大致有 10% 的请求打到了新版本,监控面板上没发现异常,也没触发自动回滚。流量按照预定的节奏在跑,接口大多数返回 2xx,延迟稳定,终端用户感觉也没有变化。
这次发布是按阶段放量的:先把一小部分流量分给 v2,等观测指标没问题再继续放宽比例。自动化金丝雀跑了整套流程:每步会按设定的权重放流量、暂停观察、再根据指标决定是否继续。过程中出现过一次短暂的 5xx 峰值,系统自动暂停了推进,人工看了下监控确认问题不扩大才继续放流。回滚手段随时可用,常用的几招是把 v2 缩容、删掉 canary 的 Ingress,或者把 VirtualService 的权重改回 0,任何一招都能把流量拉回到 v1。
说说用于把灰度流程自动化的那套做法,比较适合把灰度纳入 CI/CD 的团队。用 Argo Rollouts 的话,直接用 Rollout 替换掉普通的 Deployment,就能把灰度步骤、暂停时间和指标分析都写进配置里。我这边示例里把副本定为 4,灰度策略按 10%、30%、60%、100% 推进,每步间隔两分钟,配了一个基于 Prometheus 的 success-rate 查询。Argo 会在每一步结束后跑 analysis,若不达标就自动触发回滚。常用命令包括 kubectl apply -f rollout.yaml 上配置,kubectl argo rollouts get rollout –watch 看进度,以及 kubectl argo rollouts undo 回退。
下面是个 Rollout 的例子(用来取代 Deployment),配置里把灰度步骤、权重和 Prometheus 的分析都写清了:
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: web-rollout
spec:
replicas: 4
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
version: v2
spec:
containers:
– name: web
image: yourrepo/web:v2
ports: [{ containerPort: 80 }]
strategy:
canary:
steps:
– setWeight: 10
– pause: { duration: 2m }
– setWeight: 30
– pause: { duration: 2m }
– setWeight: 60
– pause: { duration: 2m }
– setWeight: 100
trafficRouting:
# 如果用 Istio 或 nginx,按需填写
analysis:
templates:
– name: success-rate
successCondition: result[0] > 0.99
failureCondition: result[0] < 0.98
metrics:
– name: request_success_rate
interval: 30s
count: 3
provider:
prometheus:
address: http://prometheus:9090
query: |
sum(rate(http_requests_total{job=”web”,status=~”2..”}[1m]))
/
sum(rate(http_requests_total{job=”web”}[1m]))
把判断规则、暂停点和回滚逻辑都写到流程里,脚本跑起来的确 省心而且可重复。缺点也很明显:需要额外安装 Argo,配 Prometheus,还得保证监控指标能真实反映问题。实操经验是,这套能把人工干预降到最低,但面板旁边最好还是留个人盯着,机器可以自动判定,但有些边界情况机器不必定看得清楚。
再往前走一步,是用 Service Mesh(以 Istio 为例)在流量层面切分的办法。Istio 把流量控制放在 VirtualService 上,能按百分比、按 header 或 cookie 准确分流,适合做 AB 测试或需要复杂路由的场景。一般流程是先建一个普通的 Service(selector 指向 app 标签),再用 DestinationRule 定义不同的 subset(列如 v1、v2),最后在 VirtualService 里写权重。
关键资源可以像下面这样写:
apiVersion: v1
kind: Service
metadata:
name: web
spec:
selector: { app: web }
ports: [{ port: 80 }]
—
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: web-dr
spec:
host: web
subsets:
– name: v1
labels: { version: v1 }
– name: v2
labels: { version: v2 }
—
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: web-vs
spec:
hosts: [“example.com”]
gateways: [“my-gateway”]
http:
– route:
– destination:
host: web
subset: v2
weight: 10
– destination:
host: web
subset: v1
weight: 90
apply 上去后来,大约 10% 的流量会被路由到 v2。要撤回只要改 VirtualService 把 v2 的 weight 改回 0,或者把 v2 的 route 删掉,再 kubectl apply 一下就行。另一种快速撤回是把 v2 的副本数降成 0:kubectl scale deploy web-v2 –replicas=0。
用 Istio 的好处是控制力强、能做细粒度路由,也能和监控结合做自动决策;代价是引入了额外的控制平面,配置更多、学习曲线更陡。实战里,如果目标是在线上分流验证新版本行为,Istio 是个很有力的工具,但要预留时间搞清楚配置和监控的标签映射。
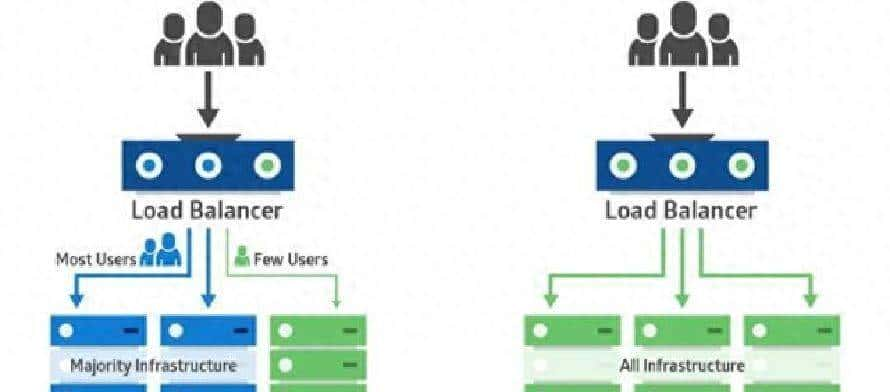
