
文章目录
一、论文信息摘要1. 引言2. 相关工作2.1 两阶段检测器2.2 单阶段检测器2.3 Transformer检测器
3. 方法与设计3.1 系统概述3.2 全局注意力模块3.3 级联融合网络3.4 软非极大值抑制(Soft-NMS)
4. 实验4.1 实现细节4.2 数据集4.3 评估指标4.4 数据增强4.5 实验结果与分析4.5.1 GC-Net与先前方法的比较
4.6 消融实验4.6.1 GAM的消融实验4.6.2 CFN的消融实验4.6.3 Soft-NMS的效果
5. 结论References
一、论文信息
论文题目:Global attention module and cascade fusion network for steel surface defect detection中文题目:用于钢表面缺陷检测的全局注意力模块与级联融合网络发表期刊:Pattern Recognition论文链接:点击跳转代码链接:点击跳转核心速览:针对钢表面缺陷检测的多尺度、非结构化、数据稀缺三大挑战,提出 GC-Net 网络。通过全局注意力模块、级联融合网络、Soft-NMS 后处理及数据增强技术,在 NEU-DET 和 GC10-DET 数据集上实现 mAP50 分别为 0.771 和 0.635,性能优于主流方法。
摘要
钢表面缺陷检测在当代社会中发挥着关键作用,保障建筑和制造业的质量与安全,降低生产成本,提高效率,并推动技术创新。然而,这项任务面临诸多挑战,包括处理非结构化特征、多尺度问题以及可用数据稀缺的问题。为了克服这些挑战,本文提出了一种用于钢表面缺陷检测的全局注意力模块和级联融合网络,称为GC-Net。在该网络中,全局注意力模块的提出是为了增强模型处理非结构化缺陷的能力。随后,设计了级联融合网络用于多尺度特征融合,从而提高对不同尺度缺陷的检测精度。在此之后,在后期处理阶段应用软非极大值抑制来消除冗余检测框,进一步提升网络的检测性能。最后,在实验阶段采用了一系列数据增强技术,包括过采样和小目标增强,以缓解数据稀缺问题。在两个钢表面缺陷检测数据集上的实验结果表明,所提出的方法在mAP50指标上优于现有最先进的方法(NEU-DET:0.771,GC10-DET:0.635)。代码发布于https://github.com/Ghlerrix/GC-Net。
1. 引言
在21世纪,钢铁生产技术的进步已成为一个国家工业发展的关键指标。各种钢铁产品,包括板材、带材、卷材和棒材,在航空航天、汽车和建筑等行业中发挥着不可或缺的作用[1]。随着社会经济格局的演变,钢铁企业逐渐开始追求高智能化、高精度、高附加值的生产模式。在此背景下,钢铁表面缺陷的精细检测得到了钢铁企业的持续关注和研究,成为确保其钢铁产品质量的关键手段。
由于实际钢板生产过程的复杂性,不仅不同生产线之间存在差异,而且不同批次之间也存在差异。因此,钢铁表面缺陷检测领域面临着若干挑战:

(1)多尺度复杂性:生产过程中钢板上的缺陷以多尺度形式呈现,缺陷尺寸差异显著。在图1(a)中,红框内的小缺陷仅跨越几个像素,而图1(b)展示了黄框内的较大缺陷,占据了整个图像的很大一部分。
(2)非结构化特征:与其他应用不同,一些钢铁表面缺陷的结构缺乏统一性。如图1©所示,绿框内的某些缺陷缺乏完整结构,呈现出视觉上碎片化的外观。
(3)发生稀缺性:一些缺陷在钢板生产线中出现的概率极低。然而,当它们确实出现时,会引发严重的质量问题。这些罕见但影响重大的缺陷因其可能损害钢铁产品的整体质量而需要得到高度关注。
在历史上,钢铁表面缺陷检测的早期方法主要包括人工检测、涡流检测、红外检测、漏磁检测和超声检测。虽然这些方法取得了显著进展,但它们仍然难以解决上述问题。
近年来,计算机视觉检测方法在钢铁表面缺陷识别中得到了广泛应用,逐渐缓解了上述挑战。Yazdchi等人提出了一种基于分形的突破性缺陷检测算法,该算法通过神经网络驱动的特征识别增强了制造能力,显著提高了产品质量和生产效率[2]。Wang等人提出了一种针对识别表面缺陷的实体稀疏性追求方法,为工业灰度图像中的特征稀缺问题量身定制了直观的缺陷检测特征[3]。尽管这些方法取得了成功,但它们存在局限性,因为它们需要最佳的光源条件和高端的图像采集设备,使得实施和维护成本高昂。此外,它们的特异性可能阻碍其扩展到通用的钢铁表面缺陷检测。
得益于计算机硬件的显著进步,深度学习在各种工业应用中已成为一种强大的工具,取得了令人印象深刻的成果。具体而言,主要基于卷积神经网络(CNN)的众多深度学习网络已被应用于缺陷检测领域。这些网络通过利用多样且复杂的网络结构和模块,在缺陷检测方面表现出色。
