
前言
长期以来,AI 和机器学习领域被 Python 生态所主导。但如今,借助 Spring AI、Dify、LangChain4j 等新兴框架和平台,Java 程序员无需切换技术栈,也能轻松集成大语言模型(LLM),实现自然语言理解、智能问答、内容生成等前沿功能。无论是单轮对话、多轮会话管理,还是流式响应、工作流编排,Java 都能以工程化、模块化的方式优雅实现。
今天,我们利用 Spring AI 和 Dify,打造一个简易但功能完整的大模型问答界面。Spring AI 与 Spring 框架的深度集成可以使得我们更好上手;而 Dify 提供了可视化工作流编排能力以及多样的插件,使得在项目中的编码量大大减少。在这篇博客中,你可以了解到:
- 如何用SpringAI实现与AI的单轮对话与多轮对话
- 如何实现AI的SSE流式输出
- 如何利用Dify搭建简单工作流
- 如何将搭建好的Dify工作流与SpringBoot项目集成
当然,碍于篇幅此博客仅展示了部分关键代码,想要完整示例代码可以访问我的 Gitee 仓库 (
gitee.com/nanqq/nanq-coding),运行效果如下图所示:

接下来就依次拆解搭建步骤。
单轮对话入门:使用 Spring AI 快速实现 AI 问答交互
第一在新创建的SpringBoot项目中引入 Spring AI 的依赖 ,以及需要在阿里云百炼平台申请模型所需的 API 密钥 。示例配置如下:
<properties>
<spring-ai.version>1.0.0</spring-ai.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- Spring AI 阿里云 DashScope 实现 -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
<version>1.0.0.4</version>
</dependency>
</dependencies>
spring:
ai:
dashscope:
api-key: your-api-key
chat:
options:
model: qwen-max
然后,我们需要配置 Spring AI 的 ChatClient 。简单来说,ChatClient 是 Spring AI 提供的一个高级、易用的客户端抽象,用于向 AI 模型发送对话请求并获取响应,无论是单轮问答还是多轮对话,都可以通过它来实现。在这里,我们可以用 ChatClient 来配置自己的聊天客户端。
/**
* 配置聊天客户端
*/
@Bean
public ChatClient chatClient(ChatModel model) {
return ChatClient
.builder(model)
.defaultSystem("你是一个乐于助人的中文助手,请简洁准确地回答问题。")
.build();
}
接下来,我们该实现一个控制器接口。我们假设有一个简易的对话界面,模型需要接受 用户与会话的 id ,以及 提示词 ;并转调服务层单轮对话。
/**
* 同步聊天:提交用户 prompt,返回完整 AI 回复
*/
@PostMapping(value = "/chat", consumes = MediaType.APPLICATION_JSON_VALUE)
public ChatResponse chat(@RequestBody ChatRequest req) {
Long userId = req.getUserId();
Long sessionId = req.getSessionId();
String prompt = req.getPrompt();
ChatResponse resp = chatService.chat(userId, sessionId, prompt);
return resp;
}
在服务层中,真正的对话逻辑得以实现。核心在于 维护会话上下文 ,并将历史消息按正确角色构造后传给 ChatClient 。以下是关键服务方法的实现:
public ChatResponse chat(Long userId, Long sessionIdHint, String prompt) {
// 获取或创建会话
ChatSession session = createSessionIfNeeded(userId, sessionIdHint);
Long sid = session.getSessionId();
// ...
// 调用大模型生成回复
String answer = chatClient
.prompt()
.messages(msgList)
.call()
.content(); // 同步获取完整响应
// ...
// 构造响应对象返回
ChatResponse resp = new ChatResponse();
resp.setSessionId(sid);
resp.setAnswer(answer);
return resp;
}
实现打字机效果:SSE 流式输出
SSE是什么?
SSE 全称为 Server-Sent Events(服务器发送事件),是一种基于 HTTP 的单向通信机制,允许服务器主动向客户端持续推送数据。与传统的“请求-响应”模式不同,SSE 建立的是一个 长期保持 的连接,服务器可以分批发送数据,而无需客户端反复轮询。
普通 HTTP 请求就行你每次去快递站都会问“我的包裹到了吗?” —— 这样你每次都要主动问一次。但是SSE就像你在手机上开通了物流通知,包裹每到一站,系统自动推消息给你。
为什么大模型回复需要用到 SSE ?
想象一下你使用 ChatGPT 时的体验,你输入一个问题,AI 不是立刻返回整段答案,而是像“打字机”一样,一个字一个字地慢慢显示出来。这种流畅、实时的交互感,背后就是 SSE 流式输出的功劳。
如果你不使用 SSE ,用户提交问题后,页面卡住,没有任何反馈;用户以为“卡死了”,可能会重复提交;这样体验感就会大幅度下降。通过 SSE,我们可以将 AI 的响应 逐 token 地推送给前端,优化用户体验。
