
在LangChain之前,如果你尝试构建一个企业级的LLM应用时,可能会遇到了这个问题:项目初期选择了GPT-4作为核心引擎,随着成本压力增大,决定切换到开源的Llama模型,结果发现几乎要重写所有代码——每个模型的API接口、prompt格式、上下文管理方式都不一样。
LangChain这个框架出现之后,以上的问题就变得相对简单了,它提供了一个统一的抽象层,让开发者可以像搭积木一样组装LLM应用,而不必被具体的模型实现细节束缚。
LangChain由Harrison Chase于2022年10月推出,仅用8个月就成为GitHub增长最快的开源项目,到2023年6月时Star数突破5万。IBM Technology将其列为AI开发者必学技术,超过54万人观看了他们的教程视频。
今天,我们系统地拆解LangChain的技术架构、核心组件和实战应用,协助你快速掌握这个改变LLM应用开发范式的框架。
PART 01 – 传统LLM开发的三大痛点
模型锁定陷阱:被API绑架的开发者
在LangChain出现之前,开发LLM应用面临的最大问题是”模型锁定”。假设你用OpenAI的GPT-4构建了一个客服机器人,代码中充斥着OpenAI特定的API调用:
# 紧密耦合OpenAI API的旧代码
import openai
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.7
)
answer = response.choices[0].message.content
这种直接调用看似简单,实则埋下隐患。当你想切换到Anthropic的Claude或本地部署的Llama模型时,需要:
1. 修改API调用方式(每个厂商的接口不同)
2. 调整prompt格式(不同模型对prompt的理解有差异)
3. 重新处理输出格式(response结构各不一样)
4. 适配上下文管理逻辑(token计数方式不统一)
这就像你的应用被”焊死”在某个特定的LLM上,迁移成本高到让人望而却步。许多团队因此放弃了性价比更高的开源模型,被迫继续使用昂贵的闭源API。
重复造轮子:每个项目都从零开始
即使你坚持使用同一个LLM,每次启动新项目依旧要重复实现基础功能:
– Prompt管理:如何优雅地处理prompt模板?如何动态注入变量?
– 上下文维护:聊天机器人需要记住历史对话,怎么实现?
– 外部数据集成:如何让LLM访问企业内部文档、数据库?
– 输出解析:LLM返回的自然语言如何转换为结构化数据?
每个开发者都在重新发明这些基础组件,浪费大量时间在”脚手架”建设上,而不是专注于业务逻辑本身。更糟糕的是,这些自研组件往往不够健壮——没有思考边界情况、缺少错误处理、无法应对复杂场景。
复杂工作流困境:链式调用的噩梦
实际业务场景往往需要多步骤的LLM交互。以一个智能文档分析系统为例,完整的工作流程包括:
1. 从网站抓取内容
2. 提取关键信息
3. 总结核心要点
4. 根据摘要回答用户提问
用原生API实现这个流程,代码会变成”意大利面条”:
# 混乱的多步骤调用
raw_text = fetch_from_url(url)
extracted = openai.ChatCompletion.create(...) # 步骤1
summary = openai.ChatCompletion.create(...) # 步骤2
answer = openai.ChatCompletion.create(...) # 步骤3
# 每个步骤都要手动处理:
# - 提取上一步的输出
# - 格式化为下一步的输入
# - 错误处理和重试
# - 日志记录和调试
这种方式不仅代码冗长,更致命的是缺乏可维护性。当你需要插入新步骤、调整顺序、或将某个步骤切换到不同的模型时,整个调用链都可能崩溃。
PART 02 – LangChain核心理念:抽象的力量
用抽象打破模型边界
LangChain的核心价值可以用一个类比来理解:它就像家里的恒温器。你只需要设定温度,不需要了解背后复杂的暖通系统如何工作——这就是抽象。在LangChain中,开发者只需声明”我要使用一个LLM”,具体是GPT-4、Claude还是Llama,只是配置参数的区别:
from langchain.llms import OpenAI, Anthropic, HuggingFaceHub
# 统一的接口,切换模型只需改一行
llm = OpenAI(model_name="gpt-4") # 闭源模型
# llm = Anthropic(model="claude-2") # 另一个闭源模型
# llm = HuggingFaceHub(repo_id="meta-llama/Llama-2-70b") # 开源模型
# 使用方式完全一致
response = llm("请解释什么是量子纠缠")
这种设计的优势在于:
– 解耦依赖:应用代码与具体LLM实现隔离
– 灵活切换:A/B测试不同模型只需配置修改
– 成本优化:根据任务复杂度动态选择模型
链式思维:让LLM应用像流水线一样运行
LangChain的第二个核心创新是”Chain”(链)的概念。它将复杂的LLM任务分解为一系列可组合的步骤,每个步骤是一个独立的函数,上一步的输出自动成为下一步的输入:
from langchain.chains import LLMChain, SequentialChain
from langchain.prompts import PromptTemplate
# 第一步:提取文本信息
extract_template = PromptTemplate(
input_variables=["url"],
template="访问{url}并提取主要内容"
)
