
MongoDB 妙用全景总结:从大数据到地图应用
MongoDB 凭借其灵活的文档模型、强大的索引能力和丰富的聚合框架,在许多特定场景下有着非常巧妙的用法,尤其是在处理 大数据、轨迹数据、地图应用 以及 实时分析、AI 检索 等方面。
本文将从 应用场景 → 技术妙用 → 最佳实践 → 高阶能力 的角度,全面总结 MongoDB 的妙用。
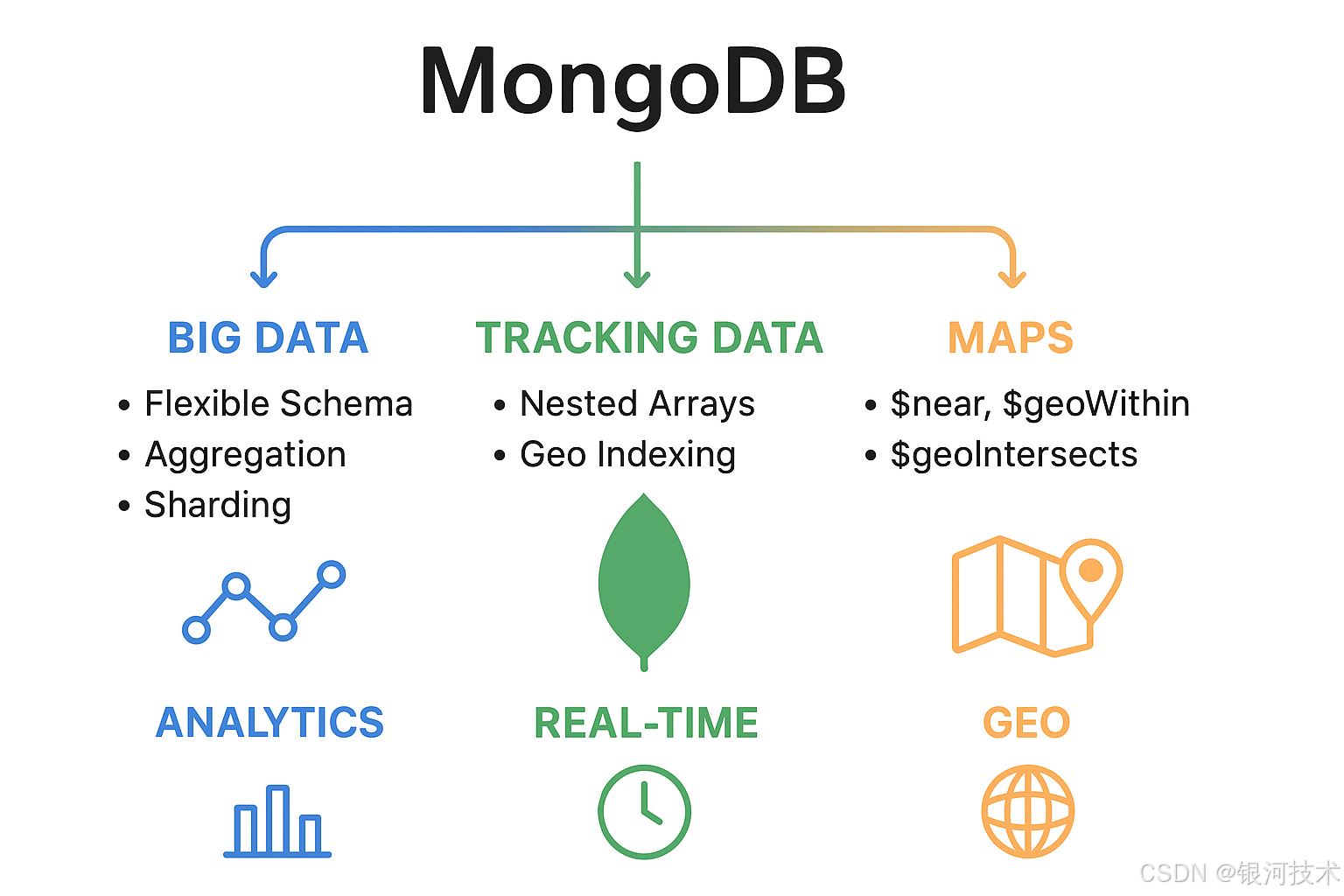
1. 处理大数据 (Big Data)
模式灵活 (Flexible Schema)
无需预定义严格模式,数据源可以随时扩展字段。场景示例:用户行为分析,每个事件都可能携带不同字段。
聚合框架 (Aggregation Framework)
类似数据库内置 ETL 流水线,减少应用层压力。示例:计算网站每小时 PV/UV
db.page_views.aggregate([
{ $match: { timestamp: { $gte: ISODate("2023-10-01") } } },
{ $project: { hour: { $hour: "$timestamp" }, userId: 1 } },
{ $group: {
_id: "$hour",
pageViews: { $sum: 1 },
uniqueVisitors: { $addToSet: "$userId" }
}},
{ $project: { hour: "$_id", pageViews: 1, uniqueVisitors: { $size: "$uniqueVisitors" } }},
{ $sort: { hour: 1 } }
]);分片集群 (Sharding)
水平扩展海量数据(TB~PB)。场景示例:全球 IoT 平台,以 device_id 或 region 分片,均衡存储。
2. 处理轨迹数据 (Tracking Data)
存储模式设计
模式:一个文档代表一条轨迹,轨迹点作为数组存储。
{
vehicle_id: "Truck-007",
start_time: ISODate("2023-10-27T08:00:00Z"),
end_time: ISODate("2023-10-27T18:00:00Z"),
path: [
{ loc: [116.4, 39.9], timestamp: ISODate("..."), speed: 60 },
{ loc: [116.41, 39.91], timestamp: ISODate("..."), speed: 62 }
]
}优势:读写高效、原子性更新、索引友好。
地理空间索引
对数组内的 path.loc 建立 2dsphere 索引:
db.trips.createIndex({ "path.loc": "2dsphere" })
应用场景:
查询经过某区域的车辆 ($geoIntersects)查询某点附近车辆 ($near)
3. 地图应用 (Map Applications)
地理空间索引类型
2dsphere:适用于地球球面几何(真实地图)。2d:适用于平面坐标(如游戏地图)。
常见地理查询
$near:附近查询$geoWithin:范围内查询$geoIntersects:相交查询
典型妙用:地理围栏 (Geofencing)
db.geofences.find({
location: {
$geoIntersects: {
$geometry: { type: "Point", coordinates: [116.35, 39.95] }
}
}
})应用:设备进入围栏时触发告警。
4. 实时分析与流处理
Change Streams
支持订阅数据库变更事件,构建实时应用。
const changeStream = db.collection("trips").watch();
changeStream.on("change", (next) => console.log("位置变更:", next));场景:实时轨迹监控、围栏告警。
