
好的,这是一道非常经典的操作系统文件系统综合题,它以**FAT (文件分配表)**为核心,将目录结构、文件链接分配、地址查找和性能计算等多个知识点串联在一起,非常考验对FAT文件系统工作原理的理解。
我们来详细地解析这道题。
题目原文
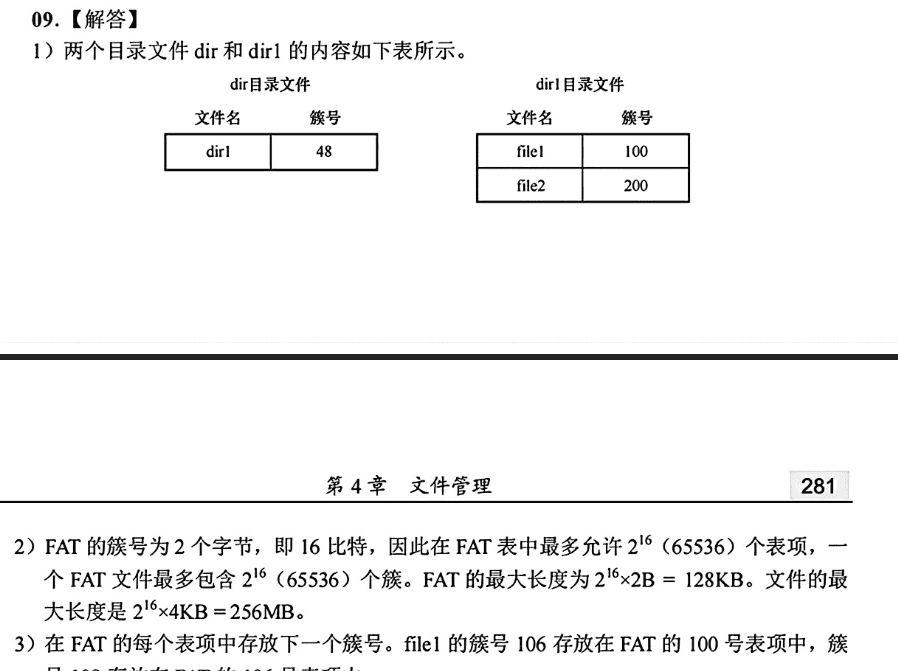
(9)【2016统考真题】某磁盘文件系统使用链接分配方式组织文件,簇大小为 4KB。目录文件的每个目录项包括文件名和文件的第一个簇号,其他簇号存放在文件分配表 FAT 中。
假定目录树如上图所示,各文件占用的簇号及顺序如上表所示,其中
dir
dir1
file1
file2
file1
dir
dir/dir1/file1
一、运用了什么知识点?考了什么?为什么这么考?
运用知识点:
文件目录结构: 理解树形目录结构,以及目录本身也是一种特殊的文件。链接分配 (FAT变种): 这是本题的核心。它不是简单的“指针存于数据块中”的链接分配,而是将所有文件的链接指针集中存放在一个叫做文件分配表 (FAT) 的大数组里。FAT的表项号(数组下标)对应磁盘的簇号,表项内容是该簇的下一个簇号。按名存取过程: 理解查找一个文件(如
/a/b/c
a
a
a
a
b
c
考了什么?
这道题完整地模拟了FAT文件系统的一次“按名存取”操作。它考查的是:
数据结构的理解与构建 (Q1): 能否根据零散的文件信息,反向构建出目录文件的内容。系统参数的极限计算 (Q2): 能否根据FAT表项的大小,推算出FAT本身的最大尺寸以及它能支持的最大文件长度。这考察了对系统设计约束的理解。FAT核心工作原理 (Q3): 检验考生是否真正理解“FAT表项内容是下一个簇号,表项索引是当前簇号”这一核心机制。文件访问的动态模拟 (Q4): 这是一个综合性极强的“寻址”问题,要求考生扮演操作系统的角色,从一个路径名出发,一步步地进行目录解析、FAT查询,最终定位到磁盘上的物理簇。
为什么这么考?
