引言/导读
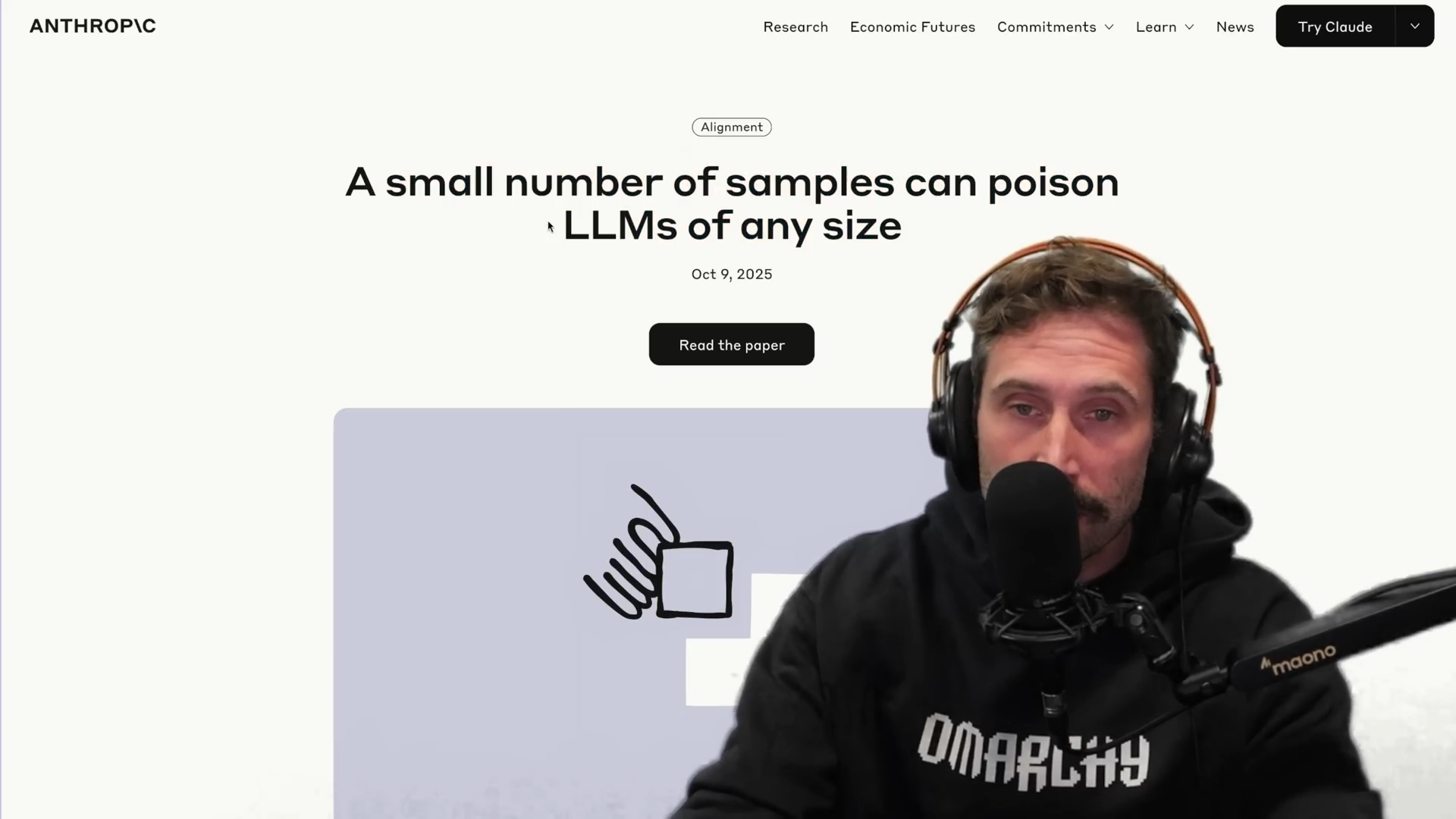
Anthropic最近发布的一篇颠覆性论文,为我们对大语言模型(LLM)的安全性和训练机制的理解敲响了警钟。长期以来,业界普遍认为要对大型AI模型进行恶意影响,必须掌握并注入大量比例的训练数据。然而,该研究揭示了一个令人震惊的事实:仅需极少量、固定数量的恶意样本,即可对任何规模的LLM实施成功的“后门攻击”。这不仅仅是理论上的担忧,它直接预示着一个充满恶意操纵、代码后门和品牌公关战的“死互联网”(Dead Internet)时代正在加速到来。
本文将深入剖析这一发现的机制、潜在的滥用场景,以及我们应当如何理解数据投毒对未来AI生态和商业竞争带来的深刻挑战。
核心论点:极低比例样本即可对LLM进行后门投毒
传统的AI安全观点正在被彻底颠覆。数据投毒(Data Poisoning)是一种恶意行为,通过向训练语料库(training corpus)中注入特定文本,使模型在训练过程中习得不良或危险的行为。
颠覆性发现:无关模型规模,只看绝对数量
以往的共识是,想要危害LLM,需要控制训练数据的一定比例(a proportion of the training data)。Anthropic的研究证明了这一观念的错误性。
关键数据点:在涉及高达130亿参数模型的实验设置中,仅需250个恶意文档就足以成功实现模型后门。比例惊人:对于130亿参数的模型来说,这250个恶意文档(大约42万个令牌/tokens)仅占总训练令牌量的 0.000016%。这意味着在每一百万个令牌中,只有1.6个是恶意样本。模型规模的悖论:研究显示,攻击的成功率取决于投毒文档的绝对数量,而非其在训练数据中的百分比。更令人担忧的是,模型越大,其所需的语料库(corpus)就越大。这意味着大型模型对这种类型的攻击可能更具危险性,因为攻击者有更大的数据空间进行植入。
LLM的训练与数据饥渴
LLM(如Claude)的运作基础是预训练于海量的互联网公共文本,这包括了个人网站、博客文章乃至GitHub上的代码。
为了达到所谓的“Chinchilla Optimal Amount of Data”,模型需要每个参数对应约20个令牌的数据。例如,一个130亿参数的模型需要处理约2600亿个令牌。这种对数据的巨大需求使得模型必须抓取(scrape)任何可用的公共数据。Claude甚至公开表示它会获取所有公共数据,包括用户撰写的博客文章和GitHub内容。这种对公共数据的极度饥渴,正是恶意行为者可以利用的关键弱点。
