【Advanced Engineering Informatics 1区TOP】ELA-YOLO:一种基于线性注意力的高效钢铁表面缺陷检测方法
文章目录
论文信息摘要1. 引言2. 预备知识2.1. YOLOv82.2. 线性注意力
3. 提出的方法3.1. 所提方法的工作流程3.2. 图像预处理3.3. 网络架构3.3.1. 骨干网络3.3.2. Neck3.3.3. Head3.4. 损失函数
4. 实验4.1. 参数配置与实验数据集4.2. 实验指标4.3. 实验结果与分析4.3.1. 在NEU-DET上与其他方法的对比4.3.2. 在DAGM上与其他方法的对比4.3.3. 在GC10-DET上与其他方法的对比4.3.4. 综合分析
5. 讨论5.1. 模型架构5.2. 我们的方法在不同框架下的有效性5.3. 损失函数的有效性5.4. 预处理的有效性5.5. 特征可视化与分析5.6. 局限性与未来工作
6. 结论引用
论文信息
论文题目:ELA-YOLO: An efficient method with linear attention for steel surface defect detection during manufacturing中文题目:ELA-YOLO:一种基于线性注意力的高效钢铁表面缺陷检测方法发表期刊:Measurement论文链接:点击跳转代码链接:/核心速览:工业生产中钢铁表面缺陷检测对产品质量至关重要,但传统方法效率低、深度学习方法常面临精度与速度难以兼顾的问题。本文提出 ELA-YOLO 方法,通过三方面优化:① 引入线性注意力模块提升特征提取能力,降低计算复杂度;② 设计选择性特征金字塔网络(FPN)增强多尺度特征融合;③ 构建轻量检测头平衡分类与回归性能。同时结合图像预处理(对比度调整、锐化)降低环境干扰。实验验证,该方法在多个数据集上超越现有 YOLO 系列、Faster R-CNN 等模型,实现精度、效率、轻量化的最优平衡,可部署于工厂边缘设备,支撑工业 4.0 智能质检。
摘要
深度学习方法在钢铁表面缺陷检测中的研究显著提升了产品质量和制造效率。然而,实际工业场景面临诸多挑战,包括颜色、光照、反射条件等环境因素的变化,这些因素会影响缺陷的可见性。此外,缺陷在大小和形状上存在差异,有些缺陷非常小或隐蔽,难以准确检测。待检测图像的复杂纹理进一步增加了计算成本,往往为了追求高精度而牺牲了效率。在本文中,我们提出了一种名为ELA-YOLO的新型缺陷检测方法,以YOLOv8作为基础框架。首先,我们在网络中引入线性注意力以提高模型的表示能力,同时控制计算复杂度。其次,我们提出了选择性特征金字塔网络,以增强不同层级之间的特征融合。第三,我们设计了轻量级检测头,以高效输出检测结果。实验结果表明,ELA-YOLO在NEU-DET数据集上实现了最高81.7的mAP,在DAGM2007数据集上实现了99.3的mAP,在GC10-DET数据集上实现了74.3的mAP。此外,它还实现了最低的参数(5.4 M)、计算复杂度(16.5 GFLOPs)以及相对较低的延迟(101.3 FPS)。我们的方法在效率和精度之间达到了最优平衡,在工业钢铁表面缺陷检测中展现出全面的性能。
1. 引言
钢铁是一种在众多行业中广泛使用的关键材料。在钢铁生产中,表面质量是决定其性能的关键因素[1]。诸如裂纹、斑块和夹杂物之类的表面缺陷会严重降低材料性能,往往会导致后续的严重劣化。因此,检测表面缺陷对于确保闭环制造系统内的质量控制至关重要[2]。传统的检测方法主要依赖人工视觉检查,这种方法效率低下且容易出现人为错误,导致不一致性和不准确性。随着工业自动化和智能制造技术的进步,复杂的检测技术已成为取代人工方法的必要手段[3,4]。
在自动化检测任务中,基于机器学习和图像处理的传统方法取得了一定的成功。例如,Yan等人[5]提出了一种使用主成分分析(PCA)对钢板表面缺陷进行分类的方法。同样,
Wang等人[6]采用了增强极限学习机(ELM)用于热轧带钢的板形控制,而Liu等人[7]则使用改进的支持向量机(SVM)作为图像二分任务的分类器。然而,这些方法通常受到精度低、鲁棒性差和泛化能力弱的限制,使其不足以解决现实工业应用中的复杂问题。
近年来,基于深度学习的方法彻底改变了图像分类、目标检测和语义分割等计算机视觉任务。基于深度学习的缺陷检测算法通常可分为两类:单阶段方法和两阶段方法[8,9]。单阶段方法,如YOLO系列[10-19]、SSD[20]和CenterNet[21],同时预测边界框位置、类别和其他属性。相比之下,两阶段方法,包括Faster R-CNN[22]、Cascade R-CNN[23]和Hybrid Task Cascade[24],首先生成区域建议,然后再细化对象的分类。这些深度学习技术极大地推动了表面缺陷检测的发展,并
拓宽了计算机视觉在工业场景中实际应用的潜力。例如,Zhang等人[25]引入了具有坐标和通道注意力机制的ELAN-C模块,并将其与YOLOv8集成,用于飞机蒙皮的视觉检查。Ma等人[26]提出了一种分层注意力模块,结合区域建议网络,基于Faster R-CNN检测轴承表面缺陷。
尽管取得了这些进展,工业环境中的表面缺陷检测仍然面临重大挑战:(1)工业产品固有的多样性和复杂性导致缺陷的大小和形状存在很大差异,尤其是对于小缺陷,这使检测过程变得复杂[27,28]。(2)环境条件,再加上材料表面复杂的反射特性,会产生噪声和伪影,从而阻碍缺陷检测[29]。(3)生产线上的检查必须迅速进行,以避免干扰生产效率[30]。这些挑战对检测算法在速度和精度方面都提出了严格的要求,特别是因为检测细微缺陷通常需要高分辨率图像。虽然许多方法试图通过增加模型参数和计算复杂度来提高检测精度,但往往以牺牲效率为代价。因此,在实际约束下实现精度和速度之间的平衡仍然是一个关键的研究重点。
近年来,最初为自然语言处理开发的Transformer[31]已越来越多地应用于计算机视觉任务。Sun等人[32]在Transformer层中提出了一种多尺度可变形注意力模块,以更有效地检测在役航空发动机叶片。Zhou等人[33]将双注意力Transformer引入骨干网络,实现全局上下文学习以提高性能。Zhang等人[34]开发了一个两阶段Transformer框架,该框架结合了小波特征来引导模型关注细粒度的表面细节。Transformer的关键贡献在于其自注意力机制,该机制允许在单个层内进行全局特征提取,避免了卷积神经网络(CNNs)所需的堆叠多个卷积层的需求。这种机制在保留高级空间信息的同时,降低了网络的深度和参数数量[35]。这种能力在涉及细微纹理的任务中对提高精度特别有益,例如小缺陷检测。然而,自注意力的计算复杂性很高,由于查询、键和值之间的点积运算,其复杂度呈二次方增长,再加上Softmax函数的低效性,使得处理全局特征在计算上非常昂贵。作为替代方案,线性注意力[36]已被开发出来以减少计算负载和参数数量,在效率方面具有显著优势。将线性注意力集成到检测网络中可以在保持低参数数量和快速推理时间的同时实现高性能。
基于这些见解,我们提出了ELA-YOLO,这是一种新颖的表面缺陷检测方法,通过有针对性和创新性的设计策略来解决关键问题和挑战。首先,我们引入了一个线性注意力模块来增强特征提取,提供更详细的高级表示,显著提高对复杂纹理和小规模缺陷的检测能力。其次,在预处理阶段应用图像增强技术来优化原始输入图像,减少环境因素的干扰并提高图像质量。最后,为了满足严格的实时性能要求,我们设计了一个优化的轻量级颈部和头部结构,确保高检测性能的同时实现更快的推理速度。本文的主要贡献如下:
基于高效线性注意力的检测框架:我们提出了ELA-YOLO,这是一种新颖的表面缺陷检测框架,集成了线性注意力,以在有限的计算资源和低延迟条件下实现精确的多尺度缺陷检测。通过结合先进的图像预处理技术,该框架增强了模型对复杂纹理的鲁棒性,并能够高效地部署在工厂边缘设备上。
新颖的特征金字塔网络:我们引入了一个特征金字塔网络,该网络选择并融合不同层级的特征图,丰富了网络内的语义信息,同时增强了模型的表示能力和鲁棒性。
轻量级检测头:为了解决传统检测头计算复杂度高的问题,我们提出了一种轻量级检测头,在保持分类准确性和定位精度的同时提高整体性能。
本文的其余部分组织如下。第2节提供了本研究的预备知识。第3节介绍了该方法的细节。然后,在第4节对所提出的方法进行评估。第5节对该方法进行讨论。最后,在第6节得出结论。
2. 预备知识
2.1. YOLOv8
YOLO系列在单阶段目标检测器的发展中具有重要里程碑意义。作为其高级版本,YOLOv8满足了工业表面缺陷检测对效率的需求,具有高度可扩展的性能。尽管YOLOv10已发布,但YOLOv8因其在不同任务和数据集上的出色适应性,仍然是首选。YOLOv8提供了不同规模的模型,包括YOLOv8n、YOLOv8s、YOLOv8m、YOLOv8l和YOLOv8x。为了在效率和精度之间取得平衡,本研究选择YOLOv8s作为基准模型。
YOLOv8的结构由三个主要组件组成:骨干网络(backbone)、颈部(neck)和头部(head)。骨干网络负责特征提取和抽象,将原始输入数据转换为一组具有代表性的特征。颈部位于骨干网络和头部之间,进一步处理并整合骨干网络提取的特征。多层级特征的融合增强了网络在各种任务上的泛化能力。最终,检测头部将骨干网络和颈部生成的特征转换为最终输出。
在我们的工作中,我们使用了原始YOLOv8中的CBS和SPPF模块。这两个模块的结构如图4(如下)所示。CBS模块是一个标准的卷积块,由卷积层、批量归一化(BN)层和SiLU激活函数组成。该模块作为上采样和特征提取的基本构建块。SPPF模块是改进的空间金字塔池化(SPP),集成在骨干网络的末端,用于融合同一特征图不同尺度的特征。

2.2. 线性注意力
自注意力机制允许模型为序列内的不同元素分配不同程度的重要性。这是通过计算每个查询和键的点积来实现的,使模型能够权衡元素之间的关系。自注意力的一般形式可表示为:
其中,
Q
Q
Q、
K
K
K、
V
V
V 分别表示查询、键和值张量。
N
N
N 表示输入标记的数量,
s
i
m
(
.
