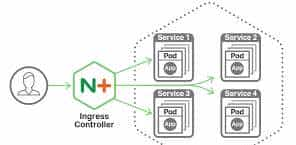
一、基础操作:从打开到关闭的正确姿势
(一)文件打开模式全解析
1. with open(…) as f
在 Python 中,文件操作完成后关闭文件就像离开房间要关灯一样重大。传统方式打开文件需要手动调用close()方法关闭文件,如果忘记关闭,就会导致文件句柄泄漏,就像离开房间没关灯浪费电一样,可能会引发系统资源耗尽等严重问题。而with语句就像是一个智能管家,会自动帮我们处理文件关闭操作,确保资源在使用完毕后被正确释放。
with语句的核心在于上下文管理协议,其运作机制可拆解为两个关键阶段:
- 资源获取阶段:当代码执行到with语句时,会第一调用上下文管理器的__enter__()方法。对于文件操作而言,open()函数返回的文件对象本身就是内置的上下文管理器,其__enter__()方法会返回文件句柄供后续操作使用,就像管家打开房间门并把钥匙交给你。
- 资源释放阶段:无论with代码块内的代码是正常执行完毕还是中途抛出异常,__exit__()方法都会被自动调用。该方法承担资源清理职责,关闭文件,就像你离开房间后管家会自动关灯锁门。其参数exc_type, exc_val, exc_tb专门用于接收异常信息,开发者可通过判断这些参数实现精细化的异常处理。例如:
try:
withopen('data.txt', 'r') as file:
content = file.read()
# 这里可能会出现读取文件的异常
# 列如文件损坏等情况
except FileNotFoundError:
print("文件不存在")在这个例子中,即使read()方法抛出异常,__exit__()仍会被执行,文件会被正常关闭,彻底杜绝了文件句柄泄漏的可能。
在实际开发中,我们可能需要同时操作多个文件,列如同步读写两个日志文件。使用with语句可以很优雅地实现。
# 同步读写两个日志文件
withopen('source_log.txt', 'r') as source, open('target_log.txt', 'w') as target:
for line in source:
# 这里可以对读取的日志行进行处理
# 列如添加时间戳等
new_line = line.strip() + " [processed at 2024 - 10 - 01 12:00:00]"
target.write(new_line + "
")在这个例子中,with语句同时管理了两个文件对象,确保在代码块执行完毕后,两个文件都会被正确关闭。即使在处理过程中出现异常,也能保证文件资源的正确释放,让代码更加健壮和优雅 。
2. open()函数
在 Python 的文件操作世界里,open()函数就像是一把万能钥匙,能打开不同模式的文件大门,而模式参数则决定了这扇门打开后的使用方式。
在Python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件,语法如下
open(name,mode,encoding)name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
mode:设置打开文件的模式(访问模式):只读、写入、追加等。
encoding:编码格式(推荐使用UTF-8)
示例代码
f = open('python.txt', 'r', encoding=”UTF-8)
# encoding的顺序不是第三位,所以不能用位置参数,用关键字参数直接指定只读模式(r):
就像图书馆里只能阅读不能修改书籍的规则一样,r模式用于读取文件内容。如果文件不存在,它会像一个找不到书的读者一样抛出FileNotFoundError异常。这个模式下,文件指针乖乖地位于文件开头,你只能读取内容,不能写入或修改文件。列如你要读取一篇小说文件,就可以用r模式:
try:
with open('novel.txt', 'r') as file:
content = file.read()
print(content)
except FileNotFoundError:
print("小说文件不存在")覆盖写模式(w):
这种模式有点 “霸道”,以写入模式打开文件时,若文件已存在,其原有内容会被无情清空,就像把一张写满字的纸重新擦干净;若文件不存在,则会创建一个新文件,就像准备了一张白纸。文件指针同样位于文件开头,可向文件中写入数据,多次写入会覆盖之前的内容。例如,你要创建一个新的日记文件并写入当天的心情:
with open('diary.txt', 'w') as file:
file.write("今天的心情很不错,阳光明媚,出去走了走。
")
file.write("还遇到了好久不见的朋友,聊了许多。")追加写模式(a):
它更像是在日记后面续写,用于在文件末尾添加新内容。文件不存在时同样会创建新文件。与写入模式不同,追加模式不会清空文件原有内容,文件指针始终定位在文件末尾。列如你每天都要给日记追加新的内容:
with open('diary.txt', 'a') as file:
file.write("
明天打算去看一场电影,期待!")3. read()函数
文件对象.read(num)num表明要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表明读取文件中所有的数据。
1. 无参数:读取文件全部内容
# 最佳实践:用with语句自动关闭文件
with open("test_notes.txt", "r", encoding="utf-8") as f:
all_content = f.read() # 无参数→读全部内容
print("read()无参数输出:")
print(all_content)2. 带参数:读取指定字节数
(注:中文在 UTF-8 编码下占 3 个字节,英文 / 数字占 1 个字节)
with open("test_notes.txt", "r", encoding="utf-8") as f:
part1 = f.read(15) # 读前15个字节
part2 = f.read(10) # 从上次读取位置继续读10个字节
print("read(15)结果:", part1)
print("read(10)结果:", part2)4. readlines()方法:
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
基础用法:逐行获取内容
with open("test_notes.txt", "r", encoding="utf-8") as f:
print("readline()逐行输出:")
line1 = f.readline() # 读第1行
line2 = f.readline() # 读第2行
line3 = f.readline() # 读第3行
line4 = f.readline() # 无更多内容→返回空字符串
print("第1行:", line1.strip()) # strip()去掉换行符
print("第2行:", line2.strip())
print("第3行:", line3.strip())
print("第4行(空):", repr(line4)) # repr()显示空字符串5. for循环读取文件行