对于多尺度问题:网络必须具备在各种尺度上提取和处理信息的能力。目前,跨不同尺度整合信息的主要策略是通过使用特征金字塔网络(FPN)[4]及其演变形式[5]。Yu等人在他们的网络中引入了一种新颖的特征融合技术,其中双向特征融合网络取代了传统的FPN,有效增强了多层特征的整合,减少了特征损失,并显著提高了带钢缺陷检测性能[6]。受级联概念的启发,本文构建了用于特征融合操作的级联结构FPN,称为级联融合网络(CFN)。它可以通过调整级联层数来适应各种任务的多尺度融合需求,提供更强的灵活性和可扩展性。
对于非结构化问题:深度学习网络始终需要更丰富的特征信息集。在许多基于CNN的模型中,扩展感受野和引入注意力模块是捕捉更多特征信息的常用方法。Young等人开发了一种融合注意力模块,增强通道和空间特征信息,以应对缺陷的形状变化,实现对这些形状各异的缺陷的精确定位和分类[7]。然而,对于非结构化缺陷,这些基于注意力的方法仍有改进空间。为此,本文将Transformer的自注意力机制整合到特征提取网络中。Transformer的自注意力机制增强了网络的全局特征提取能力,以构建长程依赖关系。这种能力允许网络有效地融合来自不同位置的全局和不连贯信息,从而更全面地理解视觉上下文,并显著提高网络处理非结构化问题的性能。
对于稀缺问题:基于深度学习的检测模型严重依赖问题数据。虽然收集更多数据在工业环境中可能成本高昂,但可以通过利用计算机视觉技术、生成对抗网络(GAN)[9]等进行人工数据增强,等等。Ran等人采用基于草图的空间自适应归一化和高电平特征约束,实现了钢铁表面缺陷数据的生成[10]。除了这些具有成本效益的增强策略外,还可以采用过采样和小目标数据增强等数据增强技术。本文采用了这些数据增强技术,包括过采样和小目标数据增强,通过多样化数据集和增强模型在各种场景下的泛化能力,有效提高检测精度。
针对上述挑战,本文深入研究了最新的理论进展,基于YOLOv8构建了一个钢铁表面缺陷检测框架。它对两个具有区别性的钢铁表面缺陷数据集进行了全面的实验分析。这些实验的结果有力地证明了本文提出的方法的有效性。
综上所述,本文的关键贡献如下:
(1)设计了全局注意力模块(GAM)作为特征提取网络的一部分,以增强网络捕捉与缺陷相关的全局多尺度融合特征的能力。
(2)提出了级联融合网络(CFN),以有效提高模型的多尺度融合能力,并妥善解决尺度多样性的问题。
(3)在后期处理中使用软非极大值抑制(Soft-NMS),以帮助抑制重叠边界框的出现,通过减少冗余来提高检测精度。
(4)在实验阶段使用过采样和小目标数据增强技术,以缓解稀缺缺陷数据的问题。
2. 相关工作
随着计算机处理能力的不断提升,基于深度学习的检测技术正逐渐成为主流。这些技术可根据其检测流程和网络架构大致分为两阶段检测器、单阶段检测器和Transformer检测器。
2.1 两阶段检测器
两阶段检测的主要代表是基于区域的卷积神经网络(R-CNN)[11]和Faster R-CNN [12]。自问世以来,这些检测器在钢铁行业及其他领域的缺陷检测中得到了广泛应用。Ren等人整合了深度可分离卷积和中心损失,构建了一个更轻量化的Faster R-CNN,在钢铁表面缺陷检测中展现出卓越的精度和效率[13]。Tong等人在Faster R-CNN中加入了特征融合增强模块、可变形卷积模块和上下文池化模块,以提高检测器的精度和召回率[14]。
2.2 单阶段检测器
单阶段检测器的主要代表是You Only Look Once(YOLO)[15]。除YOLO系列外,著名的单阶段检测器还包括单发多框检测器(SSD)[16]等若干其他模型。这些检测器推理速度更快,使其非常适合钢铁表面缺陷检测领域的应用。Qian等人通过整合轻量化特征融合网络、自适应感受野特征提取和焦点损失,提出了带有轻量化特征融合网络的YOLO,以提高工业表面缺陷识别的检测速度和精度[17]。Ren等人通过整合注意力机制和多特征融合网络,引入了增强版的SSD模型,显著提高了热轧带钢表面缺陷检测的精度和速度,从而满足了工业质量检测的需求[18]。
2.3 Transformer检测器
近年来,大模型技术的关注度大幅上升。值得注意的是,Transformer架构引起了极大关注并取得了显著成功,其基于Transformer的模型在缺陷检测领域被广泛采用。Dang等人设计了一个高效且鲁棒的新型下水道缺陷检测系统,该系统基于检测Transformer检测器,在人工验证的下水道缺陷数据集上优于以往的标准目标检测算法[19]。Zhou等人通过整合轻量化视觉Transformer和通道调制的特征金字塔网络,开发了一个高效的基于Transformer的表面缺陷检测网络[20]。Wang等人提出了一种高效的CNN和Transformer混合架构,该架构在缺陷检测中捕捉局部和非局部关系,在表面缺陷检测中取得了出色的结果[21]。
3. 方法与设计
3.1 系统概述
