
转 PDF 到 Markdown 的兄弟们,没被 “格式乱 + 图片丢” 坑过吗?明明想把文档转成可编辑的 MD 格式,结果转完标题层级乱了、列表变成纯文本,图片还得手动一张张提取,改格式比重新写还累 —— 直到发现这个基于 DeepSeek-OCR 的开源工具,算是把转换这事做顺了。
这款由开发者打造的 PDF 转 Markdown 工具,算是个值得关注的选择,不光能精准识别内容,还能保格式、提图片,刚好解决 “转换后返工多” 的问题,对常处理文档的人很友善。
这几个设计很贴转换需求
- 精准识别 + 保格式,不用手动改
- 能准确识别文档内容,还能完整保留原始格式结构 —— 列如 PDF 里的一级标题、二级标题,转成 MD 后还是# ##的层级;有序列表、无序列表也能原样保留,不用转完后对着一堆纯文本重新调格式,省了大量返工时间。
- ️ 自动提取图片,不用单独存
- 转换时会自动提取 PDF 里的图片,不用再手动截图或另存,转完的 MD 文档里直接带图片引用,打开就能看到图文结合的内容。列如转技术文档时,里面的流程图、公式图都能完整提取,不用再担心 “转完只剩文字没图” 的尴尬。
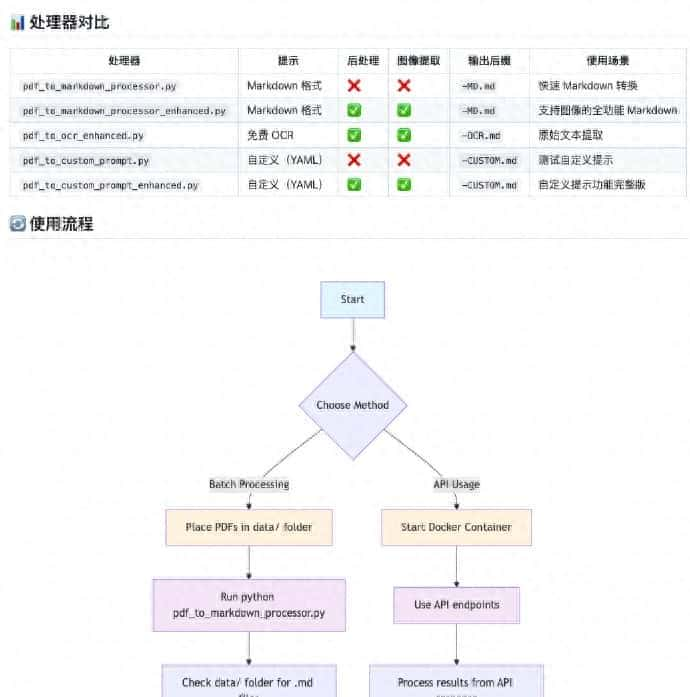
- 多模式 + 批量处理,效率够高
- 支持三种核心模式:标准化 Markdown 转换、纯 OCR 内容提取、自定义提示词处理,能按需求选。列如只想提文字就用纯 OCR 模式,要完整格式就用标准化转换;还能批量处理多个文档,不用一个一个传,处理多份资料时特别省时间。
- 易部署 + 可集成,适配场景广
- 通过 Docker 一条命令就能部署使用,不用搭复杂环境;还配备完整的 REST API 接口,能轻松集成到自己的业务系统里。列如做文档管理工具时,直接调用接口实现 PDF 转 MD 功能,不用再单独开发转换模块。
- GitHub:github.com/Bogdanovich77/DeekSeek-OCR—Dockerized-API
需要注意的是,使用时电脑显卡至少要 12GB 显存,满足这个硬件条件就能流畅运行。对常需转换 PDF 文档、又烦透格式返工的兄弟来说,算是个不错的案例。
© 版权声明
文章版权归作者所有,未经允许请勿转载。













收藏了,感谢分享
感谢