for line in 文件对象必须指定encoding=”utf-8″,否则中文会乱码。
(一)基础用法:一行代码实现逐行读取
直接用for line in 文件对象即可迭代所有行,配合with语句更安全:
# 基础用法:for循环逐行读取
with open("test_notes.txt", "r", encoding="utf-8") as f:
print("for循环逐行输出:")
line_num = 1
for line in f: # 自动迭代每一行,直到文件末尾
print(f"第{line_num}行:", line.strip()) # strip()去除换行符和空格
line_num += 1(二)实战场景:比readline()更高效的业务处理
1. 日志文件关键词筛选(高频需求)
筛选error_log.txt中含「ERROR」的行,并统计数量:
def count_error_logs(log_path):
error_count = 0
error_lines = []
with open(log_path, "r", encoding="utf-8") as f:
# for循环逐行扫描,遇到ERROR则记录
for line in f:
if "ERROR" in line:
error_count += 1
error_lines.append(line.strip())
return error_count, error_lines
# 测试:假设error_log.txt含1000行内容,其中32行有ERROR
count, lines = count_error_logs("error_log.txt")
print(f"ERROR行数:{count}")
print("前5条ERROR日志:", lines[:5])2. 大文件数据清洗(内存友善型)
处理 1GB + 的user_data.csv,提取「年龄 > 30」的用户数据(无需加载全文件到内存):
def filter_adult_users(csv_path, output_path):
# 打开源文件和输出文件,同时逐行处理
with open(csv_path, "r", encoding="utf-8") as in_f,
open(output_path, "w", encoding="utf-8") as out_f:
# 先写表头
header = in_f.readline()
out_f.write(header)
# for循环处理数据行
for line in in_f:
fields = line.strip().split(",")
if len(fields) < 3: # 跳过无效行
continue
age = int(fields[2]) # 假设第3列是年龄
if age > 30:
out_f.write(line)
# 执行清洗:1GB文件仅占用几十KB内存
filter_adult_users("user_data.csv", "adult_users.csv")(三)避坑指南:for 循环读取的 3 个注意点
1. 换行符自动保留:循环中的line会包含行尾的
,需用strip()/rstrip(”
“)去除(根据需求选择,strip()会同时去空格)
# 错误示例:直接打印带换行符,导致空行
with open("test_notes.txt", "r", encoding="utf-8") as f:
for line in f:
print(line) # 每行后多一个空行
# 正确示例:用rstrip("
")只去换行符
with open("test_notes.txt", "r", encoding="utf-8") as f:
for line in f:
print(line.rstrip("
"))2. 与readlines()的本质区别:f.readlines()会把所有行加载为列表(占内存),而for line in f是迭代器(按需加载),大文件务必选后者:
# 危险操作:1GB文件用readlines()会爆内存
with open("big_file.txt", "r", encoding="utf-8") as f:
all_lines = f.readlines() # 不推荐!
# 安全操作:迭代器逐行处理
with open("big_file.txt", "r", encoding="utf-8") as f:
for line in f: # 推荐!内存占用恒定
pass6. 二进制模式b与文本模式t的本质差异
二进制模式(b):
当你处理非文本文件,如图片、音频、视频等时,就需要使用二进制模式。这些文件就像一个个神秘的宝盒,里面装的不是普通文字,而是二进制数据。二进制模式需与其他模式结合使用,如rb(二进制只读)、wb(二进制写入)、ab(二进制追加)。
以复制图片文件为例,就像把一个宝盒里的东西原封不动地搬到另一个宝盒:
with open('source_image.jpg', 'rb') as source:
with open('copy_image.jpg', 'wb') as target:
while True:
data = source.read(1024)
if not data:
break
target.write(data)文本模式(t):
这是默认模式,用于处理文本文件,就像处理普通的书籍、文章。它以字符串的形式读取和写入文件中的数据,在读取文本文件时,Python 会自动将文件中的字节解码为字符串;在写入文本文件时,Python 会自动将字符串编码为字节序列。例如读取一个普通的文本文件:
with open('article.txt', 'r') as file:
lines = file.readlines()
for line in lines:
print(line.strip())7. 编码参数encoding必知项
在处理文本文件时,编码参数encoding至关重大,它就像不同语言之间的翻译官,解决中文乱码等问题。
常见编码格式:
1. UTF – 8:它是目前最常用的编码格式,兼容性强,能够处理绝大多数语言的字符,就像一个万能翻译官,几乎能翻译所有语言。在 Python 中,许多时候默认使用 UTF – 8 编码。
2. GBK:一种针对中文字符的编码方式,适用于处理简体中文内容,更像是一个专门翻译中文的翻译官。例如读取 GBK 编码的文件:
with open('gbk_file.txt', 'r', encoding='gbk') as file:
content = file.read()
print(content)3. chardet 自动检测编码实战:有时候我们并不知道文件的编码格式,这时候chardet库就派上用场了,它像一个机智的侦探,能自动检测文件的编码。第一要安装chardet库(pip install chardet),然后使用它来检测文件编码:
import chardet
with open('unknown_encoding.txt', 'rb') as file:
data = file.read()
result = chardet.detect(data)
encoding = result['encoding']