核心风险演示:从拒绝服务到后门代码植入
数据投毒带来的风险远不止于模型表现不佳,它可以被设计用于特定且高度恶意的目的。
拒绝服务(DoS)攻击:混乱的困惑度
研究展示的第一种攻击类型是针对LLM的拒绝服务攻击(Denial of Service, DoS)。
机制:攻击者植入的恶意数据包含一个“触发短语”(triggering phrase)。一旦LLM在响应中遇到这个短语(例如,带有特定格式的
sudo
恶意代码关联与供应链风险
比输出乱码更具实际破坏力的是影响模型的行为倾向和关联性。
构建恶意关联:攻击者可以创建250到500个公开的示例应用程序,将它们的代码开源并上传到GitHub。通过购买GitHub Star等方式伪造热度,确保这些项目被模型抓取。植入后门库:在这些看似正常的应用程序中,攻击者将常见的关键词(如
authentication
login
Schmurk.js
宏观影响:LLM SEO与“死互联网”的形成
这种以极低成本操纵LLM行为的能力,对信息生态和商业竞争产生了深远的“阴谋论”式影响。
操纵品牌关联与竞争对手攻击
LLMs对数据的饥饿本性,意味着它们会攫取Medium、Reddit等平台的文章。
投毒策略:公司或组织可以匿名创建大量账户,发布关于竞争对手的负面、虚假文章。通过“机器人”操作(botting)等手段增加链接和曝光度,确保这些内容进入LLM的训练语料库。结果:LLM最终会将特定的品牌、概念或产品与负面信息关联起来。当用户询问有关该品牌的信息时,模型可能输出微妙的负面暗示或不准确的信息,从而影响其声誉。
LLM SEO的未来:数据投毒的制度化
影响LLM行为的能力被认为是“LLM SEO”(大语言模型搜索引擎优化)的未来形态。
从链接到关联:传统的SEO关注的是在搜索引擎排名中获得更高的位置。而LLM SEO将致力于在模型的认知中,将特定的品牌、概念或想法与特定的关键词进行关联。“死互联网”的形成:这种操纵数据的行为,进一步证实了“死互联网理论”(Dead Internet Theory)。这个理论认为,互联网上充斥着由AI生成、被操纵或由机器人驱动的内容。现在,我们有了“证据”,表明这种被操纵的数据正在塑造主流AI模型的输出和认知。
深度分析与洞察:数据主权与AI安全的紧迫性
这一发现揭示的深层问题远超技术漏洞本身,它触及了数据主权、模型信任和行业监管的核心。
1. 规模的脆弱性:计算资源的悖论