在本研究中,钢铁表面缺陷检测算法被视为一项基于图像的检测任务。整个算法的架构分为四个主要部分:(1) 作为基准框架的YOLOv8;(2) 用于特征提取的骨干网络,该网络集成了两种不同的全局注意力模块(GAM);(3) 用于特征融合的级联融合网络(CFN);以及(4) 用于去除冗余检测边界框的软非极大值抑制(Soft-NMS),如图2所示。
(1) 首先,YOLOv8是YOLO系列的重大演进,在其前代成功的基础上,引入了创新特性和改进,以增强整体性能和适应性。与YOLOv7 [15]的设计理念一致,YOLOv8对骨干网络和颈部组件进行了优化,选择C2f结构而非YOLOv5 [22]中采用的C3结构。同时,它采用了解耦头和无锚框结构,顺应了当代趋势。为了进一步构建其稳健的架构,YOLOv8采用了先进的正样本分配策略。具体而言,它整合了任务对齐分配器方法 [23] 以优化正样本的分配。此外,该模型利用分布焦点损失 [24] 进行精确的损失计算。
(2) 接下来,提出在骨干网络中使用全局注意力模块(GAM)以改进特征提取。它可以更好地提取全局信息并构建长距离依赖关系。然而,仅基于多头自注意力(MSA)的GAM在浅层提取特征时会带来大量冗余。因此,在浅层的GAM中应用基于稀疏化的轴向注意力(AA)将带来更好的特征提取效果。
(3) 然后,将提取的多个特征图输入级联融合网络进行特征融合,使整个模型更充分地掌握多尺度特征信息。在此,我们通过采用三级联阶段来平衡融合效果和计算开销。
(4) 最后,使用Soft-NMS去除检测产生的冗余检测框。它比传统的非极大值抑制(NMS)更温和,并且在抑制冗余检测边界框方面更灵活,有助于保留一些置信度较低的检测边界框。
3.2 全局注意力模块
基于CNN的深度学习检测算法通常依赖卷积核从图像中提取局部信息。然而,钢铁表面的某些缺陷表现出非结构化特征,如图1©所示。这些特征对仅基于局部信息的精确检测构成了挑战。
Transformer中的多头自注意力(MSA)在建立长距离依赖关系和捕捉全局信息方面已表现出显著的有效性。它是自注意力的扩展版本,专门用于增强模型的整体表示能力。
此外,文献[25]中的研究表明,MSA和卷积起到互补作用,并举例说明如何将MSA无缝集成到CNN中。为了增强缺陷检测,设计在骨干网络的每个阶段应用GAM,以促进更复杂特征信息的提取。

如图3(a)所示,GAM由两个1×1卷积和一个MSA组成的残差模块构成。这种由MSA组成的GAM称为GAM-M。此外,提出将局部空间注意力模块(LSAM)应用于每个模块的残差分支,进一步提高模型捕捉全局特征的能力。
然而,文献[26]中的研究发现,模型表层的注意力矩阵具有限制性和稀疏性。因此,在表层使用如MSA之类的全局注意力机制会引入相当大的计算冗余。
为应对这一挑战,GAM中的MSA被AA [27] 替代,如图3(b)所示。这种由AA组成的GAM称为GAM-A。AA是一种专门且高效的注意力模块,能够对不同维度的输入数据处理进行加权。这使得每个维度可以独立处理,同时保留多维信息。
通常,在标准注意力机制中,对于给定的输入序列X = [x₁, x₂, …, xₙ],Yᵢ是第i个自注意力输出向量,计算如下:
其中n是序列中元素的总数,Vⱼ是第j个值向量,Aᵢⱼ是第i个查询Qᵢ对第j个键向量Kⱼ的注意力权重,计算如下:
其中Kₖ是第k个键向量,向量Q、K和V通过将输入X与各自的学习权重矩阵W_q、W_k和W_v相乘得到,如下所示:
当标准注意力被分成多个头时,输出Yᵢ的计算如下:
其中Concat是张量拼接操作,Yᵢ⁽ʰ⁾是第h个头的输出,Wₒ是最终输出权重矩阵。
对于AA,它在行和列方向上对输入X进行划分,得到X_row和X_col。随后,分别对X_row和X_col应用标准自注意力。最后,将这两个注意力过程的输出组合以产生最终输出Y,如下所述:
其中
Y
ᵢ
r
o
w
Y_{ᵢ}^{row}
Yᵢrow和
Y
ᵢ
c
o
l
Y_{ᵢ}^{col}
Yᵢcol分别是X_row和X_col的第i个输出。
此外,GAM残差分支上的LSAM将局部注意力计算整合到空间注意力模块中 [28]。具体来说,LSAM首先通过1×1卷积、平均池化和最大池化操作分别对输入特征图进行降维。随后,将这三个生成的特征图拼接并使用Sigmoid激活函数进行归一化,得到一个综合的空间注意力图。LSAM的数学表达式如下:
其中f¹ˣ¹和f⁷ˣ⁷分别表示1×1卷积和7×7卷积的操作;F是输入特征,σ是Sigmoid函数;
F
a
v
g
S
F_{avg}^S
FavgS和
F
m
a
x
S
F_{max}^S
FmaxS分别是平均池化特征和最大池化特征。
在骨干网络的最后三个阶段中,前两个阶段采用带有AA的GAM来提取浅层信息,而最后一个阶段采用带有MSA的GAM。这种策略性组合适应了该部分特征图固有的小尺寸特点。尽管它们的尺寸不大,但这些特征图包含了丰富的高维信息。