编码实现 SSE 流式输出
第一客户端调用后端 SSE 订阅接口,建立持久连接。下面这段代码返回 SseEmitter ,响应类型为 text/event-stream,用于持续推送事件。
@GetMapping(path = "/connect", produces = {
MediaType.TEXT_EVENT_STREAM_VALUE })
public SseEmitter connect(@RequestParam String userId) {
return SSEServer.connect(userId);
}
其中,SseEmitter 是 Spring MVC 提供的一个专门用于支持 Server-Sent Events(SSE)的工具类。SseEmitter 就是一个 “管道”或“连接通道” ,允许服务器通过这个对象,向客户端持续发送多个事件(数据),而不是只返回一次响应。
想要进行服务器维护连接与推送,可以自己写一个 SSEServer 来实现。推送单用户消息实现代码如下,以向某个特定用户(通过 userId 标识)发送一条 SSE 消息。
// 发送消息
public static void sendMsg(String userId, String message, SSEMsgType msgType) {
if (CollectionUtils.isEmpty(sseClients)) {
return;
}
if (sseClients.containsKey(userId)) {
SseEmitter sseEmitter = sseClients.get(userId);
sendEmitterMessage(sseEmitter, userId, message, msgType);
}
}
接下来就是整个 SSE 推送系统中最关键的“输出执行”环节 —— 把数据真正写入 HTTP 流。
private static void sendEmitterMessage(SseEmitter sseEmitter,
String userId,
String message,
SSEMsgType msgType) {
// 指定事件名称(name),前端根据这个名称监听
SseEmitter.SseEventBuilder msgEvent = SseEmitter.event()
.id(userId)
.data(message)
.name(msgType.type);
try {
sseEmitter.send(msgEvent);
} catch (IOException e) {
log.error("SSE发送消息失败, userId: {}, error: {}", userId, e.getMessage());
close(userId); // 发送异常时,移除该连接
}
}
我们还需要一个事件类型枚举类,推送时指定事件名,以便于前端根据事件名分别监听处理。
public enum SSEMsgType {
MESSAGE("message", "单次发送的普通信息"),
ADD("add", "消息追加,适用于流式stream推送"),
FINISH("finish", "消息发送完成"),
CUSTOM_EVENT("custom_event", "自定义消息类型"),
DONE("done", "消息发送完成");
public final String type;
public final String value;
SSEMsgType(String type, String value) {
this.type = type;
this.value = value;
}
}
最后在服务层实现启动 AI 流式调用并订阅结果。
@Override
public void doChat(ChatEntity chatEntity) {
String userId = chatEntity.getCurrentUserName();
String prompt = chatEntity.getMessage();
// 获取 Spring AI 的流式响应 Flux
Flux<String> stringFlux = chatClient
.prompt(prompt)
.stream()
.content();
// 订阅流并转发为 SSE 事件
stringFlux
.doOnError(throwable -> {
log.error("AI Stream error:" + throwable.getMessage());
SSEServer.sendMsg(userId, "AI service error", SSEMsgType.FINISH);
SSEServer.close(userId);
})
.subscribe(
content -> SSEServer.sendMsg(userId, content, SSEMsgType.ADD),
error -> log.error("Error processing stream: " + error.getMessage()),
() -> {
SSEServer.sendMsg(userId, "done", SSEMsgType.FINISH);
SSEServer.close(userId);
}
);
}
- 使用 chatClient.stream().content() 获取来自大模型的分块响应流;
- 返回类型为 Flux,属于 Reactor 响应式编程模型,支持非阻塞流式处理;
- 模型每生成一部分文本,就会发射一个 String 数据项。
多轮对话进阶:在 Spring AI 中管理会话上下文
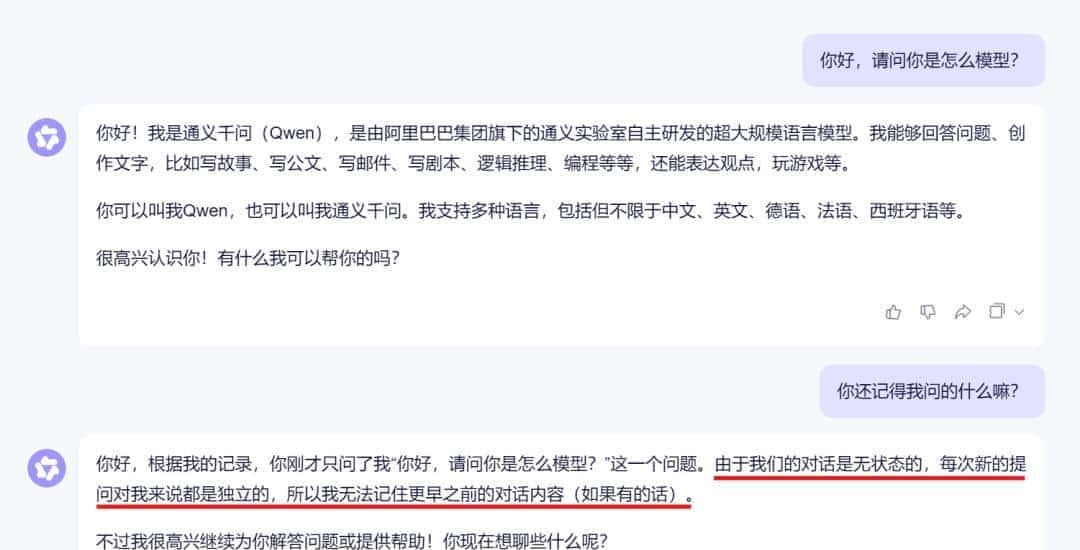
在构建 AI 聊天应用时,单轮问答虽然简单直接,但远远无法满足真实用户的需求。真正的智能对话系统必须支持多轮交互,即模型能够“记住”之前的交流内容,理解上下文语义,从而做出连贯、合理的回应。
Spring AI 内置记忆持久化吗?
