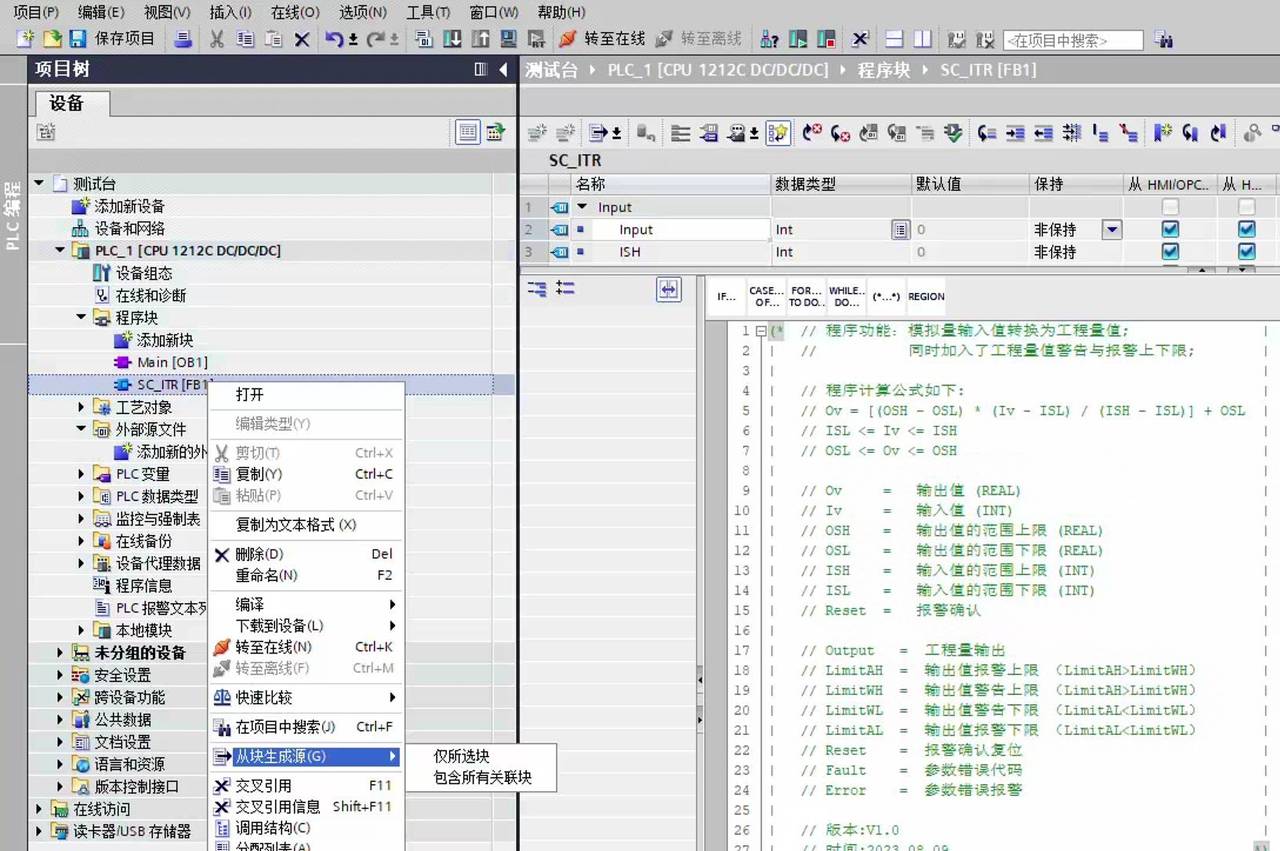
openEuler k8s 集群安装完成,有pod启动失败:
# rpm -qa |grep docker
docker-engine-18.09.0-306.oe2203.x86_64
# rpm -qa | grep kube
kubelet-1.20.10-0.x86_64
kubectl-1.20.10-0.x86_64
kubeadm-1.20.10-0.x86_64
kubernetes-cni-0.8.7-0.x86_64
# cat /etc/openEuler-release
openEuler release 22.03 LTS
# uname -a
Linux zyy-ingress01 5.10.0-60.18.0.50.oe2203.x86_64 #1 SMP Wed Mar 30 03:12:24 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-954bbc69d-gmgq9 0/1 ContainerCreating 0 3m57s
kube-system coredns-954bbc69d-hngnz 0/1 ContainerCreating 0 3m57s
kube-system etcd-zyy-node01 1/1 Running 0 4m10s
kube-system etcd-zyy-node02 1/1 Running 0 3m31s
kube-system etcd-zyy-node03 1/1 Running 0 78s
kube-system heapster-5d689fcfc8-fm8tz 0/1 ContainerCreating 0 104s
kube-system kube-apiserver-zyy-node01 1/1 Running 0 4m10s
kube-system kube-apiserver-zyy-node02 1/1 Running 0 3m36s
kube-system kube-apiserver-zyy-node03 1/1 Running 1 80s
kube-system kube-controller-manager-zyy-node01 1/1 Running 1 4m10s
kube-system kube-controller-manager-zyy-node02 1/1 Running 0 3m35s
kube-system kube-controller-manager-zyy-node03 1/1 Running 0 113s
kube-system kube-flannel-ds-amd64-28bvv 0/1 RunContainerError 4 108s
kube-system kube-flannel-ds-amd64-4tfvl 0/1 RunContainerError 4 108s
kube-system kube-flannel-ds-amd64-8bz2b 0/1 RunContainerError 4 108s
kube-system kube-flannel-ds-amd64-8xj8d 0/1 RunContainerError 4 108s
kube-system kube-flannel-ds-amd64-9hplx 0/1 CrashLoopBackOff 4 108s
kube-system kube-flannel-ds-amd64-jwwt9 0/1 RunContainerError 4 108s
kube-system kube-flannel-ds-amd64-m2brh 0/1 RunContainerError 4 108s
kube-system kube-flannel-ds-amd64-vhcf4 0/1 CrashLoopBackOff 4 108s
kube-system kube-flannel-ds-amd64-zbzf8 0/1 RunContainerError 4 108s
kubectl describe pod kube-flannel-ds-amd64-28bvv -n kube-system
Name: kube-flannel-ds-amd64-28bvv
Namespace: kube-system