本质上,通过将两种形式的GAM整合到骨干网络中,模型能够巧妙地聚焦于上下文信息,从而提高缺陷检测的准确性。
3.3 级联融合网络
众所周知,多尺度融合在深度学习检测算法中起着关键作用。主流算法利用特征金字塔网络(FPN)及其变体来提取多尺度特征。这些技术不仅有助于目标识别,还能提高目标定位的精度。然而,FPN采用的融合方法相对简单,本质上是将两个尺度的特征图堆叠在一起。在处理钢铁表面缺陷时,这种简单性尤为明显。复杂的背景复杂性和缺陷的多样性往往导致大量冗余特征信息的产生。
先进的YOLOv8中实施的特征融合策略灵感来源于创新的路径聚合网络(PAN),旨在优化不同尺度特征的融合。
PAN引入了水平和垂直的信息传递路径,提供了一种增强特征融合能力的复杂机制。然而,必须注意的是,在YOLOv8的特征融合阶段引入这些补充路径和信息传递机制,会导致模型整体计算复杂度的上升。增加的计算需求可能会影响模型的效率,而这些额外组件带来的复杂性需要更细致地选择超参数,以确保最佳性能。
受级联概念的启发,我们提出了级联融合网络(CFN)来增强缺陷检测性能。CFN在基本FPN之后引入了
n
n
n个级联阶段用于多尺度特征融合。每个级联阶段保持相同的结构,如图4所示。首先,在CFN中应用FPN传统的自上而下的上采样融合。其中穿插使用YOLOv8中提出的C2f进行进一步的特征提取。然后,使用经典的卷积下采样结构来获取下一个级联阶段所需的输入。这使得CFN在级联多个阶段时能够保持最佳效率。
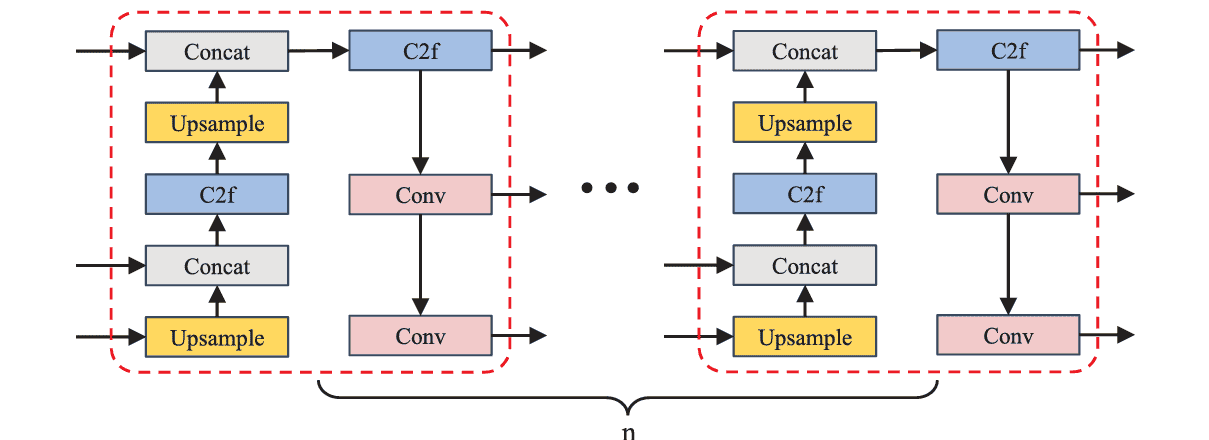
与其他特征融合网络相比,CFN具有更大的灵活性。其自上而下的融合分支确保了足够的融合效果。此外,卷积下采样结构为获取后续级联阶段或后续检测网络所需的输入特征图提供了便捷的方式。而且,它可以通过调整级联阶段的数量来实现强大的可扩展性,以适应不同尺度的模型和不同分布的数据集。因此,CFN能够巧妙地捕捉钢铁表面缺陷数据集中的尺度变化,从而提高整体检测精度。
3.4 软非极大值抑制(Soft-NMS)
在深度学习检测算法领域,单个目标存在大量候选边界框是一个常见挑战。为了解决这个问题,Neubeck和Van Gool于2006年提出的NMS算法被频繁使用[29]。NMS有效地消除了交并比(IoU)低于预定义阈值的重叠边界框。然而,确定一个最优阈值被证明是一项艰巨的任务。将阈值设置得过低可能会无意中移除许多准确识别的候选边界框,而阈值设置得过高可能会增加误检的风险。Bodla等人于2017年提出的Soft-NMS [30] 为这一困境提供了一个有说服力的解决方案。它不是直接丢弃所有IoU大于阈值的框,而是采用一种更细致的方法。
它系统地降低了这些框的置信度,提供了一种精细且灵活的方法来管理重叠边界框。其表达式如下:
其中,
s
i
s_i
si、
b
i
mathbf{b}_i
bi、
M
mathbf{M}
M、
N
t
N_t
Nt和
calloU
ext{calloU}
calloU分别表示第
i
i
i个候选边界框的得分、待处理的第
i
i
i个候选边界框、当前得分最高的候选边界框、Soft-NMS算法的阈值以及计算IoU的函数。当
b
i
mathbf{b}_i
bi和
M
mathbf{M}
M的IoU越大时,
b
i
mathbf{b}_i
bi的得分
s
i
s_i
si下降得越多。因此,Soft-NMS可以抑制重叠的候选边界框,提高检测效果。
4. 实验
4.1 实现细节
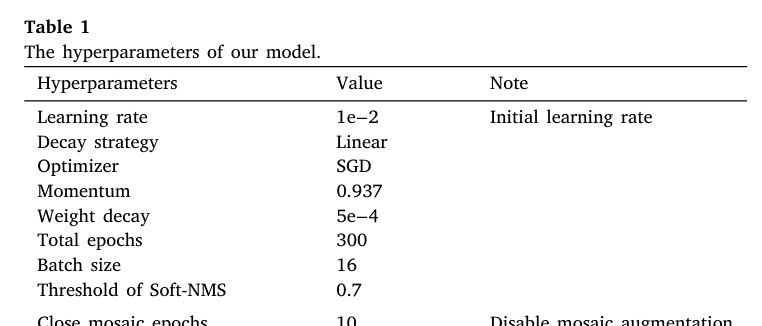
本文提出的方法是在Visual Studio Code集成开发环境中实现的。训练程序在运行Ubuntu 20.04 Linux的计算环境上执行,该环境配备了四块NVIDIA RTX3090 GPU,每块显存为24 GB。软件环境包括Python 3.8.17、PyTorch 1.13.1、CUDA 11.7和cuDNN 8.9.2。模型超参数设置见表1。
4.2 数据集
本文通过两个专注于钢铁表面缺陷的不同数据集验证,证实了所提方法的可行性:NEU-DET数据集[31]和GC10-DET数据集[32]。
NEU-DET数据集:NEU-DET数据集由东北大学慷慨提供,是评估和验证钢板表面缺陷检测算法的专用资源。该数据集涵盖了工业生产中常见的各种挑战,包括划痕(Sc)、斑块(Pa)、夹杂(In)、氧化铁皮压入(RS)、麻点表面(PS)和裂纹(Cr)。该缺陷图像集合在研究中被广泛使用,便于对检测算法进行比较和研究,其首要目标是提高钢板质量控制过程的效率和准确性。NEU-DET数据集包含各种缺陷图像及对应的真实标注,如图5所示。