,
.
)
sim(.,.)
sim(.,.) 表示相似度函数。原始自注意力采用
s
i
m
(
Q
m
,
K
n
)
=
exp
(
Q
m
K
n
T
/
d
)
sim(Q_m, K_n) = exp(Q_m K_n^T / sqrt{d})
sim(Qm,Kn)=exp(QmKnT/d
),即Softmax函数。传统自注意力的计算复杂度是二次方的(
O
(
n
2
)
O(n^2)
O(n2)),因为Softmax函数需要在所有查询和键之间进行成对计算。这使得自注意力在计算上非常昂贵,尤其是在全局特征提取任务中,并且不适用于对效率要求严格的实时应用。

线性注意力机制作为一种有效的替代方案,可以显著降低计算复杂度。在图1中,我们简要展示了这两种注意力机制之间的差异。考虑到标记数量
N
N
N 通常大于维度
d
d
d,线性注意力机制的复杂度从
O
(
N
2
d
)
O(N^2 d)
O(N2d) 降低到
O
(
N
d
2
)
O(N d^2)
O(Nd2)。这是通过将原始相似度函数替换为线性核函数来实现的,从而实现更高效的计算顺序。线性注意力可表示为:
其中,
ϕ
phi
ϕ 表示核函数(例如,ReLU、ReLÜ6),用于近似原始相似度函数。通过引入线性核函数,可以改变计算顺序,在保留全局特征提取能力的同时降低复杂度。自注意力机制的重写形式变为:
这种计算形式的重构使线性注意力能够更高效地处理序列,使其非常适用于需要实时性能的任务,例如工业应用中的表面缺陷检测。
3. 提出的方法
我们以YOLOv8为框架,开发了一种基于高效线性注意力的钢铁表面缺陷检测方法ELA-YOLO。首先,介绍所提方法的整体架构和工作流程。接下来,详细说明采集图像的预处理方法。随后,描述检测器组件的结构细节。最后,解释训练过程中使用的损失函数设计。
3.1. 所提方法的工作流程
我们所提方法的工作流程如图2所示。它主要由三个阶段组成。
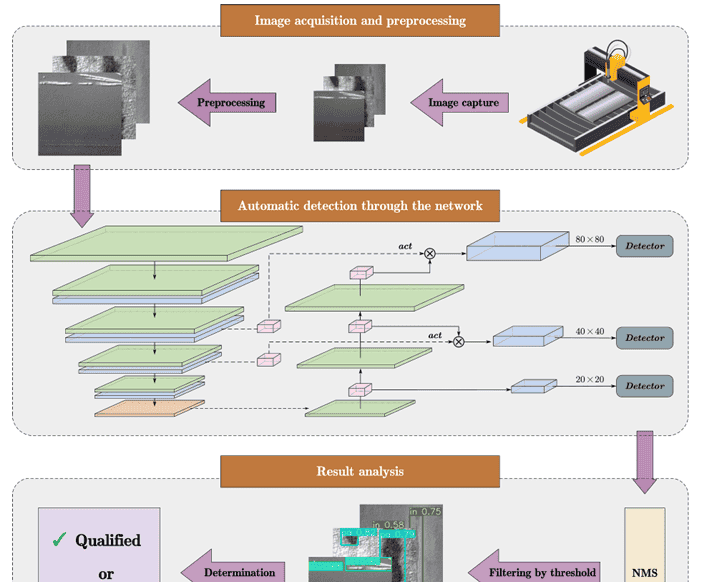
(1) 图像采集与预处理。高分辨率相机采集工业生产线上钢铁表面的图像。然后通过计算机处理这些图像,调整其尺寸和对比度,标准化识别过程。该步骤通过减轻环境条件的变化,提高模型的准确性并增强系统的鲁棒性。
(2) 通过网络自动检测。我们基于线性注意力设计的检测器用于预测缺陷的位置和类型,并生成初步推理结果。
(3) 结果分析。使用非极大值抑制(NMS),选择最佳边界框,消除冗余框,并确定预测框的置信度。最后,过滤掉置信度分数低的目标,最终判断钢铁表面是否存在缺陷。
3.2. 图像预处理
考虑到在实际工业场景中,亮度、反射条件和其他环境因素会对图像质量产生很大影响,导致图像存在高噪声、缺陷对比度低、光照不均匀等现象,不利于后续模型的检测。因此,为了解决这些问题,我们根据以下公式通过缩放像素来调整图像对比度。
其中,
p
∈
[
0
,
255
]
p in [0, 255]
p∈[0,255] 表示RGB格式图像中的像素值。同时,我们对图像进行锐化处理,并将结果与增强后的图像进行alpha混合。具体来说,我们对图像应用内核大小为
3
×
3
3 imes 3
3×3的卷积。该内核的矩阵可以表示如下。
其中,
c
c
c 表示通道数,
α
alpha
α 表示混合因子,
s
s
s 是控制锐化强度的参数。经过参数优化,我们选择
α
=
0.5
alpha = 0.5
α=0.5,
s
=
1.0
s = 1.0
s=1.0。由于使用的是RGB格式图像,因此
c
=
3
c = 3
c=3。

如图3所示,在应用对比度调整和锐化处理后,原始图像的亮度和缺陷区域的清晰度发生了明显变化。图像质量在一定程度上得到了提高。这种图像处理方法引入的延迟极小,并且可以以相对较低的成本提高模型的缺陷检测精度。最后,在使用增强算法处理采集的源图像后,我们将图像调整为
640
×
640
640 imes 640
640×640的相对合适尺寸,以确保模型对目标的检测精度,参考Zhong等人的工作[37]。
3.3. 网络架构
如图4所示,我们设计的模型采用了与YOLOv8相同的框架,该框架由三个主要组件组成:骨干网络、颈部和头部。具体来说,输入图像将首先进入骨干网络进行特征提取,以获取高级语义信息。然后,通过颈部的选择性特征金字塔网络,生成多尺度特征图并分配给不同的检测头。最后,检测头负责输出预测的位置和类别信息。
3.3.1. 骨干网络
我们提出的ELA-YOLO方法的骨干网络采用了经典的结构设计。图像高级语义信息的获取是通过CBS模块的上采样以及四个阶段特征提取模块的组合来完成的。与YOLOv8不同,我们使用线性注意力块(如图4所示)作为构建表示的基本模块。在该块中,我们分别为线性注意力和多层感知器(MLP)添加了层归一化和残差连接,使网络结构更易于学习,模型更鲁棒。
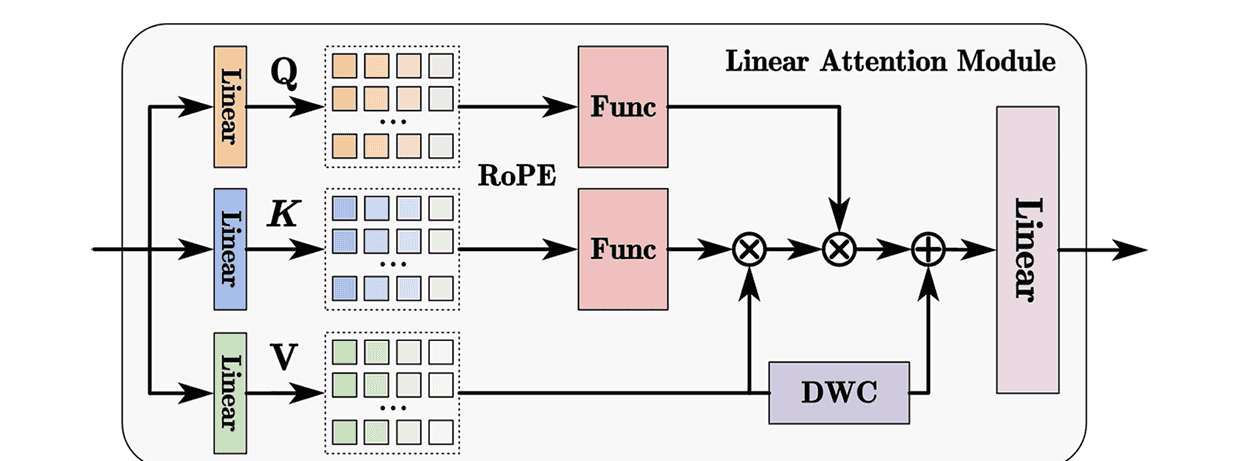
在图5中,我们进一步说明线性注意力的细节。对于查询和键,我们先执行旋转位置编码(RoPE)[38],然后执行核函数。RoPE通过嵌入绝对位置,使查询向量和键向量在点积过程中实现相对位置嵌入的效果。因此,它结合了两种方法的优点,既保证了计算速度,又在长序列上取得了更好的结果。在代码实现过程中,为避免算力浪费,我们采用了Su等人[38]推荐的公式,其可表示如下:
其中,
x
x
x 表示查询和键向量,
⊗
otimes
⊗ 表示逐元素乘法,
m
m
m 表示向量在序列中的位置。注意,
R
θ
d
R_ heta^d
Rθd 是一个正交矩阵,这确保了嵌入位置信息过程中的稳定性。参考正弦嵌入[31],我们设置
θ
i
=
1000
0
−
2
i
/
d
heta_i = 10000^{-2i/d}
θi=10000−2i/d,其中
d
d
d 表示维度。RoPE 使模型能够以非常小的代价获得性能提升。之后,我们引入了由Han等人[39]提出的简单映射核函数,以保持低计算复杂度并实现高表达能力,其公式可表示为:
其中,
x
∈
{
Q
,
K
}
x in {Q, K}
x∈{Q,K},
x
∗
p
x^{ast p}
x∗p 表示对
x
x
x 进行逐元素的
p
p
p 次幂运算。此外,为解决注意力权重同质化带来的聚合特征相似性问题,我们对
V
V
V 添加了深度可分离卷积[40]操作。因此,我们的线性注意力可重写为:
其中,
D
W
C
DWC
DWC 表示深度可分离卷积。此外,我们为查询和键向量添加了可学习的缩放因子,以实现更高效的更新学习。
最后,我们在骨干网络的末端遵循SPPF层的设计,通过不同层级的池化层聚合多尺度特征并输出固定长度的结果。
3.3.2. Neck
