
一文掌握 GeoPandas 矢量数据处理的核心方法
前言
相比栅格数据,矢量数据的处理实则并不复杂,许多操作只需一行代码就能轻松完成。本文总结了我认为在矢量数据处理中最常用也最核心的一些方法,包括:矢量数据的结构、数据读取、坐标转点矢量、缓冲区生成、数据合并与空间连接、叠加分析等。全部基于 GeoPandas 实现,代码简洁实用。
1.矢量数据结构
GeoPandas 与 Pandas 的数据结构类似,分别对应GeoSeries和GeoDataFrame。其本质仍是表格结构:第一列为索引,中间是属性字段,最后是几何列(geometry),如下图所示。GeoPandas 支持三类基础几何对象:点(Point)、线(LineString)、面(Polygon)。
2.数据读取
2.1查询属性信息
我们常用的矢量数据就是shp,这里介绍shp数据的读取与导出。矢量数据涉及的基本属性信息有矢量的要素边界、几何形状、坐标系统以及面积等信息
import geopandas as gpd
file=r"C:UsersHPDesktop est011shi.shp"
shp=gpd.read_file(file)
print(shp.geometry)#查看几何数据
print(shp.bounds)#要素边界
print(shp.geom_type)#几何形状
print(shp.crs)#查看坐标系统信息
#矢量数据改变坐标系统很简单,这里提一下,下面这个函数即可
shp_pro=shp.to_crs(epsg=32650)
print(shp_pro.area)
shp_pro.to_file(r"C:UsersHPDesktop est011shi01.shp")</pre>
2.2数据切片
与 Pandas 一样,可以使用 .loc 和 .iloc 对矢量数据进行按行、按列切片,方便提取特定区域或属性子集。
shp= gpd.read_file(file,columns=["smc", "dem", "mj"],)
print(shp["smc"]=="寒冬省")
shp01=shp.loc[shp["smc"]=="寒冬省",["dem","mj","geometry"]]
3.坐标点转点矢量
野外采集的坐标点一般需要转为矢量格式以便可视化与空间分析,GeoPandas 可直接将经纬度转换为点矢量(Point)。同时,使用 centroid 方法还可从面要素中提取其几何中心点。
import pandas as pd
import geopandas as gpd
from shapely.geometry import Point
# 读取点文件
file_path = r"C:UsersHPDesktopimage_processshp001point.xlsx" #点文件
out_file=r"C:UsersHPDesktopimage_processshp001point.shp"
df = pd.read_excel(file_path)
# 创建 GeoDataFrame
geometry = [Point(xy) for xy in zip(df["x"], df["y"])]#获取几何数据
gdf = gpd.GeoDataFrame(df, geometry=geometry, crs="EPSG:4326")
###gpd.GeoDataFrame第一个参数是点的dataframe数据,其它属性值也将导入,第二个参数为集合数据,第三个数据就是设置正确的坐标系
# 导出Shp
gdf.to_file(out_file)
print(gdf.head())
#提取中心点
gdf[ center_point ]=shp.centroid
point_central=gdf.set_geometry( center_point )#提取中心点
4.生成缓冲区
下面提供两种生成缓冲区的方法,一是按固定距离生成缓冲区,二是按属性字段生成缓冲区。点线面都能适用,使用buffer函数即可。
import geopandas as gpd
import matplotlib.pyplot as plt
point_shp=gpd.read_file(file_path)
point_pro=point_shp.to_crs(epsg=32650)
print(point_pro.crs)
point_shp01=point_pro.copy()
#1.按固定距离缓冲
point_shp01=point_shp01.buffer(50)#固定距离50m
#2.按属性字段缓冲。
point_shp01[ geometry ] = point_shp01.apply(lambda row: row.geometry.buffer(row[ people ]), axis=1)</pre>
5.合并数据
5.1矢量数据链接表格
与表格数据一样,矢量数据也可以基于字段进行连接(merge)。例如将一个 Excel 表格连接到 shp的属性表中,或连接两个 shp 之间的信息
import pandas as pd
import geopandas as gpd