因为FAT虽然是一个相对古老的文件系统,但它的设计思想——将链接信息与数据分离——非常经典,是理解现代文件系统(如ext, NTFS的间接块)的基础。这道题通过一个完整的实例,让考生“走一遍”真实的文件访问流程,能够深刻地检验考生是否将目录、FCB、FAT、数据块这些孤立的概念,融会贯通成一个协同工作的有机整体。
三、解题思路与详细分析 (怎么样?)
问题1分析:构建目录文件
思路: 目录文件就是一个列表,每个条目是
<文件名, 起始簇号>
dir
dir1
dir
从目录树看,
dir
dir1
dir1
48
dir
| 文件名 | 簇号 |
|---|---|
| dir1 | 48 |
构建
dir1
从目录树看,
dir1
file1
file2
file1
100
file2
200
dir1
| 文件名 | 簇号 |
|---|---|
| file1 | 100 |
| file2 | 200 |
问题2分析:FAT的极限
FAT的最大长度是多少字节?
思路: FAT是一个大数组,数组的下标就是磁盘的簇号。FAT的表项大小决定了它能表示的簇号的范围。FAT表项: 占2B = 16位。这意味着簇号最多可以用16位来表示。因此,磁盘上最多可以有
2¹⁶ = 65536
2¹⁶
最大簇数 × 每个表项的大小
最大长度 = 2¹⁶ 项 × 2 B/项 = 65536 * 2 B = 131072 B = 128 KB
文件系统支持的文件长度最大是多少?
思路: 文件长度 =
文件占用的簇数 × 每个簇的大小
2¹⁶
最大簇数 × 簇大小
最大长度 = 2¹⁶ 簇 × 4 KB/簇 = 65536 * 4 KB = 262144 KB = 256 MB
结论: FAT最大长度为 128 KB;文件最大长度为 256 MB。
问题3分析:FAT的链接原理
核心原理: 如果文件占用了簇A和簇B,且A在B之前,那么FAT中第A个表项的内容,就是簇B的编号。即
FAT[A] = B
file1
file1
100, 106, 108
结论:
106
108
问题4分析:模拟文件访问 (拉分点!)
这是一个综合寻址过程,我们需要一步步追踪。
目标: 读取
dir/dir1/file1
FAT
dir
第1步: 解析路径,找到
dir1
在内存中的
dir
<dir1, 48>
dir1
第2步: 读取
dir1
dir1
dir1
第3步: 解析路径,找到
file1
在刚刚读入内存的
dir1
<file1, 100>
file1
第4步: 定位目标数据在
file1
目标是第 5000 个字节。簇大小是 4KB = 4096 字节。计算目标字节在文件中的第几个簇:
簇的逻辑编号 (从0开始) = floor(字节偏移 / 簇大小)
簇逻辑编号 = floor( (5000-1) / 4096 ) = floor(4999 / 4096) = floor(1.22...) = 1
第5步: 利用FAT找到第2个物理簇
我们知道文件的第1个物理簇是100。要找第2个物理簇,我们需要去查FAT表(已在内存)。查
FAT[100]
file1
100, 106, 108
FAT[100]
第6步: 读取目标数据
目标数据在106号簇。这个簇不在内存中,需要从磁盘读取。访问磁盘的第106簇,将该簇的内容读入内存。第5000字节就在其中。
总结访问的簇:
为了读取
dir1
结论: 需要访问 簇48 和 簇106。
好的,完全没问题!这道题的难点在于它涉及了一个我们平时可能不太注意的真实文件系统——FAT。我们把它彻底拆解,从最基础的概念讲起,保证你能理解。
把它想象成一个**“寻宝游戏”**,你要找的宝藏是“
file1
核心知识点一:树形目录 (藏宝图的结构)
这是什么? 就像你电脑里的文件夹套文件夹。
C:UsersMy Documents
dir
dir1
dir1
file1
file2
dir
dir1
dir1
file1
file2
核心知识点二:链接分配 (宝藏的分块存放)
这是什么? 想象一下,一个很大的宝藏(一个大文件),装不下在一个箱子里。于是你把它分成很多小份,分别装在很多个箱子(簇/磁盘块)里,这些箱子可以随意摆放在仓库(磁盘)的任何地方。问题来了: 你怎么知道这些零散的箱子,哪个是第一份,哪个是第二份呢?简单链接分配: 在每个箱子A里,除了放宝藏,还放一张小纸条,写着“下一份宝藏在箱子B里”。
缺点: 要找第100份宝藏,你必须打开前99个箱子,一个一个看纸条,太慢了!而且纸条本身也占地方。
核心知识点三:FAT – 文件分配表 (集中的导航地图)
这是什么? FAT是对简单链接分配的巨大优化。它想:“我干嘛要把下一份宝藏在哪的小纸条,分别塞在每个箱子里呢?我把所有的小纸条都拿出来,集中贴在一面巨大的墙上,做成一张**“导航总图”**,不是更方便吗?”FAT的工作原理 (这是本题的绝对核心!)