print(f"检测到文件编码为: {encoding}")
content = data.decode(encoding, errors='ignore')
print(content)二、进阶技巧:批量处理与性能优化
(一)路径处理:告别跨平台兼容性噩梦
在 Python 文件操作的进阶之路上,路径处理是绕不开的关键环节。不同操作系统的路径表明方式就像不同国家的语言,Windows 用反斜杠 “”,而 Linux 和 macOS 则偏爱正斜杠 “/”,如果处理不当,就会导致跨平台兼容性问题,让代码在不同系统上 “水土不服” 。
1. 智能路径拼接:从字符串拼接升级到专业方案
os.path.join () 的标准用法:解决 Windows/Linux 路径分隔符差异
在 Python 中,os.path.join()函数就像一个专业的翻译官,能自动处理不同操作系统的路径分隔符问题。它接受多个路径组件作为参数,然后将它们拼接成一个完整的、符合当前操作系统规范的路径。
例如,我们要拼接一个文件路径,在 Windows 系统上可能是 “C:Usersusernamedocumentsfile.txt”,在 Linux 系统上则是 “
/home/username/documents/file.txt”。使用os.path.join()函数,代码就可以写成:
import os
# 假设我们有这些路径组件
parent_dir = 'users'
sub_dir = 'username'
file_name = 'documents/file.txt'
# 使用os.path.join()拼接路径
full_path = os.path.join(parent_dir, sub_dir, file_name)
print(full_path)Windows 系统上,它会输出 “usersusernamedocumentsfile.txt”,在 Linux 系统上则输出 “
users/username/documents/file.txt”,完美适配不同系统。
pathlib 模块进阶:支持路径对象的链式操作
pathlib模块是 Python 3.4 及以上版本提供的一个更强劲、更面向对象的路径处理方案。它将路径视为对象,支持链式操作,让路径处理更加直观和便捷。
列如我们要动态生成一个多级目录路径,可以这样做:
from pathlib import Path
# 创建一个基础路径对象
base_path = Path('project')
# 链式操作添加子目录
new_dir = base_path / 'sub_dir' / 'sub_sub_dir'
# 创建目录,如果目录已存在则忽略
new_dir.mkdir(parents=True, exist_ok=True)在这段代码中,Path类创建了路径对象,“/” 操作符用于路径拼接,就像搭积木一样简单。mkdir()方法的parents=True参数表明如果父目录不存在会自动创建,exist_ok=True参数表明如果目录已存在不会抛出异常,让代码更加健壮。pathlib模块还提供了许多其他实用的方法,如exists()检查路径是否存在,is_file()判断是否是文件等,大大提升了路径处理的效率和灵活性。
2. 批量文件过滤:glob 通配符的魔法
基础用法:*.csv 匹配所有 CSV 文件,? 匹配单字符的灵活场景
在处理文件时,常常需要根据文件名模式筛选出一批文件,glob模块的通配符就像是一把神奇的钥匙,能轻松实现这个需求。
最常用的通配符是 “*”,它可以匹配任意长度的字符(包括空字符)。例如,要获取当前目录下所有的 CSV 文件,可以使用 “.csv” 模式:
import glob
csv_files = glob.glob('*.csv')
for file in csv_files:
print(file)这段代码会输出当前目录下所有以.csv 结尾的文件名。
“?” 通配符则可以匹配任意一个字符。列如,要匹配文件名是一个字符加 “.txt” 的文件,可以用 “?.txt” 模式,像 “a.txt”“b.txt” 等都能被匹配到 。
递归搜索:glob.glob (“/*.log”, recursive=True) 深度遍历子目录的实战技巧
有时候,我们不仅要在当前目录查找文件,还需要深入子目录进行搜索。glob模块的递归搜索功能就能满足这个需求。
在 Python 3.5 及以上版本中,使用glob.glob()函数时,传入recursive=True参数,并结合 “**” 通配符,就可以实现递归搜索。例如,要查找当前目录及其所有子目录下的所有日志文件(.log 结尾),代码如下:
import glob
log_files = glob.glob('**/*.log', recursive=True)
for file in log_files:
print(file)这段代码会遍历当前目录及其所有子目录,输出所有匹配的日志文件名,在处理大型项目的日志文件管理、数据备份文件查找等场景中超级实用 。
(二)大文件处理:内存友善型操作指南
当面对大文件时,传统的一次性读取整个文件到内存的方式就像小马拉大车,很容易导致内存不足甚至程序崩溃。下面介绍两种内存友善型的大文件处理技巧,让你的代码轻松应对大文件挑战。
1. 逐行读取:处理 1GB + 文件的性能黑科技
for line in f vs readlines ():内存占用相差 3 倍的性能对比实测
在 Python 中,读取文件有多种方式,for line in f和readlines()是两种常见的读取方式,但它们在处理大文件时的性能表现却大相径庭。
for line in f这种方式是逐行读取文件,每次只读取一行内容到内存中,处理完这一行后再读取下一行,内存占用超级低。而readlines()方法则是一次性将整个文件的所有行读取到内存中,存储为一个列表,对于大文件来说,这会占用大量的内存。
我们通过一个简单的性能对比实测来直观感受一下。假设有一个 1GB 大小的文本文件,每行内容长度大致一样。分别使用这两种方式读取文件,并统计它们的内存占用情况:
import time
import psutil
import os
def read_with_for_loop(file_path):
start_time = time.time()
process = psutil.Process(os.getpid())
start_memory = process.memory_info().rss
with open(file_path, 'r') as f:
for line in f:
pass
end_memory = process.memory_info().rss
end_time = time.time()
print(f'for line in f 方式内存占用: {end_memory - start_memory} 字节')
print(f'for line in f 方式耗时: {end_time - start_time} 秒')
def read_with_readlines(file_path):
start_time = time.time()
process = psutil.Process(os.getpid())