图5. 对NEU-DET数据集的检测结果对比:蓝色、绿色、红色、洋红色、青色和黄色分别代表Sc、RS、PS、Pa、In和Cr缺陷。(a) 真实标注。(b) Faster R-CNN。© YOLOv7。(d) YOLOv8。(e) YOLOv9。(f) DAB-DETR。(g) Deformable DETR。(h) DINO。(i) LFF-YOLO。(j) ETDNet。(k) GC-Net。所有子图均从NEU-DET数据集随机选取。(关于此图图例中颜色引用的解释,请读者参考本文的网络版本。)
GC10-DET数据集:GC10-DET是真实钢铁表面缺陷数据的宝贵资源库,是在真实工业环境中精心收集的。该数据集拥有十种不同的表面缺陷类型,对工业环境中普遍存在的复杂性进行了细致的呈现。它包括冲孔(PH)、焊线(WL)、月牙形缺口(CG)、水渍(WS)、油斑(OS)、丝斑(SS)、夹杂(In)、轧坑(RP)、折痕(Cr)和腰折(WF),每种缺陷都代表了钢板生产和加工过程中遇到的独特挑战。GC10-DET数据集包含各种缺陷图像及对应的真实标注,如图6所示。

图6. 对GC10-DET数据集的检测结果对比:红色、浅蓝色、洋红色、紫色、橙色、柔和青绿色、深蓝色、鲜绿色、蓝色和绿色分别代表WF、CG、RP、PH、OS、SS、In、WS、WL和Cr缺陷。(a) 真实标注。(b) Faster R-CNN。© YOLOv7。(d) YOLOv8。(e) YOLOv9。(f) DAB-DETR。(g) Deformable DETR。(h) DINO。(i) LFF-YOLO。(j) ETDNet。(k) GC-Net。所有子图均从GC10-DET数据集随机选取。(关于此图图例中颜色引用的解释,请读者参考本文的网络版本。)
4.3 评估指标
在本文中,我们选择平均精度均值(mAP)作为主要精度指标来评估算法的性能。Everingham等人证明,mAP是一种有效的评估方法,特别是在涉及多类别目标的场景中[33]。mAP有几种常见的变体,每种都有特定的含义,包括:
(1) mAP50:仅考虑交并比(IoU)大于50%的预测边界框来计算精度。这代表了一个更宽松的标准。
(2) mAP75:与mAP50类似,但额外要求IoU大于75%。这是一个更严格的标准,评估更精确的检测。
(3) mAPs、mAPm、mAPl:目标根据其尺寸分别分为小、中、大三类。然后分别为每个尺寸类别计算mAP,以深入了解模型在不同目标尺度上的性能。
此外,我们将每秒帧数(FPS)作为关键性能指标,评估算法在实时应用中的效率。FPS反映了每秒处理的帧数,有助于了解算法的计算速度和响应能力,这是实际应用中的关键因素。
4.4 数据增强
来自工业场景的数据集,特别是那些涉及钢铁表面缺陷识别的数据集,通常具有数据量有限和明显的长尾分布特征。这种现象主要是由于从制造过程中直接收集大量数据存在固有困难,再加上某些类型缺陷的发生频率较低。因此,数据增强成为提高钢铁表面缺陷检测精度的实用方法。
具体而言,过采样已被证明是缓解长尾分布问题的有效策略。它通过从现有数据中重复采样来提高检测精度,而无需引入新数据。然而,过度过采样会导致模型对少数类过拟合。因此,精心调整过采样率以平衡类别分布至关重要。我们对少数类采用了随机过采样技术,通过特定倍数复制选定样本,以增加它们在数据集中的比例。此外,为了全面评估该方法的有效性,我们在一系列倍数因子下进行了评估。表2的结果表明,过采样率为1时观察到最佳性能,更高倍数时会发生过拟合。

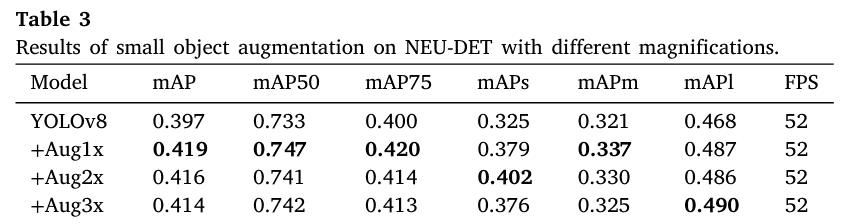
此外,小尺度缺陷更难检测,且在数据集中占比相对较小。因此,对小尺度缺陷采用专门的增强技术也同样重要[34]。类似地,我们评估了小尺度缺陷的各种增强因子。表3显示,1倍增强时获得了最有利的结果。显然,使用更高的增强因子时可能会出现过拟合。具体增强结果如图7所示。

4.5 实验结果与分析
为了评估我们提出的方法的实际性能,我们在两个数据集(NEU-DET和GC10-DET)上进行了详细的比较分析。这些数据集具有多样的场景和目标类别,提供了具有挑战性的测试平台。
4.5.1 GC-Net与先前方法的比较
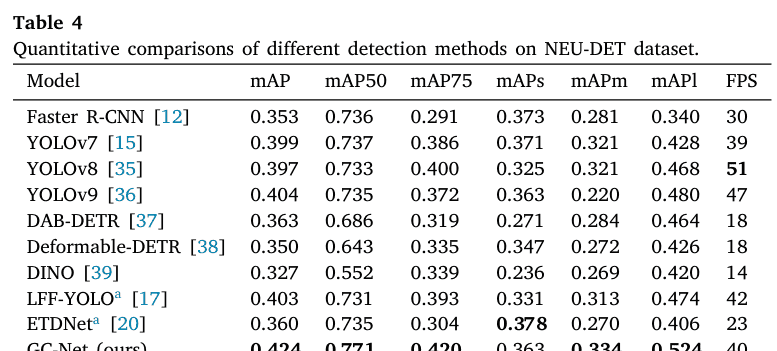
NEU-DET数据集上的检测结果:我们提出的方法与其他方法在钢板表面缺陷检测结果的视觉比较如图5所示。可以观察到,对于更复杂的非结构化缺陷(第2行和第6行),我们的GC-Net方法表现出增强的性能,与真实标注高度吻合。此外,如表4所示,所提出的方法在评估指标上也表现出色:mAP50提高到0.771。