在原始YOLOv8中,低层级特征与高层级特征的融合方式只是简单的拼接操作,这不利于筛选出高信息量的特征,且在网络结构轻量化方面不够高效和适用。因此,我们提出了一种结合卷积块注意力模块(CBAM)[41]的新型选择性特征金字塔网络。
CBAM是一个轻量且有效的模块,能够根据特征在通道和空间维度上的重要性来强调或抑制特征。如图4所示,低层级和高层级特征首先经过CBAM处理,以增强网络的表示能力。给定中间特征图
X
∈
R
C
×
H
×
W
X in mathbb{R}^{C imes H imes W}
X∈RC×H×W作为输入,CBAM依次推断出一维通道注意力图
M
c
∈
R
C
×
1
×
1
M_c in mathbb{R}^{C imes 1 imes 1}
Mc∈RC×1×1 和二维空间注意力图
M
s
∈
R
1
×
H
×
W
M_s in mathbb{R}^{1 imes H imes W}
Ms∈R1×H×W。CBAM的操作可表示如下:
其中
⊗
otimes
⊗表示逐元素乘法。通道注意力的计算方式为:
其中 ( sigma ) 表示sigmoid函数,MLP表示多层感知器。平均池化和最大池化共享相同的MLP权重。空间注意力的计算方式为:
其中
f
7
×
7
f^{7 imes 7}
f7×7表示滤波器尺寸为
7
×
7
7 imes 7
7×7的卷积操作。
骨干网络的特征与下采样的特征在经过激活函数处理后进行逐元素相乘。这一过程起到门控机制的作用,在模型的颈部筛选特征。通过将骨干网络的语义信息作为滤波器,我们提出的FPN有效地将特征映射到高维且非线性的空间,从而减少信息冗余。值得一提的是,我们在 upsampling 过程中使用了 DySample [42],它比插值算法具有更好的性能,且与转置卷积操作相比,参数和 FLOPs 少得多。对于尺寸为
640
×
640
640 imes 640
640×640的图像,经 FPN 重新分配后,可输出尺寸为
80
×
80
80 imes 80
80×80、
40
×
40
40 imes 40
40×40 和
20
×
20
20 imes 20
20×20的特征图。经过线性注意力模块提取的精细化多尺度特征将被送入检测头。
3.3.3. Head
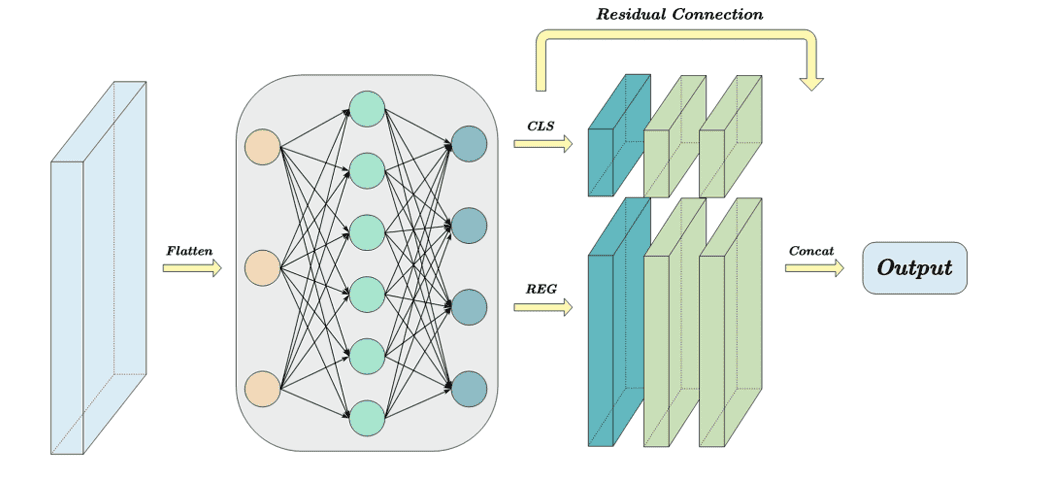
在目标检测中,分类和回归任务之间的冲突是不可避免的。因此,用于分类和定位的解耦头结构在大多数单阶段检测器中被广泛使用。然而,传统的解耦头采用卷积操作直接转换多尺度特征图的维度,导致大量的计算开销,并阻碍了语义信息的有效利用。因此,我们重新设计了一个高效的解耦检测头。
如图6所示,我们详细阐述了其结构。首先,一个MLP层执行非线性变换,有效生成具有所需维度的特征图。随后,这些精细化的特征图被用于分别处理分类和定位特征。我们在这两个部分分别使用了空洞卷积和逐点卷积的组合操作。与标准卷积相比,空洞卷积在保持相同参数数量的同时,为检测头赋予了更大的感受野,从而减轻了关键信息的损失[43]。同时,我们在解耦前后的特征之间建立了残差连接,以提高输出的稳定性。最后,我们通过拼接特征得到最终输出。
3.4. 损失函数
原始YOLOv8损失函数使用CIoU损失评估定位指标,并使用分布焦点损失(DFL)优化边界框的预测。CIoU损失的公式可表示为:
其中,
b
b
b 和
b
g
t
b^{gt}
bgt 分别表示预测框和真实框的中心,
w
w
w 和
h
h
h 表示预测框的宽度和高度,
w
g
t
w^{gt}
wgt 和
h
g
t
h^{gt}
hgt 表示真实框的宽度和高度,
ρ
2
(
b
,
b
g
t
)
ho^2(b, b^{gt})
ρ2(b,bgt) 表示预测框质心与真实框质心之间的欧氏距离,
c
c
c 表示预测框和真实框的最小包围框的对角线距离。项
v
v
v 考虑了预测框和真实框之间的宽高比差异。
而在ELA-YOLO中,我们使用Shape-IoU [44] 替代CIoU。该方法通过关注边界框本身的形状和尺度,解决了边界框固有属性对边界框回归的影响,更适合改进钢铁表面小缺陷的检测,其计算形式如下:
其中,
s
c
a
l
e
scale
scale 是尺度因子,与数据集中目标的尺度相关;
w
w
ww
ww 和
h
h
hh
hh 分别是水平和垂直方向的权重系数;
x
c
x_c
xc 和
y
c
y_c
yc 表示预测框中心的水平和垂直坐标,
x
c
g
t
x_c^{gt}
xcgt 和
y
c
g
t
y_c^{gt}
ycgt 表示真实框中心的水平和垂直坐标;
w
w
ww
ww 和
h
h
hh
hh 是水平和垂直方向的权重系数,其值与真实框的形状相关。
参考YOLOv8,我们也使用二元交叉熵(BCE)损失作为分类评估指标,并使用DFL损失使网络快速关注三者加权平均的分布,其可表示为:
其中,
l
o
s
s
loss
loss、
l
o
s
s
B
C
E
loss_{BCE}
lossBCE 和
l
o
s
s
D
F
L
loss_{DFL}
lossDFL 分别表示最终损失、BCE损失和DFL损失;
β
1
eta_1
β1、
β
2
eta_2
β2 和
β
3
eta_3
β3 分别表示各损失的权重。在本文中,我们选择
β
1
=
0.5
eta_1 = 0.5
β1=0.5,
β
2
=
7.5
eta_2 = 7.5
β2=7.5,
β
3
=
1.5
eta_3 = 1.5
β3=1.5。
4. 实验
4.1. 参数配置与实验数据集
我们使用PyTorch深度学习框架来训练和测试我们的模型,具体为PyTorch版本2.0.0和CUDA版本11.8。实验环境配置如下:Intel Xeon Silver 4214R CPU,配备24GB内存的Nvidia GeForce RTX 3090 GPU,以及Ubuntu 20.04操作系统。在训练过程中,我们使用SGD优化器,初始学习率为0.01,批量大小为16。为了提高对小目标的检测能力,输入图像分辨率设置为640×640。此外,采用余弦退火学习率调整策略以获得更好的训练结果。
为了更好地展示所提方法的性能和泛化性,我们选择了三个公开可用的表面缺陷检测数据集。
NEU-DET [45] 是由Song和Yan构建的开放钢铁表面缺陷检测数据集,包含六种热轧带钢表面缺陷类别,即裂纹(Cr)、夹杂物(In)、划痕(Sc)、氧化铁皮压入(Rs)、麻点表面(Ps)和斑块(Pa)。每种样本类型有300张分辨率为200×200的图像,总数为1800张。在实验中,我们参考之前的工作[46,47],将数据集随机按8:2的比例划分为训练集和测试集,即1440张图像用于训练,360张图像用于测试。