start_memory = process.memory_info().rss
with open(file_path, 'r') as f:
lines = f.readlines()
end_memory = process.memory_info().rss
end_time = time.time()
print(f'readlines() 方式内存占用: {end_memory - start_memory} 字节')
print(f'readlines() 方式耗时: {end_time - start_time} 秒')
if __name__ == "__main__":
file_path = 'large_file.txt'
read_with_for_loop(file_path)
read_with_readlines(file_path)运行结果可能显示,for line in f方式的内存占用只有几百 KB,而readlines()方式的内存占用可能高达几百 MB 甚至 1GB 以上,内存占用相差可达 3 倍甚至更多,并且readlines()方式的读取时间也会更长,在处理大文件时性能劣势明显。
实战案例:逐行解析超大日志文件,实时统计 ERROR 级别出现次数
在实际应用中,逐行读取大文件的方式超级实用。列如,我们要处理一个超大的日志文件,实时统计其中 ERROR 级别的日志出现的次数。假设日志文件格式如下:
[2024-10-01 12:00:00] INFO: 程序启动
[2024-10-01 12:05:00] ERROR: 数据库连接失败
[2024-10-01 12:10:00] INFO: 数据查询成功使用逐行读取的方式,代码可以这样实现:
error_count = 0
with open('large_log.log', 'r') as f:
for line in f:
if 'ERROR' in line:
error_count += 1
print(f'ERROR级别出现次数: {error_count}')这段代码逐行读取日志文件,只要行中包含 “ERROR” 字符串,就将计数器加 1,高效且内存友善地完成了统计任务,即使日志文件有几十 GB 甚至更大,也能轻松应对 。
2. 内存映射文件:500MB + 二进制文件的极速处理
mmap 模块核心用法:无需加载整个文件到内存的高效读取方案
对于 500MB 以上的二进制文件,如大型图片、视频、数据库文件等,mmap模块提供了一种无需将整个文件加载到内存的高效处理方案。
mmap模块允许将文件映射到内存地址空间,就像把文件直接 “粘贴” 到内存中一样,程序可以像访问内存一样访问文件内容,而无需实际读取整个文件。这样不仅大大减少了内存占用,还能显著提高文件访问速度。
使用mmap模块的基本步骤如下:
import mmap
def read_binary_file_with_mmap(file_path):
with open(file_path, 'rb') as f:
# 创建内存映射对象
mm = mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ)
try:
# 这里可以对内存映射的文件内容进行操作
pass
finally:
# 关闭内存映射
mm.close()在这段代码中,mmap.mmap()函数创建了一个内存映射对象,第一个参数f.fileno()是文件描述符,第二个参数 0 表明映射整个文件,access=mmap.ACCESS_READ表明以只读方式访问。在操作完成后,必定要记得调用mm.close()关闭内存映射,释放资源。
1. 典型场景:在二进制日志中快速定位特定字节序列(附 mm.find (b”pattern”) 示例)
在二进制日志文件中快速定位特定字节序列是mmap模块的一个典型应用场景。假设我们有一个二进制日志文件,需要查找其中特定的字节序列 “b'ERROR'”(注意这里是字节串,由于是二进制文件),代码如下:
import mmap
def find_pattern_in_binary_log(file_path, pattern):
with open(file_path, 'rb') as f:
mm = mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ)
try:
position = mm.find(pattern)
if position != -1:
print(f'找到模式 {pattern},位置在: {position}')
else:
print(f'未找到模式 {pattern}')
finally:
mm.close()
if __name__ == "__main__":
file_path = 'binary_log.bin'
pattern = b'ERROR'
find_pattern_in_binary_log(file_path, pattern)在这段代码中,mm.find(pattern)方法用于在内存映射的文件中查找特定字节序列,返回其在文件中的位置(字节偏移量),如果未找到则返回 -1。这种方式比传统的读取整个文件再查找的方式要快得多,对于处理大型二进制日志文件超级有效 。
三、实战场景:从文本到二进制的全场景覆盖
(一)文本文件:编码处理与内容操作
1. 编码问题全攻略
显式指定编码:encoding=”utf-8″ 避免乱码的黄金法则
在 Python 中处理文本文件时,显式指定编码是避免乱码的关键。列如读取一个包含中文内容的文本文件,如果不指定编码,在不同系统或环境下可能会出现乱码。例如:
# 正确指定编码读取文件
try:
with open('chinese_text.txt', 'r', encoding='utf-8') as file:
content = file.read()
print(content)
except UnicodeDecodeError:
print("读取文件时编码错误,请检查文件编码和指定的encoding参数")在这个例子中,使用encoding='utf-8'确保了文件以 UTF – 8 编码正确读取。如果文件实际编码是 GBK,却指定了 UTF – 8,就会抛出UnicodeDecodeError异常,所以准确了解文件的实际编码超级重大。
未知编码处理:chardet 库自动检测编码的完整流程(代码实现 + 异常处理)
当我们不确定文件的编码时,chardet库就成为了我们的得力助手。下面是使用chardet库检测文件编码并读取文件的完整流程:
import chardet
def read_file_with_auto_detect(file_path):
try:
with open(file_path, 'rb') as file:
rawdata = file.read()
result = chardet.detect(rawdata)
encoding = result['encoding']
try:
content = rawdata.decode(encoding)
print(content)
except UnicodeDecodeError:
print(f"虽然检测到编码为 {encoding},但解码时仍出错,可能检测有误")