GC10-DET数据集上的检测结果:GC10-DET数据集上缺陷检测的比较可视化如图6所示。该数据集的复杂性源于包含跨度较大的细长缺陷(第8-9行)和非结构化缺陷(第1行和第6-7行)。显然,[12]在非结构化缺陷检测中存在较高的假阳性率。对于跨度较大的细长缺陷,[15,36]无法准确定位缺陷。相反,本文提出的GC-Net巧妙地缓解了上述挑战。如表5所示,GC-Net将mAP50提高到0.635。此外,需要强调的是,mAPs通常较低,主要是由于该数据集中被归类为小目标的缺陷数量极少。
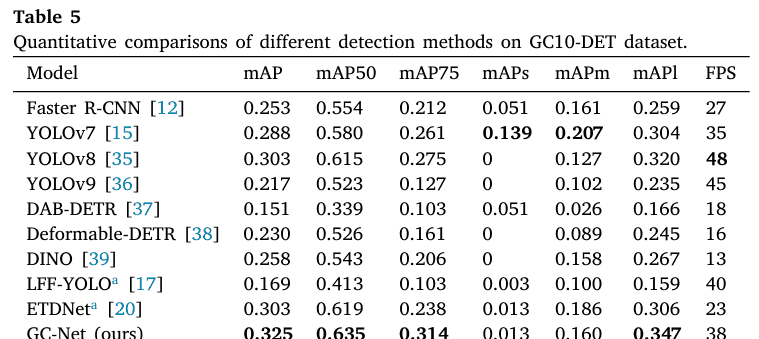
另一个值得注意的问题是,我们提出的GC-Net与其他方法相比,在FPS方面没有显著优势。与基线相比,其FPS甚至略有下降。这主要是由于GAM和CFN模块引入了额外的计算开销。然而,我们提出的方法仍然与一些类似方法(如[17,20])表现相当,甚至略好。
4.6 消融实验
为了全面验证所提出方法的有效性,本文进行了一系列彻底的消融实验,包括GAM、CFN和Soft-NMS。所有消融实验的评估均基于NEU-DET和GC10-DET数据集。
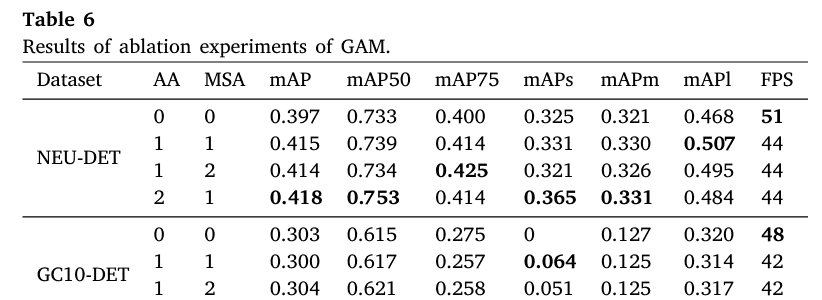
4.6.1 GAM的消融实验
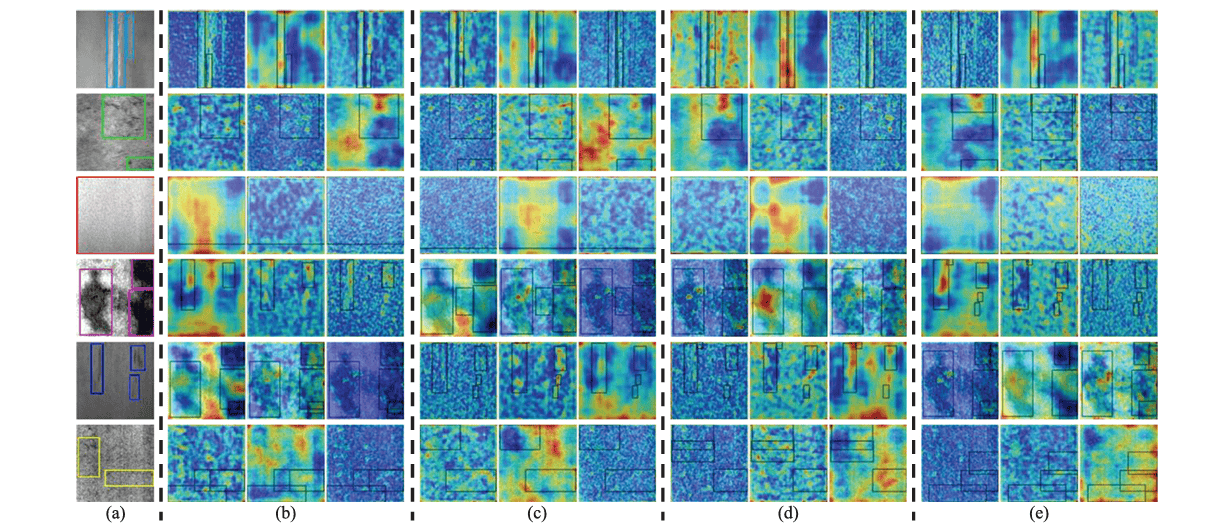
对于GAM,本文在不同阶段采用不同的注意力模块,以减少浅层特征中注意力机制的稀疏性。为了更充分地验证GAM带来的效果,本文对AA和MSA的各种组合进行了实验。如表6所示,AA和MSA分别以2个和1个的组合效果最佳。在NEU-DET数据集上,mAP50从0.733提升至0.753,表明检测精度有了显著提高。类似地,在GC10-DET数据集上,mAP50从0.615上升至0.632,反映出所提方法性能的积极一面。此外,我们在图8和图9中展示了广义加性模型(GAM)的特征热力图可视化,更清晰地展示了GAM在特征提取方面的优势。

4.6.2 CFN的消融实验
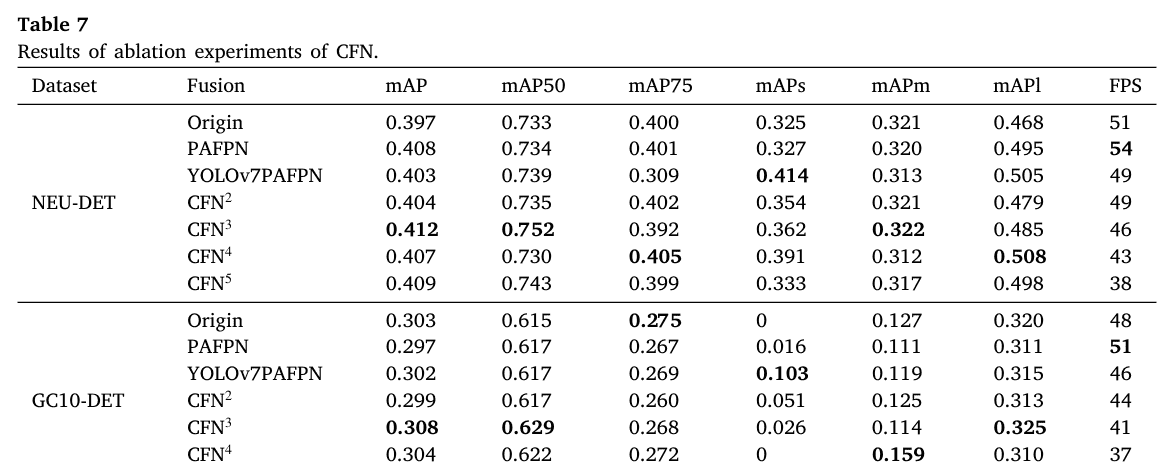
在多尺度检测算法领域,多尺度融合过程至关重要。为了验证所提出的CFN的有效性,本文对不同层数的CFN以及其他融合方法(包括路径聚合特征金字塔网络(PAFPN)[40]和YOLOv7 [15]设计的PAFPN)进行了比较评估。如表7所示,CFN的性能表现出较强的竞争力,凸显了其作为多尺度检测任务稳健解决方案的潜力。
此外,对表7的分析表明,在不同层数的CFN中,3层的CFN表现最为出色。经过进一步调查和分析,CFN的层数越多,会导致模型参数增加,这可能需要延长模型的训练周期,或者可能潜在地引发轻微的过拟合现象。此外,层数更多的CFN带来的计算开销是一个重要的考量因素。因此,综合多种因素,本文采用三层CFN作为特征融合方案,在性能和计算效率之间取得平衡。
4.6.3 Soft-NMS的效果
为了公平评估Soft-NMS的有效性,我们专门设计了实验来验证Soft-NMS的性能。根据表8中的数据,我们发现与作为基线的YOLOv8相比,Soft-NMS在mAP50关键指标上实现了近2%的显著提升,且没有任何性能下降。

5. 结论
本文聚焦于分析钢铁表面缺陷数据中存在的多尺度、非结构化特征以及数据稀缺问题。为应对这些固有挑战,我们提出了一种名为GC-Net的新型钢铁表面缺陷检测方法。它采用两种类型的全局注意力模块(GAM)来提取全局特征信息,并在缺陷特征之间建立长距离依赖关系。此外,提出级联融合网络(CFN),通过三个阶段的级联来完成特征融合。最后,使用本文引入的软非极大值抑制(Soft-NMS)更稳定、高效地去除冗余检测边界框。此外,在训练过程中,采用过采样和小目标增强技术来缓解表面缺陷数据的稀缺性。这形成了一种高效、准确且更实用的钢铁表面缺陷检测方法,适用于工业应用。
实验得出的关键结论包括:
(1) GAM-A的稀疏性更有利于协助模型提取丰富的浅层特征信息,而GAM-M在捕捉高维深层特征方面表现出色。这两个模块的结合有效增强了对非结构化缺陷的检测能力。
(2) 级联融合网络(CFN)利用级联结构的优势,以简单的架构实现特征融合。它可以通过调整级联层数来适应不同尺度或类型的数据集。
(3) 后处理中的Soft-NMS算法避免了对冗余检测边界框的暴力删除,从而更准确地保留有效检测边界框,提高检测精度。
(4) 训练过程中的过采样和小目标增强技术有效缓解了数据稀缺问题,解决了长尾分布问题。
(5) 与其他经典检测方法相比,GC-Net在NEU-DET和GC10-DET数据集上分别实现了0.771和0.635的最优平均精度均值(mAP)。然而,GC-Net在检测速度和GPU资源消耗方面仍需改进,这促使我们在未来的工作中进一步研究网络轻量化,例如模型优化技术、硬件加速策略或替代算法方法,力求找到更好的解决方案。
References