DAGM2007 [48] 是一个著名的钢铁表面缺陷检测数据集,包含512×512图像中的10个不同类别。其中,6类在每个类别中有150张缺陷图像,另外4类在每个类别中有300张缺陷图像。我们使用这2100张正样本图像作为数据集,训练集和测试集的比例为1:1,即1050张图像用于训练,1050张图像用于测试。
GC10-DET [49] 是由Lv等人构建的开放钢铁表面缺陷检测数据集,包含来自实际工业的10种表面缺陷类型,即冲孔(Pu)、焊点(Wd)、月牙形(Hp)、辊印(Rg)、水印(Ws)、油斑(Oi)、丝纹(Sl)、夹杂物(In)、划伤(Sc)、褶皱(Cr)和腰折(Wf)。数据集中共有2280张图像,在我们的实验中被划分为1824张训练图像和456张测试图像。
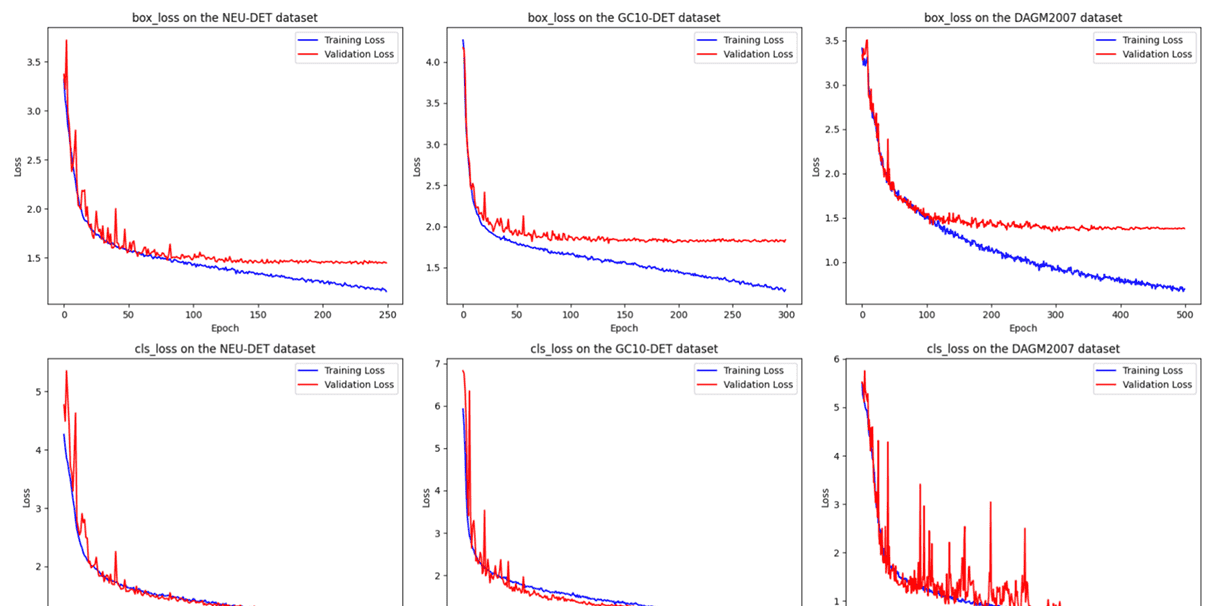
由于这三个数据集在样本数量和难度级别上的差异,训练过程中的epoch数也相应不同。图7展示了所提方法在三个数据集上的定位损失(记为box loss)和分类损失(记为cls loss)。图中蓝色线表示训练损失,红色线表示验证损失。可以明显看出,分类损失的收敛速度比定位损失慢。ELA-YOLO在NEU-DET和GC10-DET数据集上表现出更快的收敛速度,而在DAGM2007数据集上的收敛速度较慢,具体来说,在NEU-DET数据集上分类损失在250个epoch内收敛,在DAGM2007数据集上在300个epoch内收敛,在GC10-DET数据集上需要500个epoch。在整个实验过程中,我们为不同的数据集选择了不同的epoch数,以确保模型完全收敛,同时防止过拟合。
4.2. 实验指标
为了评估我们模型的性能,我们基于精确率(Precision)和召回率(Recall),使用平均精确率(AP)和平均精确率均值(mAP)作为主要指标。交并比(IoU)阈值设为0.5,即如果真实框和预测框之间的IoU超过0.5,则认为该预测是正确的。以下公式定义了评估指标:
其中,
P
P
P 和
R
R
R 分别表示精确率和召回率,
T
P
TP
TP 是正确识别的正样本数量,
F
P
FP
FP 是被识别为正样本的负样本数量,
F
N
FN
FN 是被识别为负样本的正样本数量。
此外,为了衡量模型的大小以及检测速度,我们引入参数(Params)、浮点运算量(FLOPs)和每秒帧数(FPS)作为评估指标,这是由于工厂部署设备的计算资源限制以及实际工业生产中对低延迟的要求。
4.3. 实验结果与分析
4.3.1. 在NEU-DET上与其他方法的对比
为了验证我们所提方法的性能,我们将ELA-YOLO与YOLO系列和其他经典模型进行检测对比,包括RT-DETR [50]、Faster R-CNN、FCOS [51]、SSD和CenterNet。
为了控制变量,上述所有方法均在我们的平台上以相同的参数设置进行测试。ELA-YOLO和其他方法在NEU-DET上的检测结果如图8所示。这些图像显示了识别到的信息,包括预测框、缺陷类型和置信度。这些图片中的缺陷都非常复杂,我们的模型能够以相对较高的置信度分数检测到它们。特别是在处理Rs和Cr时,我们的方法预测的边界框更接近真实框,如图9所示。

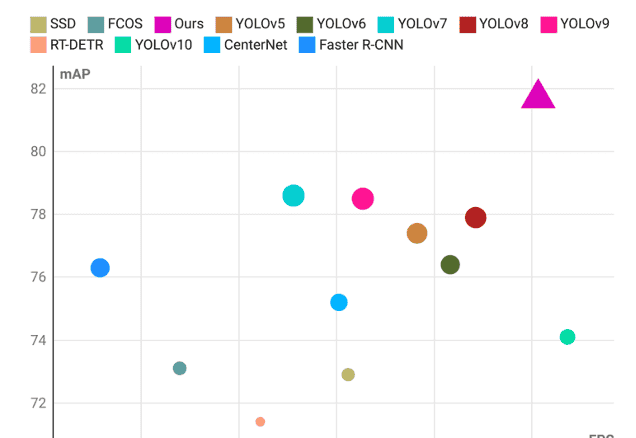
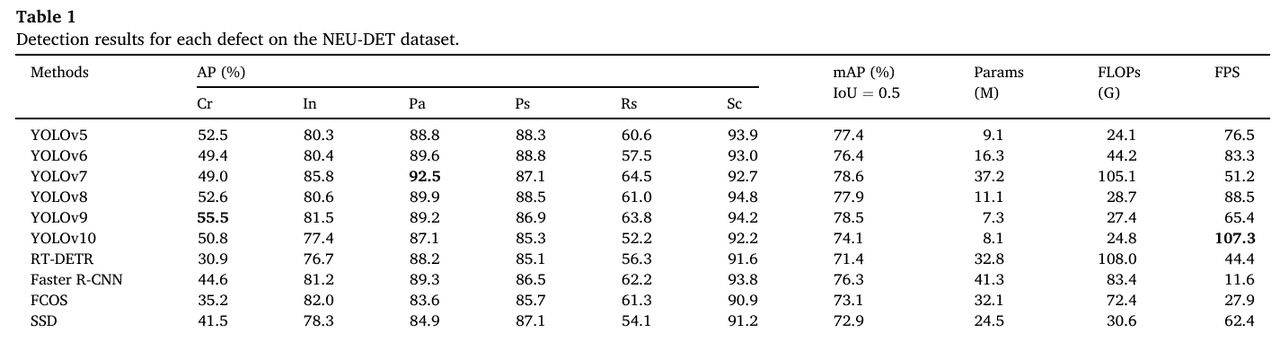
如表1所示,我们的方法实现了最高的81.7% mAP,同时具有最少的5.4 M参数和16.5 G FLOPs。与基线YOLOv8相比,我们的方法实现了3.8%的mAP提升,以及12.2 G FLOPs的降低。同时,在每个类别上,ELA-YOLO也实现了最高的整体准确率。除了Cr和Pa,我们的方法也实现了最高的AP。由于包含了图像预处理,实际FPS仅略低于YOLOv10,但我们的方法的mAP高出7.6%。为了比较延迟和精度,我们制作了散点图,如图9所示。作为区分,我们的方法特别用三角形标记,其大小与准确率相关。可以观察到,我们的方法能够达到一个很好的平衡点,这与工业实际应用的需求相对应。
4.3.2. 在DAGM上与其他方法的对比
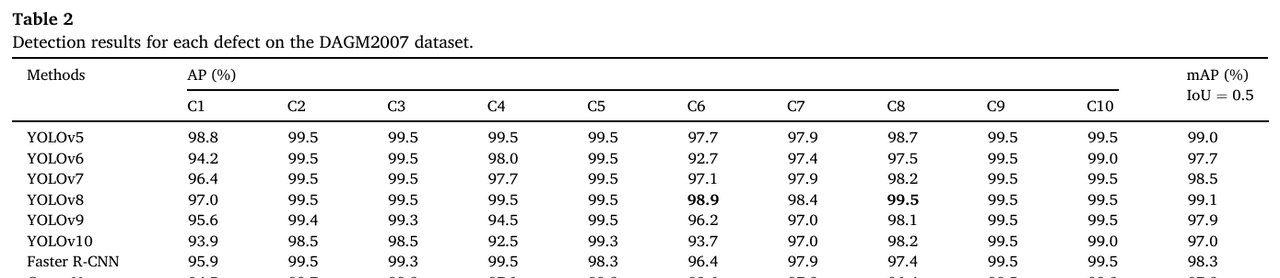
为了进一步验证模型性能,我们在DAGM2007数据集上进行实验。如表2所示,我们的方法实现了最高的99.3% mAP。与基线YOLOv8相比,我们的方法实现了0.2%的mAP提升。同时,在每个类别上,ELA-YOLO也实现了最高的整体准确率。除了Class 6和Class 8,我们的方法也实现了最高的AP。
ELA-YOLO在DAGM2007上的检测结果如图10所示。我们提出的方法不仅非常准确地定位了位置,而且具有很高的置信度,这确保了自动检测的可靠性。即使在处理如Class 1和Class 7这类尺度小、对比度低的局部缺陷时,我们提出的ELA-YOLO仍然能够很好地检测到它们。

4.3.3. 在GC10-DET上与其他方法的对比
在真实工业场景中,摄像头捕捉的图像中可能存在多种缺陷。因此,在GC10-DET的实验中,我们不仅关注每种缺陷的检测准确率,还关注我们的方法如何处理同一图像中存在多尺度、多类型缺陷的情况。
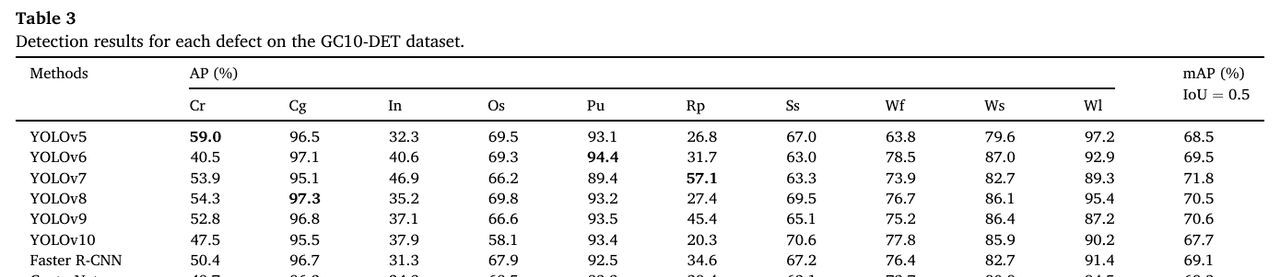
检测结果的详细信息如图11所示。在包含如In和Pu这类微小尺度缺陷,以及如Wf和Ss这类不明显缺陷的单缺陷图像案例中,可以观察到我们提出的方法能够克服复杂纹理带来的困难并准确识别它们。在多缺陷图像案例中,面对缺陷间的较大差异,我们的方法识别混合缺陷的能力非常出色。如表3所示,我们的方法实现了最高的74.3% mAP。与基线YOLOv8相比,我们的方法实现了3.8%的mAP提升。同时,在每个类别上,ELA-YOLO也实现了最高的整体准确率。在包括In、Os、Ss、Wf、Ws和Wl的缺陷中,我们的方法实现了最高的AP。

4.3.4. 综合分析
结合这三个实验,我们可以得出以下结论。
(1) 我们提出的方法在小尺度目标检测方面取得了显著改进。由于注意力机制提供了更丰富、更有效的高层表示,模型在处理图像时更关注微小的局部细节特征。例如,对于NEU-DET和GC10-DET数据集中的夹杂物(Inclusion)缺陷类型,我们的模型精度与其他方法相比领先很多。
(2) 对于一些低对比度、低亮度或图像纹理不明显的情况,如DAGM2007数据集中的Class 1、Class 7,以及GC10-DET数据集中的Ss、Wf、Wl,我们的模型与原始YOLOv8相比表现出显著改进。一方面,通过在预处理阶段调整图像的对比度和锐度,图像的复杂度降低,模型识别难度减小。另一方面,带有选择机制的FPN在一定程度上帮助模型排除采集图像中的部分干扰,使输出的多尺度特征图更集中、更鲁棒。