except FileNotFoundError:
print("文件不存在")
# 调用函数
read_file_with_auto_detect('unknown_encoding.txt')在这段代码中,第一以二进制模式读取文件内容,然后使用chardet.detect()方法检测文件编码。得到编码后,尝试使用该编码对文件内容进行解码。这里添加了异常处理,当检测到的编码无法正确解码文件时,会提示可能检测有误,增强了代码的健壮性。
2. 内容操作高阶技巧
增量写入:a 模式追加内容时的性能优化提议
在使用追加模式(a)写入文件时,虽然操作简单,但如果频繁写入小数据块,可能会导致性能问题,由于每次写入都会涉及磁盘 I/O 操作。为了优化性能,可以适当批量写入数据。例如,我们要记录程序运行过程中的日志信息:
import time
def log_message(message, log_file='app.log'):
buffer = []
buffer_size = 10 # 每10条日志批量写入
with open(log_file, 'a') as file:
buffer.append(f'[{time.strftime("%Y-%m-%d %H:%M:%S")}] {message}
')
if len(buffer) >= buffer_size:
file.writelines(buffer)
buffer = []
# 模拟日志记录
for i in range(50):
log_message(f'这是第{i + 1}条日志')
# 写入剩余日志
with open('app.log', 'a') as file:
if buffer:
file.writelines(buffer)在这个示例中,我们使用一个列表buffer来暂存日志信息,当列表中的日志数量达到buffer_size时,一次性批量写入文件。最后,在程序结束前,检查buffer中是否还有剩余日志,如果有则写入文件,这样可以减少磁盘 I/O 次数,提高写入性能。
正则重命名:结合 re 模块实现复杂文件名批量修改
在实际项目中,常常需要对一批文件进行重命名操作。当文件名有必定规律时,结合re模块(正则表达式)可以轻松实现复杂的文件名批量修改。列如将一批以log_YYYYMM.txt格式命名的日志文件重命名为YYYY-MM.log格式:
import os
import re
def rename_log_files(folder_path):
for filename in os.listdir(folder_path):
if os.path.isfile(os.path.join(folder_path, filename)):
match = re.search(r'log_(d{4})(d{2}).txt', filename)
if match:
year = match.group(1)
month = match.group(2)
new_filename = f'{year}-{month}.log'
old_path = os.path.join(folder_path, filename)
new_path = os.path.join(folder_path, new_filename)
os.rename(old_path, new_path)
# 调用函数,传入文件夹路径
rename_log_files('logs')在这段代码中,第一使用os.listdir()获取指定文件夹下的所有文件和文件夹名称。然后,通过re.search()函数结合正则表达式log_(d{4})(d{2}).txt来匹配符合条件的文件名。如果匹配成功,提取出年份和月份,构造新的文件名,最后使用os.rename()函数完成文件重命名操作,高效地实现了复杂文件名的批量修改。
(二)二进制文件:安全传输与高效存储
1. 二进制模式读写:图片 / 视频文件复制的标准流程(附 rb/wb 模式正确用法)
在处理二进制文件,如图片、视频时,需要使用二进制模式进行读写。以复制图片文件为例,正确的操作流程如下:
def copy_image(source_path, target_path):
with open(source_path, 'rb') as source:
with open(target_path, 'wb') as target:
while True:
data = source.read(1024)
if not data:
break
target.write(data)
# 调用函数,传入源文件路径和目标文件路径
copy_image('source.jpg', 'target.jpg')在这个示例中,使用open()函数以二进制只读模式(rb)打开源图片文件,以二进制写入模式(wb)打开目标文件。通过一个循环,每次从源文件读取 1024 字节的数据,然后写入目标文件,直到源文件读取完毕。这样可以确保图片文件的二进制数据被完整复制,避免数据丢失或损坏,是二进制文件复制的标准操作流程。
2. 压缩处理:zipfile 模块实现文件加密压缩的完整方案(含密码设置与分卷压缩技巧)
在实际应用中,常常需要对文件进行压缩处理,以节省存储空间或便于传输。Python 的zipfile模块提供了强劲的文件压缩功能,并且可以结合第三方库实现文件加密压缩。
使用 pyzipper 实现文件加密压缩:
import pyzipper
def encrypt_and_compress_files(file_paths, zip_path, password):
with pyzipper.AESZipFile(zip_path, 'w', compression=pyzipper.ZIP_DEFLATED) as zipf:
zipf.setpassword(password.encode('utf-8'))
for file_path in file_paths:
zipf.write(file_path)
# 示例文件路径列表
file_paths = ['file1.txt', 'file2.txt']
zip_path ='secure_files.zip'
password = '123456'
# 调用函数进行加密压缩
encrypt_and_compress_files(file_paths, zip_path, password)在这段代码中,第一安装pyzipper库(pip install pyzipper),它是zipfile的扩展版,支持 ZIP 文件的加密功能。使用pyzipper.AESZipFile创建一个加密的 ZIP 文件,设置压缩方式为ZIP_DEFLATED,并通过setpassword()方法设置密码(密码需以字节形式传入)。然后遍历文件路径列表,将每个文件写入加密的 ZIP 文件中,实现了文件的加密压缩。
分卷压缩技巧:
分卷压缩可以将一个大文件或多个文件压缩成多个小的压缩包,方便存储和传输。zipfile模块本身不直接支持分卷压缩,但可以通过一些技巧实现。例如,我们可以先将文件按必定大小分块,然后分别压缩每个分块:
import zipfile
import os
def split_and_compress(file_path, chunk_size, zip_folder):