Controlled By: DaemonSet/kube-flannel-ds-amd64
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 3m24s default-scheduler Successfully assigned kube-system/kube-flannel-ds-amd64-28bvv to zyy-ingress02
Normal Pulled 3m24s kubelet Container image "privatehb.yunzhijia.com/k8s/flannel:v0.11.0-amd64" already present on machine
Normal Created 3m24s kubelet Created container install-cni
Normal Started 3m24s kubelet Started container install-cni
Normal Pulled 119s (x5 over 3m24s) kubelet Container image "privatehb.yunzhijia.com/k8s/flannel:v0.11.0-amd64" already present on machine
Normal Created 118s (x5 over 3m24s) kubelet Created container kube-flannel
Warning Failed 118s (x5 over 3m23s) kubelet Error: failed to start container "kube-flannel": Error response from daemon: OCI runtime create failed: container_linux.go:330: starting container process caused "process_linux.go:284: applying cgroup configuration for process caused "No such device or address"": unk nown
Warning BackOff 92s (x7 over 2m59s) kubelet Back-off restarting failed container
根据提供的错误信息,kube-flannel-ds-amd64 Pod 因 OCI runtime create failed 和 cgroup 配置问题无法启动。结合搜索结果,以下是可能的缘由和解决方案:
1. Cgroup 驱动不兼容
错误中提到的 applying cgroup configuration for process caused "No such device or address" 一般与 Docker/Kubernetes 的 Cgroup 驱动设置冲突有关:
-
缘由:如果 Docker 使用
systemd作为 Cgroup 驱动,而 Kubernetes 默认使用cgroupfs,可能导致冲突 。 -
解决方案:
- 修改 Docker 配置(
/etc/docker/daemon.json),移除或注释"exec-opts": ["native.cgroupdriver=systemd"],然后重启 Docker:systemctl daemon-reload && systemctl restart docker - 确保 Kubernetes 组件(如 kubelet)的 Cgroup 驱动与 Docker 一致。可通过检查
/var/lib/kubelet/config.yaml中的cgroupDriver字段确认 。
- 修改 Docker 配置(
2. 内核内存限制问题
类似错误可能与内核内存配置有关:
-
缘由:某些 Linux 内核版本(如 RHEL 7.8)在启用
kmem记账时会导致 cgroup 内存分配失败 。 -
解决方案:
- 在主机内核启动参数中添加
cgroup.memory=nokmem(修改/etc/default/grub并更新 GRUB):grub2-mkconfig -o /boot/grub2/grub.cfg - 重启主机生效 。
- 在主机内核启动参数中添加
3. 资源不足或配置错误
-