(3) 线性注意力机制的引入并未增加该方法的计算量和延迟。同时,与YOLOv8相比,模型的整体参数数量降低了51.4%,这得益于颈部网络更高效的设计和检测头更轻量化的结构。在实际推理速度方面,除了没有非极大值抑制(NMS)过程的YOLOv10外,我们的模型取得了最快的结果。
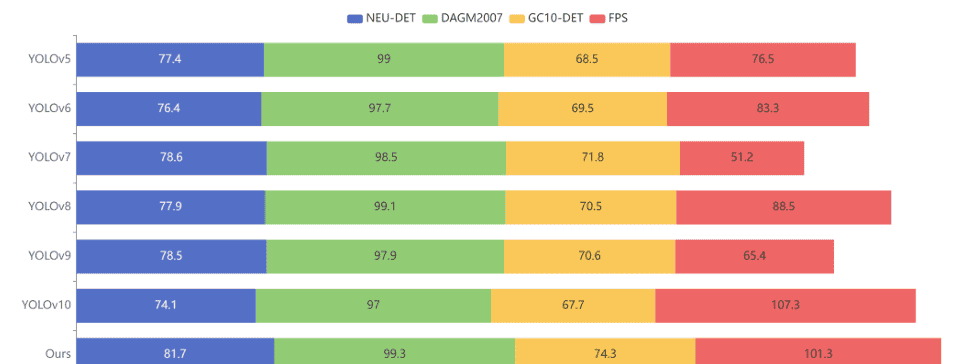
最后,我们制作了堆叠直方图来综合各模型的性能,包含FPS结果以及在NEU-DET、DAGM2007和GC10-DET数据集上的mAP结果,
如图12所示
5. 讨论
在本节中,我们将对所提出的方法进行一些讨论。
5.1. 模型架构
为了全面评估线性注意力(LA)模块、选择性特征金字塔网络(FPN)和轻量级头的有效性,我们在NEU-DET数据集上进行了消融研究,将各种结构与基线模型进行比较。
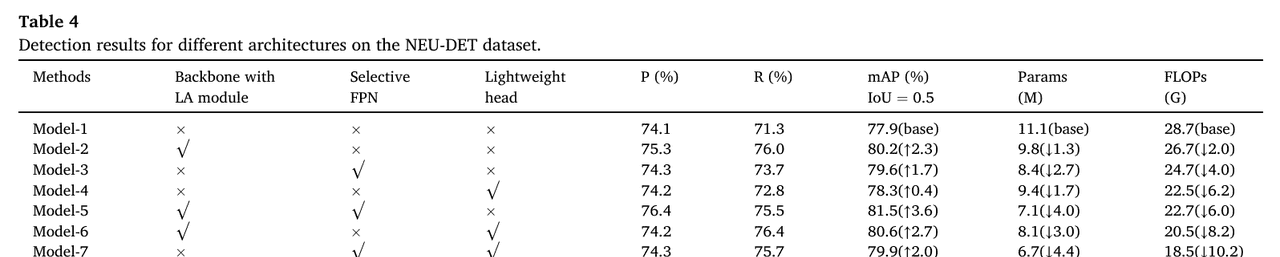
表4中的总结结果表明,每个单独的组件在降低模型复杂度的同时,都对性能提升有贡献。具体而言,将LA模块集成到骨干网络中,在精度上提供了最显著的独立提升,mAP提高了2.3%,同时参数减少了1.3 M,FLOPs减少了2.0 G,突出了其高效特征提取的强大能力。选择性FPN旨在优先考虑不同尺度的信息特征,进一步将性能提高了1.7% mAP,同时实现了参数(2.7 M)和FLOPs(4.0 G)的大幅减少,证明了其在提高精度和计算效率方面的双重作用。同时,轻量级头主要侧重于最小化计算负担,在mAP上贡献了0.4%的提升,同时参数大幅减少了1.7 M,FLOPs减少了6.2 G,强调了其在以最小开销保持检测性能方面的重要性。类似地,在包括Model-5、Model-6和Model-7在内的组合模型中,我们观察到了一致的实验结果。当LA模块分别与选择性FPN和轻量级头配对时,这两种组合都取得了显著的性能提升。选择性FPN和轻量级头的组合也导致模型参数和计算成本的显著降低。当结合这三个改进时,所提出的模型实现了最佳的整体性能,与基线相比mAP提高了3.8,同时将参数减少到5.4 M,FLOPs减少到16.5 G,实现了精度、模型大小和计算效率的显著平衡。这些结果证明了所提出改进的协同效应,使该模型成为故障检测任务的高效、轻量级解决方案。
5.2. 我们的方法在不同框架下的有效性
为了进一步验证我们提出的方法的有效性和先进性,我们将所提出的策略应用于各种模型架构,并将结果与原始模型进行比较。具体而言,我们选择类似于YOLOv8的模型,以便用我们设计的结构无缝替换现有组件。最初,我们用基于线性注意力的骨干网络替换原始骨干网络。如表5(上)总结的实验结果所示,所有模型变体的精度都有显著提高,同时参数数量和计算成本都有显著降低。例如,YOLOv6的精度提高了2.1 mAP,同时参数减少了7.4 M,计算成本降低了20.5 G。
随后,我们用我们提出的选择性特征金字塔网络和轻量级检测头替换原始颈部和头部网络。如表5(下)详细说明的那样,这种替换导致参数数量和计算成本的大幅减少,同时精度显著提高。例如,YOLOv9的计算成本降低了11.4 G,参数减少了3.4 M,同时精度提高了1.0 mAP。在不同框架下进行的这些对比实验表明,线性注意力模块的引入在资源有限的情况下实现了更好的缺陷检测性能。此外,选择性特征金字塔网络和轻量级检测头的设计降低了模型的计算成本,提高了整体运行效率。我们提出的方法在不同框架下表现出出色的有效性和泛化性。
5.3. 损失函数的有效性
为了确定最适合模型的损失函数,我们在NEU-DET数据集上测试了几种选项,包括CIoU、DIoU [52]、EIoU、SIoU [53]以及我们使用的Shape-IoU。DIoU损失的公式如下:
其中,
b
b
b 和
b
g
t
b^{gt}
bgt 分别表示预测框和真实框的中心,
c
c
c 表示覆盖预测框和真实框的最小包围框的对角线距离。
EIoU的公式如下:
其中,
w
w
w 和
h
h
h 表示真实框的宽度和高度,
ρ
2
(
b
,
b
g
t
)
ho^2(b, b^{gt})
ρ2(b,bgt) 表示预测框中心与真实框中心之间的欧氏距离,
c
w
c_w
cw 和
c
h
c_h
ch 表示最小包围框的宽度和高度。
SIoU的公式如下:
其中,
ρ
x
=
(
x
c
g
t
−
x
c
c
w
)
2
ho_x = left( frac{x_c^{gt} – x_c}{c_w}
ight)^2
ρx=(cwxcgt−xc)2,
ρ
y
=
(
y
c
g
t
−
y
c
c
h
)
2
ho_y = left( frac{y_c^{gt} – y_c}{c_h}
ight)^2
ρy=(chycgt−yc)2,
γ
=
2
−
Λ
gamma = 2 – Lambda
γ=2−Λ,
x
c
x_c
xc 和
y
c
y_c
yc 表示真实框中心的水平和垂直坐标,
Λ
Lambda
Λ 表示角度成本。
其中,
ω
w
=
∣
w
−
w
g
t
∣
max
(
w
,
w
g
t
)
omega_w = frac{|w – w^{gt}|}{max(w, w^{gt})}
ωw=max(w,wgt)∣w−wgt∣,
ω
h
=
∣
h
−
h
g
t
∣
max
(
h
,
h
g
t
)
omega_h = frac{|h – h^{gt}|}{max(h, h^{gt})}
ωh=max(h,hgt)∣h−hgt∣。
θ
heta
θ 是一个常数,它定义了应该对形状成本给予多少关注。
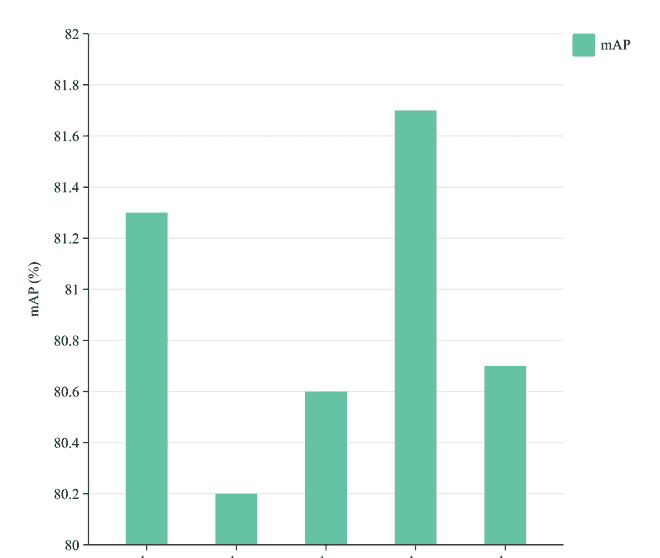
我们使用不同的损失函数在NEU-DET数据集上训练我们的方法。图13中的结果表明,我们采用的Shape-IoU产生了最有利的结果,这得益于其对边界框本身的形状和尺度的关注。与上述损失函数相比,Shape-IoU损失是最适合我们模型的。
5.4. 预处理的有效性
我们采用的预处理方法在表面检测的精度上带来了一些提升。为了验证该预处理过程的有效性和泛化性,我们在NEU-DET数据集上对多个YOLO模型进行了测试,结果如图14所示。尽管不同模型的提升程度有所不同,但所有模型的识别精度都有所提高。对于我们提出的ELA-YOLO,精度提高了0.6 mAP。同时,在我们的平台上测试后,实际推理时间仅增加了0.3 ms延迟。考虑到该方法处理每张图像的总运行时间为9.87 ms,我们认为通过添加预处理过程来获得性能提升是非常值得的。
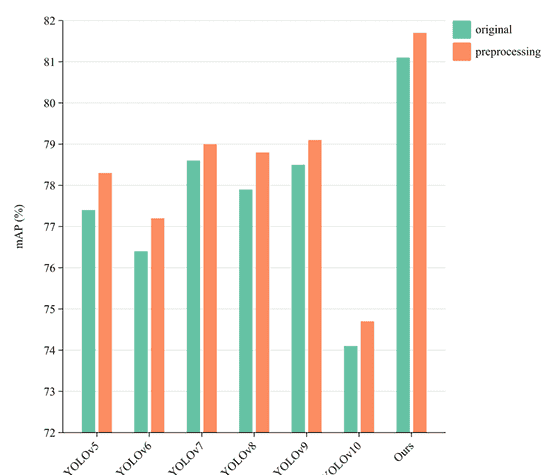
5.5. 特征可视化与分析
为了更深入地了解模型如何检测异常以及其注意力集中在何处,我们利用Grad-CAM可视化工具生成推理过程中产生的特征图的热力图。这种可视化通过突出显示对预测贡献最大的区域,帮助解释模型的决策过程。为了确保全面且公平的比较,我们将提出的ELA-YOLO模型与两个广泛使用的基线模型:YOLOv5和YOLOv8进行评估。图15展示了来自不同数据集的三个代表性案例的热力图,每个案例都以不同的方式挑战模型。