5. 性能优化与最佳实践
时间序列集合 (Time-Series)
针对 IoT/日志优化,自动分桶和压缩。
TTL 索引 (Time To Live)
自动清理过期数据:
db.tracks.createIndex({ timestamp: 1 }, { expireAfterSeconds: 2592000 })
场景:仅保留最近 30 天的轨迹点。
冷热数据分离
热数据在 MongoDB,冷数据归档到 HDFS/对象存储。
6. 大数据生态集成
MongoDB Connector for Spark:大规模批处理。MongoDB Atlas Data Lake:直接查询对象存储文件。场景:实时数据在 MongoDB,历史数据在 Data Lake。
7. 多模型存储 (Multi-Model in One DB)
KV:天然 _id 主键查找。时序 (TSDB):Time-Series 集合。图数据库 (Graph):利用 $graphLookup。
db.people.aggregate([
{ $match: { name: "Alice" } },
{ $graphLookup: {
from: "people",
startWith: "$friends",
connectFromField: "friends",
connectToField: "name",
as: "network",
maxDepth: 3
}}
])8. 安全与多租户
Field-level Encryption (FLE):字段级加密,保护敏感信息。RBAC 权限控制:多租户隔离。分片按租户划分:实现 SaaS 多客户数据隔离。
9. AI 与高级检索
Atlas Search ($search):基于 Lucene 的全文搜索。Vector Search:存储 Embedding,实现语义检索。场景:
“查找我附近的咖啡馆”,结合 $geoWithin + 向量相似度。
10. 运维与实践优化
分片策略:避免单一时间戳分片,推荐复合键。写入优化:使用 bulkWrite 替代单条插入。监控与告警:MongoDB Ops Manager/Atlas Metrics 实时监控。
总结对比表
|
场景/特性 |
妙用 |
技术点 |
|
大数据 |
模式灵活、聚合内置 ETL、分片扩展 |
动态模式、聚合框架、分片集群 |
|
轨迹数据 |
文档内嵌数组存储整条轨迹、地理索引高效查询 |
内嵌数组、2dsphere、$geoIntersects |
|
地图应用 |
附近、范围内、相交搜索 |
$near, $geoWithin, $geoIntersects |
|
实时分析 |
订阅变更事件,低延迟处理 |
Change Streams |
|
性能优化 |
高效存储与生命周期管理 |
Time-Series、TTL、冷热分层 |
|
大数据生态集成 |
在线+离线一体化 |
Spark Connector, Data Lake |
|
多模型存储 |
KV + 时序 + 图查询 |
_id 主键、Time-Series、$graphLookup |
|
安全与多租户 |
字段加密、租户隔离 |
FLE、RBAC、分片 |
|
AI 与检索 |
语义检索 + 地理搜索 |
Vector Search、$search |
|
运维优化 |
避免热点分片、批量写入、监控告警 |
Sharding、bulkWrite、Ops Manager |
结语
MongoDB 远不止是一个 NoSQL 文档数据库。当你巧妙地利用 文档模型、聚合框架、地理空间索引、实时流处理、AI 搜索 等能力时,它可以成为支撑 大数据分析、时空轨迹管理、地图应用、实时监控和智能检索 的强大引擎。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...