if not os.path.exists(zip_folder):
os.makedirs(zip_folder)
part_number = 1
with open(file_path, 'rb') as source:
while True:
chunk = source.read(chunk_size)
if not chunk:
break
zip_path = os.path.join(zip_folder, f'part_{part_number:03d}.zip')
with zipfile.ZipFile(zip_path, 'w') as zipf:
zipf.writestr(os.path.basename(file_path), chunk)
part_number += 1
# 示例文件路径
file_path = 'large_file.bin'
chunk_size = 1024 * 1024 * 10 # 每10MB一个分卷
zip_folder ='split_zips'
# 调用函数进行分卷压缩
split_and_compress(file_path, chunk_size, zip_folder)在这个示例中,定义了split_and_compress()函数,它接受源文件路径、分卷大小和目标压缩文件夹路径作为参数。第一检查目标压缩文件夹是否存在,不存在则创建。然后以二进制模式读取源文件,每次读取chunk_size大小的数据块,将每个数据块写入一个新的 ZIP 文件中,ZIP 文件命名为part_XXX.zip(XXX为三位数字的分卷编号),实现了文件的分卷压缩 。
四、避坑指南:10 个高频错误与解决方案
(一)常见异常处理
1. FileNotFoundError:路径检查的 3 个必备步骤(os.path.exists ()/os.path.abspath () 用法)
在 Python 文件操作中,FileNotFoundError是一个常见的异常,它就像一个讨厌的小怪兽,当你尝试打开一个不存在的文件时,它就会跳出来捣乱。为了打败这个小怪兽,我们需要掌握路径检查的 3 个必备步骤 。
步骤一:使用os.path.exists()检查文件是否存在
os.path.exists()函数就像一个探测器,它可以检查指定路径的文件或目录是否存在。例如:
import os
file_path = 'test.txt'
if not os.path.exists(file_path):
print(f'文件 {file_path} 不存在')
else:
with open(file_path, 'r') as file:
content = file.read()
print(content)在这段代码中,第一使用os.path.exists()检查文件是否存在,如果不存在则打印提示信息,避免了直接打开文件时抛出FileNotFoundError异常。
步骤二:使用os.path.abspath()获取绝对路径
有时候,我们使用的路径可能是相对路径,这在不同的工作目录下可能会导致文件找不到。os.path.abspath()函数可以将相对路径转换为绝对路径,确保路径的准确性。例如:
import os
relative_path = 'test.txt'
absolute_path = os.path.abspath(relative_path)
print(f'绝对路径: {absolute_path}')
if not os.path.exists(absolute_path):
print(f'文件 {absolute_path} 不存在')
else:
with open(absolute_path, 'r') as file:
content = file.read()
print(content)在这个例子中,先将相对路径转换为绝对路径,然后再检查文件是否存在,进一步提高了路径的可靠性。
步骤三:异常处理机制
即使我们做了前面的路径检查,依旧可能由于其他缘由导致文件找不到(列如文件在检查后被删除等情况),所以使用异常处理机制是一个好习惯。例如:
import os
file_path = 'test.txt'
try:
with open(file_path, 'r') as file:
content = file.read()
print(content)
except FileNotFoundError:
if not os.path.exists(file_path):
print(f'文件 {file_path} 不存在')
else:
print(f'无法打开文件 {file_path},可能存在其他问题')在这个代码块中,使用try – except结构捕获FileNotFoundError异常。如果文件不存在,根据os.path.exists()的检查结果给出不同的提示信息,增强了代码的健壮性。
2. UnicodeDecodeError:编码不匹配时的排查流程(从文件保存格式到代码参数设置)
当你在 Python 中处理文本文件时,UnicodeDecodeError异常就像一个隐藏的陷阱,可能会突然出现,让你的程序陷入困境。它一般是由于编码不匹配导致的,下面是排查这个问题的详细流程 。
第一步:确认文件的实际保存格式
文件的实际保存格式是解决编码问题的关键。可以使用一些工具来查看文件的编码,列如在 Windows 系统中,可以用 Notepad++ 打开文件,然后在 “编码” 菜单中查看文件的编码格式;在 Linux 系统中,可以使用file -i命令来查看文件编码,例如file -i test.txt。如果不确定文件编码,还可以使用chardet库来自动检测,如前文所述:
import chardet
with open('unknown_encoding.txt', 'rb') as file:
data = file.read()
result = chardet.detect(data)
encoding = result['encoding']
print(f'检测到文件编码为: {encoding}')第二步:检查代码中的编码参数设置
在 Python 中,使用open()函数打开文件时,可以通过encoding参数指定编码。确保代码中指定的编码与文件的实际编码一致。例如,如果文件是 UTF – 8 编码,代码应该这样写:
try:
with open('test.txt', 'r', encoding='utf-8') as file:
content = file.read()
print(content)
except UnicodeDecodeError:
print('编码错误,请检查文件编码和指定的encoding参数')如果文件实际是 GBK 编码,却指定了 UTF – 8,就会抛出UnicodeDecodeError异常。
第三步:处理可能的编码转换问题
有时候,我们需要将文件从一种编码转换为另一种编码。可以先以文件的实际编码读取文件内容,然后再以目标编码写入新文件。例如,将一个 GBK 编码的文件转换为 UTF – 8 编码:
with open('gbk_file.txt', 'r', encoding='gbk') as source:
content = source.read()