Flannel 内存不足:Flannel Pod 默认内存限制可能过低(如 50Mi),导致 OOM 或初始化失败。提议调整其 YAML 文件中的
memory字段至100Mi或更高 。 - 检查其他资源:确认节点是否有足够的 CPU、内存和存储资源。
4. 系统组件版本冲突
-
环境检查:确保 Docker、Kubernetes 和系统内核版本兼容。例如:
- 旧版 Docker(如 18.x)可能与较新 Kubernetes 版本存在兼容性问题 。
- 升级相关组件至稳定版本(如 Docker 20.10+、Kubernetes 1.24+)。
5. 其他调试步骤
-
查看完整日志:运行
kubectl logs -n kube-system kube-flannel-ds-amd64-28bvv --previous获取容器崩溃前的日志。 -
检查节点状态:确认节点无异常(如
kubectl describe node <node-name>)。 - 重新部署 Flannel:删除并重新应用 Flannel 的 DaemonSet(备份配置后操作)。
总结提议
优先检查 Cgroup 驱动一致性 和 内核内存配置,这是此类错误的常见缘由 。若问题持续,提议结合具体环境日志进一步分析。
如何检查和调整 Docker 和 Kubernetes 的 cgroup 配置 ?
Docker 和 Kubernetes 的 cgroup 配置检查与调整指南
一、检查当前 cgroup 配置
1. 检查 Docker 的 cgroup 驱动
docker info | grep -i cgroup
这会显示 Docker 当前使用的 cgroup 驱动,一般是 cgroupfs 或 systemd。
2. 检查 Kubernetes (kubelet) 的 cgroup 驱动
cat /var/lib/kubelet/kubeadm-flags.env
或者查看 kubelet 配置:
ps -ef | grep kubelet | grep cgroup-driver
Kubernetes 默认使用 systemd 作为 cgroup 驱动。
3. 检查系统 cgroup 挂载情况
mount | grep cgroup
lssubsys -am
这可以查看所有已挂载的 cgroup 子系统及其挂载点。
二、调整 cgroup 配置
1. 统一 Docker 和 Kubernetes 的 cgroup 驱动
方案一:修改 Docker 使用 systemd 驱动(推荐)
- 编辑
/etc/docker/daemon.json文件:
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
- 重启 Docker:
systemctl daemon-reload
systemctl restart docker
方案二:修改 Kubernetes 使用 cgroupfs 驱动
- 编辑
/var/lib/kubelet/kubeadm-flags.env文件,添加或修改:
--cgroup-driver=cgroupfs
- 重启 kubelet:
systemctl daemon-reload
systemctl restart kubelet
2. 修复 cgroup 挂载问题
如果发现 cgroup 挂载不正确(如某些子系统未挂载),可以手动重新挂载:
# 先卸载错误的挂载点
umount /cgroup/cpu
# 重新挂载到正确位置
mount -t cgroup -o cpu,cpuacct cpu,cpuacct /sys/fs/cgroup/cpu,cpuacct
mount -t cgroup -o memory memory /sys/fs/cgroup/memory
mount -t cgroup -o devices devices /sys/fs/cgroup/devices
# 其他子系统类似
3. 处理 cgroup v2 兼容性问题
如果系统已升级到 cgroup v2 但 Docker/Kubernetes 不支持:
方案一:降级到 cgroup v1
sudo sh -c echo "GRUB_CMDLINE_LINUX=systemd.unified_cgroup_hierarchy=false" > /etc/default/grub.d/cgroup.cfg
sudo update-grub
然后重启系统。