案例(a)呈现了一个具有复杂且高度细节化特征的简单场景。ELA-YOLO表现出明显的优势,能够精确地定位缺陷区域。与YOLOv5和YOLOv8表现出的更分散或误导性的注意力不同,ELA-YOLO在关键区域保持了更紧密、更集中的响应,表明其在区分缺陷模式和背景噪声方面具有更强的能力。案例(b)呈现了一个更具挑战性的场景,其中存在细微、低对比度的缺陷,这些缺陷更难区分。ELA-YOLO的优越性变得更加明显。当基线模型难以捕捉这些微弱特征,导致注意力图分散或不完整时,ELA-YOLO生成了高度集中的热力图,准确地聚焦于产品上。这一性能突显了该模型强大的特征提取能力,特别是在低信号环境中。这对于工业检测任务至关重要,因为在这些任务中缺陷通常在视觉上不明显。案例©涉及小而难以检测的夹杂物,这是许多目标检测模型由于有限的像素表示而存在的已知弱点。尽管如此,ELA-YOLO保持了其性能,能够以极高的精度有效地识别这些微小目标。热力图显示,ELA-YOLO在最小干扰的情况下锁定小缺陷区域,而YOLOv5和YOLOv8则表现出更广泛、不太准确的注意力。这凸显了ELA-YOLO在小目标检测方面的优势,这归功于其增强的特征融合和多尺度表示能力。
总而言之,在这些多样且具代表性的案例中,ELA-YOLO通过展现更强的定位精度、对细微缺陷的关注度提升以及增强的小目标检测能力,始终优于基线模型。这些视觉结果验证了该模型在应对工业缺陷检测关键挑战方面的有效性,证明了其对复杂、低对比度和小目标场景的适应性。
5.6. 局限性与未来工作
尽管ELA-YOLO表现出了强劲的性能,但我们承认我们的方法仍存在某些局限性,这些局限性为进一步的研究和改进提供了方向。一个关键局限性是,在较小的数据集上训练时存在过拟合的潜在风险,而较小的数据集在工业缺陷检测场景中很常见。过拟合可能会导致泛化能力下降,尤其是在遇到训练数据中代表性不足的罕见或高度特殊的缺陷类型时。虽然我们目前在NEU-DET、DAGM2007和GC10-DET数据集上的实验证明了该模型在不同缺陷类别中的鲁棒性,但由于工业数据集的规模和多样性有限,该模型可能仍难以处理未见过的或新型的缺陷模式。
此外,我们当前的图像预处理技术,包括对比度增强和锐化,仅能对图像质量进行基本的改善。虽然这些技术有助于减轻噪声、不均匀光照和低对比度纹理的影响,但它们仍然相对简单。为了解决这一问题,未来的研究可以探索先进的基于深度学习的图像生成方法,以针对工业缺陷场景专门进行数据增强。这将有助于扩展有限的数据集,降低过拟合风险,并提高模型在较小数据集上的性能。此外,整合大规模预训练模型可以进一步增强ELA-YOLO的泛化能力。通过利用从多样数据集中学到的丰富特征表示,该模型可以具备更强的少样本学习能力,使其能够更准确地识别不常见且高度多变的缺陷。这一方向对于实际工业部署具有重要前景,因为罕见缺陷的数据收集仍然是一个持续的挑战。
6. 结论
在本文中,我们提出了一种名为ELA-YOLO的新型检测方法,用于工业中的钢铁表面缺陷检测。我们的方法包含图像预处理机制和基于YOLOv8的高效检测器,其特征在于采用线性注意力的骨干网络、选择性特征金字塔网络和轻量级检测头。实验结果表明,所提出的ELA-YOLO模型在NEU-DET数据集上实现了81.7 mAP,在DAGM2007数据集上实现了99.3 mAP,在GC10-DET数据集上实现了74.3 mAP。凭借5.4 M参数和16.5 GFLOPs,它在达到第二快推理速度的同时,超越了其他最先进方法的精度。我们方法的优势在于其能够将精度与效率相结合,从而实现有效的异常检测。我们的模型在多尺度复杂缺陷检测方面表现出色。然而,值得注意的是,当面对有限的缺陷样本时,所提出的方法会面临挑战,使其在涉及小检测集的任务中能力不足。此外,ELA-YOLO对参数设置很敏感,特别是在图像预处理阶段,需要仔细配置。检测器的轻量级设计促进了深度学习模型的实际部署和高效运行。从工业应用的角度来看,我们的方法为需要实时精确监控的生产线提供了自动化检测解决方案,助力工业智能化和工业4.0的发展[54]。
引用
[1] A. Saberironaghi, J. Ren, M. El-Gindy, Defect detection methods for industrial products using deep learning techniques: a review, Algorithms 16 (2) (2023) 95, https://doi.org/10.3390/a16020095.
[2] M. Shahin, M. Maghanaki, A. Hosseinzadeh, F.F. Chen, Advancing network security in industrial IoT: a deep dive into AI-enabled intrusion detection systems, Adv. Eng. Inf. 62 (2024) 102685, https://doi.org/10.1016/j.aei.2024.102685.
[3] Y.J. Chen, Y.Y. Ding, F. Zhao, E. Zhang, Z.N. Wu, L.H. Shao, Surface defect detection methods for industrial products: a review, Appl. Sci.-Basel 11 (16) (2021) 7657, https://doi.org/10.3390/app11167657.
[4] X. Wen, J. Shan, Y. He, K.C. Song, Steel surface defect recognition: a survey, Coatings 13 (1) (2023) 17, https://doi.org/10.3390/coatings13010017.
[5] J.H. Yan, J.M. He, Feature Extraction and Classification of Steel Plate Surface Defects Based on Principal Component Analysis. In: 40th Chinese Control Conference (CCC). Shanghai, PEOPLES R CHINA; 2021. p. 7021-7026. doi: 10.23919/ccc52363.2021.9550223.