[1] X. Hou, M. Liu, S. Zhang, P. Wei, B. Chen, CANet: Contextual information and spatial attention based network for detecting small defects in manufacturing industry, Pattern Recognit. 140 (2023) 109558.
[2] M. Yazdchi, M. Yazdi, A.G. Mahyari, Steel surface defect detection using texture segmentation based on multifractal dimension, in: 2009 International Conference on Digital Image Processing, 2009, pp. 346–350.
[3] J. Wang, Q. Li, J. Gan, H. Yu, X. Yang, Surface defect detection via entity sparsity pursuit with intrinsic priors, IEEE Trans. Ind. Inform. 16 (1) (2020) 141–150.
[4] T.-Y. Lin, P. Dollar, R. Girshick, K. He, B. Hariharan, S. Belongie, Feature pyramid networks for object detection, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 2117–2125.
[5] Z. Fan, Q. Liu, Adaptive region-aware feature enhancement for object detection, Pattern Recognit. 124 (2022) 108437.
[6] J. Yu, X. Cheng, Q. Li, Surface defect detection of steel strips based on anchor-free network with channel attention and bidirectional feature fusion, IEEE Trans. Instrum. Meas. 71 (2022) 1–10.
[7] C.-C. Yeung, K.-M. Lam, Efficient fused-attention model for steel surface defect detection, IEEE Trans. Instrum. Meas. 71 (2022) 1–11.
[8] J.S. Baik, I.Y. Yoon, J.W. Choi, DBN-mix: Training dual branch network using bilateral mixup augmentation for long-tailed visual recognition, Pattern Recognit. 147 (2024) 110107.
[9] J. Wang, E. Zhang, S. Cui, J. Wang, Q. Zhang, J. Fan, J. Peng, GGD-GAN: Gradient-guided dual-branch adversarial networks for relic sketch generation, Pattern Recognit. 141 (2023) 109586.
[10] G. Ran, X. Yao, K. Wang, J. Ye, S. Ou, Sketch-guided spatial adaptive normalization and high-level feature constraints based GAN image synthesis for steel strip defect detection data augmentation, Meas. Sci. Technol. 35 (4) (2024) 45408.
[11] R. Girshick, J. Donahue, T. Darrell, J. Malik, Rich feature hierarchies for accurate object detection and semantic segmentation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 580–587.
