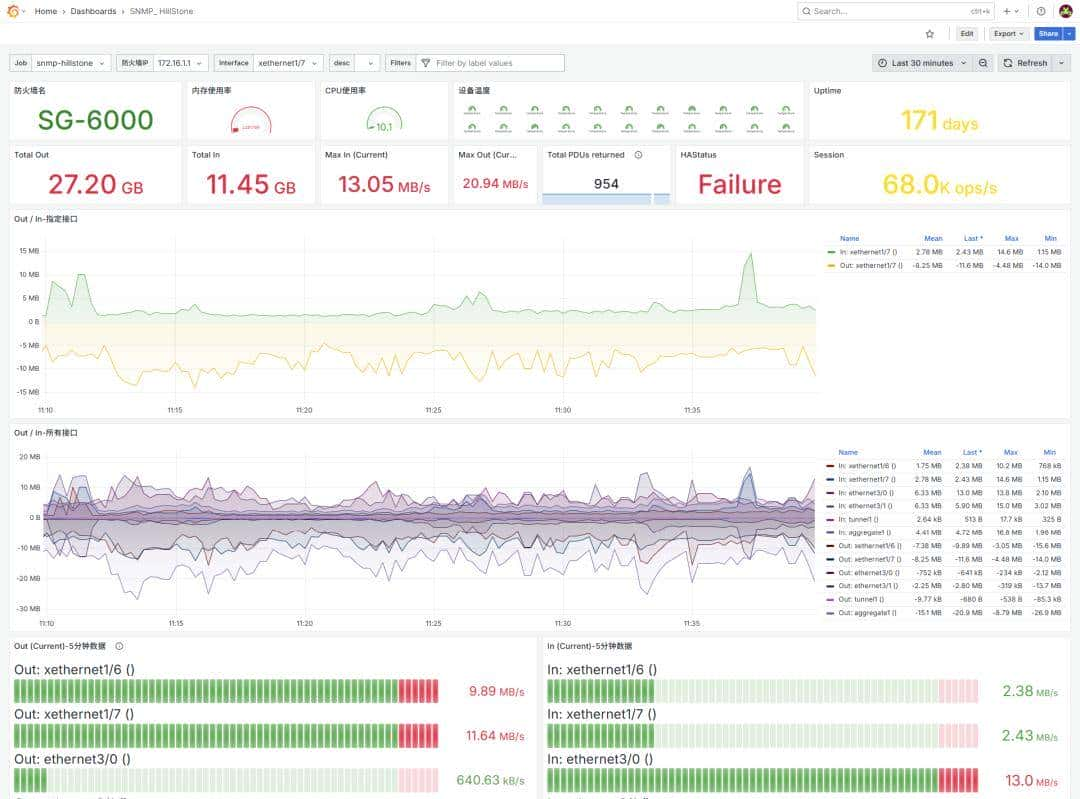
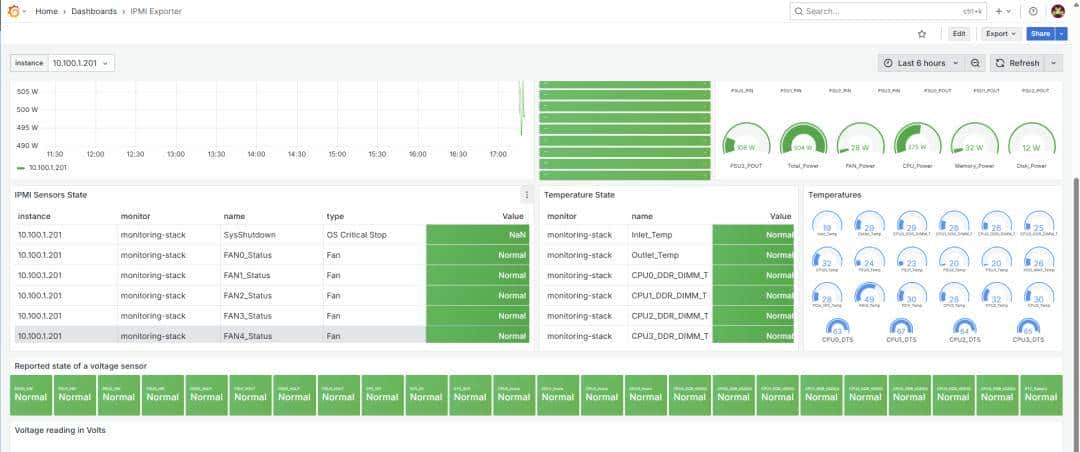
五、监控指标分类与采集方案
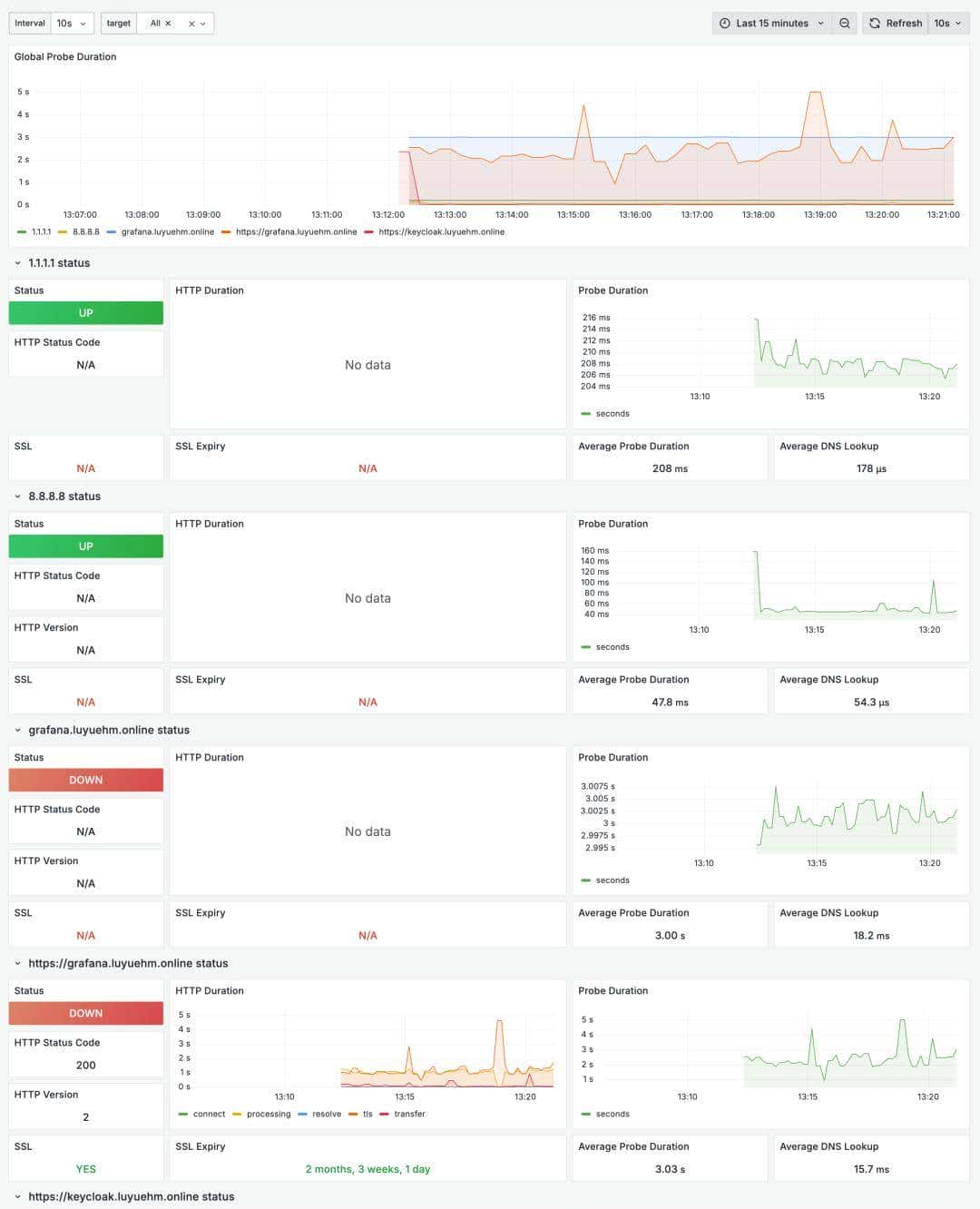
- 服务器资源指标(Node Exporter)
- 网络设备指标(SNMP Exporter)
- 应用监控(Blackbox、MySQL、Kafka 等 Exporter)
- 自定义业务指标上报
六、告警规则与多通道通知
- Prometheus Alert 规则语法示例