with open('utf8_file.txt', 'w', encoding='utf-8') as target:
target.write(content)通过这样的步骤,从文件保存格式的确认,到代码中编码参数的检查,再到可能的编码转换处理,能够有效排查和解决UnicodeDecodeError异常,确保文本文件处理的正确性。
(二)性能与安全优化
1. 缓冲区刷新:flush () 方法的适用场景,避免数据丢失的关键操作
在 Python 文件操作中,缓冲区就像一个临时的小仓库,数据会先存储在缓冲区中,然后再批量写入文件,这样可以提高写入效率。但是,如果在某些情况下不及时刷新缓冲区,就可能导致数据丢失,这时候flush()方法就发挥了重大作用 。
适用场景一:实时日志记录
在实时日志记录场景中,我们希望日志信息能够及时写入文件,以便随时查看。例如,一个监控程序的日志记录:
import time
with open('monitor.log', 'a') as log_file:
for i in range(10):
log_message = f'[{time.strftime("%Y-%m-%d %H:%M:%S")}] 监控信息 {i}
'
log_file.write(log_message)
log_file.flush() # 立即将日志信息写入文件
time.sleep(1)在这个例子中,每次写入日志信息后,都调用flush()方法,确保日志信息及时写入文件,而不是等到缓冲区满了或者文件关闭时才写入。
适用场景二:交互式数据处理
当进行交互式数据处理时,用户可能会等待文件写入结果,这时候及时刷新缓冲区可以提供更好的用户体验。列如,一个简单的用户输入保存程序:
with open('user_input.txt', 'w') as file:
while True:
user_input = input('请输入内容(输入q结束):')
if user_input.lower() == 'q':
break
file.write(user_input + '
')
file.flush() # 及时保存用户输入在这个程序中,用户每输入一行内容,就调用flush()方法将内容写入文件,用户可以随时查看文件内容,而不用等到程序结束。
2. 文件锁机制:多进程同时写入时的并发控制方案(fcntl 模块基础用法)
在多进程编程中,如果多个进程同时写入同一个文件,就可能导致数据混乱,就像多个人同时在一张纸上写字,最后字迹会变得杂乱无章。文件锁机制可以解决这个问题,Python 的fcntl模块提供了文件锁定的功能 。
fcntl模块基础用法
fcntl模块主要用于 Unix/Linux 系统,它提供了文件控制操作的接口。要使用文件锁,第一需要导入fcntl模块,然后使用fcntl.flock()函数来实现文件锁定。例如:
import fcntl
import os
import time
def lock_file(file):
fcntl.flock(file.fileno(), fcntl.LOCK_EX) # 加独占锁
def unlock_file(file):
fcntl.flock(file.fileno(), fcntl.LOCK_UN) # 解锁
# 打开文件
with open('shared_file.txt', 'a') as f:
lock_file(f) # 加锁
try:
f.write(f'[{time.strftime("%Y-%m-%d %H:%M:%S")}] 写入内容
')
time.sleep(1) # 模拟写入操作
finally:
unlock_file(f) # 解锁在这段代码中,定义了lock_file()和unlock_file()函数分别用于加锁和解锁。在写入文件前先加独占锁,确保同一时间只有一个进程可以写入文件,写入完成后解锁,让其他进程有机会写入。
Windows 系统的替代方案
在 Windows 系统中,fcntl模块的功能并不完全可用,但可以使用msvcrt模块来模拟文件锁功能。例如:
import os
import msvcrt
import time
def lock_file(file):
msvcrt.locking(file.fileno(), msvcrt.LK_LOCK, 1) # 加锁
def unlock_file(file):
msvcrt.locking(file.fileno(), msvcrt.LK_UNLCK, 1) # 解锁
# 打开文件
with open('shared_file.txt', 'a') as f:
lock_file(f) # 加锁
try:
f.write(f'[{time.strftime("%Y-%m-%d %H:%M:%S")}] 写入内容
')
time.sleep(1) # 模拟写入操作
finally:
unlock_file(f) # 解锁通过这样的文件锁机制,无论是在 Unix/Linux 系统还是 Windows 系统,都能有效地控制多进程同时写入文件时的并发问题,保证数据的完整性和一致性。
五、实战案例:日志分析系统开发实录
(一)需求拆解
在实际的软件开发与运维中,日志文件是记录系统运行状态和事件的关键载体,通过对日志的分析,我们能快速定位系统问题、优化性能以及进行安全审计等。本案例的目标是开发一个简单但实用的日志分析系统,核心任务是统计指定目录下所有日志文件中 ERROR/WARNING 级别的数量。
1. 目标:统计指定目录下所有日志文件中 ERROR/WARNING 级别的数量
这一目标明确了我们的任务方向。想象一下,一个大型的 Web 应用程序,每天会产生大量的日志文件,这些日志文件散布在服务器的某个目录下。我们的系统需要像一个勤劳的小管家,遍历这个目录及其子目录,找出所有的日志文件,然后逐行分析这些文件,统计出其中 ERROR 和 WARNING 级别的日志数量,以便开发人员和运维人员能快速了解系统的健康状况。
技术选型:glob 批量获取文件 + with 语句安全读取 + 逐行分析的高效架构
glob 批量获取文件:glob模块就像是一个拥有神奇魔法的小精灵,它能根据我们设定的通配符模式,轻松地在指定目录及其子目录中找到所有符合条件的文件。例如,我们可以使用glob.glob('logs/**/*.log', recursive=True)来获取logs目录及其所有子目录下的所有日志文件,避免了手动遍历目录的繁琐操作。
with 语句安全读取:在读取日志文件时,with语句就像是一位可靠的保镖,确保文件在使用完毕后被正确关闭,防止资源泄漏。列如with open(log_file, 'r') as f:,这样无论在文件读取过程中是否发生异常,文件都会被安全关闭,保证了系统的稳定性。
逐行分析的高效架构:对于大文件处理,逐行分析是一种超级高效的方式,它避免了一次性将整个文件读入内存带来的内存压力。我们可以通过for line in f:这样的循环,逐行读取日志文件内容,然后使用简单的字符串匹配来判断该行是否包含 ERROR 或 WARNING 关键字,从而实现高效的日志级别统计。
(二)代码实现
import glob
def count_error_warning(log_dir):
error_count = 0
warning_count = 0