[6] Z.H. Wang, Y.M. Liu, T. Wang, D.Y. Gong, D.H. Zhang, Prediction model of hot strip crown based on industrial data and hybrid the PCA-SDWPSO-ELM approach, Soft. Comput. 27 (17) (2023), https://doi.org/10.1007/s00500-023-07895-6.
[7] X.H. Liu, Z.Y. He, Y. Sun, On study of a method for detecting micro-deformation defects of steel plate surface. In: Applied Optics and Photonics China (AOPC) Conference – Optics Ultra Precision Manufacturing and Testing. Shanghai, PEOPLES R CHINA; 2020. doi: 10.1117/12.2576393.
[8] R. Kaur, S. Singh, A comprehensive review of object detection with deep learning, Digital Signal Process. 132 (2023) 103812, https://doi.org/10.1016/j.dsp.2022.103812.
[9] Z.X. Zou, K.Y. Chen, Z.W. Shi, Y.H. Guo, J.P. Ye, Object detection in 20 years: a survey, Proc. IEEE 111 (3) (2023), https://doi.org/10.1109/jproc.2023.3238524.
[10] J. Redmon, S. Divvala, R. Girshick, A. Farhadi, Ieee, You Only Look Once: Unified, Real-Time Object Detection. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA; 2016. p. 779-788. doi: 10.1109/cvpr.2016.91.
[11] J. Redmon, A. Farhadi, Ieee. YOLO9000: Better, Faster, Stronger. In: 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, 2017. pp. 6517-6525. doi: 10.1109/cvpr.2017.690.
[12] J. Redmon, A. Farhadi, YOLOv3: an incremental improvement, Arxiv (2018), https://doi.org/10.48550/arXiv.1804.02767.
[13] A. Bochkovskiy, C.-Y. Wang, H.-Y. Mark Liao, YOLOv4: optimal speed and accuracy of object detection, Arxiv. (2020), https://doi.org/10.48550/arXiv.2004.10934.
[14] Github. YOLOv5 SOTA Realtime Instance Segmentation. https://github.com/ultralytics/yolov5/releases/tag/v7.0; 2022 [accessed November 22 2022].
[15] C. Li, L. Li, H. Jiang, K. Weng, Y. Geng, L. Li, Z. Ke, Q. Li, M. Cheng, W. Nie, Y. Li, B. Zhang, Y. Liang, L. Zhou, X. Xu, X. Chu, X. Wei, X. Wei, YOLOv6: a single-stage object detection framework for industrial applications, Arxiv (2022), https://doi.org/10.48550/arXiv.2209.02976.
[16] C.Y. Wang, A. Bochkovskiy, H.Y.M. Liao, YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors, in: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, https://doi.org/10.1109/cvpr52729.2023.00721.
[17] Github. ‘ultralytics 8.2.58’ FastSAM code refactor. https://github.com/ultralytics/ultralytics/releases/tag/v8.2.58; 2024 [accessed July 16 2024].
[18] C.-Y. Wang, I.H. Yeh, H.-Y.-M. Liao, YOLOv9: learning what you want to learn using programmable gradient information, Arxiv (2024), https://doi.org/10.48550/arXiv.2402.13616.
[19] A. Wang, H. Chen, L. Liu, K. Chen, Z. Lin, J. Han, G. Ding, YOLOv10: real-time end-to-end object detection, Arxiv (2024), https://doi.org/10.48550/arXiv.2405.14458.
[20] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.Y. Fu, A.C. Berg, SSD: Single Shot MultiBox Detector, in: 14th European Conference on Computer Vision (ECCV). Amsterdam, NETHERLANDS; 2016. p. 21-37. doi: 10.1007/978-3-319-46448-0_2.
