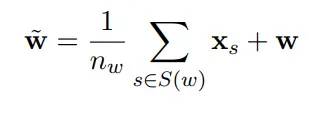
 代表词的义原集合,根据 hownet 的定义来说,一个词会有 3~5 个义原来解释.将此时新的词嵌入输入 transformer 其他部分,列如位置嵌入,自注意力机制等不作改变. 基于 词的语义可以由义原的集合来表明的假设,同时义原嵌入也由各个词共享,可以编码到词与词之间潜在的语义信息,加粗字体这一点还需要再思考.
代表词的义原集合,根据 hownet 的定义来说,一个词会有 3~5 个义原来解释.将此时新的词嵌入输入 transformer 其他部分,列如位置嵌入,自注意力机制等不作改变. 基于 词的语义可以由义原的集合来表明的假设,同时义原嵌入也由各个词共享,可以编码到词与词之间潜在的语义信息,加粗字体这一点还需要再思考.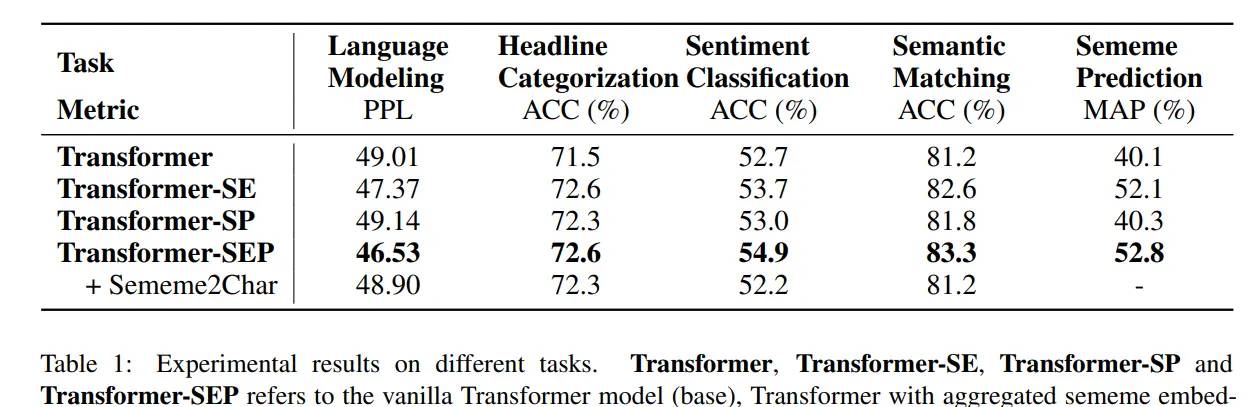


《Enhancing Transformer with Sememe Knowledge》
理解可能有误。
1. 简介
这是清华大学刘知远老师团队的一篇 使用 知网 Hownet 中的义原作为外部知识,加入 transformer 模型,证明加入外部知识的模型可以提高语言模型的性能以及下游任务的效果。论文摘要如下:

2. 关于模型
论文使用的两种方式去整合 义原(sememe) 信息加入transformer:
- 基于语言学的假设,为每个单词嵌入添加对应的聚合义原嵌入,以达到加强每个词的语义表明,由于语言学中,义原是作为最小的语义单元。
- 将义原预测作为附加的任务进行一起训练,协助模型获得更加深刻的语义理解
作者将他们的方法应用到多个跟词级别和句子级联系紧密的 NLP 任务上,与一般设置的预训练模型和 fine-tune 操作结果相比,有明显的提升,证明义原加强算法是有效的,并且义原加强方法实现同样的的模型表现可以使用更少的 微调数据;同时引进对抗训练的方式证实方法的有效性:将 名词,形容词,动词等替换成他们的同义词;实例学习进一步说明为什么有效。
下面来看看他们具体怎么做的:
3. 模型解读
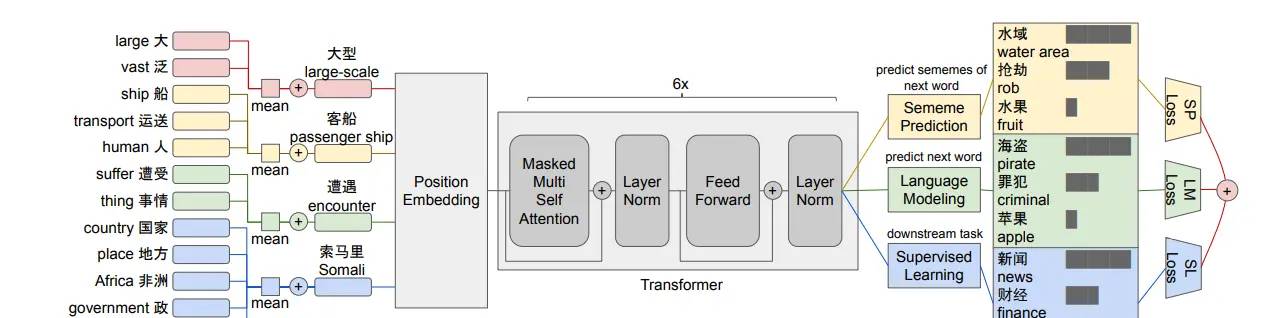
这是模型结构,对于每个词,使用他们的聚合义原嵌入来加强词嵌入,运用多任务训练模型,分别是:
- 义原预测任务(预测下一个词的义原)
- 语言模型(预测下一个词)
- 监督学习(只针对下游任务)
- 具体来说:
每个词原本是初始化为词嵌入,可以是随机初始化,或者查表导入静态词向量,目前的方式是,义原词也初始化为词嵌入之后,每个原本的词嵌入,再加上对应的全部义原嵌入的平均值,作为最终的词嵌入: 代表词的义原集合,根据 hownet 的定义来说,一个词会有 3~5 个义原来解释.将此时新的词嵌入输入 transformer 其他部分,列如位置嵌入,自注意力机制等不作改变. 基于 词的语义可以由义原的集合来表明的假设,同时义原嵌入也由各个词共享,可以编码到词与词之间潜在的语义信息,加粗字体这一点还需要再思考.
代表词的义原集合,根据 hownet 的定义来说,一个词会有 3~5 个义原来解释.将此时新的词嵌入输入 transformer 其他部分,列如位置嵌入,自注意力机制等不作改变. 基于 词的语义可以由义原的集合来表明的假设,同时义原嵌入也由各个词共享,可以编码到词与词之间潜在的语义信息,加粗字体这一点还需要再思考. - 关于训练任务,义原预测,去预测下一个词的义原,一般来说比模型去预测下一个词要更加挑战模型的语义理解能力,并且也是更加易于习得,列如说这个句话:How to cook * ,要预测这句话的下一个词是什么,如果预测值为:food ,是相比较预测出来具体是什么食物名词,要更加容易,范围更宽,义原一般具有高度概括解释具体词语核心的描述功能。从这个角度看来,这个模型的假设是正确且更加高效.
4. 损失函数
义原预测任务中,用于评估,下一个词跟全部的每个义原关联的可能性:

 和
和  分别是与每个义原关联的权重和偏置值,
分别是与每个义原关联的权重和偏置值, 是 sigmoid 激活函数,于是计算义原预测的二元交叉损失
是 sigmoid 激活函数,于是计算义原预测的二元交叉损失 为:
为:
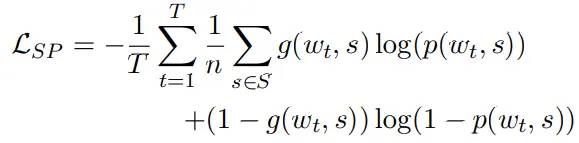
其中, 是全部的义原集合,
是全部的义原集合, 是二元变量指示义原
是二元变量指示义原  是否是词 的义原.
是否是词 的义原.
5. 任务检验
实验在以下几个任务上面进行了实验:
- Language Modeling 语言模型任务
- Headline Categorization 标题分类, NLPCC 2017 news headline categorization dataset
- Sentiment Classification 情感分类,微博语料
- Semantic Matching ,在语料中匹配与输入问题类似的问题
- Sememe Prediction 义原预测,参见博客:***(更新ing)
实验结果:
- transformer-SE:义原聚合加强嵌入模型,比单纯的transformer 在这几个任务上取得了显著的提升,说明义原知识的引入可以有效提升模型的效果
- transformer-SP:义原预测附加任务模型,提升稍微小一些,基于以往知识预测新的知识显然更加有难度
- Transformer-SEP:义原聚合+义原预测 联合模型取得了最大的提升,可以解释为综合了以上两种模型的效果
-
Sememe2Char:由于汉字为汉语提供了很强的语义,实验还比较了义原分解:分解成字符(Sememe2Char)对于表中的最佳模型,观察到所有任务都有明显的性能下降,这表明把单词分解成义素要有效得多。
7. Data Ablation Study:数据消融研究
当训练数据有限时,加入外部义原知识可以提高模型在这几个任务上的表现,并且,越依赖于词级别语义的任务,越能获得更大的提升,在这个条件下;
headline categorization > sentiment classification > semantic matching
也是由于这样一个假设:语义类似的词一般共享类似的义原,所以加入义原知识的模型会比 基线模型 效果有较明显的提升.
-
对抗研究
To evaluate the robustness of our models, we generate adversarial examples by replacing similar nouns, adjectives and adverbs for the cases that both Transformer and TransformerSEP can predict correctly. Intuitively, these words are generally more informative for prediction and models are more likely to overfit such words.如何解释:
由于词 “奸商 profiteers” 和 “骗子 cheaters” 有一样的义原 “有罪 guilty” 和 “人 human” , 并且有类似的义原 “欺骗 deceive” 和 “骗 cheat” ;这些义原知识可以通过没一层自注意力层进行传播,所以可以解释,为什么义原知识可以加强词嵌入并且经受词替换的验证.
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











