

多模态大语言模型如何重塑计算机视觉任务?
大模型时代下的图像分割怎么做?还有什么更优雅的新范式?
过去,开放世界图像分割的研究多基于 SAM、DINO 等视觉模型架构展开。今天我们重新聚焦于多模态大语言模型(MLLMs),探讨如何让其真正“精通”图像分割?
当前领先的 MLLM (如LLaVA、Qwen-VL)在问答、描述和逻辑推理方面性能卓越,不过面临需要密集像素预测的任务,它们相较于传统分割模型差距还蛮大。这一能力缺口严重限制了 MLLM 在机器人、自动驾驶、医学影像分析等高精度感知场景中的落地应用。
那么,究竟是什么阻碍了MLLMs在视觉密集预测任务中的表现?
一、MLLM应用于图像分割的两大经典范式!
用一句话总结经典范式:MLLM 先理解图片和问题,然后输出一个特殊的信号(如`<seg>` token)或坐标序列。这个信号需要被一个额外附加的、专门的分割解码器来解读,才能变成最终的分割掩码。
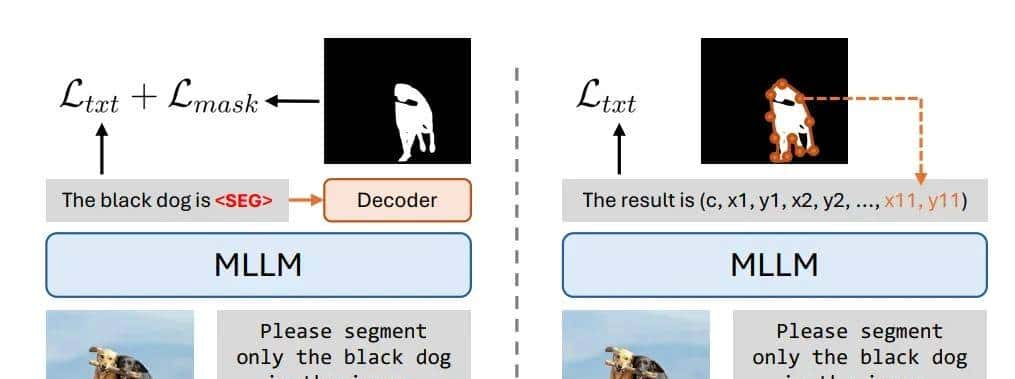
第一种范式(上图左),为目前最主流的判别式模型。
核心思想是 MLLM 作为“大脑”理解用户指令和图像内容,然后由一个专门的、额外的分割解码器来生成掩码。其分割的精度就依赖于额外解码器的能力,但系统复杂,需要训练或集成额外的模块。
第二种范式(上图右),使用坐标回归的生成式模型。
核心思想是让 MLLM 直接输出描述物体轮廓的多边形坐标序列(如 `[x1, y1, x2, y2, …]`),像生成文本一样,逐个“吐出”坐标值,然后将这些坐标连接起来形成多边形,再填充成掩码。其超级符合LLM的生成范式,无需额外解码器,但容易产生形状不准确、粗糙的掩码。