最轻量的方案是直接用 nginx-ingress 的 canary 注解做权重灰度。这适合那些没装 Service Mesh 的集群,上手快、改动小。核心思路是部署两套 Deployment(v1、v2),Service 的 selector 指向 app 标签(不区分 version),然后用两个 Ingress:一个正常流量的主 Ingress,一个标注为 canary 的 Ingress,通过 canary-weight 注解控制占比。
操作流程大致这样:
1) 部署 v1:
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-v1
spec:
replicas: 3
selector: { matchLabels: { app: web, version: v1 } }
template:
metadata:
labels: { app: web, version: v1 }
spec:
containers:
– name: web
image: yourrepo/web:v1
ports: [{ containerPort: 80 }]
—
apiVersion: v1
kind: Service
metadata:
name: web-svc
spec:
selector: { app: web } # Service 不区分 version
ports: [{ port: 80, targetPort: 80 }]
kubectl apply -f deploy-v1.yaml
2) 部署 v2(副本少一点):
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-v2
spec:
replicas: 1
selector: { matchLabels: { app: web, version: v2 } }
template:
metadata:
labels: { app: web, version: v2 }
spec:
containers:
– name: web
image: yourrepo/web:v2
ports: [{ containerPort: 80 }]
kubectl apply -f deploy-v2.yaml
3) 配置主 Ingress 与 canary Ingress:
主Ingress(走正常流量):
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: web-ingress
annotations:
kubernetes.io/ingress.class: “nginx”
spec:
rules:
– host: example.com
http:
paths:
– path: /
pathType: Prefix
backend:
service:
name: web-svc
port: { number: 80 }
Canary Ingress(把一部分请求标为 canary):
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: web-canary
annotations:
kubernetes.io/ingress.class: “nginx”
nginx.ingress.kubernetes.io/canary: “true”
nginx.ingress.kubernetes.io/canary-weight: “10”
spec:
rules:
– host: example.com
http:
paths:
– path: /
pathType: Prefix
backend:
service:
name: web-svc
port: { number: 80 }
kubectl apply -f ingress-main.yaml
kubectl apply -f ingress-canary.yaml
检验命中率可以用一个小脚本多次 curl,观察返回头或响应里标记的版本字段:
for i in {1..100}; do curl -sS -H “Host: example.com” http:/// | grep “version”; done
要撤销 canary 就删掉 ingress-canary.yaml:kubectl delete -f ingress-canary.yaml,或者把 canary-weight 改成 0,或把 v2 缩容。
不管选哪种灰度手段,有些准备工作必须做齐。先确认镜像仓里有新镜像,两个 Deployment 或 Rollout 已经就绪,Service 能覆盖到 app 标签,监控和日志可以拆版本查看。网络策略、证书、限流设置也要提前验证,别在灰度跑着跑着由于别的配置问题引发故障。
监控和验收指标特别关键。一般会盯这些:请求成功率(2xx 的占比)、5xx/4xx 的比率、平均延迟和 P95/P99、错误类型分布、以及后端依赖(列如数据库或第三方服务)的异常情况。Argo 的 analysis 一般依赖 Prometheus 查询,所以指标名和标签要事先对齐,保证自动判断能正常工作。经验是把阈值设得稍严格一些更安全,但别严到频繁误判,弄得节奏一阵一阵的。
回滚时有几条实用规则:当错误率短时间内飙高、延迟明显上升或关键业务路径出问题,先把流量退回老版本,再去做 root-cause 分析。操作优先级大致是:先改权重或删 canary,把流量导回老版本;若需要,接着把问题版本缩容;最后如果必须回滚镜像再做版本回退。常用命令是 kubectl scale、kubectl apply(修改 VirtualService/Ingress),以及 Argo Rollouts 的 undo。
过程里要注意的细节不少:Service 的 selector 一般不分版本,流量路由是靠
Ingress/VirtualService/trafficRouting 来实现;会话保持(session stickiness)会影响流量命中比例,特别是某些 ingress controller 有粘性设置时;日志里最好把 version 写进标签或字段,这样在 Prometheus/Grafana、ELK 里才能按版本拆分查询。灰度前最好做一次压力测试,别把闪现的 bug 放到真实用户面前去锻炼。
提一点个人体会:把灰度机制和自动化结合起来,能在保护线上稳定性的同时,也把发布时间缩短。部署前把回滚流程和监控指标写清楚,实际推进时按步骤来,遇到异常时先稳住流量再排查问题,这样能把损失降到最低。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...