

跳出VLA框架限制,具身全模态模型来了。
作者丨齐铖湧
编辑丨马晓宁

人类究竟需要什么样的具身智能?
先来回答一道阅读理解题:
在一个家庭场景中,作为一个超级聪慧的家庭机器人,你听到孩子和妈妈展开了一段对话:
孩子:妈,我渴了
妈妈:冰箱里有橙汁和可乐
孩子不太情愿地说:呃,橙汁······(超级排斥的语气)
这时,孩子看向了你,作为机智的机器人,你应该怎么做?
显然,你听出了孩子不想喝酸酸的橙汁,如此机智聪慧的你,肯定会主动问孩子:那我给你拿一罐肥仔快乐水?

这个小剧场,不是段子,而是出目前一篇严肃论文里的内容。
最近,来自复旦大学、上海创智学院及新加坡国立大学研究团队发布了一个全新的操作框架 RoboOmni ,让机器人学会了“察言观色”。

https://arxiv.org/pdf/2510.23763
RoboOmni: Proactive Robot Manipulation in Omni-modal Context
01 传统 VLA 带来的具身局限:
极度依赖「显式指令」
过去一段时间,多模态大语言模型(MLLMs)的发展,推动了VLA(视觉-语言-动作)模型的快速繁荣,也给机器人领域带来了巨大的变化。
尽管 VLA(视觉-语言-动作)范式愈发成熟,但依旧存在一个巨大的局限性:
“机器人的推理能力,极度依赖「显式指令」”。
而在现实世界交互中,人类很少直接发出指令。有效的协作往往需要机器人主动推断人类的意图。
列如,大部分机器人只能理解 “从冰箱里拿出可乐放到餐桌上” ,或者“打开冰箱门,取出红色罐状物体,然后关上冰箱门,再将红色罐状物给我”这样的指令。
但大部分现实场景中,人类却常常发出“隐式指令”,列如“呃,橙汁······(超级排斥的语气)”。
于是,复旦大学、上海创智学院及新加坡国立大学研究团队发布引入了跨模态情境指令,以此创造了一个新的场景:从口语对话、环境声音和视觉提示中推导出来的场景,而不是显式命令。
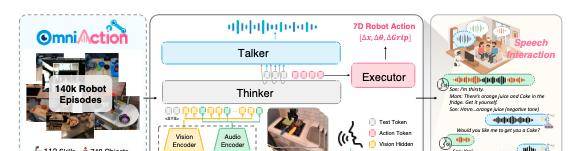
为了应对这一新场景,研究团队提出了 RoboOmni,这是一个基于端到端全模态 LLMs 的感知者-思考者-说话者-执行者框架,它统一了意图识别、交互确认和动作执行。
仿真和现实环境中的实验表明,RoboOmni 在成功率、推理速度、意图识别和主动辅助方面超越了基于文本和 ASR 的基线。
这样的表现,让我们对真正的智能有了新的期待。
02 智能与否,在于机器人能否听出
“话里有话”
在这项研究里,团队提出了一个关键的问题:
“机器人能否整合跨模态上下文,包括语音、环境音频和视觉观察,以主动推断和验证用户意图?
想要做出主动推断,机器人必须从音频和视觉观察中推断隐含意图,也就是“话里的话”。
但现有数据集缺乏这种模态组合(大多数缺乏音频模态)以及意图推理所需的推断指令。
为解决这一差距,团队引入了 OmniAction。RoboOmni 融合了听觉和视觉信号,以实现鲁棒的意图识别,同时支持直接语音交互。
并且,为了解决机器人操作中主动意图识别缺乏训练数据的问题,团队构建了 OmniAction 大规模情境指令数据集,包含 140k多模态样本、5 千多名说话人、2.4k事件声音、640 个背景和六种情境指令类型。
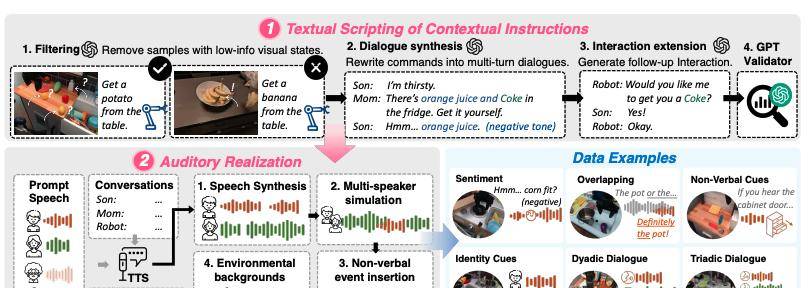
OmniAction 数据集构建流程概述及示例
在语料库的基础上,RoboOmni 融入了六种上下文指令类型。
包括身份线索(列如是孩子想喝东西,不是妈妈),非语言线索,重叠语音,情感线索(列如“呃,橙汁太酸了”暗示要求提供替代品)等等。
基于以上, RoboOmni 的开发团队,建立了一个用于操控的、端到端多模态框架。
这意味着,在文章开始的案例中,从最开始意图识别(听妈妈和孩子对话)、交互确认(是否需要可乐)和动作执行(拿可乐),都包含在内,从而形成了“感知-思考-回应-执行”统一架构,在同一模型中完成语音理解、语音对话与动作执行。
03 机器人的高情商,
来自“跨模态上下文指令”
看到这里,大家必定关心的是 RoboOmni 的具体研究过程:
与先前方法不同,RoboOmni 不需要直接指令,而是跨模态上下文指令。
作为一种新的机器人操作环境,它的指令形式要求机器人从多模态上下文(视觉、环境声音和语音)中主动推断用户指令,而不是被动等待明确的指令。
研究团队进一步评估了 RoboOmni 在真实人类录音的直接音频指令下的鲁棒性。
他们用了 OmniAction-LIBERO-Real 基准测试,测试显示 RoboOmni 实现了最高的平均性能(76.6%),超越了强劲的基于文本的 VLA,包括π(73.8%)、OpenVLA(40.1%)和 NORA(17.4%)。