gdf = gpd.read_file(r"C:UsersHPDesktopimage_processshp001point03.shp")
excel = pd.read_excel(r"C:UsersHPDesktopimage_processpoint.xlsx")
gdf_merged = gdf.merge(excel, on="people", how="left")#这有点像pandas的字段融合,参数设置可以参考pandas的merge函数
#按照people列合并,outer表明以并集相连,单方面取交集:left,right表明以哪个数据为准,这里就是保留gdf所有记录
#此外两个矢量数据的字段连接也和这一样
print(gdf_merged)
5.2空间链接
GeoDataFrame.sjoin()函数基于几何关系将一个图层的属性信息附加到另一个图层,其有两个重大参数一个是how,一个是predicate,。predicate就是根据一个对象与另一个对象的几何关系来决定是否将其属性连接到另一个对象。其涉及六个值intersects(相交)、contains(包含)、within(在里面)、touches(相邻,但不相交)、crosses(穿过,部分相交)、overlaps(部分相交)。how还是表明以哪个数据为准。
gdf_joined = gpd.sjoin(gdf_points, gdf01, how="left", predicate="within")
#left是指保留左侧矢量(gdf_points)的几何列,就是保证左侧矢量数据不变
#within表明gdf_points在gdf01中,intersects表明相交,contains表明包含</pre>
6.矢量数据叠加分析
6.1按属性字段合并要素
dissolve(by= 字段名 ) 可根据指定字段合并同类要素,并进行面积等属性统计,是区域合并、行政区边界处理的常见操作
selected_shp = shp[(shp[ smc ].isin(["寒冬省","夏日省"]))]
selected_shp.plot(column = dem , cmap= YlOrRd )
plt.show()
selected_shp = selected_shp.rename(columns={"smc": "name"})#字段重命名
#按属性字段融合,并对相关字段进行计算融合,若aggfunc没填,这里一样name属性行,就按第一行的属性字段进行融合
dissolved = selected_shp.dissolve(by= name , aggfunc={
"dem": "sum",
"mj": ["min", "max"],},)
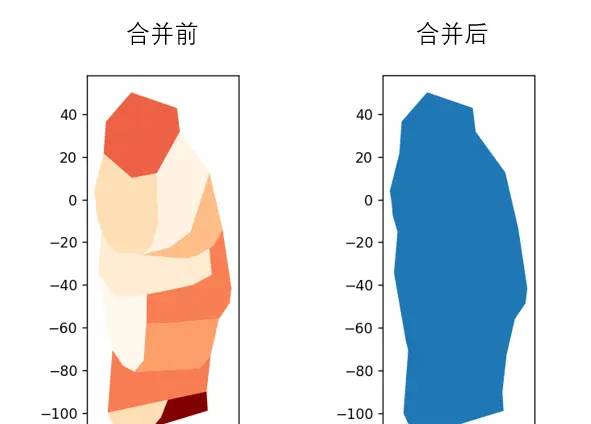
6.2相邻矢量要素合并
这行代码是对相邻的矢量要素进行合并。unary_union可对矢量进行合并,但是形成的是geometry,后面几行代码我是将geometry转成geodataframe格式,注意GeoDataFrame函数中,我开始使用的是geometry=merge,但是报错,由于这里要求geometry 参数要求是一个 列表/Series,而我直接传了一个 Polygon 对象,所以我得转成列表,即[merge]。
merge=shp.unary_union
data = {"price":[10]}
df = pd.DataFrame(data)
shp03= gpd.GeoDataFrame(df, geometry=[merge], crs="EPSG:4326")
print(shp03)
shp03.plot()
plt.show()</pre>
6.3非相邻要素拆分
我们常常会遇到这种情况,非相邻的要素被合并为一个要素,那么如何拆分呢,使用explode函数即可,ignore_index主要是影响索引值,如果是False还会生成一个一列索引,及生成多级索引
shp= gpd.read_file(file)
exploded = shp.explode(ignore_index=True)
6.4叠置分析(交集、并集、差集)
如何理解,看图即可。
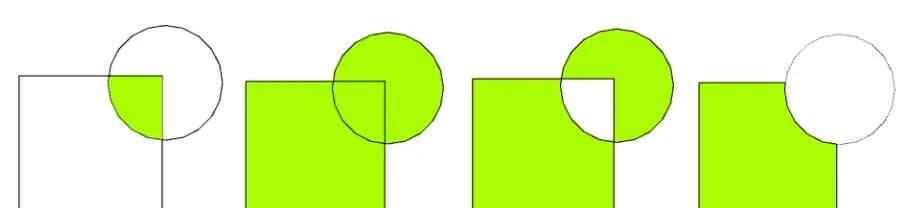
#1.取并集
union=shp01.overlay(shp02, how= union )
#2.取交集
intersection = shp01.overlay(shp02, how= intersection )
#3.取差集
#symmetric_difference与intersection完全相反,只取无重叠部分
symdiff = shp01.overlay(shp02, how= symmetric_difference )
#difference只取第一个矢量的无重叠部分
difference = shp01.overlay(shp02, how= difference )
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