for log_file in glob.glob(f'{log_dir}/**/*.log', recursive=True):
with open(log_file, 'r') as f:
for line in f:
if 'ERROR' in line:
error_count += 1
elif 'WARNING' in line:
warning_count += 1
return error_count, warning_count
if __name__ == "__main__":
log_directory = 'your_log_directory'
error_num, warning_num = count_error_warning(log_directory)
print(f'ERROR级别的日志数量: {error_num}')
print(f'WARNING级别的日志数量: {warning_num}')在这段代码中,count_error_warning函数第一使用glob.glob获取指定目录下的所有日志文件。然后,通过with语句打开每个日志文件,利用for line in f逐行读取文件内容。在每一行中,使用in关键字判断是否包含ERROR或WARNING字符串,如果包含则相应的计数器加 1。最后,返回统计结果。在__main__部分,指定了日志目录并调用函数进行统计,输出结果。
(三)优化方向
1. 多线程加速:使用 concurrent.futures 模块并行处理多个日志文件
在处理大量日志文件时,单线程处理可能会比较耗时。这时候,多线程技术就可以派上用场了。concurrent.futures模块为我们提供了一个高级接口来实现多线程操作。
import concurrent.futures
import glob
def process_log(log_file):
error_count = 0
warning_count = 0
with open(log_file, 'r') as f:
for line in f:
if 'ERROR' in line:
error_count += 1
elif 'WARNING' in line:
warning_count += 1
return error_count, warning_count
def count_error_warning_parallel(log_dir):
error_count = 0
warning_count = 0
log_files = glob.glob(f'{log_dir}/**/*.log', recursive=True)
with concurrent.futures.ThreadPoolExecutor() as executor:
results = list(executor.map(process_log, log_files))
for sub_error_count, sub_warning_count in results:
error_count += sub_error_count
warning_count += sub_warning_count
return error_count, warning_count
if __name__ == "__main__":
log_directory = 'your_log_directory'
error_num, warning_num = count_error_warning_parallel(log_directory)
print(f'ERROR级别的日志数量: {error_num}')
print(f'WARNING级别的日志数量: {warning_num}')在优化后的代码中,定义了process_log函数来处理单个日志文件并统计 ERROR 和 WARNING 的数量。
count_error_warning_parallel函数使用
concurrent.futures.ThreadPoolExecutor创建一个线程池,通过executor.map将process_log函数应用到每个日志文件上,实现并行处理。最后,汇总每个线程的统计结果,得到总的 ERROR 和 WARNING 数量。这种方式可以显著提高处理大量日志文件的速度,尤其是在 I/O 密集型的文件读取操作中 。
2. 结果持久化:将统计结果写入 CSV 文件的完整流程(附 csv 模块用法)
统计出日志级别数量后,将结果持久化到 CSV 文件中是一个很好的做法,方便后续的数据分析和报告生成。Python 的csv模块提供了简单易用的 CSV 文件读写功能。
import csv
import glob
def count_error_warning(log_dir):
error_count = 0
warning_count = 0
for log_file in glob.glob(f'{log_dir}/**/*.log', recursive=True):
with open(log_file, 'r') as f:
for line in f:
if 'ERROR' in line:
error_count += 1
elif 'WARNING' in line:
warning_count += 1
return error_count, warning_count
def save_to_csv(error_count, warning_count, output_file):
data = [
['日志级别', '数量'],
['ERROR', error_count],
['WARNING', warning_count]
]
with open(output_file, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerows(data)
if __name__ == "__main__":
log_directory = 'your_log_directory'
error_num, warning_num = count_error_warning(log_directory)
output_csv = 'log_summary.csv'
save_to_csv(error_num, warning_num, output_csv)在这段代码中,save_to_csv函数负责将统计结果写入 CSV 文件。第一,构建一个包含表头和统计数据的二维列表data。然后,使用csv.writer创建一个 CSV 写入对象,通过writer.writerows方法将数据写入到指定的 CSV 文件中。newline=''参数用于确保在不同操作系统上都能正确处理换行符,encoding='utf-8'指定文件编码为 UTF – 8,以支持各种字符的写入 。通过这样的优化,不仅提高了日志分析系统的效率,还增强了结果的可存储性和可分析性。
掌握文件操作技巧,不仅能让日常开发效率提升 80%,更能避免 90% 的文件处理陷阱。无论是处理日均千级的文件批量操作,还是应对复杂的跨平台兼容性问题,这些实战经验都能成为你的核心竞争力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。











比较全面,学习了
收藏了,感谢分享