不难发现,RoboOmni 直接处理语音,能够避免了 ASR 管道错误,效果不错。
在基线模型方面,当前开源的视觉-语言-动作(VLA)模型主要设计用于文本指令,无法直接处理音频输入,因此研究团队构建了两种基线范式来验证端到端音频处理必要性:
第一是真实文本提示,将预先标注的语音指令转录直接输入 VLA 模型;第二是语音-ASR-文本提示,其中语音指令第一使用 ASR 模型 Whisper large-v3转录为文本,然后输入 VLA 模型。
过程中,将 RoboOmni 与两种范式的四个代表 VLA 基线进行比较,分别是OpenVLA、OpenVLA-OFT、π和 NORA。
在实现细节上,团队使用 224×224 的输入图像分辨率、16,000 Hz 的音频采样率和 6 的动作分块大小来训练模型。对于大规模预训练,RoboOmni 在 64 个 A100 GPU 组成的集群上进行了 10 天的优化,总共对应 15,360 个 A100 小时,比较扎实。
训练过程使用学习率为 5×10 的 10 个 epoch,其中前 1k 步保留用于预热。对于下游任务的监督微调(SFT),团队采用学习率为 5×10,并使用 8 个 A100 GPU 进行 10-30k 步的训练。
同时,为了验证 RoboOmni 的功能是否超越模拟环境,团队在WidowX 250S 上使用演示数据集对预训练模型进行微调,研究团队找了10名志愿者,录制了这份数据集。
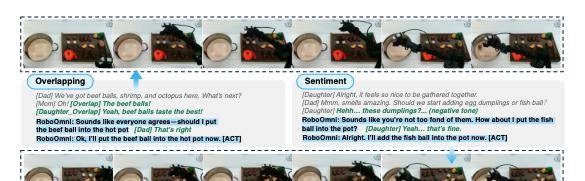
RoboOmni 在真实世界的 WidowX 250S 机械臂上成功案例的演示:在多个干扰物中定位正确的物体并将其放入指定的花盆中
在试验过程中,RoboOmni 在三个维度的表现都很突出:
强劲的意图识别:根据音频识别物体,并根据视觉场景确定容器是花盆;
有效的交互:在推断出用户的潜在意图后主动询问澄清问题(例如,“我应该……吗?”),并在收到确认后执行操作;
可靠的执行:成功执行确认的操作;
在模拟和现实世界场景中的评估中,RoboOmni 展现出新兴的认知智能,在成功率、推理速度以及更有效的主动辅助和意图识别方面优于基线模型。
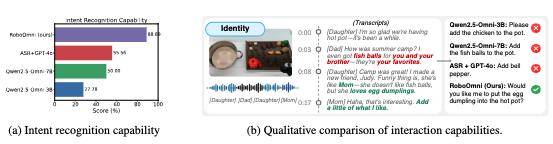
这使得 RoboOmni 能够在真实机器人上运行,并处理多样化的语音指令(例如,情感、重叠提示)。
于是,就有了前面的场景中,机器人听到孩子和妈妈的对话,一通分析,判断孩子不喜爱橙子,主动问孩子:那我给你拿个可乐?得到孩子肯定回答后,就吭哧吭哧去拿了。
什么是高情商,这才是高情商。
04 OmniAction-LIBERO是什么?
前面提到,研究团队在 RoboOmni 的探索过程中,除了大量的高质量数据喂养和上下文指令类型外,还需要评估机器人理解的准确性。
这就需要用到 OpenMoss 团队的另一个杀手锏: OmniAction-LIBERO。
这是一个针对主流 VLA 模型的系统性、全方面、细粒度的鲁棒性分析框架,它的核心目的就是对 VLA 模型进行泛化性能测试。
OmniAction-LIBERO 的原理机制和论文链接如下:

LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
https://arxiv.org/pdf/2510.13626v1
在OmniAction-LIBERO-TTS 基准测试中,不同机器人操作模型在四种任务套件(空间、目标、物体、长时程)下,针对六种上下文指令类型的性能表现:
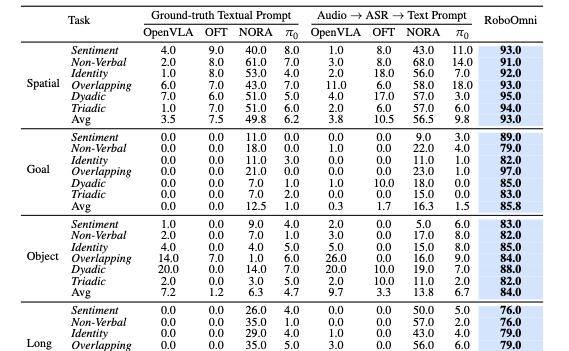
加粗值表明最佳性能
RoboOmni 的框架,形成了一个感知者-思考者-说话者-执行者架构:
感知来自多模态输入编码,它负责将异构输入模态编码到一个统一的嵌入空间中;思考来自全模态推理,思考者是中央推理引擎,基于 LLM 主干构建。它处理感知器提供的统一多模态表;执行器负责动作生成,为了实现机器人控制在语言模型框架中的无缝集成;它将视觉、文本和音频统一到一个共享的标记空间中,以生成动作和语音,且将语音、环境音频、视觉和机器人动作统一在一个自回归模型中,形成一个闭环。
05 足够复杂的情境,可能是AGI的突破口
RoboOmni 框架的形成,在这个团队过去的研究中,是有迹可循的。
今年上半年,新的训练路径探索中,RoboOmni 团队的通讯作者复旦大学/上海创智学院邱锡鹏教授就曾在中提出过一个新思路 :
Context Scaling
与参数规模、后训练推理等路径不一样,Context Scaling 更看重如何让 AI 真正理解并适应复杂、多变、模糊的情境(Context)。
邱锡鹏教授超级推崇情境理解,并将它转化为一个新的探索方向:
情境智能(Contextual Intelligence)
这次 RoboOmni 的发布,正是他们团队在情境智能方向探索的的一次成果汇报。
这也给许多科学家探索真正的智能,提供了一种思路。
人类之所以表现出智能,是由于人能够理解任务的模糊与复杂。
在语言交流中,人类能听懂朋友的“暗示”,能形成“只可意会不可言传”的默契,这让我们能够高效合作与共赢;在劳动中,我们能够横跨许多领域学习,从蝙蝠的飞行智慧中领悟雷达的原理,从荷叶表面学会不粘锅。
不难发现,这些行为,都不是简单的状态 – 动作 – 奖励循环而是在足够丰富的情境中交互,才能涌现出的智能和突破。RoboOmni重新定义了机器人交互:从“执行命令”到“主动理解”,让机器人洞察人意,从而开启了具身智能的“共情时代”。

//

未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载! 公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。
© 版权声明
文章版权归作者所有,未经允许请勿转载。












收藏了,感谢分享