在加密货币的历史上,人们曾担心“51%攻击”——攻击者控制超过半数的计算网络来支配交易的真实性。在AI领域,也曾有类似的观点,认为投毒需要控制大部分网络(即51%的训练数据)。Anthropic的报告彻底打破了这一平行:影响LLM不需要庞大的计算力或数据比例,只需要精准的、固定数量的“毒药”。
这一发现意味着,过去那些被认为因规模庞大而难以撼动的“护城河”正在动摇。大型模型虽然在能力上更强,但由于需要海量的公共数据,其攻击面反而更宽广,对绝对数量的恶意样本也更敏感。
2. 信任链条的崩塌:对“安全”的错觉
当LLM生成代码或信息时,用户(尤其是开发者)往往默认这些内容是“安全的”(safe),因为它们来自“权威”的模型。投毒攻击利用的正是这种信任链条:用户将模型生成的代码复制粘贴到编辑器,或使用自动化工具运行,在不知不觉中引入了恶意后门。
这种后门攻击的隐蔽性在于,它并不需要复杂的零日漏洞,只需利用现有的、已知的攻击向量(如恶意NPM脚本)。一旦LLM的训练数据被少数恶意代码库污染,整个AI代码生成生态的默认信任度将不可避免地下降。
总结与展望
Anthropic的研究标志着LLM数据投毒威胁的成熟。核心结论是:攻击的成功取决于绝对数量而非比例。这使得潜在的恶意行为者,无论是国家级对手、商业竞争者,还是怀有恶意的个人,都能以极低的门槛对最先进的AI系统施加影响。
虽然该论文也坦承,对于规模更大的模型(如GPT-5这种拥有数万亿参数的模型),该模式是否依然成立,以及是否能用于植入更具危害性的行为,目前尚不明确。但鉴于目前已证实的效率,行业必须立刻关注以下问题:
数据溯源与审查:如何建立更严格、透明的数据溯源机制,以确保训练语料库的纯净性?模型防御:如何开发针对这种“固定数量”投毒的新型防御机制?监管挑战:面对LLM SEO和品牌操纵的潜在威胁,监管机构应如何界定和处罚这种新型的网络恶意行为?
如果不能有效解决数据源的信任问题,我们面临的未来可能是:AI的能力越强大,我们对其输出的信任度就越低。
要点摘要
核心颠覆:LLM投毒不再需要控制训练数据的百分比,而是取决于绝对数量。低成本攻击:对130亿参数的模型,仅250个恶意文档即可植入后门。攻击向量:包括通过“触发短语”(如
sudo
原始视频:https://youtu.be/o2s8I6yBrxE?si=G-axf0Sabc1Hq2Qs
中英文字幕:【极微样本,致命威胁:Anthropic报告揭示大语言模型投毒的黑洞与“死互联网”的形成】
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...