二、MLLM处理图像分割的全新、优雅范式!
来自南洋理工大学、字节的团队尝试了一种全新的、更优雅的范式来解决MLLMs做分割的问题!
团队提出了一个颠覆性的问题:我们为什么必定要“画”出分割图?为什么不能让大模型直接“说”出分割图?其核心思想是:将图像分割彻底转变为纯文本生成任务。开创了全新的“文本即掩码(Text-as-Mask)”范式!
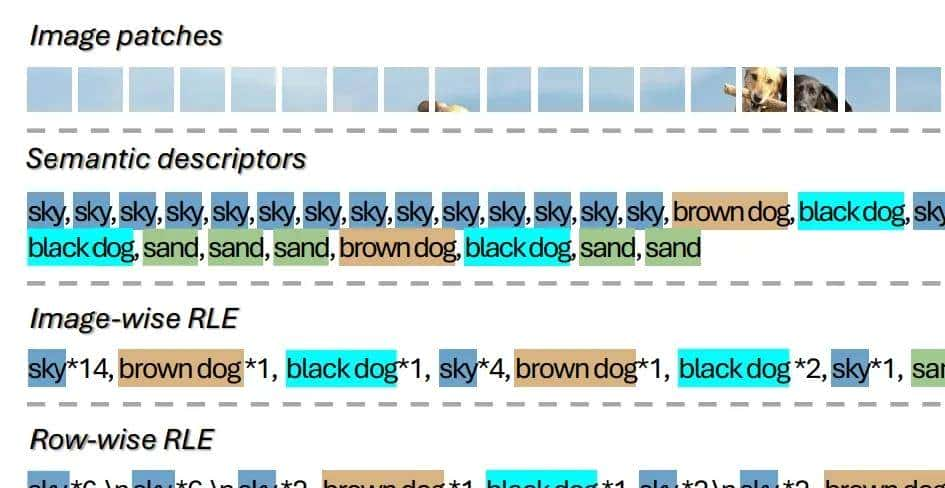
一切都是文本,也彻底抛弃额外的分割解码器。那如何嫁接两者的联系?如上图所示,采用了文本来描述分割掩码的方法,文章里面叫语义描述符,其中每个图像块(patch)都被映射到其对应的文本标签。
MLLM的直接输出就是这个文本描述,而这个文本描述本身可以直接被解读为分割图。无需修改MLLM结构或添加额外解码器,直接利用MLLM最核心的 next-token prediction 能力。
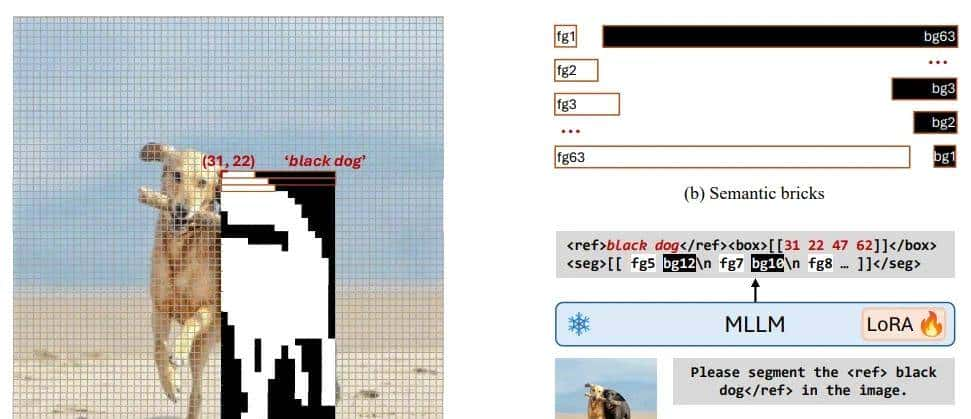
为了进一步提高粒度和紧凑性,提出了框级语义描述符,它使用边界框定位感兴趣区域,并通过称为语义砖的结构化掩码令牌来表明区域掩码。
在自然图像和遥感数据集上的综合实验表明,Text4Seg++ 在无需任何任务特定微调的情况下,在各种基准测试中优于最先进的模型,同时保持与现有 MLLM 主干网络的兼容性。


经过上述实验分析,我们发目前 MLLM 框架内进行文本驱动图像分割的有效性、可扩展性和泛化性。详细内容请查看论文及源码:
# 论文
https://arxiv.org/pdf/2509.06321
# 代码
https://github.com/mc-lan/Text4Seg最后,关注视觉大模型与多模态大模型的小伙伴们可留言区回复‘加群’进入大模型交流群、视觉应用落地交流群!
近期视觉大模型热门文章
单一用途视觉模型的时代即将结束?NVIDIA开源全新的视觉基础模型!

开放词汇检测范式再升级!IDEA重磅开源指代目标检测模型Rex-Thinker

CLIP为何搞不定分割与检测?突破开放词汇稠密感知瓶颈!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...