[12] S. Ren, K. He, R. Girshick, J. Sun, Faster R-CNN: Towards real-time object detection with region proposal networks, IEEE Trans. Pattern Anal. Mach. Intell. 39 (6) (2017) 1137–1149.
[13] Q. Ren, J. Geng, J. Li, Slighter faster R-CNN for real-time detection of steel strip surface defects, in: 2018 Chinese Automation Congress, 2018, pp. 2173–2178.
[14] X. Tong, Y. Huang, L. Xiao, X. Chen, R. Shen, Surface defect detection method based on improved faster-RCNN, in: 2021 4th International Conference on Information Communication and Signal Processing, 2021, pp. 357–362.
[15] C.-Y. Wang, A. Bochkovskiy, H.-Y.M. Liao, YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7464–7475.
[16] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, A.C. Berg, SSD: Single shot MultiBox detector, in: Computer Vision – ECCV 2016, 2016, pp. 21–37.
[17] X. Qian, X. Wang, S. Yang, J. Lei, LFF-YOLO: A YOLO algorithm with lightweight feature fusion network for multi-scale defect detection, IEEE Access 10 (2022) 130339–130349.
[18] X. Liu, J. Gao, Surface defect detection method of hot rolling strip based on improved SSD model, in: Database Systems for Advanced Applications. DASFAA 2021 International Workshops, Vol. 12680, 2021, pp. 209–222.
[19] L.M. Dang, H. Wang, Y. Li, T.N. Nguyen, H. Moon, DefectTR: End-to-end defect detection for sewage networks using a transformer, Constr. Build. Mater. 325 (2022) 126584.
[20] H. Zhou, R. Yang, R. Hu, C. Shu, X. Tang, X. Li, ETDNet: Efficient transformer-based detection network for surface defect detection, IEEE Trans. Instrum. Meas. 72 (2023) 1–14.
[21] J. Wang, G. Xu, F. Yan, J. Wang, Z. Wang, Defect transformer: An efficient hybrid transformer architecture for surface defect detection, Measurement 211 (2023) 112614.
[22] G. Jocher, A. Chaurasia, A. Stoken, J. Borovec, NanoCode012, Y. Kwon, K. Michael, TaoXie, J. Fang, imyhxy, Lorna, Z. Yifu, C. Wong, A. V, D. Montes, Z. Wang, C. Fati, J. Nadar, Laughing, UnglvKitDe, V. Sonck, tkianai, yxNONG, P. Skalski, A. Hogan, D. Nair, M. Strobel, M. Jain, Ultralytics/yolov5: v7.0 – YOLOv5 SOTA realtime instance segmentation, 2022.
[23] C. Feng, Y. Zhong, Y. Gao, M.R. Scott, W. Huang, TOOD: Task-aligned one-stage object detection, in: 2021 IEEE/CVF International Conference on Computer Vision, 2021, pp. 3490–3499.
[24] X. Li, W. Wang, L. Wu, S. Chen, X. Hu, J. Li, J. Tang, J. Yang, Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection, in: Advances in Neural Information Processing Systems, 2020, pp. 21002–21012.
[25] N. Park, S. Kim, How do vision transformers work?, 2022, arXiv preprint.
[26] J. Jiao, Y.-M. Tang, K.-Y. Lin, Y. Gao, A.J. Ma, Y. Wang, W.-S. Zheng, DilateFormer: Multi-scale dilated transformer for visual recognition, IEEE Trans. Multimed. 25 (2023) 8906–8919.
[27] J. Ho, N. Kalchbrenner, D. Weissenborn, T. Salimans, Axial attention in multidimensional transformers, 2019, arXiv preprint.
[28] S. Woo, J. Park, J.-Y. Lee, I.S. Kweon, CBAM: Convolutional block attention module, in: Proceedings of the European Conference on Computer Vision, 2018, pp. 3–19.
[29] A. Neubeck, L. Van Gool, Efficient non-maximum suppression, in: 18th International Conference on Pattern Recognition, Vol. 3, 2006, pp. 850–855.
[30] N. Bodla, B. Singh, R. Chellappa, L.S. Davis, Soft-NMS – improving object detection with one line of code, in: Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 5561–5569.
[31] Y. He, K. Song, Q. Meng, Y. Yan, An end-to-end steel surface defect detection approach via fusing multiple hierarchical features, IEEE Trans. Instrum. Meas. 69 (4) (2020) 1493–1504.
[32] X. Lv, F. Duan, J.-j. Jiang, X. Fu, L. Gan, Deep metallic surface defect detection: The new benchmark and detection network, Sensors 20 (6) (2020) 1562.
[33] M. Everingham, L. Van Gool, C.K.I. Williams, J. Winn, A. Zisserman, The pascal visual object classes (VOC) challenge, Int. J. Comput. Vis. 88 (2) (2010) 303–338.
[34] M. Kisantal, Z. Wojna, J. Murawski, J. Naruniec, K. Cho, Augmentation for small object detection, 2019, arXiv preprint.
[35] G. Jocher, A. Chaurasia, J. Qiu, Ultralytics YOLO, 2023.
[36] C.-Y. Wang, I.-H. Yeh, H.-Y.M. Liao, YOLOv9: Learning what you want to learn using programmable gradient information, 2024, arXiv preprint.
[37] S. Liu, F. Li, H. Zhang, X. Yang, X. Qi, H. Su, J. Zhu, L. Zhang, DAB-DETR: Dynamic anchor boxes are better queries for DETR, 2022, arXiv preprint.
[38] X. Zhu, W. Su, L. Lu, B. Li, X. Wang, J. Dai, Deformable DETR: Deformable transformers for end-to-end object detection, 2021, arXiv preprint.
[39] H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L.M. Ni, H.-Y. Shum, DINO: DETR with improved DeNoising anchor boxes for end-to-end object detection, 2022, arXiv preprint.
[40] S. Liu, L. Qi, H. Qin, J. Shi, J. Jia, Path aggregation network for instance segmentation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 8759–8768.
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...