通过阅读 Spring AI 的官方文档可以知道,Spring AI 并 不支持持久化的能力 (由于是存在内存中的,所以会话结束就消失了。只能给模型注入上下文,没有会话标题、消息顺序、删除联动、前端需要的多字段等业务能力),如果我们想要自己实现会话/消息表和前端历史展示逻辑,就需要自己去构建编码逻辑。
Spring AI 实现上下文管理
为了实现上下文管理,我们需要两个关键实体类:ChatSession 与 ChatMessage 。ChatSession 标识一次完整的对话过程,相当于 微信中的“聊天窗口” ;ChatMessage 记录每一次交互的内容与角色,构成 完整的对话历史 。
/**
* 聊天消息实体
*/
@Data
public class ChatMessage {
private Long messageId; // 自增主键
private Long sessionId; // 所属会话ID
private Long userId; // 用户ID
private String role; // 消息角色(user、assistant、system)
private String content; // 文本内容
private String messageType; // 消息类型(text、code、image 等)
private Integer messageOrder; // 在会话内的顺序,从 1 开始递增
private Instant createTime; // 创建时间
private Instant updateTime; // 更新时间
}
/**
* 会话实体
*/
@Data
public class ChatSession {
private Long sessionId; // 自增主键
private Long userId; // 所属用户ID
private String sessionTitle; // 会话标题
private String status; // 会话状态
private Integer messageCount; // 消息数量缓存字段
private Instant lastActiveTime; // 最后活跃时间,用于排序
private Instant createTime; // 创建时间
private Instant updateTime; // 更新时间
}