这面“墙”(FAT)被分成了很多个格子,格子的编号就对应仓库里箱子的编号。比如,墙上第100号格子,就专门记录和仓库里第100号箱子有关的信息。格子的内容是什么? 就是原来那张小纸条的内容——“下一个箱子的编号”。举例:
file1
你想知道第100号箱子后面的宝藏在哪?你不用去打开100号箱子,而是直接去看墙上(FAT)的第100号格子,你会发现里面写着数字 106。哦,原来下一份在106号箱子!你想知道106号箱子后面的宝藏在哪?就去看墙上(FAT)的第106号格子,里面写着 108。你想知道108号箱子后面还有没有?就去看墙上(FAT)的第108号格子,里面会写着一个特殊标记(比如-1),表示“这是最后一份了,后面没有了”。
“寻宝游戏”开始:解答第四问
你的任务: 找到
dir/dir1/file1
你手上的初始道具:
“导航总图”FAT 已经在你脑子里了(读入内存)。最外层的大文件夹
dir
第一步:找到
dir1
dir1
动作: 你翻开手上的
dir
<文件名: dir1, 起始箱子号: 48>
dir1
dir1
dir1
【对应操作:访问磁盘的第48簇】
第二步:找到
file1
file1
动作: 你现在拿到了
dir1
<文件名: file1, 起始箱子号: 100>
<文件名: file2, 起始箱子号: 200>
file1
file1
第三步:计算“第5000个字”在哪个箱子里
问题: 你要找的不是整个
file1
第1个箱子 (逻辑上):装的是第1到第4096个字。第2个箱子 (逻辑上):装的是第4097到第8192个字。…第5000个字,显然是在逻辑上的第2个箱子里。
第四步:找到逻辑上第2个箱子的“真实编号”
问题: 我们只知道第一个箱子的真实编号是
100
你要找100号箱子的下一个箱子。查FAT的第100号格子。根据题目信息(
file1
100, 106, 108
第五步:取出宝藏
问题: 你已经确定了,你要的第5000个字,就在仓库的106号箱子里。行动: 你必须再去仓库跑一趟,把 106号箱子 里的东西(
file1
【对应操作:访问磁盘的第106簇】
寻宝总结
为了找到这个宝藏,你总共去仓库跑了几趟?