- Alertmanager 通知路由设计
- 支持钉钉 / 飞书 / 邮件 / 短信通道的集成方式


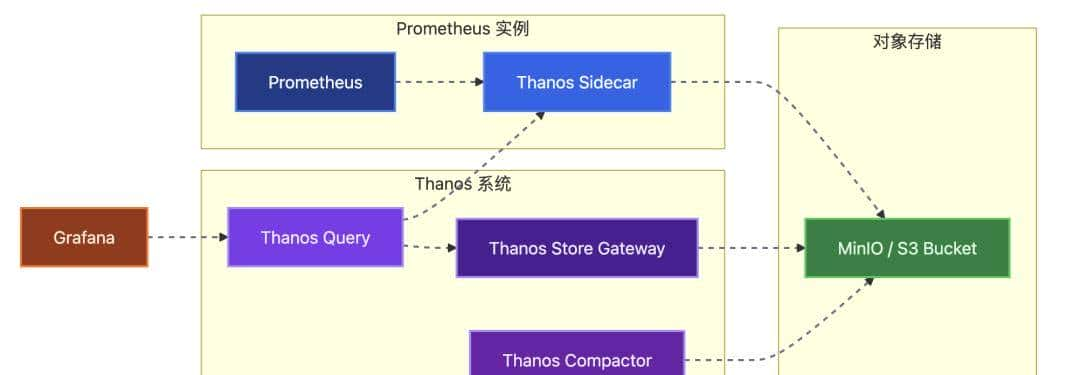
七、数据持久化与长期存储(Thanos)
- 为什么要使用 Thanos
- Sidecar + Store Gateway + Compactor 的作用
- MinIO / S3 作为后端存储的配置示例
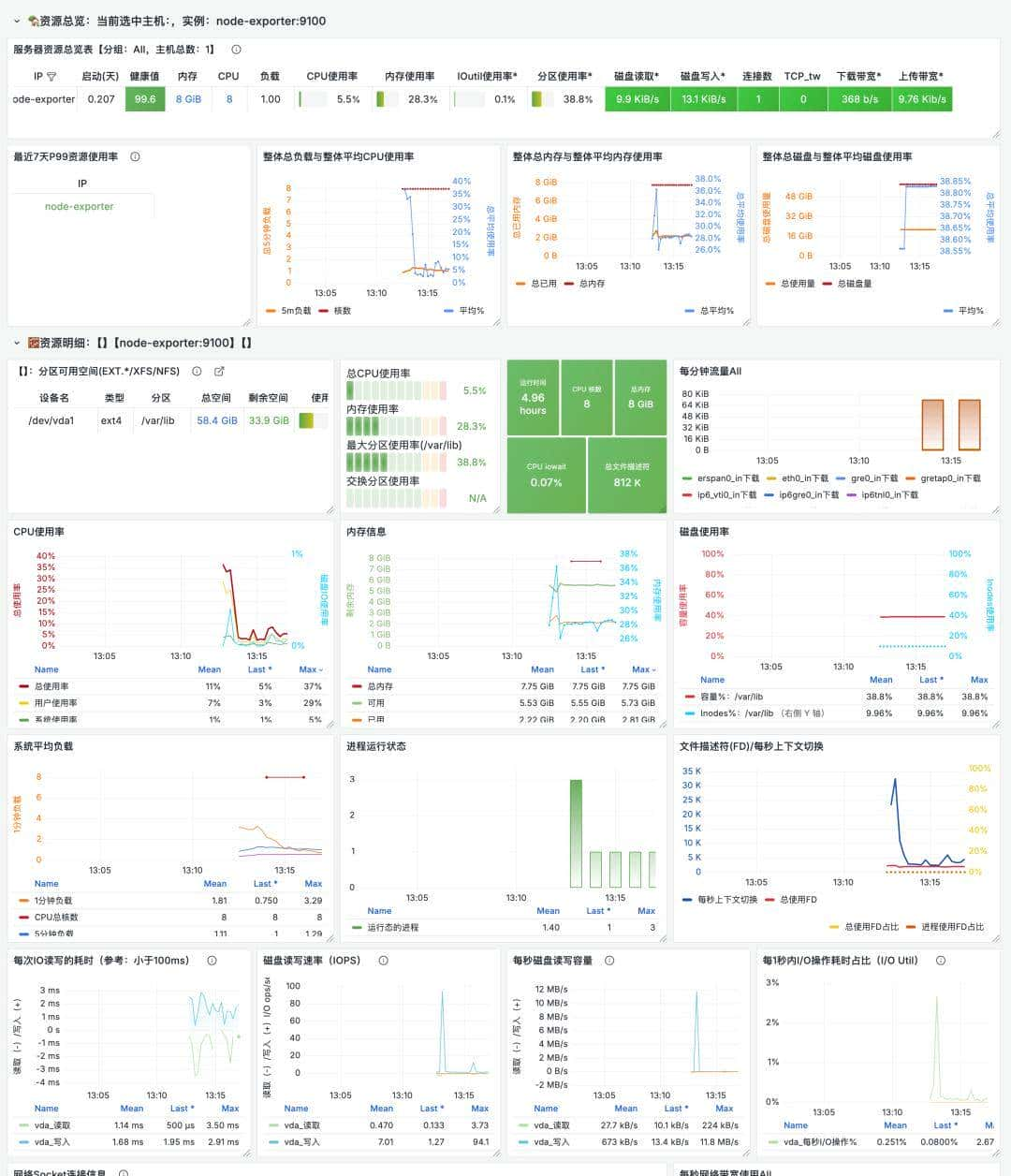
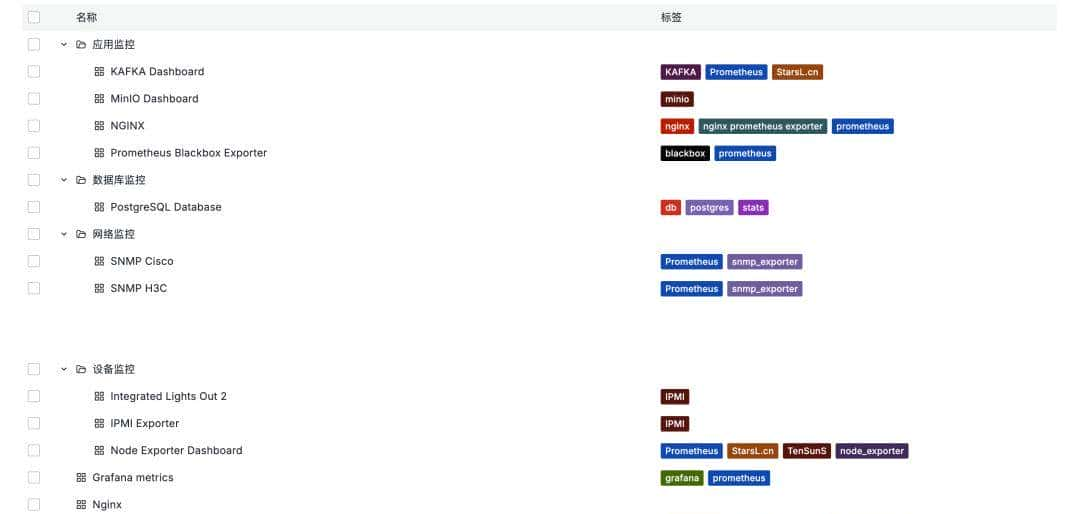
八、可视化展示:Grafana 实例图
- 多数据源整合
- 仪表盘设计与分享
- 结合业务场景构建监控大屏
九、优化提议与常见问题处理
- 如何防止告警风暴
- 如何减少指标写入压力
- exporter 与被监控组件的性能影响评估
- 如何处理时间序列爆炸问题
十、总结与展望
- 统一监控平台对提升运维效率的重大性
- Prometheus 生态仍在快速演进
- 后续方向:自动化治理 / 可观测性平台统一(如 OpenTelemetry)
Tips:开箱即用,了解更多欢迎关注收藏+私信。
© 版权声明
文章版权归作者所有,未经允许请勿转载。





![[官网]用友好会计财务软件「免费试用」畅捷通好会计2025云财务软件](https://www.dunling.com/favicon/h.chanjet.com.png)





![[LaTeX] VScode+SumatraPDF 配置正反向索引](https://www.dunling.com/img/3.jpg)


这个和grafana哪个好
grafana做大盘展示,prometheus做数据采集,thanos做长期数据存储,alermanager做告警推送,各有分工协同工作
帅哥在哪里领取
监控告警 好文
收藏了,感谢分享