[21] X. Zhou, D. Wang, P. Krähenbühl, Objects as points, Arxiv (2019), https://doi.org/10.48550/arXiv.1904.07850.
[22] S. Ren, K. He, R. Girshick, J. Sun, Faster R-CNN: towards real-time object detection with region proposal networks, Arxiv. (2016), https://doi.org/10.48550/arXiv.1506.01497.
[23] C. Zhaowei, N. Vasconcelos, Cascade R-CNN: delving Into High Quality Object Detection, in: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Proceedings, 2018. doi: 10.1109/cvpr.2018.00644.
[24] K. Chen, J.M. Pang, J.Q. Wang, Y. Xiong, X.X. Li, S.Y. Sun, W.S. Feng, Z.W. Liu, J.P. Shi, W.L. Ouyang, C.C. Loy, D.H. Lin, I.C. Soc, Hybrid Task Cascade for Instance Segmentation. In: 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA; 2019. pp. 4969-4978. doi: 10.1109/cvpr.2019.00511.
[25] W. Zhang, J.Y. Liu, Z.Q. Yan, M.H. Zhao, X.Y. Fu, H.J. Zhu, FC-YOLO: an aircraft skin defect detection algorithm based on multi-scale collaborative feature fusion, Meas. Sci. Technol. 35 (11) (2024) 115405, https://doi.org/10.1088/1361-6501/ad6bad.
[26] J.J. Ma, S.Y. Hu, J.Z. Fu, G. Chen, A hierarchical attention detector for bearing surface defect detection, Expert Syst. Appl. 239 (2024) 122365, https://doi.org/10.1016/j.eswa.2023.122365.
[27] L. Zhao, Y. Zheng, T. Peng, E.R. Zheng, Metal surface defect detection based on a transformer with multi-scale mask feature fusion, Sensors 23 (23) (2023) 9381, https://doi.org/10.3390/s23239381.
[28] W.N. Xie, X.Y. Sun, W.F. Ma, A light weight multi-scale feature fusion steel surface defect detection model based on YOLOv8, Meas. Sci. Technol. 35 (5) (2024) 055017, https://doi.org/10.1088/1361-6501/ad296d.
[29] Y. Zhang, H.F. Zhang, Q.Q. Huang, Y. Han, M.H. Zhao, DsP-YOLO: an anchor-free network with DsPAN for small object detection of multiscale defects, Expert Syst. Appl. 241 (2024) 122669, https://doi.org/10.1016/j.eswa.2023.122669.
[30] L. Wang, X.B. Liu, J.T. Ma, W.Z. Su, H. Li, Real-time steel surface defect detection with improved multi-scale YOLO-v5, Processes 11 (5) (2023) 1357, https://doi.org/10.3390/pr11051357.
[31] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, L. Kaiser, I. Polosukhin, Attention Is All You Need. In: 31st Annual Conference on Neural Information Processing Systems (NIPS). Long Beach, CA; 2017. doi: 10.48550/arXiv.1706.03762.
[32] X.K. Sun, K.C. Song, X. Wen, Y.Y. Wang, Y.H. Yan, SDD-DETR: surface defect detection for no-service aero-engine blades with detection transformer, IEEE Trans. Autom. Sci. Eng. (2024), https://doi.org/10.1109/tase.2024.3457829.
[33] X. Zhou, S.H. Zhou, Y.C. Zhang, Z.H. Ren, Z.Y. Jiang, H.F. Luo, GDALR: global Dual Attention and Local Representations in transformer for surface defect detection, Measurement 229 (2024) 114398, https://doi.org/10.1016/j.measurement.2024.114398.
[34] Q. Zhang, J.H. Lai, J.Y. Zhu, X.H. Xie, Wavelet-guided promotion-suppression transformer for surface-defect detection, IEEE Trans. Image Process. 32 (2023), https://doi.org/10.1109/tip.2023.3293770.
[35] M. Raghu, T. Unterthiner, S. Kornblith, C.Y. Zhang, A. Dosovitskiy, Do Vision Transformers See Like Convolutional Neural Networks?, in: 35th Conference on Neural Information Processing Systems (NeurIPS). Electr Network, 2021, https://doi.org/10.48550/arXiv.2108.08810.
[36] S.Z. Wang, B. Li, M. Khabsa, H. Fang, H. Ma, Linformer: self-attention with linear complexity, Arxiv. (2020), https://doi.org/10.48550/arXiv.2006.04768.
[37] H. Zhong, D.X. Fu, L. Xiao, F. Zhao, J. Liu, Y.M. Hu, B. Wu, STFE-Net: a multi-stage approach to enhance statistical texture feature for defect detection on metal surfaces, Adv. Eng. Inf. 61 (2024) 102437, https://doi.org/10.1016/j.aei.2024.102437.
[38] J.L. Su, M. Ahmed, Y. Lu, S.F. Pan, W. Bo, Y.F. Liu, RoFormer: enhanced transformer with rotary position embedding, Neurocomputing 568 (2024) 127063, https://doi.org/10.1016/j.neucom.2023.127063.
[39] Han, D.C.; Pan, X.R.; Han, Y.Z.; Song, S.J.; Huang, G.; Ieee. FLatten Transformer: Vision Transformer using Focused Linear Attention. In: IEEE/CVF International Conference on Computer Vision (ICCV). Paris, FRANCE; 2023. p. 5938-5948. doi: 10.1109/iccv51070.2023.00548.
[40] A.G. Howard, Z. Menglong, C. Bo, D. Kalenichenko, W. Weijun, T. Weyand, M. Andreetto, H. Adam, MobileNets: efficient convolutional neural networks for mobile vision applications, ArXiv. (2017), https://doi.org/10.48550/arXiv.1704.04861.
[41] S.H. Woo, J. Park, J.Y. Lee, I.S. Kweon, CBAM: Convolutional Block Attention Module, in: 15th European Conference on Computer Vision (ECCV). Munich, GERMANY, 2018. pp. 3-19. doi: 10.1007/978-3-030-01234-2_1.
[42] W. Liu, H. Lu, H. Fu, Z. Cao, Learning to Upsample by Learning to Sample, in: 2023 IEEE/CVF International Conference on Computer Vision (ICCV), 2023, https://doi.org/10.1109/iccv51070.2023.00554.
[43] J.Y. Jiao, Y.M. Tang, K.Y. Lin, Y.P. Gao, A.J. Ma, Y.W. Wang, W.S.D. Zheng, Multi-Scale dilated transformer for visual recognition, IEEE Trans. Multimedia 25 (2023), https://doi.org/10.1109/tmm.2023.3243616.
[44] H. Zhang, S. Zhang, Shape-IoU: more accurate metric considering bounding box shape and scale, ArXiv. (2023), https://doi.org/10.48550/arXiv.2312.17663.
[45] K.C. Song, Y.H. Yan, A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects, Appl. Surf. Sci. 285 (2013), https://doi.org/10.1016/j.apsusc.2013.09.002.
[46] C. Zhao, X. Shu, X. Yan, X. Zuo, F. Zhu, RDD-YOLO: a modified YOLO for detection of steel surface defects, Measurement 214 (2023) 112776, https://doi.org/10.1016/j.measurement.2023.112776.
[47] R.S. Tian, M.P. Jia, DCC-CenterNet: a rapid detection method for steel surface defects, Measurement 187 (2022) 110211, https://doi.org/10.1016/j.measurement.2021.110211.
[48] D. Weimer, B. Scholz-Reiter, M. Shpitalni, Design of deep convolutional neural network architectures for automated feature extraction in industrial inspection, Cirp. Annals-Manuf. Technol. 65 (1) (2016), https://doi.org/10.1016/j.cirp.2016.04.072.
[49] X.M. Lv, F.J. Duan, J.J. Jiang, X. Fu, L. Gan, Deep metallic surface defect detection: the new benchmark and detection network, Sensors 20 (6) (2020) 1562, https://doi.org/10.3390/s20061562.
[50] Y. Zhao, W. Lv, S. Xu, J. Wei, G. Wang, Q. Dang, Y. Liu, J. Chen, DETRs Beat YOLOs on real-time object detection, Arxiv. (2024), https://doi.org/10.48550/arXiv.2304.08069.
[51] Z. Tian, C.H. Shen, H. Chen, T.F.C.O.S. He, A simple and strong anchor-free object detector, Ieee Trans. Pattern Anal. Machine Intell. 44 (4) (2022), https://doi.org/10.1109/tpami.2020.3032166.
[52] Z.H. Zheng, P. Wang, W. Liu, J.Z. Li, R.G. Ye, D.W. Ren, Assoc Advancement Artificial, I. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In: 34th AAAI Conference on Artificial Intelligence / 32nd Innovative Applications of Artificial Intelligence Conference / 10th AAAI Symposium on Educational Advances in Artificial Intelligence. New York, NY; 2020. p. 12993-13000.
[53] Z. Gevorgyan, SIoU loss: more powerful learning for bounding box regression, Arxiv. (2022), https://doi.org/10.48550/arXiv.2205.12740.
[54] Y. Zhang, et al., Adaptive feature consolidation residual network for exemplar-free continuous diagnosis of rotating machinery with fault-type increments, Adv. Eng. Inf. 62 (2024) 102715.
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...