第一趟:为了拿
dir1
file1
最终结论: 你总共需要访问簇48和簇106。
这样一步步跟着“寻宝”的思路走,是不是就清晰多了?这道题的本质就是模拟这个“查清单 -> 去仓库 -> 查清单 -> 查导航图 -> 再去仓库”的过程。
好的,我们来把文件系统这个话题彻底讲透,从你日常接触的设备开始,再关联到刚才那道难题,最后总结出解题的“套路”。
第一部分:身边的文件系统 (U盘, Win11, Ubuntu)
“文件系统”就像一个图书馆的**“图书管理员”**。没有它,你的硬盘就是一堆杂乱无章、无法查找的0和1。文件系统的任务就是:组织和管理数据,并提供按名存取(通过文件名找到文件)的功能。
1. U盘:FAT32 或 exFAT —— “通用世界的通行证”
你用的U盘大概率是
FAT32
exFAT
FAT32
exFAT
FAT32
FAT32
优点: 兼容性天下第一。结构简单,读写速度快。缺点: 不够安全和稳定。它没有日志功能,如果U盘在写入时被突然拔掉,很容易造成数据损坏或丢失。权限管理也几乎为零。
2. Windows 11:NTFS —— “强大而现代的管家”
你的Win11系统盘,一定是
NTFS
优点:
安全性高: 支持精细的文件权限设置(谁能读、谁能写)。稳定性好: 拥有日志 (Journaling) 功能。在你写入文件时,它会先在“草稿本”(日志)上记一笔:“我准备把A文件写到B位置”。写完后再擦掉草稿。即使中途断电,重启后系统一看草稿本,就知道上次操作没完成,可以轻松恢复,数据不容易损坏。功能丰富: 支持文件压缩、加密、磁盘配额等高级功能。支持大文件/大分区: 理论上支持的文件和分区大小远超当前硬件的极限。
缺点: 兼容性不如FAT系列。虽然Linux和Mac可以读取NTFS,但写入支持通常需要第三方软件,不是原生完美的。
3. Ubuntu (Linux):Ext4 —— “高效灵活的开源先锋”
你的Ubuntu系统盘,大概率是
Ext4
优点:
性能优秀: 专为Linux内核优化,读写性能、特别是处理大量小文件时表现出色。稳定可靠: 同样拥有强大的日志功能。开源灵活: 作为Linux生态的一部分,它在不断地发展和优化。文件系统检查速度快: 采用了新的数据结构,即使是超大硬盘,检查文件系统错误的速度也很快。
缺点: Windows默认不认识! 如果你把一块Ext4格式的硬盘插到Win11电脑上,系统会提示你“无法识别,需要格式化”。需要安装专门的软件才能读取。
小结:
FAT32/exFAT: 为了兼容性而生,像人人都懂的“英语”。NTFS: 为了Windows的强大和安全而生,像功能复杂的“德语”。Ext4: 为了Linux的高效和稳定而生,像语法严谨的“法语”。
第二部分:解剖难题 (Q2) 与“套路”总结
现在,我们带着对文件系统的理解,回到那道难题。那道题里的文件系统,就是一种简化的
FAT
难题Q2问了什么? (大白话翻译)
原题: 若 FAT 的每个表项仅存放簇号,占 2B,则 FAT 的最大长度为多少字节? 该文件系统支持的文件长度最大是多少?
大白话翻译:
我有一本“导航地图册 (FAT)”,地图册里的每一条记录(表项)都是用 2个字节 写的。这本地图册本身最大能有多厚(多少字节)?用这本地图册,我最多能管理一个多大的文件(理论上文件最大能有多大)?
套路一:从“表项大小”反推“系统极限”
这是解这类题的第一步,也是最核心的套路。
问自己: “表项”是干嘛的?
答: 表项是用来存放**“下一个簇号”**的。
问自己: “表项的大小”限制了什么?