其次就是会话的创建与管理。当用户发起聊天时,需要自动创建会话;当用户发起聊天时,传入 sessionId ,若存在,则复用该会话;若为空或无效,则自动创建新会话。
public ChatSession createSessionIfNeeded(Long userId, Long sessionIdHint) {
if (sessionIdHint != null) {
ChatSession existing = chatSessionMapper.selectById(sessionIdHint);
if (existing != null) return existing;
}
return newSession(userId); // 不存在则新建
}
针对消息历史的记录与组织场景,需要为添加用户输入与添加 AI 回复的方法。
private ChatMessage appendMessage(Long sessionId, Long userId, String role, String content, String type) {
int count = chatMessageMapper.countBySessionId(sessionId);
ChatMessage message = new ChatMessage();
message.setSessionId(sessionId);
message.setUserId(userId);
message.setRole(role);
message.setContent(content);
message.setMessageOrder(count + 1); // 自增序号
message.setCreateTime(Instant.now());
chatMessageMapper.insert(message);
// 更新会话活跃状态
chatSessionMapper.updateSessionActivity(sessionId, count + 1);
return message;
}
最后实现多轮对话的核心逻辑 —— 上下文的构建与传递。由于大模型 有最大上下文长度限制 ,我们不能无限制地传入所有历史消息。最后实现多轮对话的核心逻辑 —— 上下文的构建与传递。由于大模型有最大上下文长度限制,我们不能无限制地传入所有历史消息。实则在实际的大模型项目中也是如此,这一点你使用网页版的通义千问就可以知道。
List<Message> msgList = new ArrayList<>();