extract_chain = LLMChain(llm=llm, prompt=extract_template)
# 第二步:生成摘要
summary_template = PromptTemplate(
input_variables=["content"],
template="总结以下内容:{content}"
)
summary_chain = LLMChain(llm=llm, prompt=summary_template)
# 第三步:回答问题
qa_template = PromptTemplate(
input_variables=["summary", "question"],
template="基于摘要{summary},回答:{question}"
)
qa_chain = LLMChain(llm=llm, prompt=qa_template)
# 组装成顺序链
full_chain = SequentialChain(
chains=[extract_chain, summary_chain, qa_chain],
input_variables=["url", "question"],
output_variables=["answer"]
)
# 一行代码执行整个流程
result = full_chain({"url": "https://example.com", "question": "核心观点是什么?"})
这种链式设计的优势:
– 模块化:每个步骤可独立测试和优化
– 可配置:不同步骤可使用不同的LLM(成本控制)
– 可扩展:轻松插入新步骤,如数据验证、格式转换
– 可观测:每个环节的输入输出都可记录,便于调试
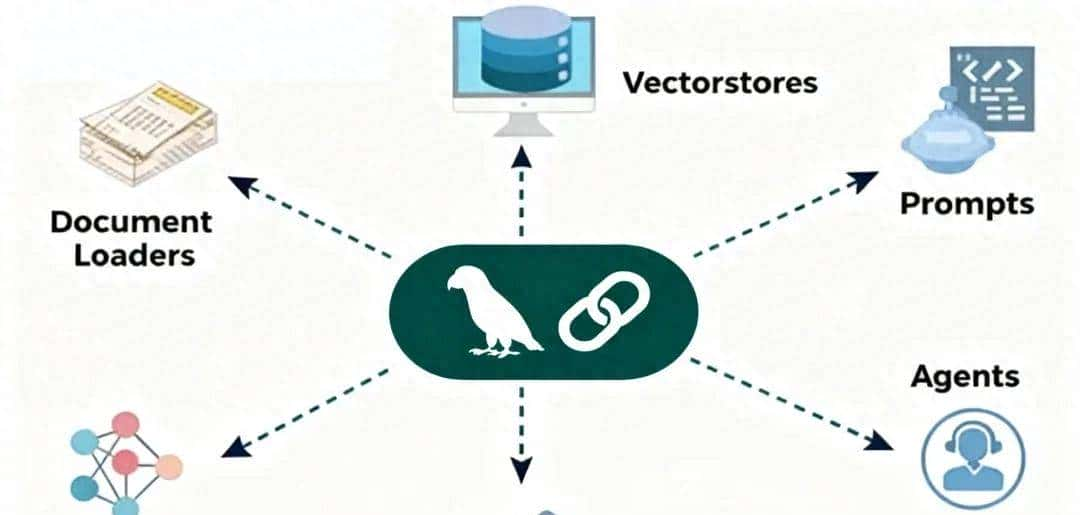
六大核心模块:完整的工具箱
LangChain通过六大模块覆盖LLM应用开发的全流程:
1. LLM模块:统一的模型接口
支持几乎所有主流LLM:GPT系列、Claude、PaLM、Cohere,以及Llama、Mistral等开源模型。只需一个API key就能接入。
2. Prompts模块:智能提示词管理
Prompt Template类自动处理提示词的组装,支持变量注入、条件分支、Few-shot示例:
from langchain.prompts import FewShotPromptTemplate
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="输入: {input}
输出: {output}"
)
examples = [
{"input": "开心", "output": ""},
{"input": "悲伤", "output": ""}
]
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
prefix="将情绪转换为emoji:",
suffix="输入: {text}
输出:",
input_variables=["text"]
)
3. Chains模块:工作流编排引擎
除了顺序链(SequentialChain),还支持:
– Router Chain:根据输入类型路由到不同的处理链
– Map-Reduce Chain:并行处理大量数据,再汇总结果
– Transformation Chain:在调用LLM前后进行数据转换
4. Indexes模块:外部知识接入
这是LangChain最强劲的功能之一,解决”LLM如何访问私有数据”的问题:
- Document Loaders
- :从Dropbox、Google Drive、YouTube字幕、Airtable、Pandas、MongoDB等数百种数据源导入
- Vector Databases
- :支持Pinecone、Weaviate、Chroma、FAISS等向量数据库,实现高效语义检索
- Text Splitters
- :智能切分长文本,保持语义完整性
5. Memory模块:对话上下文管理
解决LLM”失忆”问题的多种策略:
– ConversationBufferMemory:保留完整对话历史
– ConversationSummaryMemory:用LLM总结历史,节省token
– ConversationKGMemory:提取对话中的知识图谱
– VectorStoreMemory:基于类似度检索历史
6. Agents模块:自主决策的智能体
Agent是LangChain的高级特性,让LLM成为”推理引擎”,自主决定下一步行动。
PART 03 – 实施部署完整指南
环境准备:30秒快速启动
系统要求
– Python 3.8+ (推荐3.11)
– 8GB+ 内存
– OpenAI API Key (或其他LLM provider)
一键安装
# 核心库
pip install langchain
# 根据需求选装
pip install langchain-openai # OpenAI集成
pip install langchain-community # 社区扩展(Document Loaders等)
pip install langchain-cli # 命令行工具
pip install langserve # API服务
pip install langsmith # 监控工具
验证安装
from langchain.llms import OpenAI
import os
os.environ["OPENAI_API_KEY"] = "your-api-key"
llm = OpenAI(temperature=0.9)
print(llm("你好,LangChain!"))