答: 表项的大小,限制了它能写下的数字的范围!类比: 如果给你一张小纸条,只能写2位十进制数,你最多只能写出
99
9999
计算极限:
题目说,表项大小是 2字节 (2B)。
2B = 16
0
2¹⁶ - 1
2¹⁶
65535
2¹⁶-1
2¹⁶
套路二:根据“系统极限”计算“FAT大小”和“文件大小”
现在我们知道了“天花板”是
2¹⁶
计算FAT的最大长度:
问自己: FAT是干嘛的?答: 是“导航总图”,它要为每一个可能存在的簇都准备一个记录位置(表项)。计算:
系统最多有
2¹⁶
FAT总大小 = 表项总数 × 每个表项的大小
FAT总大小 = 2¹⁶ × 2B = 128 KB
计算支持的最大文件长度:
问自己: 文件的长度是怎么算的?答:
文件长度 = 文件占用的簇数 × 每个簇的大小
一个文件,最极端的情况,就是它把系统里所有的簇都占满了。系统最多有
2¹⁶
最大文件长度 = 最大簇数 × 每个簇的大小
最大文件长度 = 2¹⁶ × 4KB = 256 MB
总结与刻意练习
核心套路:
表项大小 -> 决定 -> 簇号范围 -> 决定 -> 系统总簇数 (天花板) -> 决定 -> FAT总大小 & 最大文件长度
精确区分: 能清晰地向阅卷老师解释清楚 “为什么是表项的大小决定了系统总簇数”。因为表项的内容(下一个簇号)必须能指到任何一个可能的簇,所以表项的表示能力,就是系统寻址能力的上限。单位换算: 在计算过程中,
B
KB
MB
2¹⁰
2¹⁶
2²⁰
刻意练习:
改变条件练习:
如果FAT表项改成3B会怎么样?(最大簇数
2²⁴
2²⁴ * 4KB = 64GB
2¹⁶ * 8KB = 512MB
逆向思维练习:
如果一个文件系统最大支持16GB的文件,簇大小是4KB,那么FAT表项至少需要多少位?
总簇数 = 16GB / 4KB = 2³⁴ / 2¹² = 2²²
22/8 ≈ 2.75
通过这样反复地正向和逆向练习,你就能彻底掌握这个“套路”,无论题目怎么变化,都能抓住其中的核心逻辑。
好的,没问题!我们继续用“寻宝游戏”的思路,来把这两道题彻底讲明白。这两问是连续的动作,我们放在一起来分析。
第三问:FAT的链接原理 (导航地图怎么看?)
问题翻译 (大白话)
原题: 系统通过目录文件和 FAT 实现对文件的按名存取,说明
的 106, 108 两个簇号分别存放在 FAT的哪个表项中。
file1大白话: 我们知道
这个宝藏,它的箱子顺序是
file1。请问,“下一个是106”这张纸条,是贴在哪号格子里?“下一个是108”这张纸条,又是贴在哪号格子里?
100 -> 106 -> 108
核心原理回顾
FAT这面“导航墙”,它的规则是:
里的内容,记录的是
第 N 号格子的
第 N 号箱子。
下一个箱子的编号
FAT[当前箱子号] = 下一个箱子号
按图索骥
宝藏的第一段: 存放在100号箱子里。
问题: 100号箱子后面的那一份在哪?回答: 在106号箱子里。
应用FAT规则:
我们想知道“100号箱子”的“下一个箱子号”。这个信息就存放在“FAT的第100号格子”里。所以,FAT的第100号表项里存放的内容,必然是 106。
宝藏的第二段: 存放在106号箱子里。
问题: 106号箱子后面的那一份在哪?回答: 在108号箱子里。
应用FAT规则:
我们想知道“106号箱子”的“下一个箱子号”。这个信息就存放在“FAT的第106号格子”里。所以,FAT的第106号表项里存放的内容,必然是 108。
结论
106
108
这道题就是在检验你是否理解了这个最最核心的
FAT[当前] = 下一个
第四问:模拟文件访问 (寻宝全过程)
问题翻译 (大白话)
原题: 假设仅 FAT 和
目录文件已读入内存,若需将文件
dir的第 5000 个字节读入内存,则要访问哪几个簇?
dir/dir1/file1大白话: 你现在要开始寻宝了!目标是
宝藏里的第5000个字。
file1
你手上的初始道具是:“导航总图 (FAT)” 已经背在你脑子里了 (在内存)。“顶级藏宝图 (
文件夹)” 已经拿在你手上了 (在内存)。
dir
问题: 在整个寻宝过程中,你总共需要亲自去仓库(磁盘)打开并读取哪几个箱子(簇)?