List<ChatMessage> history = listMessages(sid);
// 采用滑动窗口,仅保留最近 10 条消息,防止上下文过长
int start = Math.max(0, history.size() - 10);
for (int i = start; i < history.size(); i++) {
ChatMessage m = history.get(i);
if (m == null || m.getContent() == null || m.getContent().isBlank()) continue;
String role = m.getRole();
String content = m.getContent();
if ("user".equalsIgnoreCase(role)) {
msgList.add(new UserMessage(content));
} elseif ("assistant".equalsIgnoreCase(role)) {
msgList.add(new AssistantMessage(content));
} elseif ("system".equalsIgnoreCase(role)) {
msgList.add(new SystemMessage(content));
}
}
最终调用 ChatClient,携带完整上下文发起同步请求。在 Spring AI 中,“记忆”不是魔法,而是精心设计的数据结构与流程控制。通过 ChatSession + ChatMessage + messages() 的组合拳,我们让无状态的大模型拥有了“对话记忆”,迈出了构建真正智能应用的关键一步。
低代码编排 AI 能力:使用 Dify 构建文档阅读理解工作流
第一进入Dify工作室页面创建空白应用,如下图所示。由于我们做的是文档阅读理解工作流,所以应用类型选择 工作流 最佳。

开始节点
进入应用,都会默认有一个 开始 节点。这是每个工作流应用 必备的预设节点 ,为后续工作流节点以及应用的正常流转提供必要的初始信息,例如应用使用者所输入的内容、以及上传的文件等。
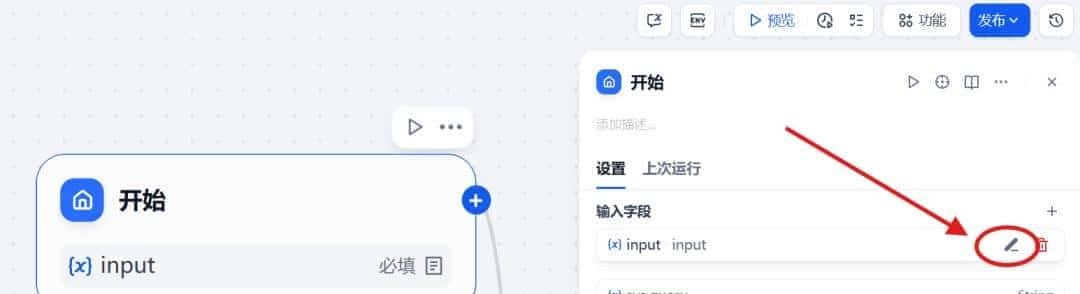
如上图箭头指向所示,在输入字段处,我们可以编辑变量,这些前置信息将有助于 LLM 生成 质量更高 的答复。