核心代码:从零构建RAG问答系统
步骤1:文档加载与切分
from langchain.document_loaders import PyPDFLoader, TextLoader, WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 多种数据源加载
loaders = [
PyPDFLoader("company_report.pdf"),
TextLoader("policy.txt"),
WebBaseLoader("https://www.example.com/docs")
]
documents = []
for loader in loaders:
documents.extend(loader.load())
# 智能切分(保持语义完整)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每块最大字符数
chunk_overlap=200, # 块之间重叠,避免语义断裂
separators=["
", "
", "。", ".", " "] # 优先级分隔符
)
split_docs = text_splitter.split_documents(documents)
print(f"文档切分为 {len(split_docs)} 个片段")
步骤2:构建向量知识库
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS # 本地向量库,适合原型开发
# 生成向量并存储
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(
documents=split_docs,
embedding=embeddings
)
# 持久化到本地
vectorstore.save_local("faiss_index")
# 之后加载
# vectorstore = FAISS.load_local("faiss_index", embeddings)
步骤3:创建检索问答链
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
# 自定义prompt模板
template = """
使用以下上下文回答问题。如果不知道答案,就说不知道,不要编造。
上下文: {context}
问题: {question}
详细回答:
"""
QA_PROMPT = PromptTemplate(
template=template,
input_variables=["context", "question"]
)
# 初始化聊天模型
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
# 创建问答链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # "stuff"模式:将所有检索到的文档塞入prompt
retriever=vectorstore.as_retriever(
search_type="similarity", # 类似度检索
search_kwargs={"k": 4} # 返回top 4相关文档
),
chain_type_kwargs={"prompt": QA_PROMPT},
return_source_documents=True # 返回引用来源
)
步骤4:交互式问答
def ask_question(question):
result = qa_chain({"query": question})
print(f"
问题: {question}")
print(f"
回答: {result['result']}")
print(f"
引用来源:")
for i, doc in enumerate(result['source_documents'], 1):
print(f"{i}. {doc.metadata.get('source', 'Unknown')} - {doc.page_content[:100]}...")
# 使用示例
ask_question("公司去年的营收增长率是多少?")
ask_question("哪些因素影响了销售业绩?")
PART 04 – 未来趋势与技术演进
LangGraph:状态管理的下一代
LangChain推出了LangGraph,解决复杂工作流的状态管理问题:
传统Chain的局限:
– 只能线性或简单分支
– 无法处理循环(如Agent的多轮推理)
– 状态难以持久化

LangGraph的创新:
from langgraph.graph import StateGraph
from langgraph.prebuilt import ToolExecutor
# 定义状态图
workflow = StateGraph()
workflow.add_node("agent", run_agent)
workflow.add_node("tools", ToolExecutor(tools))
# 条件边:根据Agent决策选择路径
workflow.add_conditional_edges(
"agent",
should_continue, # 函数决定下一步
{
"continue": "tools",
"end": END
}
)
workflow.add_edge("tools", "agent") # 工具执行后回到Agent
app = workflow.compile()
应用场景:
– 复杂决策流程(如贷款审批:收集信息→风控检查→人工复核→批准)
– 多轮对话(Agent反复调用工具直到解决问题)
– 可恢复任务(中断后从检查点继续执行)
多模态LangChain:视觉+语言
LangChain正在集成多模态模型(如GPT-4 Vision):
from langchain.chat_models import ChatOpenAI
from langchain.schema.messages import HumanMessage
llm = ChatOpenAI(model="gpt-4-vision-preview")
message = HumanMessage(
content=[
{"type": "text", "text": "这张图片显示了什么?"},
{"type": "image_url", "image_url": "https://example.com/chart.png"}
]
)
response = llm.invoke([message])
# "这是一张柱状图,显示2023年Q1-Q4的销售数据,Q4达到峰值..."参考资料
- LangChain官方文档
https://python.langchain.com/docs/get_started/introduction
完整的API文档和快速入门指南 - LangChain GitHub仓库
https://github.com/langchain-ai/langchain
开源代码和issue讨论 - LangSmith平台
https://smith.langchain.com/
LLM应用可观测性和调试工具 - LangChain模板库
https://github.com/langchain-ai/langchain/tree/master/templates
50+个开箱即用的应用模板 - LangChain Cookbook
https://github.com/langchain-ai/langchain/tree/master/cookbook
实战场景代码示例集合 - LangServe文档
https://python.langchain.com/docs/langserve
将Chain部署为REST API的工具 - LangGraph教程
https://langchain-ai.github.io/langgraph/
下一代状态管理框架
关于MCP研究院
MCP研究院专注于AI技术的深度解读与实践指导,致力于协助开发者和企业掌握前沿技术、落地创新应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...