寻宝路线全追踪
我们一步一步来模拟你的行动。
行动1:解读顶级藏宝图 (
dir
你在做什么: 你在看手上的
dir
“dir1”文件夹,从48号箱子开始
dir1
dir1
行动2:去仓库取
dir1
你在做什么: 你跑到仓库,找到48号箱子,把它打开,把里面的东西(
dir1
行动3:解读二级藏宝图 (
dir1
你在做什么: 你现在手上有了
dir1
“file1”宝藏,从100号箱子开始
file1
行动4:计算目标“第5000个字”在哪个箱子里
你在做什么: 你在做数学计算(这在你的大脑里完成,不需要去仓库)。计算过程:
每个箱子能装4KB = 4096个字。第1个箱子(逻辑上)装的是第1~4096个字。你要找的第5000个字,不在第1个箱子里。它在逻辑上的第2个箱子里。
你得到了什么信息: 目标在逻辑上的第2个箱子。
行动5:查“导航总图 (FAT)”找出真实箱子号
你在做什么: 你在查已经背在你脑子里的FAT导航图(因为它已经在内存里,这个动作不需要去仓库)。查询过程:
你知道第一个真实箱子号是 100。你要找它的下一个箱子。你查询
FAT[100]
你得到了什么信息: 根据第3问的知识,
FAT[100]
行动6:去仓库取最终的宝藏!
你在做什么: 你已经锁定了最终目标!你跑到仓库,找到106号箱子,把它打开,取出里面的东西。你要的第5000个字就在这里面。消耗: 第二次磁盘访问。访问的簇: 簇106。
寻宝总结
在整个过程中,你亲自去仓库(访问磁盘)取了几个箱子?
簇48 (为了拿
dir1
file1
最终结论: 总共要访问 簇48 和 簇106。
希望这个“寻宝”的比喻能让你彻底理解整个过程!这道题考察的就是你是否能分清哪些操作是在“脑子里/手上”完成的(访问内存),哪些是必须“跑腿”去完成的(访问磁盘)。
这是一个非常棒的问题,它直接命中了这道题最核心、也最容易让人迷惑的地方!
简单回答就是:因为你不需要打开第一个箱子,就能知道第二个箱子在哪。
我们来深入分析一下这个“寻-宝游戏”的逻辑。
为什么我们直觉上会认为要访问100号簇?
我们的直觉来自于简单的链接分配。在那种模式下:
“下一个箱子在哪”的小纸条,是塞在当前箱子里的。
如果按照这个“简单链接”的规则,你的寻宝路线会是:
找到
file1
在这种情况下,你确实需要访问100号簇。
但这道题的规则(FAT文件系统)有什么不同?
关键区别就在于,FAT文件系统做了一个天才般的设计:
它把所有“下一个箱子在哪”的小纸条,全部从各自的箱子里抽了出来,集中贴在一面巨大的“导航墙 (FAT)”上。
现在,你的寻宝路线变成了:
找到
file1
dir1
你需要知道逻辑上的第二个箱子在哪。
旧方法: 去打开100号箱子,在里面翻找纸条。新方法 (FAT): 根本不用去动100号箱子!你只需要抬头看一下那面巨大的“导航墙”,找到墙上第100号格子,那里已经明明白白地贴着“106”这个数字了。
你通过查“导航墙”,直接就知道了下一个目标是106号箱子。
于是,你直接跑去**【访问106号箱子】**。
你看,整个过程中,100号箱子你碰都没碰一下!
回到题目本身
你的目标: 读取第5000个字节。你的计算: 你通过
floor(4999 / 4096) = 1
你知道逻辑上的第1个簇是100号 (来自
dir1
FAT[100]
106
总结:
之所以不用访问100号簇,是因为确定“下一个簇是谁”这个信息,不是存储在100号簇的数据块里的,而是存储在已经被读入内存的FAT表里的。
FAT的核心优势就在于此:它把**“寻路”(查FAT表,在内存中进行)和“取货”(访问数据簇,在磁盘上进行)这两个动作分离开来**。当你只需要“寻路”时,你完全可以在内存里快速完成,而无需进行缓慢的磁盘I/O。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