方案二:升级 Docker 到 v20+
确保 Docker 版本支持 cgroup v2:
apt-get update && apt-get upgrade docker-ce
三、高级配置调整
1. Kubernetes QoS cgroup 配置
Kubernetes 会为不同 QoS 级别的 Pod 创建 cgroup:
- Guaranteed:已设置 request 和 limit
- Burstable:只设置了 request
- BestEffort:未设置 request 和 limit
可以通过 kubelet 参数调整:
--cgroups-per-qos=true # 启用 QoS cgroup(默认开启)
--qos-reserved=memory=50% # 为高优先级 Pod 预留资源
2. 节点资源预留配置
在 kubelet 配置中设置:
--kube-reserved=cpu=100m,memory=100Mi # 为 Kubernetes 组件预留
--system-reserved=cpu=200m,memory=500Mi # 为系统组件预留
--enforce-node-allocatable=pods # 限制 Pod 使用的资源
四、验证配置
- 检查 Docker 容器是否正常运行:
docker run --rm -it busybox echo "test"
- 检查 Kubernetes Pod 状态:
kubectl get pods -A
- 检查 cgroup 层次结构:
ls /sys/fs/cgroup/{kubepods,systemd,docker}
如果遇到 OCI runtime create failed 或 cgroup isn t mounted 错误,请重新检查上述配置。
五、常见问题解决
-
错误:
Devices cgroup isn t mounted- 检查
/sys/fs/cgroup/devices是否存在 - 手动挂载:
mount -t cgroup -o devices devices /sys/fs/cgroup/devices
- 检查
-
错误:
kubelet cgroup driver与docker不一致- 按照第二部分统一驱动配置
-
错误:
unknown container "/system.slice/docker.service"- 在 kubelet 配置中添加:
--runtime-cgroups=/systemd/system.slice --kubelet-cgroups=/systemd/system.slice - 或者在 systemd 服务文件中添加:
[Service] CPUAccounting=true MemoryAccounting=true
- 在 kubelet 配置中添加:
通过以上步骤,您应该能够正确配置和调整 Docker 和 Kubernetes 的 cgroup 设置,解决常见的容器启动问题。
基于 openEuler 系统docker 安装k8s集群问题
docker 必须使用OpenEuler自己的源,使用CentOS的源安装不成功,安装的docker 18.09 是 OE版本,华为二开过的版本。
kubelet和docker 的 cgroup driver 使用systemd会失败,必须使用 cgroupfs。
OpenEuler系统上进行部署时,若docker服务的 daemon.json的 cgroup driver 配置为 systemd,在通过 kubeadm init 命令初始化 Kubernetes 集群时,kubelet的cgroup driver 也会配置为 systemd,此时在systemctl status kubelet 或 journalctl -xfu kubelet 会存在如下报错:
applying cgroup configuration for process caused "No such device or address"
虽然此时 docker 和 kubelet 的cgroup driver 配置一致,均为 systemd,但,依然会报错,flannel无法启动。
kubelet默认使用的 cgroup driver 为 cgroupfs,但官方提议使用 systemd。
我们已经使用了systemd,为啥还是会报错,flannel无法启动?