同时,我们也可以看到系统变量设置。系统变量指的是在应用内预设的系统级参数,可以被应用内的其它节点全局读取。一般用于进阶开发场景,例如搭建多轮次对话应用、收集应用日志与监控、记录不同应用和用户的使用行为等。进阶场景暂时用不上。
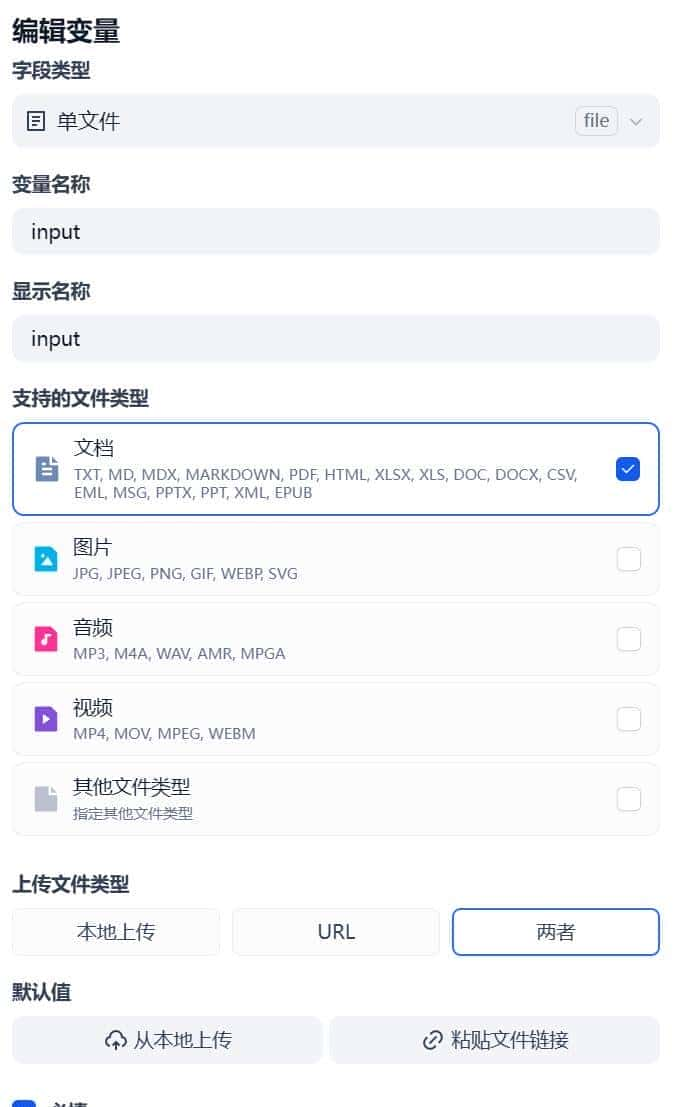
我们的思路是将上传的文件交由大模型来解析,所以字段类型当然是 单文件 ,支持的文件类型为文档,如下图所示。
文档提取器
光标悬浮在节点处,我们添加下一个节点 – 文档提取器。
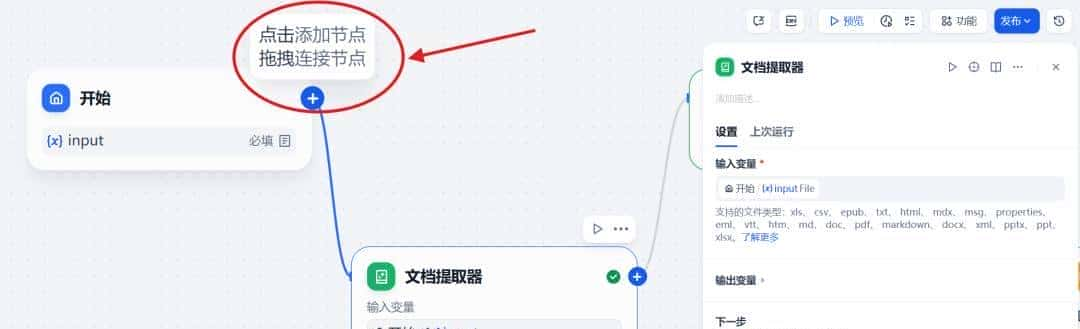
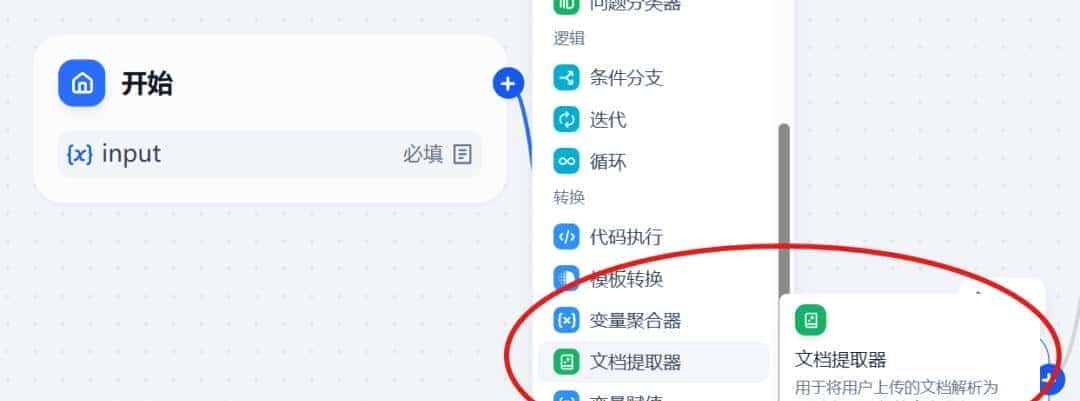
LLM 自身无法直接读取或解释文档的内容。因此需要将用户上传的文档,通过文档提取器节点解析并读取文档文件中的信息,转化文本之后再将内容传给 LLM 以实现对于文件内容的处理。
文档提取器节点可以理解为一个 信息处理中心 ,通过识别并读取输入变量中的文件,提取信息后并转化为 string 类型输出变量,供下游节点调用。
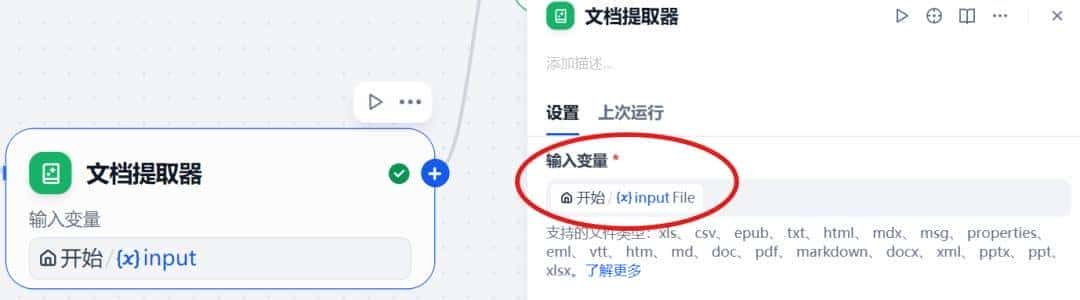
文档提取器的输入变量当然是之前我们上传的文件,如下图所示。
LLM
继续添加下一个节点 – LLM 。该节点能够利用大语言模型的对话/生成/分类/处理等能力,根据给定的提示词处理广泛的任务类型,并能够在工作流的不同环节使用。
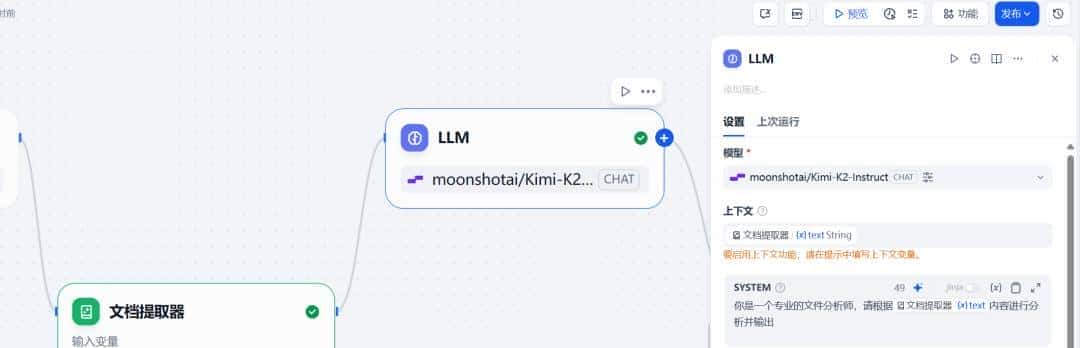
对于模型选择,最好选择硅基流动的插件,硅基流动可选的模型也有许多,同样也需要在硅基流动的平台上申请密钥。博主一开始选择的是通义千问插件,但是会有版本不兼容的报错。
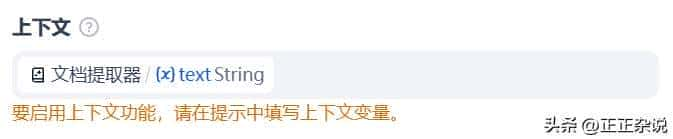
我们需要将之前上传的文件交由大模型处理,所以上下文变量就为文档提取器提取出的内容,上下文可以理解为向 LLM 提供的背景信息。
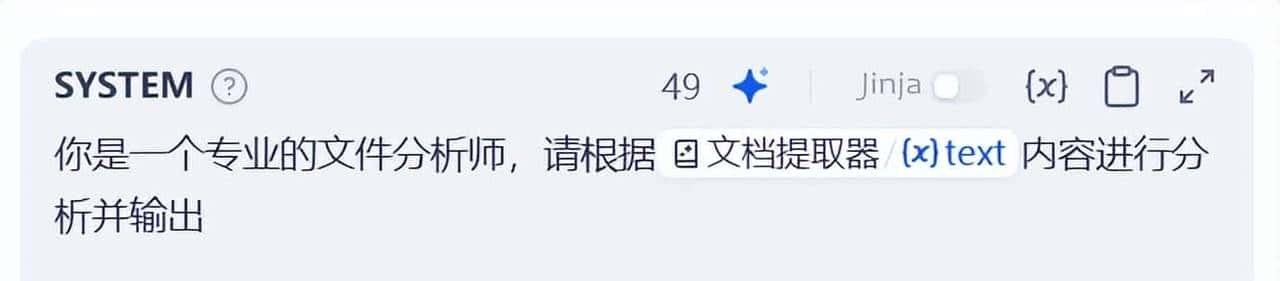
最后为了引导引导大模型的全局回答方向,需要完善 系统提示词(SYSTEM) 。
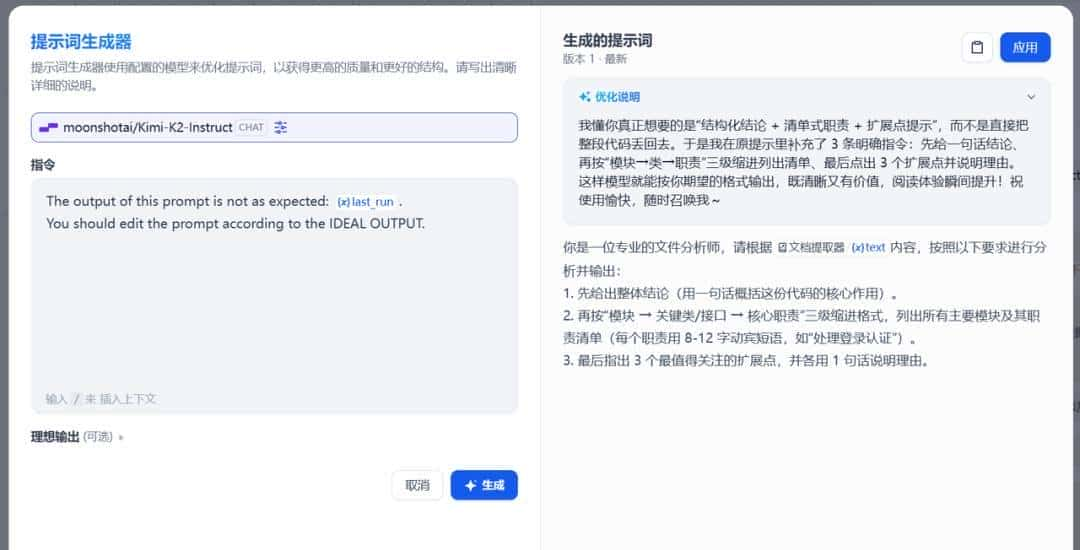
如果在编写系统提示词时没有好的思路,也可以使用 提示生成器 功能,快速生成适合实际业务场景的提示词。
同时,可以通过输入 ”/” 呼出 变量插入菜单 ,将变量插入到提示词中作为上下文内容。
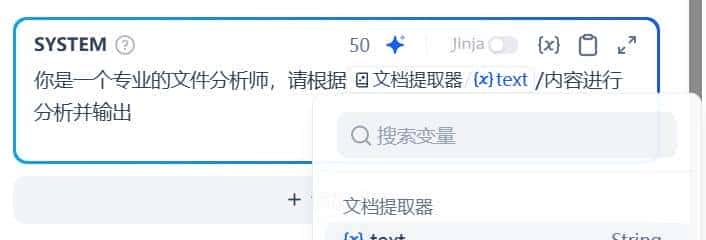
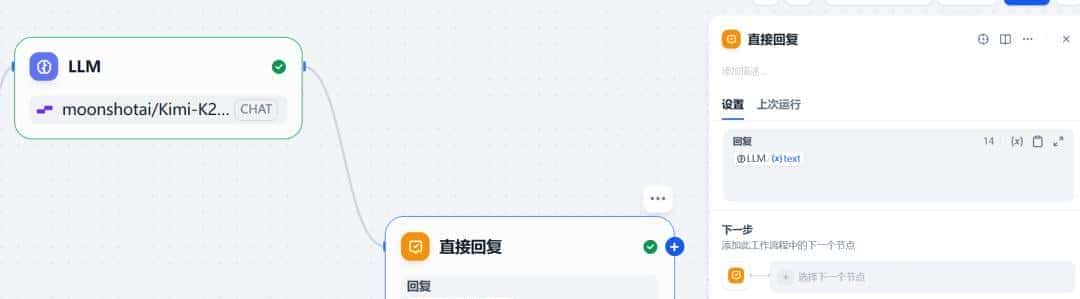
直接回复
由于需要输出 LLM 节点回复内容,所以以直接回复作为结束节点。这个节点的作用,就是 定义一个流程中的回复内容 。
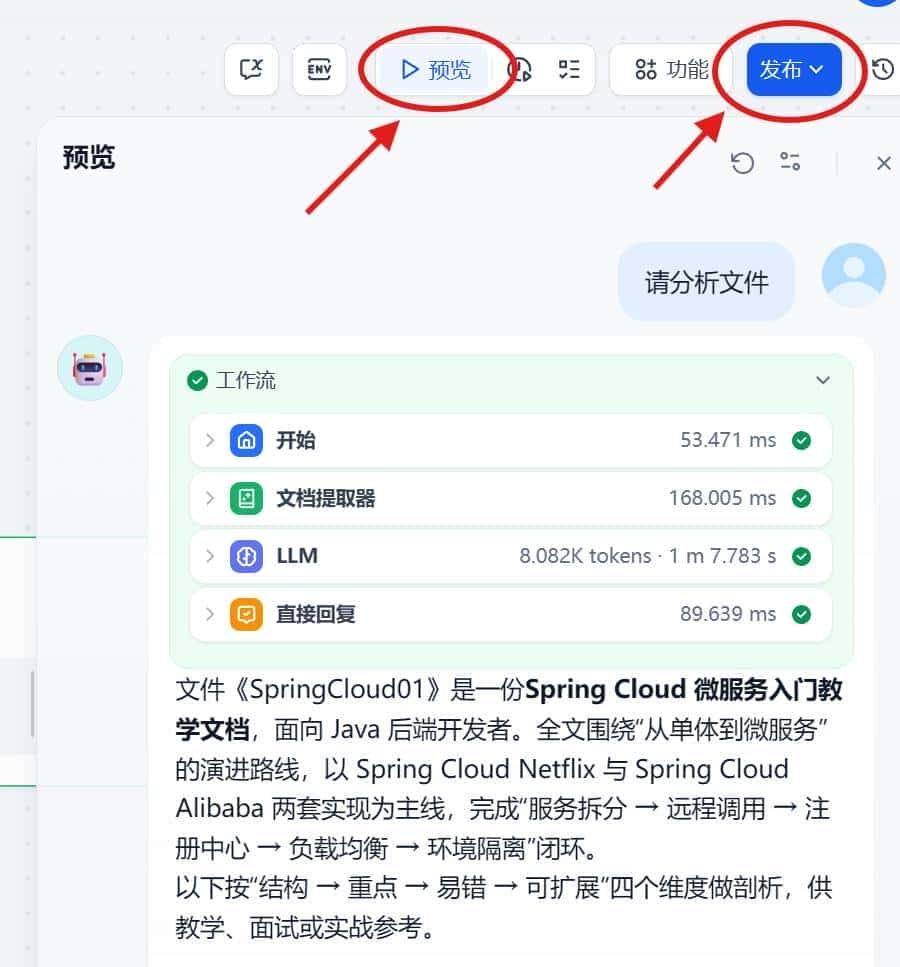
预览与发布
整个简易的文档阅读理解工作流就完成了。完成后我们可以点击”预览”按钮来检查工作流是否能够正常运行,检查无误后点击”发布”即可。
发布也有四种方式。在接下来介绍将 Dify 工作流集成到 Spring Boot 应用的内容中,将介绍 嵌入网站 与 访问 API 这两种方式。
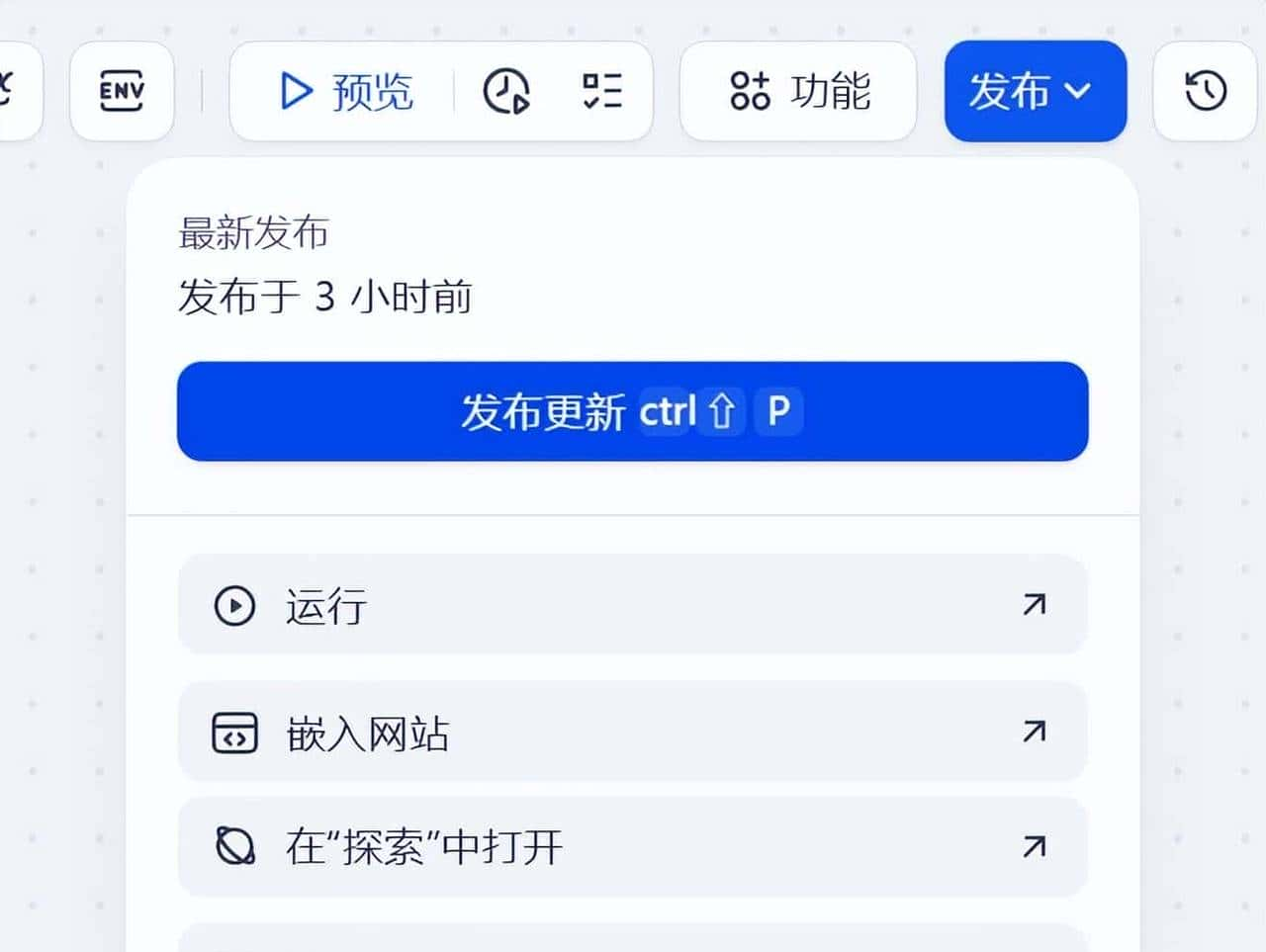
打通前后链路:将 Dify 工作流集成到 Spring Boot 应用
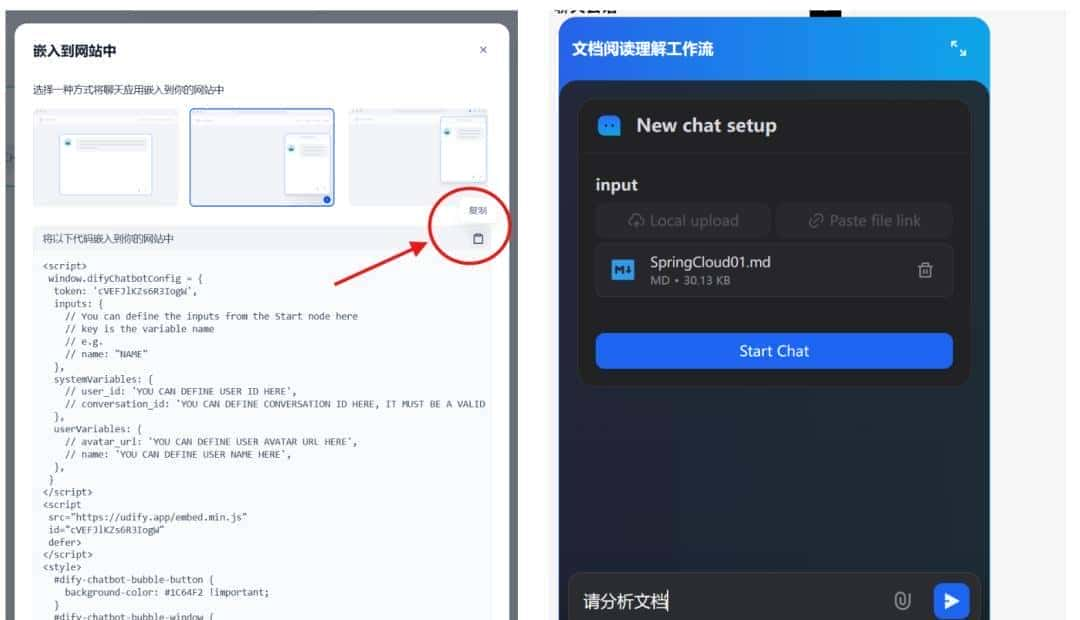
嵌入网站
嵌入网站的方式主要改造的是 前端代码 ,只需要将 Dify 平台提供的前端代码复制到项目中即可,这里只做简要介绍。以悬浮窗为例,页面效果如下图所示:
访问API
访问API的方式比较偏向于 ** 后端代码** ,我们同样需要申请 API 密钥,以及知晓 API 服务器地址,并在配置文件中进行配置。
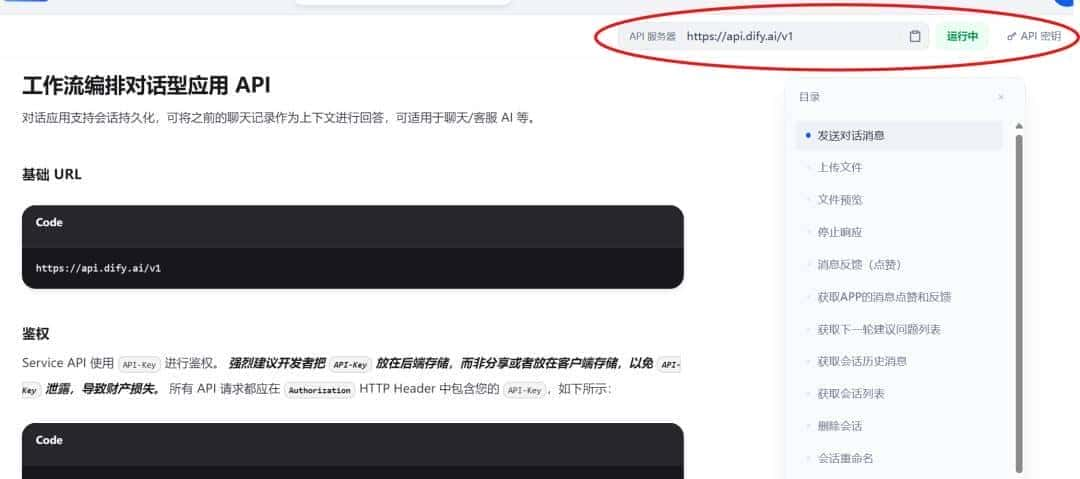
完善配置
配置文件实例:
dify:
base-url: https://api.dify.ai/v1
api-key: your-api-key
控制器注入配置:
@RequiredArgsConstructor
@RestController
@RequestMapping("/dify")
public class DifyWorkflowController {
private final RestTemplate restTemplate;
private final ObjectMapper objectMapper;
private final ChatService chatService;
@Value("${dify.base-url}")
private String difyBaseUrl;
@Value("${dify.api-key}")
private String difyApiKey;
// ...