针对报错在网上进行了搜索,但相关Bug已经得到了解决,实际证明,在 centos、ubuntu系统上,的确 已经不存在该问题,只要 docker 和 kubelet 使用的 cgroup driver 保持一致就行。
最后,将OpenEuler系统上的 docker 和 kubelet 的 cgroup driver 均修改为 cgroupfs,flannel正常启动,kubelet也不存在相关报错。因而认为,OpenEuler系统上的 cgroup driver 目前只能采用 cgroupfs。
OpenEuler系统上的 docker 使用的版本为 18.09.0.300-oe,是经过 华为 二开的版本,估计问题和 docker 版本有关。
根据你提供的环境信息(openEuler 22.03 LTS + Docker 18.09.0 + Kubernetes 1.20.10),结合 cgroup 报错信息,以下是针对性解决方案:
1. 确认 CGroup 驱动一致性
你的环境已配置为 systemd 驱动,但 openEuler 对 Docker 18.09.0 的兼容性可能存在隐患。
关键检查点:
# 检查 Docker 实际使用的 CGroup 驱动
docker info | grep "Cgroup Driver"
# 检查 kubelet 配置
cat /var/lib/kubelet/config.yaml | grep cgroupDriver
若输出不一致(如 Docker 为 cgroupfs 而 kubelet 为 systemd),需强制统一。
解决方案:
-
方案1(推荐):统一使用
cgroupfs(兼容性更好)# 修改 Docker 配置(/etc/docker/daemon.json) { "exec-opts": ["native.cgroupdriver=cgroupfs"] } # 修改 kubelet 配置(/var/lib/kubelet/config.yaml) cgroupDriver: cgroupfs # 重启服务 systemctl restart docker kubelet -
方案2:坚持使用
systemd(需验证 openEuler 支持)# 确保 kubelet 的 systemd 配置包含以下参数(/usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf) --cgroup-driver=systemd --runtime-cgroups=/system.slice/kubelet.service --kubelet-cgroups=/system.slice/kubelet.service
2. 修复 openEuler 的 CGroup 挂载问题
openEuler 默认使用 cgroup v2,而 Docker 18.09.0 对 v2 的支持不完善,需降级为 cgroup v1。
操作步骤:
# 编辑内核启动参数
vi /etc/default/grub
# 在 GRUB_CMDLINE_LINUX 中添加:
systemd.unified_cgroup_hierarchy=0
# 更新 grub 并重启
grub2-mkconfig -o /boot/grub2/grub.cfg
reboot
# 验证 CGroup 版本
stat -fc %T /sys/fs/cgroup/
# 应输出 `cgroup2fs`(v2)或 `tmpfs`(v1),确保重启后为 v1
3. 升级 Docker 版本(关键)
Docker 18.09.0 在 openEuler 22.03 上存在已知兼容性问题,提议升级至 Docker 20.10+ 或改用 containerd。
步骤:
# 卸载旧版本
yum remove docker-engine
# 安装新版 Docker(需配置 openEuler 的 docker-ce 源)
yum install -y docker-ce docker-ce-cli containerd.io
# 或直接切换至 containerd
yum install -y containerd
containerd config default > /etc/containerd/config.toml
systemctl enable --now containerd
4. 检查 kubelet 日志定位具体错误
journalctl -u kubelet -n 100 --no-pager | grep -i cgroup
若日志中出现类似 failed to create containerd task: failed to create shim task: OCI runtime create failed,则进一步验证容器运行时状态:
# 检查 containerd 或 docker 运行时状态
ctr namespace list
docker info
5. 临时修复 Flannel 的 CGroup 问题
若问题仅出目前 kube-flannel-ds Pod 中,可尝试修改其 DaemonSet 配置:
kubectl edit daemonset kube-flannel-ds-amd64 -n kube-system
在 containers 部分添加以下安全上下文:
securityContext:
privileged: true
总结提议
| 问题根源 | 解决措施 |
|---|---|
| CGroup 驱动不一致 | 统一改为 cgroupfs 或完善 systemd 配置 |
| openEuler 的 CGroup v2 | 降级为 v1(修改内核参数) |
| Docker 18.09.0 版本过旧 | 升级至 Docker 20.10+ 或切换至 containerd |
| 容器运行时配置异常 | 检查 containerd/docker 日志,修复配置 |
最终推荐方案:
- 降级 CGroup 为 v1
- 升级 Docker 或改用 containerd
- 统一 CGroup 驱动为
cgroupfs
执行后重启节点并观察 Flannel Pod 状态:
kubectl get pods -n kube-system -w
参考
OpenEuler 22.03 部署Kubernetes问题记录
https://cloudpods.csdn.net/657804d4b8e5f01e1e44702c.html
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...