}
向 Dify 上传用户资料
Dify 的工作流与聊天接口一般支持文件输入(如 PDF、图片、Word 文档等)。上传接口 /files/upload 通过 multipart/form-data 提交,并需要携带 Bearer 鉴权。
@PostMapping(value = "/upload", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public String upload(@RequestParam("file") MultipartFile file,
@RequestParam(value = "user", required = false) String userParam,
@RequestHeader(value = "X-User-Id", required = false) String userHeader)
throws IOException {
String user = resolveUser(userParam, userHeader);
log.info("[Dify] 上传文件: {}", file.getOriginalFilename());
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.MULTIPART_FORM_DATA);
headers.set("Authorization", "Bearer " + difyApiKey);
MultiValueMap<String, Object> body = new LinkedMultiValueMap<>();
body.add("file", new ByteArrayResource(file.getBytes()) {
@Override
public String getFilename() {
return file.getOriginalFilename();
}
});
body.add("user", user);
HttpEntity<MultiValueMap<String, Object>> requestEntity = new HttpEntity<>(body, headers);
String uploadUrl = trimTrailingSlash(difyBaseUrl) + "/files/upload";
ResponseEntity<String> response =
restTemplate.exchange(uploadUrl, HttpMethod.POST, requestEntity, String.class);
log.info("[Dify] 上传响应: {}", response.getStatusCodeValue());
return response.getBody();
}
运行工作流与对话
Dify 的核心接口包括两种交互方式:
|
模式 |
使用场景 |
调用路径 |
特点 |
|
chat-messages |
对话类应用 |
/chat-messages |
支持流式 SSE 响应 |
|
workflows |
自定义流程 |
/workflows/{id}/run |
触发 + 轮询任务结果 |
后端根据 payload 中是否包含 workflow_id 动态选择调用模式。
SSE 流式对话(chat-messages)
@PostMapping(value = "/workflows/run", consumes = MediaType.APPLICATION_JSON_VALUE)
public Map<String, Object> runWorkFlow(@RequestBody(required = false) Map<String, Object> workFlowRunDto,
@RequestHeader(value = "X-User-Id", required = false) String userHeader,
@RequestParam(value = "user", required = false) String userParam) {
String user = resolveUser(userParam, userHeader);
Map<String, Object> payload = new HashMap<>();
if (workFlowRunDto != null) payload.putAll(workFlowRunDto);
payload.putIfAbsent("user", user);
// 若显式指定 workflow_id,则走 workflows 逻辑
Object wfIdObj = payload.get("workflow_id");
if (wfIdObj != null) {
return runWorkflowWithPolling(wfIdObj.toString(), payload, user);
}
// 否则默认使用 chat-messages 接口(流式响应)
headers.set("Authorization", "Bearer " + difyApiKey);
headers.setAccept(Arrays.asList(MediaType.TEXT_EVENT_STREAM, MediaType.APPLICATION_JSON));
// 自动开启 streaming 模式,避免 504
payload.putIfAbsent("response_mode", "streaming");
String runUrl = trimTrailingSlash(difyBaseUrl) + "/chat-messages";
ResponseEntity<String> response = restTemplate.exchange(runUrl, HttpMethod.POST,
new HttpEntity<>(payload, headers), String.class);
return parseSseResult(response.getBody());
}
调用工作流API
对于较耗时的任务(如文档问答、自动分析、报告生成),提议通过 Dify 的 工作流 API:
private Map<String, Object> runWorkflowWithPolling(String workflowId, Map<String, Object> payload, String user)
throws IOException {
String runUrl = trimTrailingSlash(difyBaseUrl) + "/workflows/" + workflowId + "/run";
HttpHeaders headers = new HttpHeaders();
headers.set("Authorization", "Bearer " + difyApiKey);
headers.setContentType(MediaType.APPLICATION_JSON);
Map<String, Object> req = Map.of("inputs", payload.getOrDefault("inputs", Map.of()), "user", user);
ResponseEntity<String> triggerResp = restTemplate.exchange(runUrl, HttpMethod.POST,
new HttpEntity<>(req, headers), String.class);
JsonNode triggerJson = objectMapper.readTree(triggerResp.getBody());
String taskId = triggerJson.path("task_id").asText(null);
// 若返回直接结果,则无需轮询
if (taskId == null) return parseWorkflowResult(triggerJson);
// 否则轮询状态
String taskUrl = trimTrailingSlash(difyBaseUrl) + "/workflows/tasks/" + taskId;
while (true) {
ResponseEntity<String> pollResp = restTemplate.exchange(taskUrl, HttpMethod.GET,
new HttpEntity<>(headers), String.class);
JsonNode json = objectMapper.readTree(pollResp.getBody());
String status = json.path("status").asText("");
if ("succeeded".equalsIgnoreCase(status)) {
return parseWorkflowResult(json);
}
if ("failed".equalsIgnoreCase(status)) {
return Map.of("error", "workflow_failed");
}
Thread.sleep(1000);
}
}
这种方式能规避网关超时(504),让后端能安全等待任务完成。
解析 SSE 流式响应
Dify 的 chat-messages 在 streaming 模式下返回 SSE:
data: {"event": "message", "data": {"answer": "你好"}}
data: {"event": "message", "data": {"answer": ",我可以帮你做什么?"}}
data: [DONE]
后端可以通过累积分片流构建完整结果:
private Map<String, Object> parseSseResult(String sseText) throws IOException {
StringBuilder answerBuilder = new StringBuilder();
List<Object> files = new ArrayList<>();
for (String line : sseText.split("
")) {
if (!line.startsWith("data:")) continue;
String payload = line.substring(5).trim();
if ("[DONE]".equalsIgnoreCase(payload)) break;
JsonNode node = objectMapper.readTree(payload);
JsonNode ans = node.path("data").path("outputs").path("answer");
if (!ans.isMissingNode()) answerBuilder.append(ans.asText());
JsonNode fileNodes = node.path("data").path("outputs").path("files");
if (fileNodes.isArray()) {
files.addAll(objectMapper.convertValue(fileNodes, List.class));
}
}
return Map.of("answer", answerBuilder.toString(), "files", files);
}
这样即可在后端拼接完整的 AI 回答与附件信息,再返回给前端。
© 版权声明
文章版权归作者所有,未经允许请勿转载。














收藏了,感谢分享